一、线程和进程介绍
1.1、进程基本概念
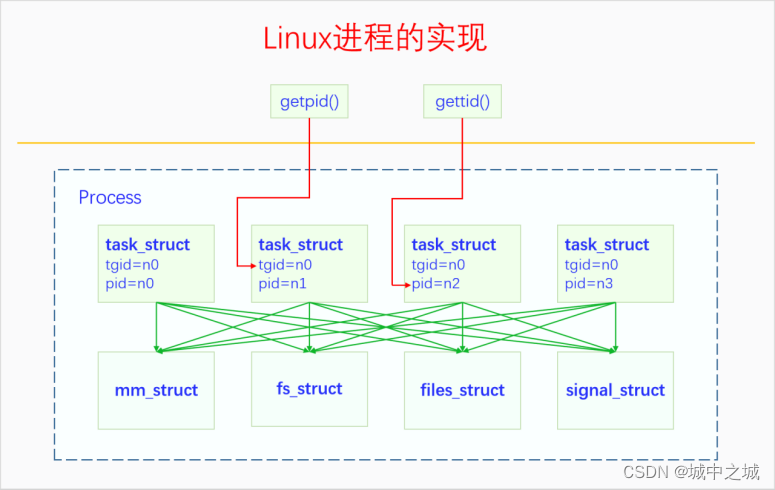
进程(Process),是计算机中已运行程序的实体,曾经是分时系统的基本运作单位。在面向进程设计的系统(如早期的Unix、Linux2.4及更早的版本)中,进程是程序的基本执行实体;在面向线程设计的系统(如当代多数操作系统、Linux2.6及更新的版本)中,进程本身不是基本运行单位,而是线程的容器。程序只是指令、数据及其组织形式的描述,进程才是程序(哪些指令和数据)的真正运行实例。
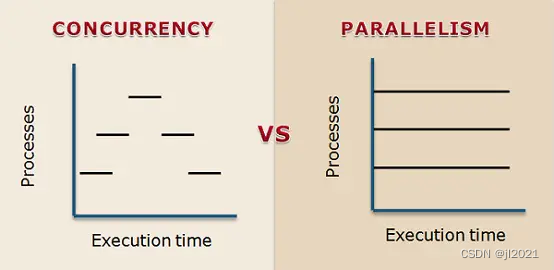
若干进程有可能与同一程序有关系,且每个进程皆可以同步(循序)或异步(平行)的方式独立运行。现代计算机系统可在同一段时间以进程的形式将多个程序加载到存储器中,并借由时间共享(或称时分复用)在一个处理器上表现出同时(平行性)运行的感觉。同样地,使用多线程技术(多线程即每一个线程都代表一个进程内的一个独立执行上下文)的操作系统或计算机体系结构,同样程序的平行线程可在多CPU主机或网络上真正同时运行(在不同的CPU上)。
1.2、线程基本概念
线程(Thread)是操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运作单位。一个线程指的是进程中一个单一顺序的控制流,一个进程可以并发多个线程,每个线程并行执行不同的任务。线程在Unix System V及SunOS中也被称为轻量进程,但“轻量进程”更多值内核线程,而用户线程则被称为“线程”。
线程是独立调度和分派的基本单位,可以分为:(1)操作系统内核调度的内核线程,如Win32线程;(2)由用户进程自行调度的用户线程,如Linux平台的POSIX Thread;(3)有内核与用户进程进行混合调度,如Windows 7线程。
同一进程中的多个线程将共享进程中的全部系统资源,如虚拟地址空间、文件描述符和信号处理等。但同一进程中的多个线程有各自的调用栈(Call Stack)、各自的寄存器环境(Register Context)、各自的线程本地存储(Thread-Local Storage)。
1.3、多线程基本概念
多线程(Multithreading)是指在软件或硬件上实现多个线程并发执行的技术。具有多线程能力的计算机因有硬件支持而能够在同一时间执行多个线程,进而提升整体处理性能。具有这种能力的系统包括对称处理机、多核心处理器以及芯片级多处理或同事多线程处理器。
软件多线程是说即便处理器只能运行一个线程,操作系统也可以快递地在不同线程之间进行切换,由于时间间隔很小,给用户造成一种多个线程在同时运行的假象。这样的程序运行机制被称为软件多线程,比如微软的Windows和Linux系统就是在各个不同的执行绪间来回切换,被称为单人多任务作业系统。而DOS这类文字接口作业系统在一个时间只能处理一项工作,被视为单人单工作业系统。
1.4、Python与全局解释器锁
全局解释器锁(Global Interpreter Lock,简称GIL)是计算机程序设计语言解释器用于同步线程的工具,保证任何时刻仅有一个线程在执行。
首先要申名的是,全局解释器锁并不是Python语言的特性,全局解释器是为了实现Python解释器(主要是CPython,最流行的Python解释器)而引入的概念,并不是所有Python解释器都有全局解释器锁。Jython和IronPython没有全局解释器锁,可以完全利用多处理器系统。PyPy和CPython都有全局解释器锁。
CPython的线程是操作系统的原生线程,完全由操作系统调度线程的执行。一个CPython解释器进程内有一个主线程以及多个用户程序的执行线程。即使使用多核心CPU平台,由于全局解释器锁的存在,也将禁止多线程的并行执行,这样会损失许多多线程的性能。
在CPython中,全局解释器锁是一个互斥锁,用于保护对Python对象的访问,防止多条线程同时执行Python字节码。这种锁是必要的,主要是因为CPython的内存管理不是线程安全的。
在多线程环境中,CPython虚拟机按以下方式执行:
(1)设置全局解释器锁;
(2)切换到一个线程中去运行;
(3)运行;
① 指定数量的字节码指令;
② 线程主动让出控制[可以调用time.sleep(0)];
(4)把线程设置为睡眠状态;
(5)解锁全局解释器锁;
(6)再次重复以上所有步骤;
在调用外部代码(如C/C++扩展函数)的时候,全局解释器锁将会被锁定,直到这个函数结束为止(因为这期间没有Python的字节码被运行,所以不会做线程切换)。
二、Python线程模块
Python标准库中关于线程的主要是_thread模块和threading模块。
2.1、_thread模块
标准库中的_thread模块作为低级别的模块存在,一般不建议直接使用,但在某些简单的场合也是可以使用的,因为_thread模块的使用方法十分简单。
标准库_thread模块的核心其实就是start_new_thread方法:
_thread.start_new_thread(function,args[,kwargs])
启动一个新线程并返回其标识符,线程使用参数列表args(必须是元组)执行函数,可选的kwargs参数指定关键字参数的字典。当函数返回时,线程将以静默方式退出。当函数以未处理的异常终止是,将打印堆栈跟踪,然后线程退出(但其他线程继续运行)。
import time
import datetime
import _threaddate_time_format = "%H:%M:%S"def get_time_str():now = datetime.datetime.now()return datetime.datetime.strftime(now,date_time_format)def thread_function(thread_id):print("Thread %d\t start at %s" % (thread_id,get_time_str()))print("Thread %d\t sleeping" % thread_id)time.sleep(4)print("Thread %d\t finish at %s" % (thread_id,get_time_str()))def main():print("Main thread start at %s" % get_time_str())for i in range(5):_thread.start_new_thread(thread_function,(i,))time.sleep(1)time.sleep(6)print("Main thread finish at %s" % get_time_str())if __name__ == "__main__":main()
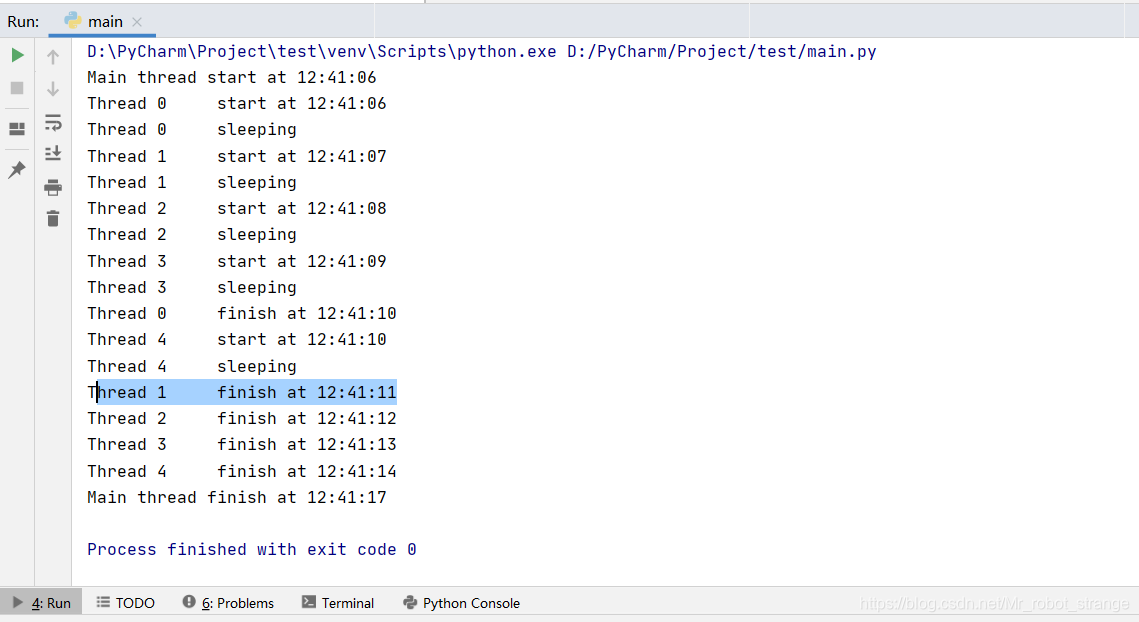
主线程过早或者过晚的退出都不是我们所期望的这时候就需要使用线程锁,主线程可以在其他线程执行完之后立即退出。
_thread.allocate_lock()方法返回一个Lock对象。Lock对象有三个常用的方法:
| 方法 | 作用 |
|---|---|
| acquire | 用于无条件地获取锁定Lock对象,如果有必要,等待它被另一线程释放(一次只有一个线程可以获取锁定) |
| release | 用于释放锁,释放之前必须先锁定,可以不在同一线程中释放锁 |
| locked | 用于返回锁的装填,如果已被某个线程锁定,则返回True,否则返回False |
import time
import datetime
import _threaddate_time_format = "%H:%M:%S"def get_time_str():now = datetime.datetime.now()return datetime.datetime.strftime(now,date_time_format)def thread_function(thread_id,lock):print("Thread %d\t start at %s" % (thread_id,get_time_str()))print("Thread %d\t sleeping" % thread_id)time.sleep(4)print("Thread %d\t finish at %s" % (thread_id,get_time_str()))lock.release()def main():print("Main thread start at %s" % get_time_str())locks = []for i in range(5):lock = _thread.allocate_lock()lock.acquire()locks.append(lock)for i in range(5):_thread.start_new_thread(thread_function,(i,locks[i]))time.sleep(1)for i in range(5):while locks[i].locked():time.sleep(1)print("Main thread finish at %s" % get_time_str())if __name__ == "__main__":main()
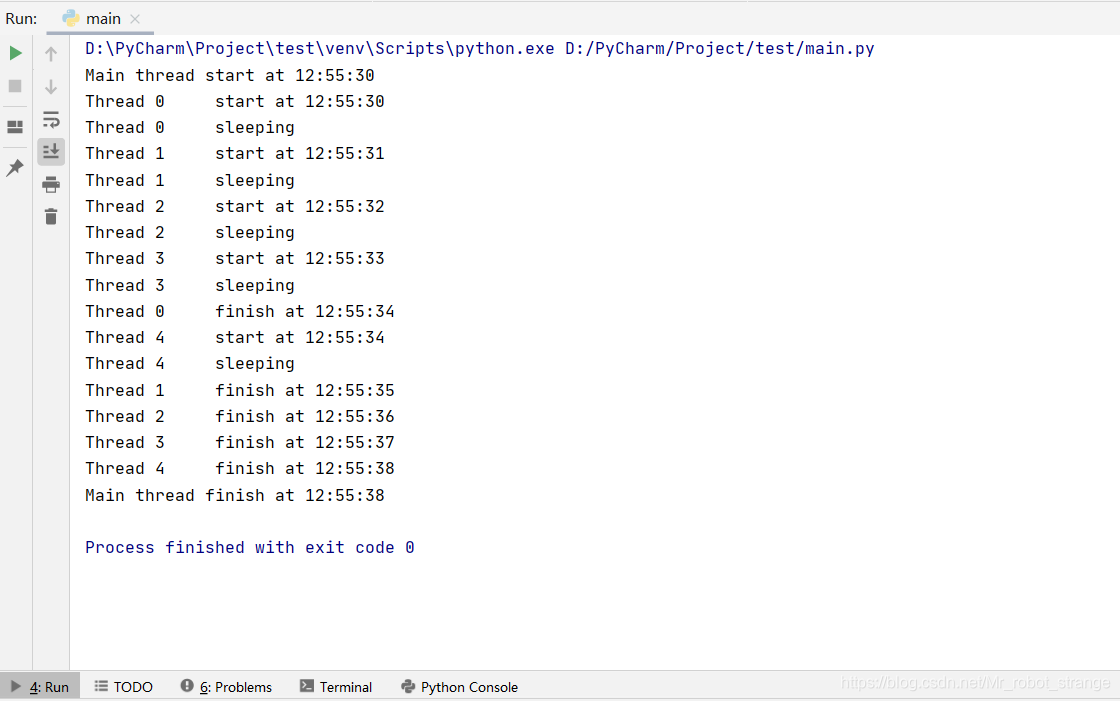
2.2、Threading.Thread
Python标准库不仅提供了_thread这样的底层线程模块,还提供了threading模块。threading模块不仅提供了面向对象的线程实现方式,还提供了各种有用的对象和方法方便我们创建和控制线程。
使用threading模块创建线程很方便,大部分操作都是围绕threading.Thread类来实现的。直接使用threading.Thread类也可以像_thread模块中的start_new_thread一样方便。
import time
import datetime
import threadingdate_time_format = "%H:%M:%S"def get_time_str():now = datetime.datetime.now()return datetime.datetime.strftime(now,date_time_format)def thread_function(thread_id):print("Thread %d\t start at %s" % (thread_id,get_time_str()))print("Thread %d\t sleeping" % thread_id)time.sleep(4)print("Thread %d\t finish at %s" % (thread_id,get_time_str()))def main():print("Main thread start at %s" % get_time_str())threads = []#创建线程for i in range(5):thread = threading.Thread(target=thread_function,args=(i,))threads.append(thread)#启动线程for i in range(5):threads[i].start()time.sleep(1)#等待线程执行完毕for i in range(5):threads[i].join()print("Main thread finish at %s" % get_time_str())print("Main thread finish at %s" % get_time_str())if __name__ == "__main__":main()
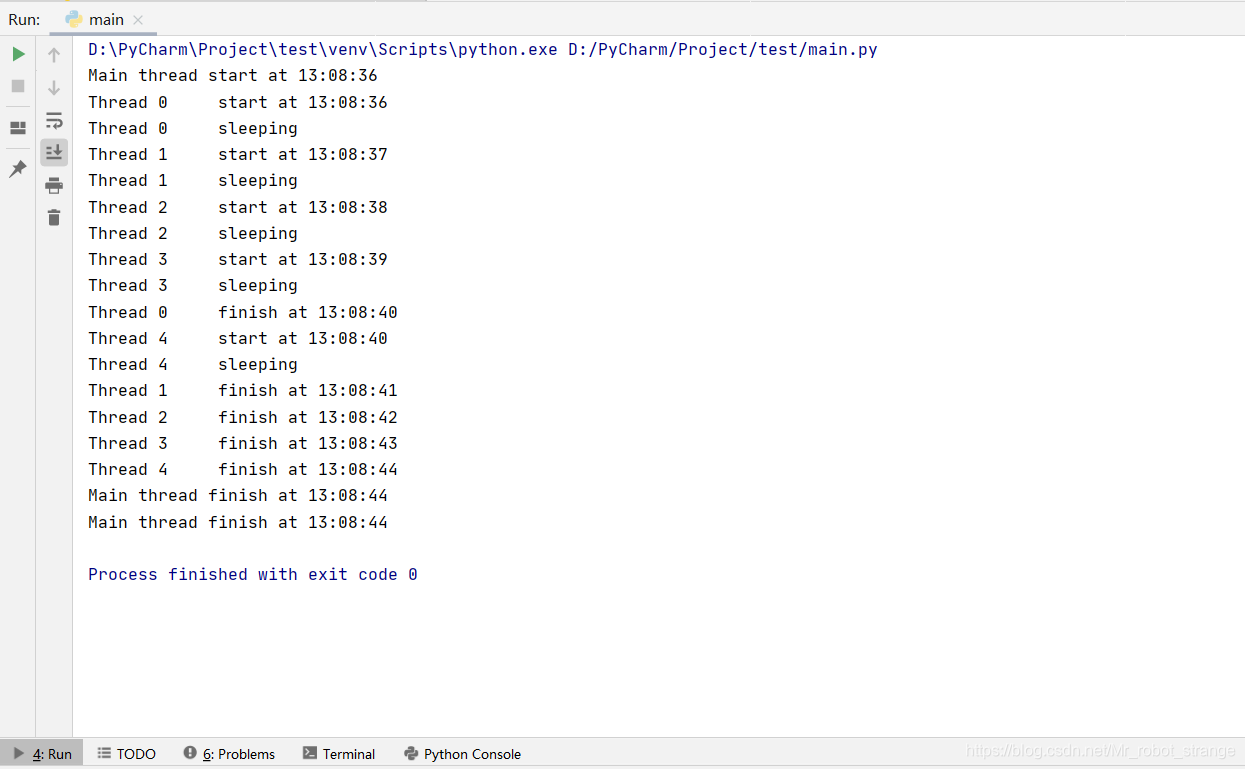
从执行结果可以看出,使用threading.Thread可以实现和_thread模块ongoing的线程一样的效果,并且还不需要我们手动地操作线程锁。threading.Thread对象实例化之后不会立即执行线程,只会创建一个实例,之后需要调用start()方法,才真正地启动线程。最后调用join()方法来等待线程的结束,使用threading.Thread对象可以自动地帮助我们管理线程锁(创建锁、分配锁、获得锁、释放锁和检测锁等步骤)。
还有一个常见的方法就是可以从threading.Thread派生一个子类,在这个子类中调用父类的构造函数并实现run方法即可,例如:
import time
import datetime
import threadingdate_time_format = "%H:%M:%S"def get_time_str():now = datetime.datetime.now()return datetime.datetime.strftime(now,date_time_format)class MyThread(threading.Thread):def __init__(self,thread_id):super(MyThread,self).__init__()self.thread_id = thread_iddef run(self):print("Thread %d\t start at %s" % (self.thread_id,get_time_str()))print("Thread %d\t sleeping" % self.thread_id)time.sleep(4)print("Thread %d\t finish at %s" % (self.thread_id,get_time_str()))def main():print("Main thread start at %s" % get_time_str())threads = []#创建线程for i in range(5):thread = MyThread(i)threads.append(thread)#启动线程for i in range(5):threads[i].start()time.sleep(1)#等待线程执行完毕for i in range(5):threads[i].join()print("Main thread finish at %s" % get_time_str())if __name__ == "__main__":main()
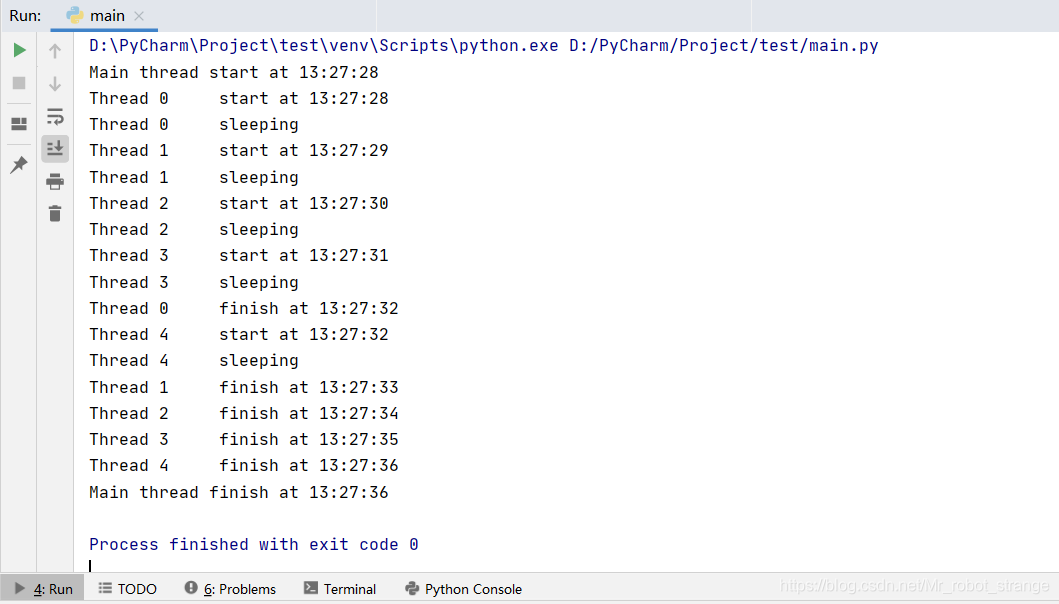
上述例子中,我们先定义了threading.Thread的子类MyThread。在MyThread子类的构造函数中一定要先调用父类的构造函数,然后要实现run方法。在创建线程之后我们就可以调用start方法来启动线程了,调用内部启动方法之后再调用我们实现的run方法(其实start方法创建线程调用的也是_thread.start_new_thread方法)。
2.3、线程同步
标准库threading中有Lock对象可以实现简单的线程同步(threading.Lock其实调用的就是_thread.allocate_lock对象)。多线程的优势在于可以同时运行多个任务,但是当线程需要处理同一个资源时,就需要考虑数据不同步的问题了。
import time
import threadingthread_lock = Noneclass MyThread(threading.Thread):def __init__(self,thread_id):super(MyThread,self).__init__()self.thread_id = thread_iddef run(self):#锁定thread_lock.acquire()for i in range(3):print("Thread %d\t printing! times: %d" % (self.thread_id,i))#释放thread_lock.release()time.sleep(1)#锁定thread_lock.acquire()for i in range(3):print("Thread %d\t printing! times: %d" % (self.thread_id, i))# 释放thread_lock.release()def main():print("Main thread start")threads = []#创建线程for i in range(5):thread = MyThread(i)threads.append(thread)#启动线程for i in range(5):threads[i].start()#等待线程执行完毕for i in range(5):threads[i].join()print("Main thread finish")if __name__ == "__main__":#获取锁thread_lock = threading.Lock()main()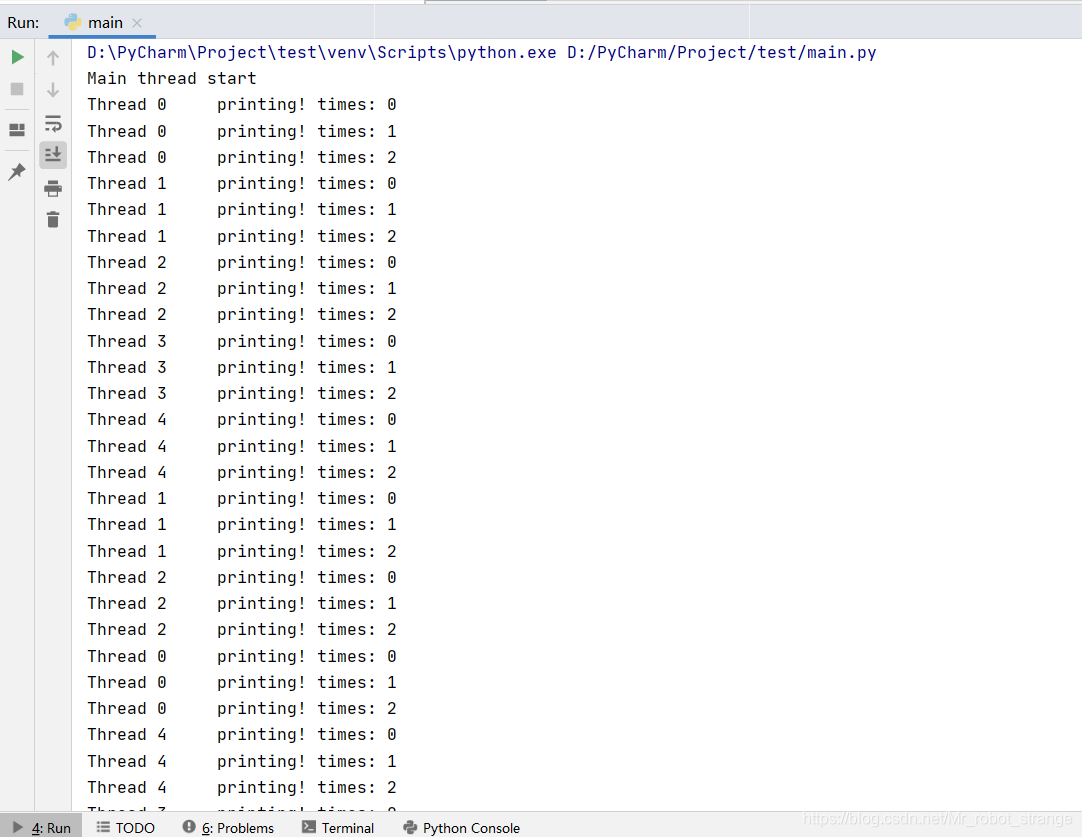
从执行结果中可以看到,加了锁之后的线程不再像之前的例子那么不可控制了,每次执行都会得到相同的结果,并且例子中的五个线程是同时在执行的。当子线程运行到thread_lock.acquire()的时候,程序胡判断thread_lock是否处于锁定转态,如果是锁定状态,线程就会在这一行阻塞,直到被释放为止。
2.4、队列
在线程之间传递、共享数据是常有的事情,我们可以使用共享变量来实现相应的功能。使用共享变量在线程之间传递信息或数据时需要我们手动控制锁(锁定、释放等),标准库提供了一个非常有用的Queue模块,可以帮助我们自动地控制锁,保证数据同步。
Python的Queue模块提供了一种适用于多线编程的先进先出(FIFO)实现,它可用于生产者和消费者之间线程安全地传递消息或其他数据,因此多个线程可以共用一个Queue实例。Queue的大小(元素的个数)可用来限制内存的使用。
Queue类实现了一个基本的先进先出容器,使用put()将元素添加到序列尾端,使用get()从队列尾部移除元素。
from queue import Queueq = Queue()for i in range(5):q.put(i)while not q.empty():print(q.get())
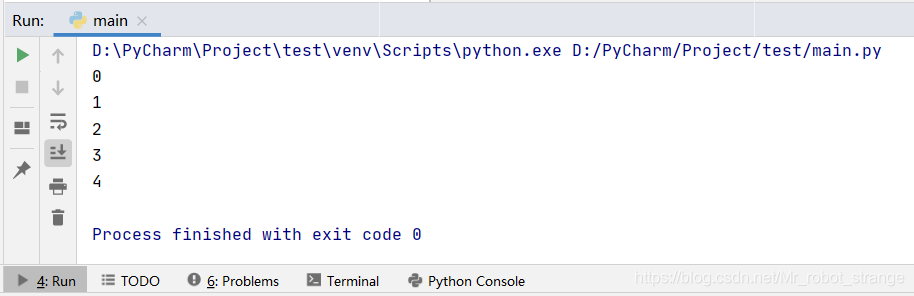
Queue模块并不是一定要使用多线程才能使用,这个例子使用单线程演示了元素以插入顺序从队列中移除。
import time
import threading
import queue#创建工作队列并且限制队列的最大元素是10个
work_queue = queue.Queue(maxsize=10)#创建结果队列并且限制队列的最大元素是10个
result_queue = queue.Queue(maxsize=10)class WorkerThread(threading.Thread):def __init__(self,thread_id):super(WorkerThread, self).__init__()self.thread_id = thread_iddef run(self):while not work_queue.empty():#从工作队列获取数据work = work_queue.get()#模拟工作耗时3秒time.sleep(3)out = "Thread %d\t received %s" % (self.thread_id,work)#把结果放入结果队列result_queue.put(out)def main():#工作队列放入数据for i in range(10):work_queue.put("message id %d" % i)#开启两个工作线程for i in range(2):thread = WorkerThread(i)thread.start()#输出十个结果for i in range(10):result = result_queue.get()print(result)if __name__ == "__main__":main()
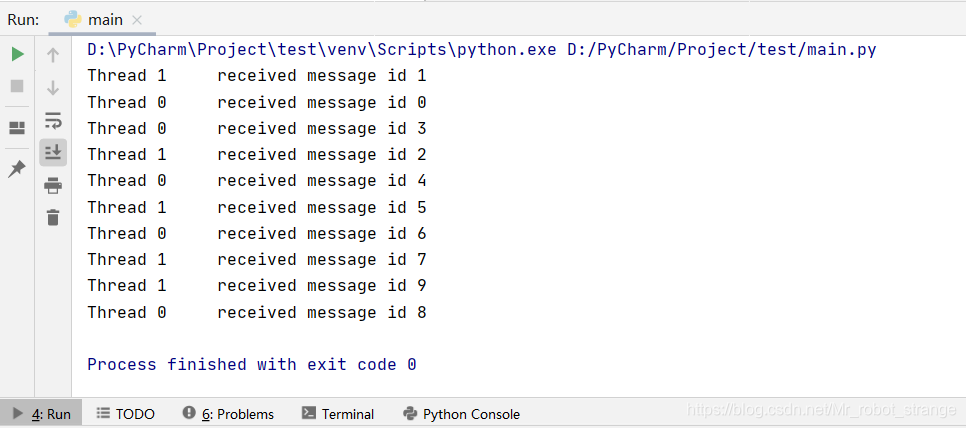
多线程使用Queue模块也不需要多余的锁操作,因为queue.Queue对象已经在执行方法的时候帮助我们自动调用threading.Lock来实现锁的使用了。标准库queue模块不止有Queue一种队列,还有LifoQueue和PriorityQueue等功能复杂的队列。
三、Python进程模块
3.1、OS模块
调用system函数是最简单的创建进程的方式,函数只有一个参数,就是要执行的命令。
import os#判断是否是windows
if os.name == "nt":return_code = os.system("dir")
else:return_code = os.system("ls")#判断命令返回值是0,0代表运行成功
if return_code == 0:print("Run success!")
else:print("Something wrong!")

这个例子会根据不同的操作系统调用不同的命令,结果都是输出当前目录的文件和文件夹。os.ststem函数会返回调用的命令的返回值,0代表运行成功。
比os.system函数更复杂一点的是exec系列函数,os.exec系列函数一共有八个,它们的定义分别是:
os.execl(path,arg0,arg1,...)
os.execle(path,arg0,arg1,...env)
os.execlp(file,path,arg0,arg1,...)
os.execlpe(file,path,arg0,arg1,...,env)
os.execv(path,args)
os.execve(path,args,env)
os.execvp(file,args)
os.execvpe(file,args,env)
os.fork()函数调用系统API并创建子进程,但是fork函数在Windows上并不存在,在Linux和Mac可以成功使用。
import osprint("Main Process ID (%s)" % os.getpid())
pid = os.fork()
if pid == 0:print("This is child process (%s) and main process is %s" % (os.getpid(),os.getppid()))
else:print("Created a child process (%s)" % (pid,))
3.2、subprocess模块
标准库os中的system函数和exec系统函数虽然都可以调用外部命令(调用外部命令也是创建进程的一种方式),但是使用方式比较简单,而标准库的subprocess模块则提供了更多和调用外部命令相关的方法。
大部分subprocess模块调用外部命令的函数都使用类似的参数,其中args是必传的参数,其他都是可选参数:
- args:可以是字符串或者序列类型(如:list、tuple)。默认要执行的程序应该是序列的第一个字段,如果是单个字符串,它的解析依赖于平台。在Unix系统中,如果args是一个字符串,那么这个字符串会解释成被执行程序的名字或路径,然而这种情况只能用在不需要参数的程序上。
- bufsieze:指定缓冲。0表示无缓冲,1表示缓冲,其他的任何整数值表示缓冲大小,负数值表示使用系统默认缓冲,通常表示完全缓冲,默认值为0即没有缓冲。
- stdin,stdout,stderr:分别表示程序的标准输入、输出、错误句柄。
- preexec_fn:只在Unix平台有效,用于指定一个可执行对象,它将在子进程运行之前被调用。
- close_fds:在Windows平台下,如果close_fds被设置为True,则新创建的子进程将不会继承父进程的输入、输出与错误管道,所以不能将close_fds设置为True,同时重定向子进程的标准输入、输出与错误。
- shell:默认值为False,声明了是否使用shell来执行程序;如果shell=True,它将args看做是一个字符串,而不是一个序列。在Unix系统中shell=True,shell默认使用/bin/sh。
- cwd:用于设置子进程的当前目录。当它不为None时,子进程在执行前,它的当前路径会被替换成cwd的值。这个路径并不会被添加到可执行程序的搜索路径中,所以cwd不能是相对路径。
- env:用于指定子进程的环境变量。如果env=None,子进程的环境变量将从父进程继承。当它不为None时,它是新进程的环境变量的映射,可以用它来代替当前进程的环境。
- universal_newlines:不同系统的换行符不同,文件对象stdout和stderr都被以文件的方式打开。
- startipinfo与creationflags只在Windows下生效,将被传递给底层的CreateProcess函数,用于设置子进程的一些属性,如主窗口的外观、进程的优先级等等。
- subprocess.call函数和os.system函数有点类似。subprocess.call函数接收参数运行命令并返回命令的退出码(退出码为0表示运行成功)。
import os
import subprocess#判断是否是Windows
if os.name == "nt":return_code = subprocess.call(["cwd","/C","dir"])
else:return_code = subprocess.call(["ls","-l"])if return_code == 0:print("Run success!")
else:print("Something wrong!")
subprocess.check_call方法和subprocess.call方法基本相同,只是如果执行的外部程序返回码不是0,就会抛出CalledProcessError异常(check_call其实就是再封装了一层call函数)。
import os
import subprocesstry:# 判断是否是Windowsif os.name == "nt":return_code = subprocess.check_call(["cwd", "/C", "dir"])else:return_code = subprocess.check_call(["ls", "-l"])
except subprocess.CalledProcessError as e:print("Something wrong!",e)if return_code == 0:print("Run success!")
else:print("Something wrong!")
subprocess.Popen对象提供了功能更丰富的方式来调用外部命令,subprocess.call和subprocess.check_call其实调用的都是Popen对象,再进行封装。
import os
import subprocessif os.name == "nt":ping = subprocess.Popen("ping -n 5 www.baidu.com",shell=True,stdout=subprocess.PIPE)
else:ping = subprocess.Popen("ping -c 5 www.baidu.com",shell=True,stdout=subprocess.PIPE)#等待命令执行完毕
ping.wait()#打印外部命令的进程id
print(ping.pid)#打印外部命令的返回码
print(ping.returncode)#打印外部命令的输出内容
output = ping.stdout.read()
print(output)
3.3、multiprocessing.Process
标准库multiprocessing模块提供了和线程模块threading类似的API来实现多进程。multiprocess模块创建的是子进程而不是子线程,所以可以有效地避免全局解释器锁和有效地利用多核CPU的性能。
mulprocessing.Process对象和threading.Thread的使用方法大致一样,例如:
from multiprocessing import Process
import osdef info(title):print(title)print("module name: ",__name__)print("parent process: ",os.getppid())print("process id: ",os.getpid())def f(name):info("function f")print("Hello",name)if __name__ == "__main__":info("main line")p = Process(target=f,args=("人生苦短",))p.start()p.join()
使用target参数指定要执行的函数,使用args参数传递元组来作为函数的参数传递。multiprocessing.Process使用起来和threading.Thread没什么区别,甚至也可以写一个子类从父类multiprocessing.Process派生并实现run方法。例如:
from multiprocessing import Process
import osclass MyProcess(Process):def __init__(self):super(MyProcess,self).__init__()def run(self):print("module name: ", __name__)print("parent process: ", os.getppid())print("process id: ", os.getpid())def main():processes = []#创建进程for i in range(5):processes.append(MyProcess())#启动进程for i in range(5):processes[i].start()#等待进程结束for i in range(5):processes[i].join()if __name__ == "__main__":main()
注意:在Unix平台上,在某个进程终结之后,该进程需要被其父进程调用wait,否则进程将成为僵尸进程。所以,有必要对每个Process对象调用join()方法(实际上等同于wait)。
在multiprocessing模块中有个Queue对象,使用方法和多线程中的Queue对象一样,区别是多线程的Queue对象是线程安全的,无法在进程间通信,而multiprocessing.Queue是可以在进程间通信的。
使用multiprocessing.Queue可以帮助我们实现进程同步:
from multiprocessing import Process,Queue
import os#创建队列
result_queue = Queue()class MyProcess(Process):def __init__(self,q):super(MyProcess,self).__init__()#获取队列self.q = qdef run(self):output = "module name %s\n" % __name__output += "parent process: %d\n" % os.getppid()output += "parent id: %d" % os.getpid()self.q.put(output)def main():processes = []#创建进程并把队列传递给进程for i in range(5):processes.append(MyProcess(result_queue))#启动进程for i in range(5):processes[i].start()#等待进程结束for i in range(5):processes[i].join()while not result_queue.empty():output = result_queue.get()print(output)if __name__ == "__main__":main()
注意:线程之间可以共享变量,但是进程之间不会共享变量。所以在多进程使用Queue对象的时候,虽然multiprocessing.Queue的方法和quequ.Queue方法一模一样,但是在创建进程的时候需要把Queue对象传递给进程,这样才能正确地让主进程获取子进程的数据,否则主进程的Queue内一直都是空的。
四、进程池与线程池
4.1、进程池
在利用Python进行系统管理,特别是同时操作多个文件目录或者远程控制多台主机的时候,并行操作可以节省大量的时间。当被操作对象数目不打死,可以直接利用multiprocessing中的Process动态生成多个进程。十几个还好,但如果是上百个、上千个目标,手动限制进程数量便显得太过烦琐,这时候进程池(Pool)就可以发挥功效了。
Pool可以提供指定数量的进程供用户调用,当有新的请求提交到Pool中时,如果池还没有满,就可以创建一个新的进程来执行该请求;但如果池中的进程数已经达到规定最大值,那么该请求就会等待,直到池中有进程结束,才会创建新的进程来执行它。
import multiprocessing
import timedef process_func(process_id):print("process id %d" %process_id)time.sleep(3)print("process id %d end" % process_id)def main():pool = multiprocessing.Pool(processes=3)for i in range(10):#向进程池中添加要执行的任务pool.apply_async(process_func,args=(i,))#先调用close关闭进程池,不能再有新任务被加入到进程池中pool.close()#join函数等待子进程结束pool.join()if __name__ == "__main__":main()
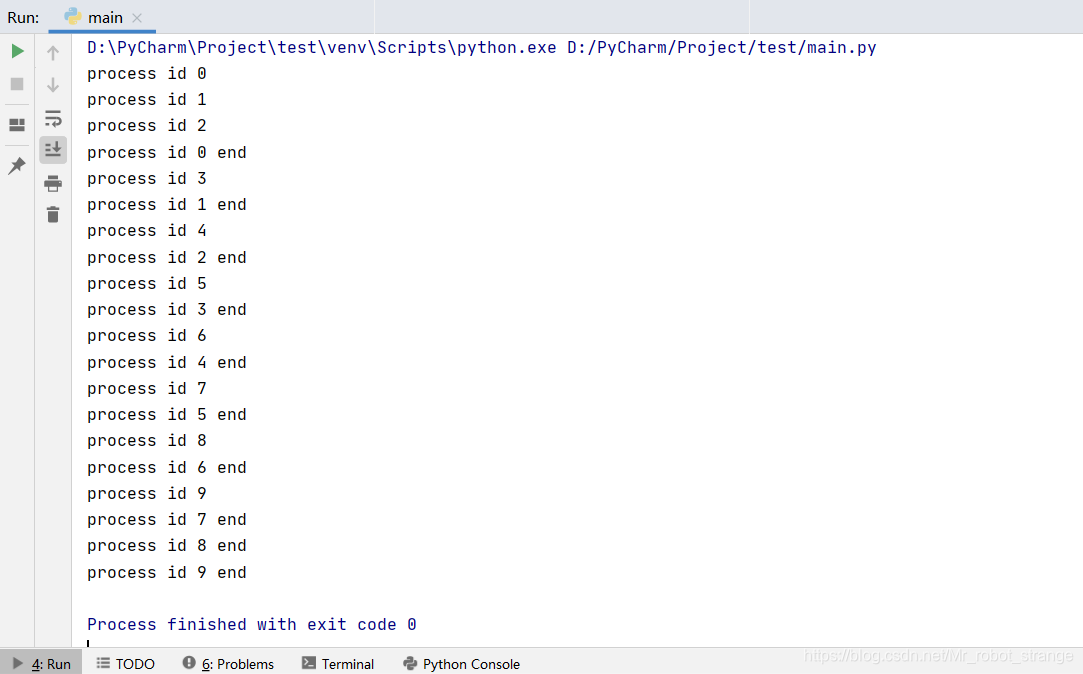
如果每次调用的都是同一个函数,还可以使用Pool的map函数。map方法的第一个参数是要执行的函数,第二个参数必须是可迭代对象。map方法会帮助我们迭代第二个参数,并把迭代出的元素作为参数分批传递给第一个要执行的函数并执行。例如:
import multiprocessing
import timedef process_func(process_id):print("process id %d" %process_id)time.sleep(3)print("process id %d end" % process_id)def main():pool = multiprocessing.Pool(processes=3)pool.map(process_func,range(10))#先调用close关闭进程池,不能再有新任务被加入到进程池中pool.close()#join函数等待子进程结束pool.join()if __name__ == "__main__":main()
4.2、线程池
multiprocessing模块中有个multiprocessing.dummy模块。multiprocessing.dummy模块复制了multiprocessing模块的API,只不过它提供的不再是适用于多进程的方法,而是应用在多线程上的方法。但多线程实现线程池的方法和多进程实现进程池的方法一模一样:
import multiprocessing.dummy
import timedef process_func(process_id):print("process id %d" %process_id)time.sleep(3)print("process id %d end" % process_id)def main():pool = multiprocessing.dummy.Pool(processes=3)for i in range(10):#向线程池中添加要执行的任务pool.apply_async(process_func,args=(i,))#先调用close关闭进程池,不能再有新任务被加入到线程池中pool.close()#join函数等待子线程结束pool.join()if __name__ == "__main__":main()
Pool的map的使用方法也是一样的:
import multiprocessing.dummy
import timedef process_func(process_id):print("process id %d" %process_id)time.sleep(3)print("process id %d end" % process_id)def main():pool = multiprocessing.dummy.Pool(processes=3)pool.map(process_func,range(10))#先调用close关闭进程池,不能再有新任务被加入到线程池中pool.close()#join函数等待子线程结束pool.join()if __name__ == "__main__":main()








![BUUCTF Web [GXYCTF2019]Ping Ping Ping](https://img-blog.csdnimg.cn/968a0da5dd5b4e02b3fcf59e1f7e7667.png)
![[GXYCTF 2019]Ping Ping Ping](https://img-blog.csdnimg.cn/0d839c18004b4af0a56f496b4d68c3c7.png)
![[GXYCTF2019]Ping Ping Ping(命令执行)](https://img-blog.csdnimg.cn/d49506efe9764a19a069f4dc37f3224c.png)
![CTF_Web_[GXYCTF2019]Ping Ping Ping](https://img-blog.csdnimg.cn/05cb9320eb954ef3b8ddffd299d650bf.png)