目录
第1步.创建一个独立的虚拟内存空间
第2步.读取可执行文件头,建立虚拟空间和可执行文件之间的映射关系
第3步.将cpu的指令寄存器设置成可执行文件的入口地址,启动运行。
程序开始执行,发生页错误。
随着程序的执行,不停的发生页错误,当物理内存不够用的时候
Linux装载ELF可执行文件
动态链接下的ELF可执行文件的装载
ps:动态链接器的自举代码
动态链接器的特点
显式运行时链接——动态加载共享对象
Windows装载PE可执行文件
程序的入口函数
C语言标准库和运行时库
MSVC CRT
MSVC CRT的版本
以静态和动态为主要的划分标准
下面是C语言的标准运行时库
下面是C++的标准运行时库
VS2010的运行时库的可选择项
一些问答:
MSVC CRT在多线程环境下运行下的改进
glibc的_start和_exit的汇编实现
msvcrt的mainCRTStartup
I/O相关的部分
I/O的概念
I/O初始化
IO函数fread的实现
程序执行时所需要的指令和数据必须在内存中(指的是物理内存)才能正常运行。
程序装载指的就是把这些指令和数据加载到内存中。
最简单的装载方式就是把所需的指令和数据全部装入内存,称为静态装载。但是这样会比较消耗内存。
动态装载的思想是程序用到哪个模块就装入内存。
首先介绍进程(即运行着的程序)的建立过程,然后是进程运行中的缺页,然后是linux和windows下的可执行文件(除了可执行文件,动态库,静态库等分类)的装载。
创建一个进程,首先要做的三件事是:
第1步.创建一个独立的虚拟内存空间
每一个进程都有自己独立的虚拟地址空间,本质上就是创建虚拟空间到物理空间的映射关系的数据结构。
使用二级表的话,分配一个4K的页目录(https://blog.csdn.net/u012138730/article/details/90271193)就可以了。后面的映射关系等到发生页错误的时候再进行设置。即先为进程创建一个页目录,常驻内存。
第2步.读取可执行文件头,建立虚拟空间和可执行文件之间的映射关系
这一步需要建立的是可执行文件到虚拟空间的映射关系——通过可执行文件头部(如果是elf文件格式,即elf文件的文件头。windows下可执行文件是pe格式,linux下是elf格式)的信息建立一个保存在操作系统内部的一个跟进程相关的数据结构中。
Linux下操作系统创建进程时候会在进程相应的数据结构(操作系统中有一个进程相关的数据结构,记录着所有的进程)中设置一个.text段的VMA,内容包括:
(Linux中将进程虚拟空间中的一个段叫做虚拟内存区域VMA,windows叫虚拟段VirtualSection。)
1)段在虚拟空间中的地址
2)段在elf文件中的偏移
3)段的权限读写执行以及其他的一些属性。(参考https://blog.csdn.net/u012138730/article/details/90273751中最后的虚拟内存分布)
这一步是装载过程中最重要的一步。操作系统通过上述这样的一个数据结构,当缺页时找到虚拟内存中对应的在可执行文件中的位置,从而加载到内存中。
如下图是可执行文件的text段和进程虚拟空间之间的映射。

可执行文件很多时候又叫做映像文件,因为可执行文件在装载时候是被映射的虚拟空间。
第3步.将cpu的指令寄存器设置成可执行文件的入口地址,启动运行。
操作系统设置cpu的指令寄存器(应该是设置PC,程序计数器吧?指令寄存器记录的是指令,PC记录的是内存中指令的地址),设置为可执行文件的入口地址,比如上个例子中的是0x08048000(设置的是虚拟空间地址,可执行文件头部保存着入口地址信息),将控制权转交给进程,由此进程开始执行。
控制权由操作系统转给进程:操作系统执行内核堆栈和进程堆栈的切换,cpu运行权限的切换
一些概念
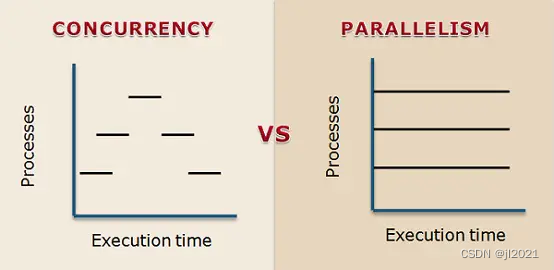
并发和并行区别
并发:逻辑上具有处理多个任务的能力。两个或两个以上的任务在一段时间内被执行。我们并不关心这些任务是否在同一时刻执行,我们只是知道,这些任务在这一段时间内能能够都被执行。
并行:物理上具备处理多个任务的能力。物理CPU的核数和并行的任务数相同,是并发的最理想目标,理论上同一时刻内一个CPU执行一个任务。
并发的目的在于把单个 CPU 的利用率使用到最高。并行则需要多核 CPU 的支持。
任务指的是线程还是进程
从cpu角度看是线程——TSS Task Status Segment(之前说过一个TSS段,再讲中断和异常的那篇文章中,任务状态段,用来记录每个线程的状态的)
从操作系统角度看是进程——windows的任务管理器里就是以进程为单位的
所以,操作系统的每个任务,对应于cpu的一个或者多个任务。
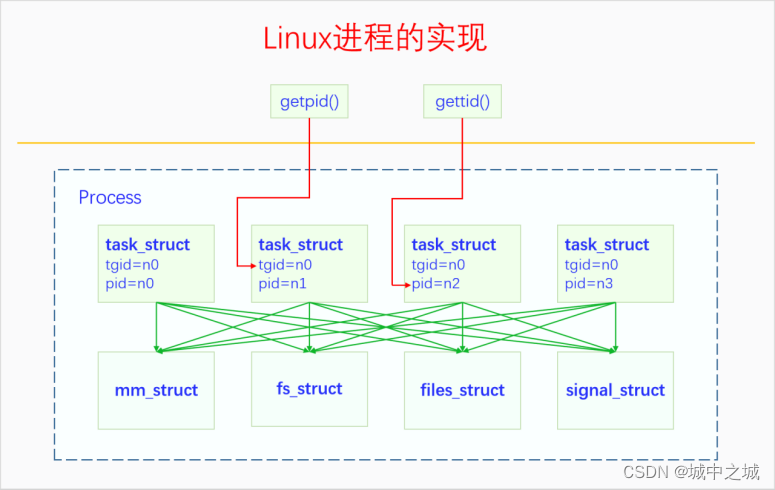
进程、程序、线程
进程和程序,一个动态,一个静态。一个加载到内存中,一个是映射文件。
如果程序是类,那么进程就是实例————一个程序可以有多个实例在运行(也可以控制,只能让一个实例在电脑上运行)。
进程是系统资源分配的最小单位,系统是由一个个进程组成的,包括文本区,数据区和堆栈区。进程的创建和销毁都比较消耗资源和时间。进程是抢占式的争夺CPU的资源,单核CPU在同一时刻只能有一个进程在执行。
线程是属于进程的资源。如果把进程比作一栋大楼,线程就是大楼中的生命。进程是线程生活的空间,线程是进程中的生命。线程是CPU调度的最小单位(所以上面说从cpu角度看任务,任务就是线程),线程属于进程,它共享进程的整个内存空间。多线程是不安全的,进程内的一个线程崩溃会导致整个进程崩溃。
线程的切换:
除了不用做 1)切换页目录以使用新地址之外(进程需要),
依然要2)切换内核栈,3)切换硬件上下文。
通常,一个进程内有一个或者多个线程,但是在某些情况下,比如一个进程只有在一开始创建或者最后销毁的时候没有任何线程。
ps:协程是属于线程的,协程的程序是在线程里面跑的。协程没有线程的上下文切换,协程的切换是程序员自己控制的。协程是原子操作的,不存在代码执行一半,被终止的情况。
进程:
多个进程之间不会相互影响,因为有分页机制,每个进程有自己的进程空间。关于用户空间和内核空间见虚拟内存那篇文章。
在操作系统层面,很多资源都是针对进程来分配的。必须要有一个进程,才能有资源。一个进程可以拥有的资源有哪些——从windows操作系统来说,创建了一个进程就相当于拥有了哪些东西的内存呢:
1)虚拟地址空间,进程空间,其实就是页表结构
2)全局唯一的进程id,pid,一个页面录基址,也就是上述的页表结构的物理地址。
3)一个可执行映像,该进程的程序文件在内存中的表示。(如果同个进程的多个实例同时运行,那么代码段是不是应该是在内存中只有一份呢,代码段应该是地址无关的吧)
4)一个或者多个线程
5)一个在内核空间的进程执行块的数据结构(EPROCESS)——进程的创建时间,映像文件名等
一个在用户空间的进程环境块(PEB)
6)一个在内核空间的对象句柄表,记录和索引该进程所创建和打开的内核对象
7)一个访问令牌,用于表示该进程的用户,安全组,以及优先级。
在windbg中使用!process 0 0 可以看到所有进程的基本的上述信息。见windbg的使用那篇文章
EPROCESS数据结构
跟每个人都有档案一样,eprocess就是进程的档案,在内核空间。
>dt _EPROCESS 进程地址 ——————可以看到详细的档案信息。
包括:
0)开头就是PCB,进程控制块的地址,用来记录与任务调度有关的信息。类型是_KPROCESS。(>dt _KPROCESS 进程地址——因为是第0个元素)
1)与调试密切相关的debugport和exceptionport
2)指向进程的虚拟地址描述符vad二叉树根节点的vadroot(>!vad) ——不知道vad是个啥东西
3)指向进程内所有线程列表表头的ThreadListHead——所以通过进程命令,可以显示当前所有的线程
4)进程环境块地址PEB——地址是位于用户空间的(所以即可在用户调试会话中看,也可以在内核调试会话中看,内核时,需要用.process 设置当前进程)(PEB(进程环境块)在内核中创建,映射到用户空间。)
>dt _PEB Peb的地址 以及 >!peb peb的地址
显示是否被调试、进程的默认堆、进程的模块列表、进程的命令行
5)Token结构的地址——
>dt nt!_TOKEN Token地址 以及 >!Token Token地址
可以使用>!process 进程地址 来显示关键的信息,没有上面dt那个那么全了,那个把每个变量都显示出来了。
>?? sizeof(_EPROCESS ) ————_EPROCESS 的大小
线程:
一个线程可以通过系统调用,可以从用户模式切换到内核模式
线程的KTHREAD结构中,定义了UserTime 和 KernelTime 两个字段,记录这个线程在用户模式下的运行时间和在内核模式下的运行时间。
ETHREAD数据结构
跟进程一样,ETHREAD就是线程的档案,也在内核空间。
>dt _ETHREAD 线程地址 ——————先通过.thread 得到当前线程的地址。
0)开头就是TCB,线程控制块的地址,用来记录与线程调度有关的信息。类型是_KTHREAD。(>dt _KTHREAD 线程地址——因为是第0个元素)——对比,进程的pcb,一样的。
TCB包含一些比较关键的信息:
+0x194 KernelTime : 6
+0x1c0 UserTime : 5定义了UserTime 和 KernelTime 两个字段,记录这个线程在用户模式下的运行时间和在内核模式下的运行时间。
+0x090 State : 0x2
定义了线程的状态字段, 0-8,2代表正在运行的状态。

windows 线程的挂起——suspendthread (难道是切换到等待状态) sleep join wait suspend函数
windows 线程的唤醒——resumethread (就绪状态?) notify resume函数

>!ready——显示出所有处于就绪状态的线程。这个是从PRCB中的DispatcherReadyListHead的数组中读取信息的。这个数组有32个元素,每个元素对应一个优先级,每个元素是一个链表,记录这对应优先级的就绪线程。
显示单独state的值 dt _KTHREAD 线程地址 -y state
+0x18b WaitReason : 0x6
定义了线程的等待原因字段, 1个字节,6代表用户代码主动请求等待(UserRequest)
为软件调试用的,对于nt内核中的等待函数来说,并不关心这个值的内容。
+0x0a8 Teb : 0x7fb4f000 Void
线程环境块地址TEB——描述线程的用户空间信息,内核在创建线程的时候,会分配专门的内存页用作TEB,将其地址记录在KTHREAD中。
>dt _TEB Teb的地址 以及 >!teb——显示当前线程的TEB信息
显示用户态栈、异常处理、错误码、线程局部存储。
可以使用>!thread 进程地址 来显示关键的信息,没有上面dt那个那么全了,那个把每个变量都显示出来了。
>?? sizeof(_ETHREAD ) ————_ETHREAD 的大小

处理器控制块PRCB
内核为每一个cpu定义了一个处理器控制块PRCB
>dt _KPRCB 地址 -y Dispatcher
读取DispatcherReadyListHead地址
_beginthreadex(CRT运行时函数)和CreateThread(windowsapi )
头文件:#include <process.h>
语法:
uintptr_t _beginthreadex( // NATIVE CODEvoid *security,unsigned stack_size,unsigned ( __stdcall *start_address )( void * ),void *arglist,unsigned initflag,unsigned *thrdaddr);返回类型: 新创建的线程的句柄,创建失败返回NULL,退出使用 _endthreadex。_beginthreadex和_endthreadex都是CRT线程函数
ThreadX * o1 = new ThreadX( 0, 1, 2000 );
HANDLE hth1;
unsigned uiThread1ID;
hth1 = (HANDLE)_beginthreadex( NULL, // security0, // stack sizeThreadX::ThreadStaticEntryPoint,o1, // arg listCREATE_SUSPENDED, // so we can later call ResumeThread()&uiThread1ID )_beginthreadex在内部调用了CreateThread(Windows的API函数 操作系统函数),在调用之前_beginthreadex做了很多的工作,从而使得它比CreateThread更安全
(事实上如果不使用Microsoft的VisualC++编译器,如果你的编译器供应商有它自己的CreateThread替代函数。不管这个替代函数是什么,你都必须使用他来代替CreateThread。)
(每个线程 获取由C/C++运行期库的堆栈分配的自己的tiddata内存结构(tiddata结构位于Mtdll.h文件中的VisualC++源代码中),就保存在tiddata内存块:线程函数的地址以及传递给该线程函数的参数。)
_beginthread是简化版的_beginthreadex,可控制性太差
beginthread是_beginthreadex的功能子集,
虽然_beginthread内部是是调用_beginthreadex但他屏蔽了安全特性这样的功能
例如,如果使用_beginthread,就无法创建带有安全属性的新线程,无法创建暂停的线程,也无法获得线程的ID值
(但是在海战代码里还是用了很多 _beginthread,需要看下这个函数的使用场景,还是有使用的必要性的)
wow进程
我们的windows大部分都是64位的系统了,但是上面能运行32位的程序,也就所谓的wow进程,就是wow64=windows 32 on windows 64。
32位的可执行文件要使用的库肯定也是32位的库,但是内核时64位的即操作系统的代码,所以就有个中间转接层来做转化,主要是做一些指针长度的转化和api兼容的问题。整个框架如下所示:

在C:\Windows下,有两个子目录(不要混淆):
System32 存放着内核和64位的各种程序文件。
SysWOW64 存放的是32位的win32api和一些库函数。
例子调用:
我打开一个32位的记事本,然后用64位的windbg调试,切换到0号线程,然后看堆栈:
>.effmach amd64——切换到64位模式 ,可以看到64位转接成的执行代码,wow64win和wow64就是转接层的核心模块。调用到的是核心模块的NtUserGetMessage

>.effmach x86——切换到32位模式,看到的是32位代码的执行情况。ntdll_XXXXX这个就是32位dll。因为在wow进程中总有两个ntdll模块,64位和32位,两者的名字都是ntdll,windbg为了区分,就把后加载进进程的32位版本的模块名上加了基地址(所以基地址怎么看,lm)。
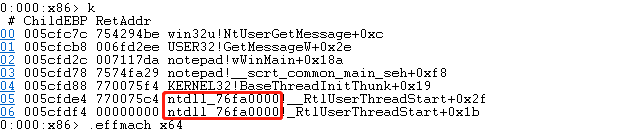

(windbg有32位和64位的,可以用32位的windbg调试wow进程(就跟调试普通的32位程序一样),也可以用64位的调试wow进程(即可调试32位代码,也可以调试64位转接层),但是应该不能用32位的windbg调试64位进程。)
上面两个图都是同一个notepad进程,在32位和64位模式下的栈回溯,可以看到epb的值都相差很远,因为wow进程很多东西都是双份的,每个进程有两个peb,每个线程有两个teb,有两个栈。
>!wow64exts.info————看wow进程的双份资产

wow进程的注册表重定向
对于wow进程访问的路径位HKEY_LOCAL_MACHINE\Software会重定向到HKEY_LOCAL_MACHINE\Software\Wow6432Node
ps:windows64位系统的注册表的键值
1)有一些键值有两份,32位,64位,如上。
2)有一些共享,如HKEY_LOCAL_MACHINE\Software\Policies。
3)有一些情况试操作系统的版本不同而不同(是有两份,还是共享),如HKEY_LOCAL_MACHINE\Software\Classes。
4)那一些有32位和64位COM组件,当用户在一个版本中设置了以后,在另外一个版本中就会自动更新:

wow进程的文件系统重定向
之前说的ntdll.dll,64位的是在 %windir%\System32目录中, 32位的是在 %windir%\SysWOW64目录中。
即当32位的wow进程访问系统文件目录的时候,会自动重定向到 %windir%SysWOW64中。(如果是windows on arm系统的话,就是自动重定位到%windir%\SysArm32)
最小进程和pico进程
一般的进程叫做nt进程。一般的进程都需要内核空间中的ntdll.dll,peb,teb映射到用户空间。但是对于最小进程,在创建之初,就会告诉nt内核,只创建进程空间,不要自动向进程空间添加内容。pico进程是最小进程的一个子类。具体到时候遇到了再看吧

上面三步只是进程的创建,通过可执行文件头部的信息建立可执行起来了 可执行文件和进程虚存之间的映射关系(执行文件的头部信息很全面了),而具体的虚拟空间到物理空间的映射关系还没有建立起来:
程序开始执行,发生页错误。
当cpu执行入口地址(比如是0x08048000)的指令的时候(要读取真正的指令的时候),发现这是个空页面(加载一页,0x08048000-0x08049000),发生页错误(在映射表中没有对应的项目),操作系统接手处理。
在第2步中,操作系统建立了虚拟空间和可执行文件之间的映射关系,所以通过查询第2步中建立的数据结构,先得到这个页面在可执行文件中的偏移,然后再物理内存中分配一个页面来加载可执行文件的那些数据和指令,并且对该虚拟页和物理页建立映射关系(更新第1步中的页表),然后再交由进程,重新从发生页错误的地方进行执行,现在执行就没有页错误了,此时物理内存中就有真正的数据cpu就可以读取指令执行了。

随着程序的执行,不停的发生页错误,当物理内存不够用的时候
涉及到操作系统的虚拟内存管理,把硬盘空间中的一部分当成RAM使用,根据一些规则把已经分配出去的物理内存暂时回收,置换到硬盘空间中。(PP和DP的置换)
上面是理论的部分,下面讲一下具体的例子
Linux装载ELF可执行文件
linux下的bash(bash进程)下用一个命令执行某个elf可执行文件 发生的事情:(执行其他的程序应该也是一样的,比如 shell,python,perl等解释型脚本语言)
- 1.首先bash进程调用fork()系统调用创建一个新进程。
- 2.然后新的进程会调用execve()系统调用,然后linux内核进行真正的装载过程:
1)execve() 调用 sys_execve()——sys_execve()执行一些参数的检查复制。
2)sys_execve() 调用 do_execve()——do_execve()检查被执行的文件是否存在,如果存在读取前128个字节,判断文件的格式(魔数),调用search_binary_handle()找到对应的装载处理过程。比如elf格式的装载处理过程是load_elf_binary()。
3)do_execve() 调用 load_elf_binary()—— load_elf_binary()就装载具体步骤(!!!重点在这里):
1)检查elf可执行文件格式的有效性,比如魔数,程序头表中Segment的数目。
2)寻找有没有.interp段,如果有的画,就是要设置动态链接器的路径。(参考剖析ELF文件格式的内容———文件头,段表,符号....(第三章)中动态链接的部分)。
3)读取程序头表,对elf可执行文件进行映射,也就是设置进程的虚存空间分布(参考https://blog.csdn.net/u012138730/article/details/90273751中最后的虚拟内存分布)。
4)初始化elf进程环境(初始化堆,栈)。
5)将系统调用的返回地址修改为可执行文件的入口地址。(入口地址是:如果是静态链接的elf就是elf文件头中的地址;如果是动态链接的elf就是动态链接器的地址,因为动态链接需要动态链接器先进行动态链接的过程才能运行程序)
4)load_elf_binary() 执行完毕返回到do_execve(),再返回到sys_execve()
5)sys_execve()系统调用从内核态返回到用户态的时候,因为上述的3)中第5步把系统调用的返回地址改成了可执行文件的入口地址了,所以程序(进程)就开始执行了。
- 3.最后bash进程返回,等待用户输入命令。
模拟的一个minibash的程序:

注:execlp是对execve的封装,最后都会调用到execve。
注:execve签名:int execve(const char * filename,char * const argv[ ],char * const envp[ ]);
第1个参数filename字符串所代表的文件路径
第2个参数是利用指针数组来传递执行参数,并且需要以空指针(NULL)结束
第3个参数则为传递给执行文件的环境变量数组
注:因为每种可执行文件的头几个字节都是不同的,称为魔数,其对应的装载处理过程也是不同的。
elf格式的前四个字节为:0x7F,“e”,“l”,“f”,装载处理过程是load_elf_binary()。
java可执行文件的前4个字节为“c”,“a”,“f”,“e”。
a.out可执行文件的装载处理过程是load_aout_binary()。
shell,python,perl等解释型脚本语言的前两个往往是“#!”(“#!/bin/sh” "#!/usr/bin/perl" "#!/usr/bin/python")。装载处理过程是load_script()。
动态链接下的ELF可执行文件的装载
上述说道 load_elf_binary()就装载具体步骤:第5步
5)将系统调用的返回地址修改为可执行文件的入口地址。(入口地址是:如果是静态链接的elf就是elf文件头中的地址;如果是动态链接的elf就是动态链接器的地址,因为动态链接需要动态链接器先进行动态链接的过程才能运行程序)
当动态链接器得到控制权以后进行:
1)首先执行自身的一些初始化操作,完成自举等
2)然后对可执行文件文件进行动态链接工作(!!!重点在这里):
0)将动态链接器本身的符号表和可执行文件的符号表合并到一个符号表中,称之为全局符号表。当然只有是符号表中是GLOBAL的才会进行合并的。
1)查找可执行文件的依赖共享对象(可执行文件的.dynamic段的DT_NEED类型的值),放入一个装载集合中。
2)依次进行查找依赖共享对象,打开,读取elf文件头和dynamic段(共享对象也是elf格式,也有文件头和dynamic段),将相应的数据段和代码段映射到进程空间中(如果该共享对象依赖其他的共享对象,再次放入到装载集合中,如果该对象没有被装载过)。每当一个新的共享对象装载进来以后,他的符号表就会合并到全局符号表中。
3)。。。
3)最后将控制权转交到可执行文件的入口地址
因为如果是动态链接下,可执行文件还依赖于很多共享对象,可执行文件引用很多共享对象中的符号还处于无效的地址。所以操作系统会启动动态链接器来完成这个地址的映射。
动态链接器本身就是一个共享对象(动态链接器这一共享对象其实就是ld.so,我们再查看动态链接下的可执行文件的虚拟空间分布的时候看到过ld.so。跟可执行文件一样,共享对象也有入口地址。)
动态链接时进程的堆栈初始化信息:查看
ps:动态链接器的自举代码
自举:具有一定限制条件的启动代码。
动态链接器的入口地址即自举代码的入口。
动态链接器入口_start(源码位于sysdeps/i386/dl-manchine.h)(跟可执行文件一样,共享对象也有入口地址。)
(vs 普通elf可执行文件程序入口_start位于 sysdeps/i386/elf/start.S)
1)然后调用_dl_start()——重定位自身完成自举,以后可以调用其他函数了和全局访问(为什么可以调用_dl_start呢)
2)然后调用_dl_start_final()——收集一些基本的运行数据
3)然后调用_dl_sysdep_start()——进行一些平台相关的处理
4)然后调用_dl_main()——动态链接器的主函数:1)装载可执行程序需要的共享对象,符号解析和重定位
因为动态链接器也是一个共享库,他本身的重定位靠自己来完成,所以动态链接器是特殊的共享库,他的限制:
1)不能依赖别的共享库
2)本身的重定位工作由自己完成
动态链接器的特点
1)动态链接器本身是静态链接的(静态链接 vs 动态链接 看 https://blog.csdn.net/u012138730/article/details/90749833)
![]()
2)动态链接器本身是PIC的(虽然也可以不是)(PIC地址无关代码的介绍 https://blog.csdn.net/u012138730/article/details/90749833 )

3)动态链接器也可以被当作可执行文件执行(同样的,windows下有个rundll32.exe 用来把一个dll当作可执行文件进行运行。rundll就是运用了运行时加载的原理,将指定的共享对象在运行时加载进来,然后找到某个函数开始执行DLL是DllMain。书中p227实现了一个runso)

显式运行时链接——动态加载共享对象
即运行时加载,让程序在运行时自己控制加载使用卸载哪些模块(插件,驱动等),使用动态链接器提供的api:
1)dlopen打开动态库:返回是动态库的句柄。
涉及到动态库的查找路径(LD_LIBRARY_PATH环境变量,/etc/ld.so.cache,/lib,/usr/lib),
动态库名称(如果是0,那就是返回全局符号表的句柄),
符号解析方式——一个例子:(RTLD_LAZY延迟绑定PLT机制release模式用减少加载时间 | RTLD_NOW即时所有绑定debug模式用即时发现问题)& RTLD_GLOBAL将符号就加入到全局符号表中。
另外动态模块有依赖其他动态库,需要手动先加载依赖的模块。
dlopen加载过程:装载,映射,重定位,执行模块的.init段内容
2)dlsym查找符号:输入句柄以及需要查找的符号名。如果符号是个函数或变量返回其地址,如果是常量返回其值。
3)dlerror错误处理:dlopen,dlsym,dlclose调用后如果有错误,使用dlerror返回不是null。
4)dlclose关闭动态库:前面在打开已经打开的动态库会直接返回句柄,同时引用计数+1。所以同样使用dlclose关闭的时候都会引用计数-1,直到为0的时候才真正卸载(先执行.finit段,再取消进程空间映射,最后关闭模块文件)
ps:gcc提供了一组对c/c++的函数属性声明,可以声明共享对象的构造和析构函数,可以分别在
加载(动态装载dlopen返回之前或者一开始装载main执行之前)共享对象和
卸载(动态卸载dlclose返回之前或exit调用时)共享对象时执行。
多个构造(数字越小越早执行)和析构(数字越小越晚执行)函数的执行顺序的优先级设置
这些构造函数和析构函数是在系统默认的标准运行库(c语言运行时库crt)或启动文件里面被运行的。所以必须使用系统默认的标准运行库或启动文件才能有效。
gcc如果使用-nostartfile 和或-nostdlib就会失效。
一般的共享对象不需要进行任何修改就可以进行运行时装载,这种共享对象也叫做动态装载库。
动态装载(显式运行时链接)优点:1)减少程序的启动时间和内存使用 2)使得程序本身不用进行重新启动而实现模块的增加,删除,更新等(比如web服务器,更新脚本解释器,数据库连接驱动等)
Windows装载PE可执行文件
在PE文件中,链接器在生成可执行文件时,会将段尽可能的合并,最后只有代码段、数据段、只读数据段、BSS等为数不多的几个段。
(并不会像elf那样有很多section,最后再合并成segment。)
并且还没有段地址对齐,所有的段的起始地址都是页的整数倍。
每个PE文件在装载的时候都会有一个装载目标地址TargetAddress(也就是所谓的基地址,BaseAddress)
PE文件被设计成可以装载到任何地址,所以这个基地址并不固定,每次装载都有可能不同。RVA RelativeVirtualAddress,相对虚拟地址,表示文件中的偏移量,这个值肯定是不会变化的。
装载过程
1)读取文件的第一个页。PE文件的第一个页:包含DOS头(用来兼容DOS操作系统)+ PE文件头(包含各种说明数据:文件入口,堆栈位置、重定位表)+段表信息(各个段的描述,后续用于装载各个段)。
2)检查进程地址空间的中目标地址是否可用(每个pe文件都有个一个目标地址,也叫基地址)。
3)使用段表中提供的信息,将PE文件的段映射到虚拟地址空间中。
4)(等看了PE文件的内容和Windows下的动态链接部分再加以补充)
5)
6)
7)
注:
|
| 硬盘中(装载前) | 虚拟内存空间(装载后) |
| 称为 | 可执行文件 | 映像文件 |
| 各个段 | 连续存放 | 按页对齐 |
ps:DOS系统中的装载
DOS系统中是通过command.com 命令解释器将可执行文件装入内存中。
command设置cpu的cs:ip指向程序的第一条命令,将cpu的控制权交给他,然后程序退出以后,控制器交回给command
debug可以将程序加载入内存,但是不放弃对cpu的控制,这样就可以利用debug的相关命令来单步执行程序。
创建一个新进程
windows操作系统使用一套标准的流程来创建一个新的进程.
1)在父进程的用户空间中打开要执行的映像文件,确定名字,类型和系统对他的设置。
2)进入父进程的内核空间,为新进程创建EPROCESS结构,进程地址空间,KPROCESS,PEB(即一个进程在内核空间的资源).
3)创建初始线程,但是指定为挂起(suspend)标志,所以它并不会立刻开始运行。
4)通知子系统服务程序。对于windows程序就是windows子系统服务进程,csrss。
5)初始线程开始在内核空间执行.(上面四步都是在父进程或者csrss中完成的)
6)通过apc机制,在新进程自己的用户控件中执行初始化动作,这一步最重要的动作的就是通过ntdll.dll的加载器,加载进程所依赖的dll。
参考:
《程序员的自我修养-链接装载库》第六章
程序的入口函数
在操作系统装载程序后,运行的并不是我们在写的main函数的第一行,而是一些别的代码,执行一些准备工作,只有做了这些准备工作,你才能在main函数中正常的使用申请内存,使用系统调用,触发异常,访问i/o等。
这些代码执行的内容是:
- 1)main函数调用前的准备工作:
环境变量,用户输入参数等的初始化赋值
堆初始化
i/o初始化
线程初始化
全局变量构造
等等
- 2)调用main函数
- 3)main函数调用返回后的收尾工作
调用比如使用atexit注册的函数,全局变量的析构,堆销毁,关闭i/o等,然后结束进程。
这些代码一般都是运行库的一部分,叫做入口函数,下面先介绍一下运行库时库,然后介绍两个运行时库——glibc和msvcrt的入口函数。
C语言标准库和运行时库
不同的机构可以制定不同的标准,且会有版本更新。
C语言标准有ANSI C(版本有C89、C99、C11、C14) 和 ISO C 。
实现了某标准的代码就是标准库。
ANSI C的标准包括的内容24个头文件,具体 P336。
运行时库就是背后支撑某种程序运行的一个庞大的代码集合,运行时库与平台结合的非常紧密——他将不同的操作系统api(系统调用)抽象成同一个库函数,比如我们用可以同一个标准库函数fread来读取文件(最后会介绍)。
一个C语言运行库(C语言运行时库叫CRT)大致包括:

![]()
crt在linux下最常用的是glibc库(GNU C Library,也就是我们常见libc.so.6,之前用的是linux libc库即libc.so.5,已不再维护)和microsoft下最常用的是msvcrt。
当然crt并不是万能,还是有些功能需要你自己真正调用操作系统的api或者其他的库来完成。比如用户的权限控制,操作系统创建线程,网络,图形库这些都不属于标准的c运行时库。
而由于多线程在现在程序设计中占重要的位置,所以主流的c运行时库都会提供多线程相关的部分:1)提供多线程操作的接口 2)运行库本身能在多线程环境下运行——glibc和msvcrt中都包含了线程操作的库函数——glibc中是pthread_create,msvcrt中是_beginthread()。
MSVC CRT
C和C++运行时库 由编译器实现,实现的内容是C标准和C++标准定义了一系列常用的函数(标准只是定义函数原型,编译器来实现)
MSVC CRT的版本
同一个版本的MSVC CRT提供多个字版本,根据不同的属性:
- 静态链接还是动态链接——静态版本,动态版本
- 单线程还是多线程——单线程版本,多线程版本
- 调试还是发布——调试版本,发布版本
- 是否支持C++——纯C运行库版本,支持C++版
- 是否支持托管代码——本地代码/托管代码版本,纯托管代码版本
有些属性可以相互正交:但是有些组合是没有的,比如动态链接的版本,没有单线程的。动态链接的都是多线程的。
以静态和动态为主要的划分标准
静态的库的命名规则:
libc [p:Cplusplus][mt:Multi-Thread 支持多线程][d:debug版本].lib
比如:静态 多线程 纯C 本地代码 调试版本 —— libcmtd.lib
动态的库的每个版本都有对应的两个文件:一个用于链接的lib文件,一个用于运行时的dll动态链接库(会包含版本号)
下面是C语言的标准运行时库

下面是C++的标准运行时库
包含C++的内容,如iostream string map等

VS2010的运行时库的可选择项
(都是多线程了,分调试还是发布,以及动态还是静态)

编译器传递给链接器的信息的段 obj文件中的段:DIRECTIVES段 中指示了需要链接什么库。
一些问答:
- 当一个程序里面的不同obj,使用了不同版本的静态crt的情况会怎么样

- 当一个程序里面的不同obj,使用了不同版本的静态/动态crt混合的情况会怎么样

- 当一个程序里面的dll文件,使用了不同版本的动态crt的情况会怎么样


manifest机制是个啥?看文章https://blog.csdn.net/u012138730/article/details/80938993

MSVC CRT在多线程环境下运行下的改进
1)使用TLS——线程局部存储ThreadLocalStorage实现:
虽然每个线程有自己的栈和当前的寄存器,但是栈在函数调用前后就会被改变,寄存器又少。所以如果想访问一个线程私有的全局变量,方便就是单独设计一个空间作为线程私有的全局数据区。对于MSVC来说,定义的此类型的关键字是
__declspec(thread) int number
定义为TLS的变量会在放在tls段中,当系统启动一个新的线程,就会从进程的堆中分配一块足够的大小的空间,把tls段的内容复制到这块空间中,这样每个线程都有自己独立的tls段副本了。
对于每个windows线程来说,系统都会保存有每个线程的线程环境块TEB,内容有:
1)线程的堆栈地址 2)线程ID 3)TLS数组的地址 等。
对于MSVC 2008来说,TLS数组在TEB中的偏移是0x2C,而TLS数组的第一个元素就是指向该线程的tls段的副本的地址。
例子:定义TLS的变量

代码汇编以后,__tls_index 和 __tls_array 分别是 0 和 0x2C:

例子:标准库中的例子errno:
原来:
现在:
errno在多线程版本中是作为各个线程的私有成员,即设计成TLS类型的变量。

2)增加多线程安全版本的api——strtok---》strtok_s:


3) 函数内部进行加锁
原来:
现在:


glibc的_start和_exit的汇编实现
解析一下比如crt1.o中的入口函数的_start::(具体见 https://blog.csdn.net/u012138730/article/details/82805675)
(上面讲动态链接的时候说过,普通elf可执行文件程序入口_start位于 sysdeps/i386/elf/start.S)

xor ————的作用是让两个操作数异或,结果存储在第一个操作数里。这里即让ebp寄存器清零。如果ebp是0,表明当前是程序的外层。
pop esi ————把栈顶元素弹出存入esi(此时的栈顶元素是argc),所以esi就是argc的值。(操作系统在进程启动前将系统环境变量和进程的运行参数提前保存到虚拟空间的栈中。 https://blog.csdn.net/u012138730/article/details/90273751)
mov esp ecx ————上一步弹出栈顶元素argc以后,此时的栈顶元素就是argv了,把栈顶地址存入ecx,所以ecx就是指向argv和环境变量数组。
虚线是执行pop esi之前的栈顶,实线是执行pop esi以后的栈顶:
(在调用入口函数_start之前,装载器会把用户的参数和环境变量压入栈中,也就是pop esi执行前的栈的样子)

把上述的_start改写成一段可读的伪代码:

而__libc_start_main 的大概内容是:
 传入七个参数,其中rtld_fini是有关动态加载的收尾工作
传入七个参数,其中rtld_fini是有关动态加载的收尾工作
 选的是else中的,上面那个宏已经废弃
选的是else中的,上面那个宏已经废弃
 __environ指向环境变量数组env,upb_ev指向argv(这两个不是指向同个地址么)
__environ指向环境变量数组env,upb_ev指向argv(这两个不是指向同个地址么)
 __cxa_atexit将需要在main后的执行的函数传入。
__cxa_atexit将需要在main后的执行的函数传入。
 exit函数就是执行__cxa_atexit 和 atexit注册的函数
exit函数就是执行__cxa_atexit 和 atexit注册的函数
其中exit函数,除了调用__cxa_atexit和atexit中注册的函数以外,就是调用_exit函数,此函数也是由汇编实现的:

int 80调用exit的系统调用。所以调用_exit以后进程就会结束了。
程序正常结束的两种情况:
1)main函数的正常返回(即上述的流程,__libc_start_main 中main函数返回了,会调用到exit)
2)程序中直接利用exit退出
_start和_exit最后末尾都有hlt指令,这条指令的作用:
1)_exit中的hlt是为了检测int 80系统调用有没有正常执行,如果有的话就不会调用hlt。而如果没有正常执行,调用到了hlt也是把程序强行停止下来。
2)_start中的hlt,调用到说明__libc_start_main 没有正常执行完(比如有人删了__libc_start_main 中的最后exit函数调用)。如果之前没有正常执行,所以最后调用到hlt也是把程序强行停止下来。
msvcrt的mainCRTStartup
以上是glibc的入口函数_start的实现,是用的汇编
以下是msvcrt的入口函数mainCRTStartup的实现,是函数实现:代码比较清晰,不像glibc那么分散,做的事情都差不多


 使用GetVersionExA获取版本信息赋值给各个全局变量
使用GetVersionExA获取版本信息赋值给各个全局变量
 初始化堆,_heap_init应该是调用了HeapCreate这个API去创建堆的。
初始化堆,_heap_init应该是调用了HeapCreate这个API去创建堆的。
 初始化io,获取argv环境变量,c库,调用main
初始化io,获取argv环境变量,c库,调用main
 如异常则错误处理退出
如异常则错误处理退出
ps1:以上的try中调用的main,我们知道win32的调用的WinMain,其实就是根据不同的编译参数编译成了不同的版本。
不同的版本的入口函数会在其中调用不同名字的函数,包括main/wmain/WinMain/wWinMain等。
ps2:io初始化跟文件息息相关p330
ps3:全局构造的相关内容:_initterm函数


I/O相关的部分
I/O的概念
input和output即输入和输出。
对于计算机来说,io代表的就是计算机与外界的交互,交互的对象可以是人或者设备。

对于程序来说,io代表的就是程序与外界的交互。
程序与外界交互的对象可以是磁盘文件,管道,网络,命令行,信号等。
这些交互对象,在许多操作系统,都将这种具有输入输出概念的实体统称为“文件”,这里的“文件”是一个广义的含义。
“文件”有不同的类型。对于任意类型的“文件”,操作系统会提供一组操作函数——打开文件,读文件,写文件,移动文件指针。
那么这些函数操作的背后是会调用操作系统进行操作“文件”对象的。在操作系统层面,有一个操作文件的概念——Linux叫文件描述符FileDescriptor,Windows下叫句柄Handle。
比如某函数打开文件获得返回的句柄或者文件描述符,以后用户操作文件都通过该句柄或文件描述符完成。
而句柄或文件描述符的背后,是系统内核的文件对象,系统内核可以用过句柄或文件描述符计算出内核中文件对象的地址。
比如在Linux中,文件描述符fd为0,1,2的分别是标准输入,标准输出,标准错误输出。在程序中打开的文件的文件描述符从3开始。
在编程语言C来说,是通过一个FILE结构的指针来进行文件操作的,比如如下的fopen是打开文件,fwrite是写文件,fclose关闭文件:

当进程打开一个“文件”,内核就会在内部生成一个“打开文件对象”,并在进程的私有的“打开文件表”中找到一个空项,让这一项指向内核中生成的打开文件对象,并返回这一项的下标作为fd。FILE结构中必定有个fd的概念(应该就是_file),每个FILE都会记录自己唯一对应的fd。
(下面图中fd等于0 1 2项就是指向的标准输入,标准输出,标准错误输出,stdin,stdout,stderr均是FILE结构的指针。)。
这个“打开文件表”在内核中,用户无法访问也无法得到“打开文件对象”的地址,用户只知道fd,只能通过fd,只能通过调用系统函数来操作文件。

上表中的11-4是Linux下的。Windows下的如下图:

可以看到,跟linux的不同,windows在用户空间,也有“打开文件表”,叫用户态的“打开文件表”,图中画的不是很好。其实这是一个二维的“打开文件表”,通过_file字段(_file的第5-10位表示第一维坐标,0-4位表示第二维坐标)可以定位到其中的一项,然后通过这一项的内容(即打开文件的句柄)对应到内核中的“打开文件表”的某一项。
用户态的“打开文件表”结构__pioinfo数组:

其中ioinfo的结构如下:osfhnd就是句柄,通过这个找到内核中的“打开文件表”的某一项;osfile是文件的打开属性,pipech是用于管道的单字符缓冲。

osfile:

![]()
FILE结构中_file(FILE结构没有定义在C语言标准中,所以可能有不同的实现):

I/O初始化
io初始化函数就是在用户空间建立标准输入,标准输出,标准错误输出以及对应的文件结构。
对于C来说就是,stdin,stdout,stderr以及对应的FILE结构,使用进入main函数以后就可以使用printf,scanf等输入输出函数了。
对于windows下的io来说,就是初始化用户态的“打开文件表”——__pioinfo[64],然后将预定的一些打开文件给初始化——比如继承日父进程的句柄,标准输入输出句柄。
在msvcrt的入口函数中,我们看到io初始化是调用的_ioinit()函数(上文有),_ioinit函数的内容就是具体的具体的io初始化的实现细节:p332
 1)初始化第一维,设置个数为32个。
1)初始化第一维,设置个数为32个。
 2)获取继承句柄个数和信息数组
2)获取继承句柄个数和信息数组
![]() 3)句柄个数不超过“打开文件表”的大小
3)句柄个数不超过“打开文件表”的大小
 4)个数>32,则初始化第二维,依次
4)个数>32,则初始化第二维,依次
 5)将继承的合法的句柄复制过来
5)将继承的合法的句柄复制过来
 6)输入输出句柄初始化(如果未继承)
6)输入输出句柄初始化(如果未继承)
IO函数fread的实现
C语言标准库函数fread到WindowsAPI ReadFile的调用轨迹:_read函数中才会去调用ReadFile系统调用。但是_fread_nolock_s函数并不一定会调用到_read,因为有缓冲的存在。如果缓冲区中的未读的字节数已经小于的需要读取的数据就可以不调用了。否则就需要进行调用到系统调用ReadFile了(没用完的把缓冲区填满)

fread的签名: 尝试从文件流stream中读取count个大小为elementSize的数据,存储到buffer中
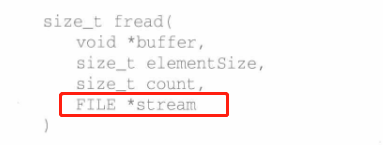
其中第四个数据成员,用FILE结构表示的文件流stream,这个不一定要真正打开文件,有可能是从缓冲区读取数据。
FILE结构中有关缓冲的各个变量的含义有:
- _ptr指向缓冲中第一个未读的字节
- _cnt缓冲中剩余未读的字节数。如果=0,说明缓冲已经为空了,需要再次flush进来了。
- _base指向一个字符数组,即文件的缓冲
- _flag所打开的文件的一些属性:

- _file上面讲过 用来对应找到内核中的文件对象
- _charbuf看_flag的_IONBF,就是某种情况下的缓冲区。
- _bufsize这个缓冲的大小,如果是0,就说明这个文件没有使用缓冲