一、C语言学习心得记录
函数递归
编写顺序
- 终结条件
- 输入下一级递归参数,调用下一级递归函数.
- 当前递归函数的操作代码,在下一级递归函数执行完成后执行的操作代码.
#include <stdio.h>
#include <string.h>void revert(char *s, int len)
{// 终结条件if(len <= 1)return;// 1,将中间部分翻转revert(s+1, len-2);// 2,调换首尾两个字符char tmp;tmp = s[0];s[0] = s[len-1];s[len-1] = tmp;
}int main(void)
{char s[] = "abcdefg";// 翻转revert(s, strlen(s));printf("%s\n", s);
}
函数参数之数组指针传入
知识点:
任何数组名,都可能有两个含义:例如 int a[3]; 1,代表整块数组:
a. 在定义语句中的时候: int a[3];
b. 在取址的时候:&a;
c. 在使用 sizeof 计算内存大小的时候:printf(“%d\n”, sizeof(a)); 2,除了上述情况之外,其他任何情况都代表首元素的地址
注意: 当数组作为函数参数传递的时候,表示是指针,不能用sizeof(名称),求出来是计算机指针字长。
知识点:
sumup(a, b, c, 4); // 等价于sumup(&a[0], &b[0], &c[0]);
知识点:三者等价
void sumup(int a[ ], int b[ ], int c[ ], int len)
void sumup(int *a, int *b, int *c, int len) // 本质形式
void sumup(int a[4], int b[4], int c[4], int len)
二维指针传入:代码
//函数外定义
int m, n;
int a[m][n];
int b[m][n];
copy(m, n, a, b);
copy(m, n, &a[0], b);
//函数定义
void copy(int m, int n, int (*a)[n], int b[m][n])
理解int (*a)[n]:
- (*a) *声明a是指针变量, (*a)括起来提前声明为指针.
- int [n] 声明a指针变量指向的类型,是int型的数组
删除线格式 - 定义指针变量的时候需要思考是否有指定的变量内存空间可以指向,没有则需要自己初始化
C语言变量空间分布

枚举 enum
枚举类型 枚举常量列表
重要作用:
1,用有意义的单词,代替无意义的数字
2,限定整型的数值范围
3,如果没有对任何枚举常量赋值,默认从0开始递增
如果有赋值x,那么后续的枚举常量x开始递增
注意:
C语言只实现了枚举的部分特性,不包含以上第2条
因此在C语言中,枚举类型跟int型语法上完全一样
C++才真正实现了枚举
- 枚举列表中的 Mon、Tues、Wed 这些标识符的作用范围是全局的(严格来说是 main() 函数内部),不能再定义与它们名字相同的变量。
- Mon、Tues、Wed 等都是常量,不能对它们赋值,只能将它们的值赋给其他的变量。
枚举和宏其实非常类似:宏在预处理阶段将名字替换成对应的值,枚举在编译阶段将名字替换成对应的值。我们可以将枚举理解为编译阶段的宏。
Mon、Tues、Wed 这些名字都被替换成了对应的数字。这意味着,Mon、Tues、Wed 等都不是变量,它们不占用数据区(常量区、全局数据区、栈区和堆区)的内存,而是直接被编译到命令里面,放到代码区,所以不能用&取得它们的地址。
http://c.biancheng.net/view/2034.html
enum colors {red=0, blue=1, green=2};
colors =100;//可以这样无意义赋值
enum week{ a = 1, b = 5, c = 3} d;d = 10;printf("a=%d d=%d\r\n",sizeof(a),sizeof(d));
结果
a=4 d=4
// C语言中,经常使用宏来定义常量,代替枚举
// 约定俗成的规矩: 宏用大写字母
// C++中,宏没落了,枚举有用正规的定义
#define RED 0
#define BLUE 1
#define GREEN 2
typedef enum
{
GetCarVelocity_STATE_Door1_START, // 车辆进入第一个光电门
GetCarVelocity_STATE_Door1_FINISH, // 车辆出去第一个光电门
GetCarVelocity_STATE_Door2_START, // 车辆进入第二个光电门
GetCarVelocity_STATE_Door2_FINISH // 车辆出去第个光电门
}GetCarVelocityStateTypedef
联合体 union
4.1 定义
联合”与“结构”有一些相似之处。但两者有本质上的不同。在结构中各成员有各自的内存空间,一个结构体变量的总长度大于等于各成员长度之和。而在“联合”中,各成员共享一段内存空间,一个联合变量的长度等于各成员中最长的长度。应该说明的是,这里所谓的共享不是指把多个成员同时装入一个联合变量内,而是指该联合变量可被赋予任一成员值,但每次只能赋一种值,赋入新值则冲去旧值。如下面介绍的“单位”变量,如定义为一个可装入“班级”或“教研室”的联合后,就允许赋予整型值(班级)或字符型(教研室)。要么赋予整型值,要么赋予字符型,不能把两者同时赋予它。联合类型的定义和联合变量的说明:一个联合类型必须经过定义之后,才能把变量说明为该联合类型。
联合体,也叫共用体
本质特征: 所有的成员,共用同一块内存
1,有什么用: 存储一些互斥的量
2,只有最后一个被赋值的成员是有效的
3,最常用的场合:
作为结构体的一员,表达一些互斥的信息
联合体很少单独使用
标签:
1,用来区分不同的联合体
2,可以省略,但省略之后只能在模板中定义变量
一般情况下,作为单独的联合体,不省略标签
当作为结构体的成员时,一般会省略标签
联合体的尺寸、m值:
1,联合的尺寸取决于最大的成员
2,联合的m值取决于成员中最大的m值
4.2联合体的应用示例
1、检测当前处理器是大端模式还是小端模式?
- 联合体union的存放顺序是所有成员都从低地址开始存放
- 16位操作系统中,int 占16位;在32位操作系统中,int 占32位。但是现在人们已经习惯了 int 占32位,因此在64位操作系统中,int 仍为32位。64位整型用 long long 或者 __int64
- char范围-128-127 0xFFFFFFFFFFFFFF80-0x7d 64位
之前分享的《什么是大小端模式?》中已经有介绍怎么判断当前处理器的大小端问题:

现在,可以使用联合体来做判断:
2、分离高低字节
单片机中经常会遇见分离高低字节的操作,比如进行计时中断复位操作时往往会进行
(65535-200)/256,
(65535-200)%256
这样的操作,而一个除法消耗四个机器周期,取余也需要进行一系列复杂的运算,如果在短时间内需要进行很多次这样的运算无疑会给程序带来巨大的负担。其实进行这些操作的时候我们需要的仅仅是高低字节的数据分离而已,这样利用联合体我们很容易降低这部分开销。
代码:
union div
{
int n; // n中存放要进行分离高低字节的数据
char a[2]; // 在keil c中一个整形占两个字节,char占一个字节,所以n与数组a占的字节数相同
}test;
test.n = 65535-200; // 进行完这句后就一切ok了,下面通过访问test中数组a的数据来取出高低字节的数据
TH1 = test.a[0]; // test.a[0]中存储的是高位数据
TL1 = test.a[1]; // test.a[1]中储存了test.n的低位数据
联合体内数据是按地址对齐的。具体是高位数据还是低位数据要看平台的大小端模式,51是大端,stm32默认是小端,如果其他编译器还请自测。仅仅用了一条减法指令就达到了除法、取余的操作,在进行高频率定时时尤为有用。
3、寄存器封装
看看TI固件库中寄存器是怎么封装的: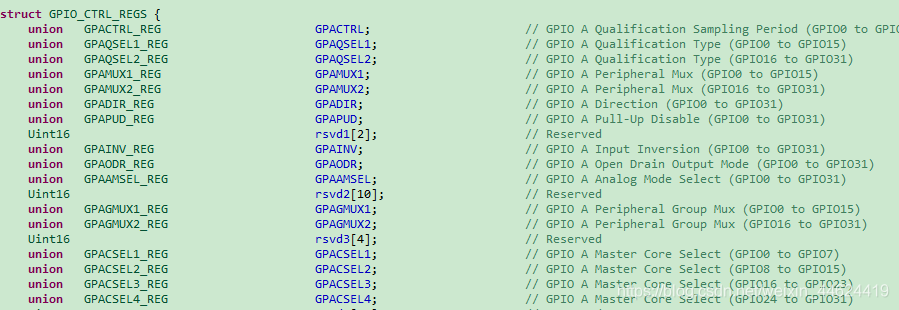
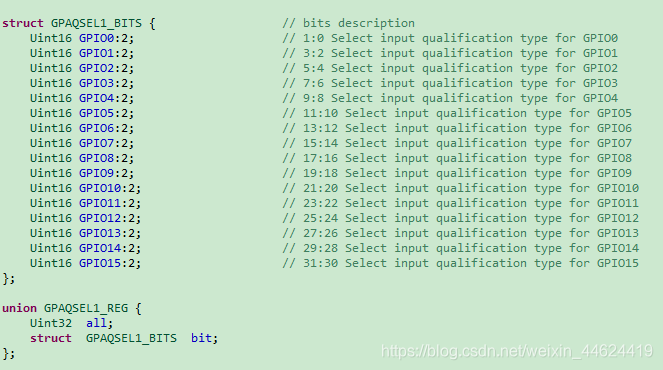
所有的寄存器被封装成联合体类型的,联合体里边的成员是一个32bit的整数及一个结构体,该结构体以位域的形式体现。这样就可以达到直接操控寄存器的某些位了。比如,我们要设置PA0引脚的GPAQSEL1寄存器的[1:0]两位都为1,则我们只操控两个bit就可以很方便的这么设置:
GpioCtrlRegs.GPAQSEL1.bit.GPIO0 = 3
或者直接操控整个寄存器:
GpioCtrlRegs.GPAQSEL1.all |=0x03
union–一道经典的C++笔试题
#i nclude <stdio.h>
union
{
int i;
char x[2];
}a; void main()
{
a.x[0] = 10;
a.x[1] = 1;
printf("%d",a.i);
}
答案:266 (低位低地址,高位高地址,内存占用情况是Ox010A)
b)
main()
{
union{ /*定义一个联合*/
int i;
struct{ /*在联合中定义一个结构*/
char first;
char second;
}half;
}number;
number.i=0x4241; /*联合成员赋值*/
printf("%c%c/n", number.half.first, mumber.half.second);
number.half.first='a'; /*联合中结构成员赋值*/
number.half.second='b';
printf("%x/n", number.i);
getch();
}
答案: AB (0x41对应’A’,是低位;Ox42对应’B’,是高位)
6261 (number.i和number.half共用一块地址空间)
union中的各个成员共用一块内存,而且这块内存的大小是和union中占空间最大的元素所占空间一样大(例如上边T1,sizeof(a)=4)
而且对union中不同成员的写操作,会覆盖其他成员的值
T1:
main函数中对union变量a中的数组X进行赋值,由于会分配4个字节的空间,但是x只占用了两个字节的空间,而且在赋值时从低地址开始,
所以a在内存中的分布是这样的:

从高位到低位读也就是0x00 00 01 0A 注意:低位两个字节是01 0A 不是10 A0(我就是当时把这个搞错了。。)
当输出a.i时,由于占用同样一块内存,所以会读出四个字节,转换为10进制也就是266
还有一个误区就是:10在16进制中是A,但是A只有4位,但是一个字节有八位,在高位添0,所以10在内存中是0A,而不是A(当时我也搞错了。。。)
T2:
union中有两个变量,一个int i 占四个字节,一个结构体,占两个字节,所以这个union占有四个字节的内存
当给i赋值后内存中是这样的:

当输出结构体中的成员时:
printf(“%c%c/n”, number.half.first, mumber.half.second);
第一个字节(也就是0x41)被赋给 number.half.first,第二个字节(0X42)被赋给 number.half.second
于是分别输出了AB
当给结构体中的元素赋值后:
number.half.first=‘a’; /联合中结构成员赋值/
number.half.second=‘b’;
‘a‘=0x61,’b‘=0x62
内存中是这样的:

当输出i的时候,把四个字节都读出来
用十六进制输出就是0X00 00 62 61也就是6261
https://www.cnblogs.com/paulbai/articles/2711809.html
结构体 struct
知识点
64位系统: 字长64位
即意味着:
1,long型数据是64位的
2,任何指针尺寸也都是64位的
任何一个变量都有所谓的m值,对此,约定:
1,m值代表该变量的地址,必须是m的整数倍
2,m值代表该变量的尺寸,必须是m的整数倍
另外,m值越大,代表该变量对位置的要求越高,越挑剔
另外,m值是可以调整的,当然只能调大不能调小
另外,数组的m值等于数组元素类型的m值
// 以下结构体的大小是4+1+1+2 = 8字节
// 其中,第二个1是系统为了地址对齐自动填补上去的
struct node1
{int a; // 4,m1=4char c; // 1, m2=1short d;// 2, m3=2
}; // M=max{m1, m2, m3}=4
//以下结构体的大小是32+32 = 64字节
struct node2
{char c; // 大小为1字节, m2=1int a; // 大小为4字节,m1=4// 大小为2字节, m3=32short d __attribute__((aligned(32)));}; // M=max{m1, m2, m3}=32
解释:
第二个 char c 的地址作为结构体的首地址,所以取3者最大的m值32,后续int a可以放大char c的后面,所以int a和char c的大小加起来一起为32字节.
任何类型的指针变量一般都占4个字节,结构体由于存在边界对齐问题,实际占用内存比真实所需内存大,根据边界对齐要求降序排列结构成员可以最大限度地减少浪费。sizeof返回的值包含了结构中浪费的内存空间
位域
在结构体定义时,我们可以指定某个成员变量所占用的二进制位数(Bit),这就是位域。
有些数据在存储时并不需要占用一个完整的字节,只需要占用一个或几个二进制位即可。例如开关只有通电和断电两种状态,用 0 和 1 表示足以,也就是用一个二进位。正是基于这种考虑,C语言又提供了一种叫做位域的数据结构。
在结构体定义时,我们可以指定某个成员变量所占用的二进制位数(Bit),这就是位域。请看下面的例子:
struct bs{unsigned m;unsigned n: 4;unsigned char ch: 6;
};
:后面的数字用来限定成员变量占用的位数。成员 m 没有限制,根据数据类型即可推算出它占用 4 个字节(Byte)的内存。成员 n、ch 被:后面的数字限制,不能再根据数据类型计算长度,它们分别占用 4、6 位(Bit)的内存。
n、ch 的取值范围非常有限,数据稍微大些就会发生溢出,请看下面的例子:
#include <stdio.h>
int main(){struct bs{unsigned m;unsigned n: 4;unsigned char ch: 6;} a = { 0xad, 0xE, '$'};//第一次输出printf("%#x, %#x, %c\n", a.m, a.n, a.ch);//更改值后再次输出a.m = 0xb8901c;a.n = 0x2d;a.ch = 'z';printf("%#x, %#x, %c\n", a.m, a.n, a.ch);return 0;
}
运行结果:
0xad, 0xe, $
0xb8901c, 0xd, :
对于 n 和 ch,第一次输出的数据是完整的,第二次输出的数据是残缺的。
第一次输出时,n、ch 的值分别是 0xE、0x24(‘$’ 对应的 ASCII 码为 0x24),换算成二进制是 1110、10 0100,都没有超出限定的位数,能够正常输出。
第二次输出时,n、ch 的值变为 0x2d、0x7a(‘z’ 对应的 ASCII 码为 0x7a),换算成二进制分别是 10 1101、111 1010,都超出了限定的位数。超出部分被直接截去,剩下 1101、11 1010,换算成十六进制为 0xd、0x3a(0x3a 对应的字符是 :)。
C语言标准规定,位域的宽度不能超过它所依附的数据类型的长度。通俗地讲,成员变量都是有类型的,这个类型限制了成员变量的最大长度,:后面的数字不能超过这个长度。
例如上面的 bs,n 的类型是 unsigned int,长度为 4 个字节,共计 32 位,那么 n 后面的数字就不能超过 32;ch 的类型是 unsigned char,长度为 1 个字节,共计 8 位,那么 ch 后面的数字就不能超过 8。
我们可以这样认为,位域技术就是在成员变量所占用的内存中选出一部分位宽来存储数据。
C语言标准还规定,只有有限的几种数据类型可以用于位域。在 ANSI C 中,这几种数据类型是 int、signed int 和
unsigned int(int 默认就是 signed int);到了 C99,_Bool 也被支持了。
关于C语言标准以及 ANSI C 和 C99 的区别,我们已在付费教程《C语言的三套标准:C89、C99和C11》中进行了讲解。
但编译器在具体实现时都进行了扩展,额外支持了 char、signed char、unsigned char 以及 enum 类型,所以上面的代码虽然不符合C语言标准,但它依然能够被编译器支持。
位域的存储
C语言标准并没有规定位域的具体存储方式,不同的编译器有不同的实现,但它们都尽量压缩存储空间。
位域的具体存储规则如下:
- 当相邻成员的类型相同时,如果它们的位宽之和小于类型的 sizeof 大小,那么后面的成员紧邻前一个成员存储,直到不能容纳为止;如果它们的位宽之和大于类型的 sizeof 大小,那么后面的成员将从新的存储单元开始,其偏移量为类型大小的整数倍。
以下面的位域 bs 为例:
#include <stdio.h>
int main(){struct bs{unsigned m: 6;unsigned n: 12;unsigned p: 4;};printf("%d\n", sizeof(struct bs));return 0;
}
运行结果:
4
m、n、p 的类型都是 unsigned int,sizeof 的结果为 4 个字节(Byte),也即 32 个位(Bit)。m、n、p 的位宽之和为 6+12+4 = 22,小于 32,所以它们会挨着存储,中间没有缝隙。
sizeof(struct bs) 的大小之所以为 4,而不是 3,是因为要将内存对齐到 4 个字节,以便提高存取效率,这将在《C语言内存精讲》专题的《C语言内存对齐,提高寻址效率》一节中详细讲解。
如果将成员 m 的位宽改为 22,那么输出结果将会是 8,因为 22+12 = 34,大于 32,n 会从新的位置开始存储,相对 m 的偏移量是 sizeof(unsigned int),也即 4 个字节。
如果再将成员 p 的位宽也改为 22,那么输出结果将会是 12,三个成员都不会挨着存储。
- 当相邻成员的类型不同时,不同的编译器有不同的实现方案,GCC 会压缩存储,而 VC/VS 不会。
请看下面的位域 bs:
#include <stdio.h>
int main(){struct bs{unsigned m: 12;unsigned char ch: 4;unsigned p: 4;};printf("%d\n", sizeof(struct bs));return 0;
}
在 GCC 下的运行结果为 4,三个成员挨着存储;在 VC/VS 下的运行结果为 12,三个成员按照各自的类型存储(与不指定位宽时的存储方式相同)。
m 、ch、p 的长度分别是 4、1、4 个字节,共计占用 9 个字节内存,为什么在 VC/VS 下的输出结果却是 12 呢?这个疑问将在《C语言和内存》专题的《C语言内存对齐,提高寻址效率》一节中为您解开。
3) 如果成员之间穿插着非位域成员,那么不会进行压缩。例如对于下面的 bs:
struct bs{unsigned m: 12;unsigned ch;unsigned p: 4;
};
在各个编译器下 sizeof 的结果都是 12。
通过上面的分析,我们发现位域成员往往不占用完整的字节,有时候也不处于字节的开头位置,因此使用&获取位域成员的地址是没有意义的,C语言也禁止这样做。地址是字节(Byte)的编号,而不是位(Bit)的编号。
无名位域
位域成员可以没有名称,只给出数据类型和位宽,如下所示:
struct bs{int m: 12;int : 20; //该位域成员不能使用int n: 4;
};
无名位域一般用来作填充或者调整成员位置。因为没有名称,无名位域不能使用。
上面的例子中,如果没有位宽为 20 的无名成员,m、n 将会挨着存储,sizeof(struct bs) 的结果为 4;有了这 20 位作为填充,m、n 将分开存储,sizeof(struct bs) 的结果为 8。
http://c.biancheng.net/view/2037.html
指针
void型指针可以强转为任意指针
宏定义 define
// 复合赋值语句: ({…})
// 常用语宏中,将多语句合并成一条语句
// 以下的斜杠,用来将多个物理行,变成一个逻辑行
// (void)(&_x==&_y); 的作用:
// 1,当用户使用两个不同的类型进行比对的时候,给出警告
// 2,void的作用是骗过编译器,不对后续比对本身给出警告
#define MAX(x, y) \({ \typeof(x) _x = x; \typeof(y) _y = y; \(void)(&_x==&_y); \_x>_y ? _x : _y; \})
#define paster( n ) printf( "token " #n" = %d\n ", token ## n )那么可以调用:
paster( 1 );
paster( 2 );
paster( 1234 );
paster( ABCD );
意为:
printf( "token1 " = %d", token1 );
printf( "token2 " = %d", token2 );
printf( "token1234 " = %d", token1234 );
printf( "tokenABCD " = %d", tokenABCD );
#define语句中的#是把参数字符串化,##是连接两个参数成为一个整体。
注意:#n 两边的引号必须要
// ## 两边的空格可有可无,不影响
多次宏定义只取最后一个宏定义,可能和编译器版本有关
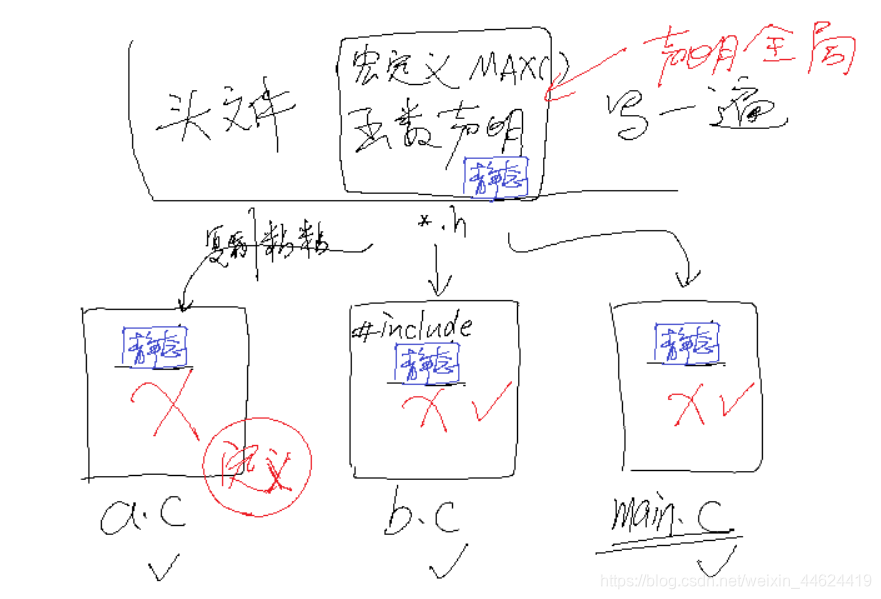
头文件
// 仔细分析,头文件可以包含如下内容:
// 0,其他头文件
// 1,普通函数的声明
// 2,宏定义
// 3,全局变量的声明
// 4,静态函数的定义
头文件定义
// 以下两句话,能防止头文件被重复包含
#ifndef __HEADER_H // 如果没有定义该宏,则编译以下内容
#define __HEADER_H // 立刻定义该宏,使得下一次的判断不成立
静态函数
// 静态函数的定义
// 普通函数:在所有的.c文件中都可见
// 静态函数:只在.c文件内部可见
static void static_func(void)
{printf("我是一个静态函数\n");
}
因为只在.c文件内部可见,所以每个.c文件都可以有static_func(void)函数。
猜测效果:不同c文件有相同的函数名,但是不同的函数操作,是否可以实现类似于c++的继承
const只读变量
| const int a =1 / int const a=1 | 变量a的值不能改变 |
|---|---|
| const int *a=&b/ int const *a=&b | (常目标指针)指针变量a指向的值不能改变,b可以改变内容(常用) |
| int * const a=&b | (常指针)指针的指向不能改变 |
| int const *const a=&b | 指针指向不能改变,指向的值也不能改变 |
| 理解:代码从右往左看,const靠近的那个变量就修饰为只读。 | |
int const *a=&b *a等于是引用变量,const把引用变量的方式修饰为只读 int声明为整数型,放前放后都可以 | |
int * const a=&b a为地址值,指向地址只读=指针变量指向不可改变 |
inline
编译期,内联函数会在它被调用的位置上将自身的代码展开
Linux 内核常常使用 static 修饰内联函数,因为可以避免函数的重复定义。
static
static
a) static在面向过程编程中的使用场景包括三种:
- 修饰函数体内的变量(局部)
- 修饰函数体外的变量(全局)
- 修饰函数
第一种情况,static延长了局部变量的生命周期,static的局部变量,并不会随着函数的执行结束而被销毁,当它所在 的函数被第再次执行时,该静态局部变量会保留上次执行结束时的值。
对于后面的两种情况,static是对它修饰的对象进行了作用域限定,static修饰的函数以及函数外的变量,都是只能在当前的源文件中被访问,其它的文件不能直接访问。当多个模块中有重名的对象出现时,我们不妨尝试用static进行修饰。
b)在面向对象编程中,static可以被用来修饰类内数据成员和成员函数。 - 修饰数据成员
*)被static修饰的数据成员实际上相当于类域中的全局变量。因此,对于类的每个对象来说,它是共有的。它在整个程序中只有一份拷贝,只在定义时分配一次内存,供该类所有的对象使用,其值可以通过每个对象来更新。由于静态数据成员存储在全局数据区,因此,在定义时就要分配内存,这也就导致静态数据成员不能在类声明中定义。
判断系统是小端序还是大端序
大端模式:高字节保存在内存的低地址
小端模式:低字节保存在内存的低地址
int–char的强制转换,是将低地址的数值截断赋给char
强制将char型量p指向i则p指向的一定是i的最低地址
int a = 0x12345678;
int b= 0x87654321;
char *p_a = (char*)&a;
char *p_b = (char*)&b;
char *p_a_tail = ((char*)&a)+3;
printf("address of a:%p\r\n",&a);
printf("address of b:%p\r\n",&b);
printf("p_a:%x\r\n",*p_a);
printf("p_b:%x\r\n",*p_b);
printf("address of p_a:%p\r\n",p_a);
printf("address of p_a_tail:%p\r\n",p_a_tail);
printf("p_a = %x\r\n",*p_a);
printf("p_a_tail = %x\r\n",*p_a_tail);
printf("address of p_b:%p\r\n",p_b);;
if (*p_a == 0x78)
{printf("小端序");
}
else if (*p_a == 0x12)
{printf("大端序");
}
变量在栈中地址是如何分布的
linux
address of a:0x7fffad867070
address of b:0x7fffad867074
p_a:78
p_b:21
address of p_a:0x7fffad867070
address of p_b:0x7fffad867074
little endian
address of a:0x7ffd11df2728
address of b:0x7ffd11df272c
p_a:78
p_b:21
address of p_a:0x7ffd11df2728
address of p_a_tail:0x7ffd11df272b
p_a = 78
p_a_tail = 12
address of p_b:0x7ffd11df272c
little endian
windows
address of a:0060FEF4
address of b:0060FEF0
p_a:78
p_b:21
address of p_a:0060FEF4
address of p_b:0060FEF0
little endian
address of a:0060FEE0
address of b:0060FEDC
p_a:78
p_b:21
address of p_a:0060FEE0
address of p_a_tail:0060FEE3
p_a = 78
p_a_tail = 12
address of p_b:0060FEDC
little endian

#include <stdio.h>
#include <stdlib.h>
int main()
{
int a = 0x12345678;
int b = 0x87654321;
int c[10] = {1,2,3};
char p_a = (char)&a;
char p_b = (char)&b;
char p_a_tail = ((char)&a) + 3;
printf(“address of a:%p\r\n”, &a);
printf(“address of b:%p\r\n”, &b);
printf(“p_a:%x\r\n”, *p_a);
printf(“p_b:%x\r\n”, *p_b);
printf(“address of p_a:%p\r\n”, p_a);
printf(“address of p_a_tail:%p\r\n”, p_a_tail);
printf(“p_a = %x\r\n”, *p_a);
printf(“p_a_tail = %x\r\n”, *p_a_tail);
printf(“address of p_b:%p\r\n”, p_b);
int i = 0;
for (i = 0; i < 10; i++)
{printf("value of c[%d]:%d\r\n", i, c[i]);printf("address of c[%d]:%p\r\n", i, &c[i]);
}if (*p_a == 0x78)
{printf("小端序");
}
else if (*p_a == 0x12)
{printf("大端序");
}
return 0;
}
address of a:0x7ffdd9c8478c
address of b:0x7ffdd9c84790
p_a:78
p_b:21
address of p_a:0x7ffdd9c8478c
address of p_a_tail:0x7ffdd9c8478f
p_a = 78
p_a_tail = 12
address of p_b:0x7ffdd9c84790
value of c[0]:1
address of c[0]:0x7ffdd9c847b0
value of c[1]:2
address of c[1]:0x7ffdd9c847b4
value of c[2]:3
address of c[2]:0x7ffdd9c847b8
value of c[3]:0
address of c[3]:0x7ffdd9c847bc
value of c[4]:0
address of c[4]:0x7ffdd9c847c0
value of c[5]:0
address of c[5]:0x7ffdd9c847c4
value of c[6]:0
address of c[6]:0x7ffdd9c847c8
value of c[7]:0
address of c[7]:0x7ffdd9c847cc
value of c[8]:0
address of c[8]:0x7ffdd9c847d0
value of c[9]:0
address of c[9]:0x7ffdd9c847d4
小端序
堆的分布也同样如此
int *a = ma
lloc(sizeof(int));
a = 0x12345678;
大小端序是单个数据存储方式
栈从高向低地址分配是数据访问方式
两者没关系
C语言、内存管理、堆、栈、动态分配
栈是由高地址向低地址扩展的数据结构,有先进后出的特点,即依次定义两个局部变量,首先定义的变量的地址是高地址,其次变量的地址是低地址。函数参数进栈的顺序是从右向左(主要是为了支持可变长参数形式)。
理解 类似于函数嵌套进行运行,第一个函数运行,里面的第二个函数调用在函数基础上再运行;退出也是先退出第二个函数,再退出第一个函数
https://blog.csdn.net/weixin_39371711/article/details/81783780
字符指针数组
char *a[ ]=(Morning", "Afternoon", "Evening","Night");
进去函数前确认进入的值和变量类型
题目一:
void GetMemory( char *p )
{p = (char *) malloc( 100 );
}void Test( void )
{char *str = NULL;GetMemory( str ); strcpy( str, "hello world" );printf( str );
}
【运行错误】传入GetMemory(char* p)函数的形参为字符串指针,在函数内部修改形参并不能真正的改变传入形参的值。执行完
char *str = NULL;
GetMemory( str );
后的str仍然为NULL。编译器总是要为每个参数制作临时副本,指针参数p的副本是_p,编译器使_p=p。如果函数体内的程序修改了_p的内容,就导致参数p的内容作相应的修改,这就是指针可以用作输出参数的原因。在本例中,_p申请了新的内存,只是把_p所指的内存地址改变了,但是p丝毫未变。所以GetMemory并不能输出任何东西。事实上,每执行一次GetMemory就会泄露一块内存,因为没有用free释放内存。
题目二:
char *GetMemory( void )
{ char p[] = "hello world"; return p;
}void Test( void )
{ char *str = NULL; str = GetMemory(); printf( str );
}
【运行错误】GetMemory中的p[]为函数内的局部自动变量,在函数返回后,内存已经被释放。这是很多程序员常犯的错误,其根源在于不理解变量的生存期。用调试器逐步跟踪Test,发现执行str=GetMemory语句后str不再是NULL指针,但是str的内容不是“hello world”,而是垃圾。
题目三:
void GetMemory( char **p, int num )
{*p = (char *) malloc( num );
}void Test( void )
{char *str = NULL;GetMemory( &str, 100 );strcpy( str, "hello" ); printf( str );
}
【运行正确,但有内存泄露】题目三避免了题目一的问题,传入GetMemory的参数为字符串指针的指针,但是在GetMemory中执行申请及赋值语句
*p = (char *) malloc( num );
后未判断内存是否申请成功,应加上
if ( *p == NULL )
{...//进行申请内存失败处理
}
也可以将指针str的引用传给指针p,这样GetMemory函数内部对指针p的操作就等价于对指针str的操作:
void GetMemory( char *&p) //对指针的引用,函数内部对指针p的修改就等价于对指针str的修改
{p = (char *) malloc( 100 );
}void Test(void)
{char *str=NULL;GetMemory(str);strcpy( str, "hello world" );puts(str);}
https://blog.csdn.net/zhuxiaoyang2000/article/details/8084629
字符数组引用
c i[s]等价于*(i+s)等价于*(s+i)等价于s[i]
printf("%c","xyz"[1]);//'y'
printf("%c",*("xyz"+1));//'y'
printf("%c",*(1+"xyz"));//'y'
printf("%c",1["xyz"]);//'y'
习惯把"xyz"[1]看成*("xyz"+1)来思考问题,本质就是字符指针+1,再加*取内容运算符进行取内容操作。
switch区间匹配
switch(tmp)
{
case 0 … 9 :
tmp += tmp + ‘0’;
break;
case 10 … 15 :
tmp += tmp + ‘A’;
break;
}
switch参数宏定义(方便查看)
#define LEFT 1
#define RIGHT 2
switch (touchpanel(tp)){case LEFT://...break;case RIGHT://...break;}
linux C中的__ASSEMBLY__的作用
转载地址:http://my.oschina.net/u/930588/blog/134751
某些常量宏会同时出现被c和asm引用,而c与asm在对立即数符号的处理上是不同的。asm中通过指令来区分其操作数是有符号还是无符号,而不是通过操作数。而c中是通过变量的属性,而不是通过操作符。c中如要指名常量有无符号,必须为常量添加后缀,而asm则通过使用不同的指令来指明。如此,当一个常量被c和asm同时包含时,必须作不同的处理。故AFLAGS中将添加一项D__ASSEMBLY__,来告知预处理器此时是asm。
下面的代码取自kernel 2.6.10,include/asm-i386/page.h,L123-127
#ifdef __ASSEMBLY__
#define __PAGE_OFFSET (0xC0000000)
#else
#define __PAGE_OFFSET (0xC0000000UL)
#endif
类似的大家也可以去分析一下__KERNEL__的作用.
逻辑左移和算术右移
C语言中移位操作符实现的是逻辑左移和算术右移,但是算术左移和逻辑左移的效果相同,算术右移和逻辑右移的效果不同,要实现逻辑右移可将操作数强制类型转化为无符号数。
算术右移需要考虑符号位,右移一位,若符号位为1,就在左边补1,;否则,就补0。
数组方式访问地址偏移
C51 宏定义:
#define XBYTE ((unsigned char volatile xdata *) 0)
调用方法:
#define PA XBYTE[0x7cff]
PA = 0X80;
通常是这么用的: *(unsigned char volatile xdata )(0x3000)=0xFF这类的方式来进行对外部绝对地址的字节访问。
其实XBYTE就相当于一个指向外部数据区的无符号字符型变量的指针(的名称,且当前的指针指向外部RAM的0地址),而在C里面指针一般和数组是可以混用的。可以直接用XBYTE[0xnnnn]或(XBYTE+0xnnnn)访问外部RAM了。
等于使用[]的寻址方法,调用从0偏移0x7cff个8位char型地址进行写值操作
字符串复制
strcpy不安全,没有指定边界
使用strncpy(this->s,s,len);
extern (转载)
编辑本段编译、链接
1、 声明外部变量
现代编译器一般采用按文件编译的方式,因此在编译时,各个文件中定义的全局变量是
互相透明的,也就是说,在编译时,全局变量的可见域限制在文件内部。下面举一个简单的例子。创建一个工程,里面含有A.cpp和B.cpp两个简单的C++源文件:
//A.cpp
int i;
void main()
{
}
//B.cpp
int i;
这两个文件极为简单,在A.cpp中我们定义了一个全局变量i,在B中我们也定义了一个全局变量i。
我们对A和B分别编译,都可以正常通过编译,但是进行链接的时候,却出现了错误,错误提示如下:
Linking…
B.obj : error LNK2005: “int i” (?i@@3HA) already defined in A.obj
Debug/A.exe : fatal error LNK1169: one or more multiply defined symbols found
Error executing link.exe.
A.exe - 2 error(s), 0 warning(s)
这就是说,在编译阶段,各个文件中定义的全局变量相互是透明的,编译A时觉察不到B中也定义了i,同样,编译B时觉察不到A中也定义了i。
但是到了链接阶段,要将各个文件的内容“合为一体”,因此,如果某些文件中定义的全局变量名相同的话,在这个时候就会出现错误,也就是上面提示的重复定义的错误。
因此,各个文件中定义的全局变量名不可相同。
在链接阶段,各个文件的内容(实际是编译产生的obj文件)是被合并到一起的,因而,定义于某文件内的全局变量,在链接完成后,它的可见范围被扩大到了整个程序。
这样一来,按道理说,一个文件中定义的全局变量,可以在整个程序的任何地方被使用,举例说,如果A文件中定义了某全局变量,那么B文件中应可以使用该变量。修改我们的程序,加以验证:
//A.cpp
void main()
{
i = 100; //试图使用B中定义的全局变量
}
//B.cpp
int i;
编译结果如下:
Compiling…
A.cpp
C:\Documents and Settings\wangjian\桌面\try extern\A.cpp(5) : error C2065: ‘i’ : undeclared identifier
Error executing cl.exe.
A.obj - 1 error(s), 0 warning(s)
编译错误。
其实出现这个错误是意料之中的,因为:文件中定义的全局变量的可见性扩展到整个程序是在链接完成之后,而在编译阶段,他们的可见性仍局限于各自的文件。
编译器的目光不够长远,编译器没有能够意识到,某个变量符号虽然不是本文件定义的,但是它可能是在其它的文件中定义的。
虽然编译器不够远见,但是我们可以给它提示,帮助它来解决上面出现的问题。这就是extern的作用了。
extern的原理很简单,就是告诉编译器:“你现在编译的文件中,有一个标识符虽然没有在本文件中定义,但是它是在别的文件中定义的全局变量,你要放行!”
我们为上面的错误程序加上extern关键字:
//A.cpp
extern int i;
void main()
{
i = 100; //试图使用B中定义的全局变量
}
//B.cpp
int i;
顺利通过编译,链接。
编辑本段函数
extern 函数1
常见extern放在函数的前面成为函数声明的一部分,那么,C语言的关键字extern在函数的声明中起什么作用?
答案与分析:
如果函数的声明中带有关键字extern,仅仅是暗示这个函数可能在别的源文件里定义,没有其它作用。即下述两个函数声明没有明显的区别:
extern int f(); 和int f();
当然,这样的用处还是有的,就是在程序中取代include “*.h”来声明函数,在一些复杂的项目中,我比较习惯在所有的函数声明前添加extern修饰。
extern 函数2
当函数提供方单方面修改函数原型时,如果使用方不知情继续沿用原来的extern申明,这样编译时编译器不会报错。但是在运行过程中,因为少了或者多了输入参数,往往会造成系统错误,这种情况应该如何解决?
答案与分析:
目前业界针对这种情况的处理没有一个很完美的方案,通常的做法是提供方在自己的xxx_pub.h中提供对外部接口的声明,然后调用包涵该文件的头文件,从而省去extern这一步。以避免这种错误。
宝剑有双锋,对extern的应用,不同的场合应该选择不同的做法。
转载链接
三元运算符
三元运算符 性能更好,但是会带来类型转化的问题
例子
int x=4;
cout << ((x>4)?99.0:9);
输出的结果为9.0
printf()后不打印东西
printf会把东西送到缓冲区,而如果缓冲区不刷新到话,你便不会在屏幕上看到东西,而能导致缓冲区刷新到情况有这些:
1 强制刷新 标准输出缓存fflush(stdout);
2,放到缓冲区到内容中包含/n /r ;
3,缓冲区已满;
4,需要从缓冲区拿东西到时候,如执行scanf;
volatile
Volatile意思是“易变的”,应该解释为“直接存取原始内存地址”比较合适。
.一般用处:
一般说来,volatile用在如下的几个地方:
1) 中断服务程序中修改的供其它程序检测的变量,需要加volatile;
当变量在触发某中断程序中修改,而编译器判断主函数里面没有修改该变量,因此可能只执行一次从内存到某寄存器的读操作,而后每次只会从该寄存器中读取变量副本,使得中断程序的操作被短路。
2) 多任务环境下各任务间共享的标志,应该加volatile;
在本次线程内, 当读取一个变量时,编译器优化时有时会先把变量读取到一个寄存器中;以后,再取变量值时,就直接从寄存器中取值;当内存变量或寄存器变量在因别的线程等而改变了值,该寄存器的值不会相应改变,从而造成应用程序读取的值和实际的变量值不一致 。
3) 存储器映射的硬件寄存器通常也要加volatile说明,因为每次对它的读写都可能由不同意义;
假设要对一个设备进行初始化,此设备的某一个寄存器为0xff800000。for(i=0;i< 10;i++) *output = i;前面循环半天都是废话,对最后的结果毫无影响,因为最终只是将output这个指针赋值为9,省略了对该硬件IO端口反复读的操作。
https://www.cnblogs.com/hjh-666/p/11148119.html
寄存器操作
*pGPFDAT &= ~(7<<4);//清零第4位的4个bit
*pGPFDAT |= (tmp<<4);//写入第4位的4个bit
转移字符 \t \177 \7f
转义字符的初衷是用于ASCII编码,所以它的取值范围有限:
八进制形式的转义字符最多后跟三个数字,也即\ddd,最大取值是’\177’;//注意是单引号不是双引号
十六进制形式的转义字符最多后跟两个数字,也即\xdd,最大取值是’\7f’。
定义一个无返回值,无参数的函数类型fun
typedef void(*fun)();
逗号表达式
int a= 0, b = 0, c = 0;
c = (a-=a-5), (a=b,b+3);
printf(“%d,%d,%d\n”,a,b,c);
这是个逗号表bai达式,逗号表达式du有三点要领:
(1) 逗号表达式的运算过程为:从zhi左dao往右逐个计算表达式。
(2) 逗号表达式作为一个整体,它的值为最后一个表达式(也即表达式n)的值。
(3) 逗号运算符的优先级别在所有运算符中最低
由此可知:先计算: (a-=a-5),a=5,由于逗号表达式的优先级别低于’=',此时5赋值给c
然后计算(a=b,b+3),这个也是逗号表达式,此时赋值a=b,所以a=0,整个表达式的值为3
最后输出a=0,b=0,c=5
二、Linux系统命令
1.linux终端的复制和粘贴
在终端选中文字就是复制,右键文字就是粘贴
2.linux终端的复制和粘贴
关于环境变量
查看所有的环境变量
ubuntu:~$ env
查看单个指定的环境变量
ubuntu:~$ echo $PATH
知识点:环境变量 PATH 的作用是:规定系统中的可执行文件的位置。只要是处于这些位置中的可执行文件,执行的时候就不需要指定路径,直接执行即可。
设置 PATH(在其原有的路径的基础上,增添一个路径/home/gec)
// 临时设定 PATH :(所谓临时,指的是关闭终端之后就失效)
gec@ubuntu:~$ PATH=$PATH:/home/gec
// 永久设定 PATH :
将语句 PATH=$PATH:/home/gec 添加到文件 ~/.bashrc 的末尾
知识点:终端tty也是可以添加变量的。
所以可以临时设定PATH
ubuntu:~$ a = apple
ubuntu:~$ echo $a
apple
3.linux网络设置
设置网络参数
配置文件:/etc/network/interfaces,有两种配置方法:
固定IP:
# interfaces(5) file used by ifup(8) and ifdown(8)
auto lo
iface lo inet loopbackauto ens33
iface ens33 inet static
address 169.254.54.200 # IP地址,根据具体的网络环境来写
netmask 255.255.0.0 # 子网掩码
gateway 169.254.54.1 #网关地址
- 动态IP(自动获取IP)
# interfaces(5) file used by ifup(8) and ifdown(8)
auto lo
iface lo inet loopbackauto ens33
iface ens33 inet dhcp
将static改成dhcp,就由原来的静态固定IP改成动态自动获取IP。
重新加载网络配置和重启网络服务
gec@ubuntu:~$ sudo service networking force-reload
gec@ubuntu:~$ sudo service networking restart
注意:老版本的Ubuntu可能不支持以上命令,可以试试下面这个
gec@ubuntu:~$ sudo /etc/init.d/networking force-reload
gec@ubuntu:~$ sudo /etc/init.d/networking restart
测试网络是否连通(ping)
gec@ubuntu:~$ ping www.qq.com
PING public-v6.sparta.mig.tencent-cloud.net (14.18.175.154) 56(84) bytes of data.
64 bytes from 14.18.175.154 (14.18.175.154): icmp_seq=1 ttl=52 time=12.0 ms
64 bytes from 14.18.175.154 (14.18.175.154): icmp_seq=2 ttl=52 time=11.7 ms
64 bytes from 14.18.175.154 (14.18.175.154): icmp_seq=3 ttl=52 time=10.8 ms
64 bytes from 14.18.175.154 (14.18.175.154): icmp_seq=4 ttl=52 time=11.8 ms
注:只要有返回延时时间,就代表网络是通的;如果卡主不动,代表网络不通或者网络拥塞
查看指定的网址的IP地址:
gec@ubuntu:~$ host www.qq.com
www.qq.com is an alias for public-v6.sparta.mig.tencent-cloud.net.
public-v6.sparta.mig.tencent-cloud.net has address 14.18.175.154
public-v6.sparta.mig.tencent-cloud.net has address 113.96.232.215
public-v6.sparta.mig.tencent-cloud.net has IPv6 address 240e:ff:f101:10::15f
注:
host成功返回域名的IP地址,代表当前网络是通的。
host成功返回域名的IP地址,代表当前系统的DNS解析是正常的。
DNS解析,就是通过域名,查询其对应的IP
如果ping成功,但host不成功,代表当前电脑的DNS配置有问题,解决办法:
gec@ubuntu:~$ sudo vi /etc/resolv.conf
在以上文件中,添加如下信息:
nameserver x.x.x.x(可以上百度搜索,选择离你家最近的)
gec@ubuntu:~$ sudo service systemd-resolved restart
以上命令用来重启 DNS 服务
查看或修改网络接口配置信息:(ifconfig)
查看当前活跃的网络接口
gec@ubuntu:~$ ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500inet 192.168.1.103 netmask 255.255.255.0 broadcast 192.168.1.255inet6 fe80::20c:29ff:fe80:949c prefixlen 64 scopeid 0x20<link>ether 00:0c:29:80:94:9c txqueuelen 1000 (Ethernet)RX packets 2020 bytes 266623 (266.6 KB)RX errors 0 dropped 0 overruns 0 frame 0TX packets 8299 bytes 548748 (548.7 KB)TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536inet 127.0.0.1 netmask 255.0.0.0inet6 ::1 prefixlen 128 scopeid 0x10<host>loop txqueuelen 1000 (Local Loopback)RX packets 37191 bytes 2722682 (2.7 MB)RX errors 0 dropped 0 overruns 0 frame 0TX packets 37191 bytes 2722682 (2.7 MB)TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
注:其中,ens33是当前虚拟机的虚拟网卡lo是Linux系统的本地回环设备,一般不用管它
启停指定的网络接口(网卡)
gec@ubuntu:~$ sudo ifconfig ens33 up ==> 启用ens33
gec@ubuntu:~$ sudo ifconfig ens33 down ==> 停用ens33以上命令也可以用如下命令替代,注意:有些系统不支持
gec@ubuntu:~$ sudo ifup ens33 ==> 启用ens33
gec@ubuntu:~$ sudo ifdown ens33 ==> 停用ens33
临时修改指定的网络接口的IP地址(即重启后失效)
gec@ubuntu:~$ sudo ifconfig ens33 192.168.1.103
查看当前网络状态:查看各种协议的网络信息
gec@ubuntu:~$ netstat
重新启动Ubuntu:
sudo shutdown -r now
5.kill
向指定的一堆进程发送信号:(killall)
gec@ubuntu:~$ killall while ==> 杀死当前系统中所有名为while的进程
6.find xargs grep(当前目录下所有.cpp文件中查找efg函数)
在当前目录下所有.cpp文件中查找efg函数
find . -name “*.cpp” | xargs grep ‘efg’
xargs展开find获得的结果,使其作为grep的参数
另外 rm mv等命令对大量文件操作时报错 -bash: /bin/rm: Argument list too long也可用xargs 解决
删除当前目录下所有.cpp文件
find . -name “*.cpp” | xargs rm
下面用find和grep来进一步说明:
// 将find找到的*.h文件列表的名称直接作为grep要查找的数据(输入)
gec@ubuntu:~$ find . -name "*.h" | grep 'abc'
// 将find找到的*.h文件列表的名称直接作为grep要查找的文件(参数)
gec@ubuntu:~$ find . -name "*.h" |xargs grep 'abc'
注:
1.find命令是把找到的结果输出到标准终端输出流中,管道改变输出流指向为指向grep的输入流。sort排序指令,把文件的文本内容提取出来输出缓冲区,清空文件;在缓冲区排序后,输出到文件,并且输出到标准终端输出流(方便配合管道指令)。
2. 第一种就是.h就是文本输入,第二种.h的文字段识别为文件,然后打开文件进行操作(或者说每行的内容识别成一个文件,把他打开再进行搜索)
7.查看文本内容
gec@ubuntu:~$ cat a.txt ==> 查看 a.txt 的内容
gec@ubuntu:~$ head -n 20 a.txt ==> 查看 a.txt 的前20行的内容
gec@ubuntu:~$ tail -n 20 a.txt ==> 查看 a.txt 的末20行的内容
gec@ubuntu:~$ less a.txt ==> 分屏查看 a.txt 的内容
gec@ubuntu:~$ more a.txt ==> 分屏查看 a.txt 的内容(推荐?)
gec@ubuntu:~$ od a ==> 查看二进制 a 的内容(默认八进制)
gec@ubuntu:~$ od -d a ==> 查看二进制 a 的内容(以十进制)
gec@ubuntu:~$ od -x a ==> 查看二进制 a 的内容(以十六进制)
8.od查看二进制文件
查看二进制文件,用od或hexdump命令。
$ od -tx1 -tc -Ax binFile
000000 61 62 63 64 65 31 32 33 34 35 61 62 63 64 65 31a b c d e 1 2 3 4 5 a b c d e 1
000010 32 33 34 35 61 62 63 64 65 31 32 33 34 35 61 622 3 4 5 a b c d e 1 2 3 4 5 a b
000020 63 64 65 31 32 33 34 35 0ac d e 1 2 3 4 5 \n
000029
-tx1选项表示将文件中的字节以十六进制的形式列出来,每组一个字节(类似hexdump的-c选项)-tc选项表示将文件中的ASCII码以字符形式列出来(和hexdump类似,输出结果最左边的一列是文件中的地址,默认以八进制显示)-Ax选项要求以十六进制显示文件中的地址
https://zhidao.baidu.com/question/1860941808766537387.html
9.将文件内容排序、去除文件中的重复的相邻行
sort / uniq
作用:将文件内容排序、去除文件中的重复的相邻行
用法:
gec@ubuntu:~$ sort file ==> 将文件file的内容排序输出
gec@ubuntu:~$ uniq file ==> 将文件file的重复相邻行删除后输出
gec@ubuntu:~$ sort file | uniq ==> 先排序,再去除重复行
10.管道命令
管道: |
作用:将不同的命令连接起来,将前面命令的输出,作为后面命令的输入或者参数
用法:
gec@ubuntu:~$ cmd1 | cmd2 ==> 将cmd1的输出,作为cmd2的输入
gec@ubuntu:~$ cmd1 |xargs cmd2 ==> 将cmd1的输出,作为cmd2的参数
11. 显示ELF格式目标文件的信息(查看代码段)
readlf -S
11. 查看外网ip
curl icanhazip.com
12. 设置终端代理
export http_proxy="http://127.0.0.1:10808"
export https_proxy="http://127.0.0.1:10808"
export http_proxy="socks5://127.0.0.1:7890"
export https_proxy="socks5://127.0.0.1:7890"
13. 查看历史命令
history
三、文件IO
1.把一个文件的内容复制到另一个文件
注: read函数特性,无法确定的把100个字节全部读取进入字节流,所以需要while进行处理
#include <stdio.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
#include <stdlib.h>
#include <unistd.h>int main(int argc, char *argv[]) // ./copy a b ...// argv[0] argv[1] argv[2] ...// argc = 外部参数总数
{// 判断外部参数(包括程序本身)个数的合法性if(argc != 3){printf("参数错误!用法: <源文件> <目标文件>\n");exit(0);}// 1,打开你要操作的文件// 打开第一个参数指定的文件,并将模式指定为只读: O_RDONLY// 此种打开模式代表: 文件必须存在,否则报错int fd1 = open(argv[1], O_RDONLY); // aif(fd1 == -1){// 万一不幸打不开,输出失败的原因perror("打开源文件失败");exit(0);}// 打开第二个参数指定的文件,并将模式指定为只写: O_WRONLY// 另外:// O_CREAT代表如果文件不存在则创建文件,并将权限设置为0644// O_TRUNC代表如果文件已存在则清空文件int fd2 = open(argv[2], O_WRONLY|O_CREAT|O_TRUNC, 0644); // bif(fd2 == -1){// 万一不幸打不开,输出失败的原因perror("打开目标文件失败");exit(0);}// 2,不断地读取源文件内容,并放入目标文件中char *buf = calloc(1, 100);while(1){// 从文件fd1中读取最多100个字节,放入buf中// read的返回值n,代表实际读取的字节数(n<=100)int n = read(fd1, buf, 100);// 读完了if(n == 0){printf("复制完毕!收工!\n");break;}// 出错了!if(n == -1){perror("读取源文件内容失败");break;}// 将buf中最多n个字节,写入fd2中// write的返回值m,代表实际写入的字节数(即m<=n)char *tmp = buf;while(n > 0){int m = write(fd2, tmp, n);n -= m;tmp += m;}}// 3,关闭文件,释放相关资源close(fd1);close(fd2);free(buf);return 0;
}
2. 静态库、动态库的制作
静态库、动态库基本概念
静态库(相当于书店,东西只卖不借)
原理:编译时,库中的代码将会被直接复制一份到程序中
优点:程序不依赖于库、执行效率稍高
缺点:浪费存储空间、无法对用户升级迭代
动态库(相当于图书馆,东西只借不卖)
原理:编译时,程序仅确认库中功能模块的匹配关系,并未复制
缺点:程序依赖于库、执行效率稍低
优点:节省存储空间、方便对用户升级迭代
库文件的命名
都以 lib 作为前缀,比如 libx.a、liby.so
静态库的后缀为 .a ,动态库的后缀为 .so
静态库、动态库的制作和使用
不管是静态库还是动态库,其原料都是 *.o 文件
不管是静态库还是动态库,天生都是用来被其他程序链接的功能模块,一定不能包含main
编译生成 *.o 文件的方法如下:
gec@ubuntu:~$ gcc a.c -o a.o -c -fPIC
静态库的制作与使用:
// 将a.o b.o c.o ... 制作成一个静态库文件libx.a
gec@ubuntu:~$ ar rcs libx.a a.o b.o c.o ...// 链接静态库libx.a
gec@ubuntu:~$ gcc main.c -o main -L . -lx
动态库的制作与使用:
// 将a.o b.o c.o ... 制作成一个动态库文件liby.so
gec@ubuntu:~$ gcc -shared -fPIC -o liby.so a.o b.o c.o ...// 链接动态库liby.so
gec@ubuntu:~$ gcc main.c -o main -L . -ly
链接了动态库的程序怎么运行?
由于程序和动态库在编译之后,都可能会随着系统的变迁而发生位置改变,因此链接了动态库的程序在每次运行时都会动态地去寻找其所依赖的库文件,这是他们为什么被称为动态库的原因。
三种办法可以使得程序在运行时成功找到其所依赖的动态库:
设置环境变量:
gec@ubuntu:~$ export LD_LIBRARY_PATH=...
编译时预告:
gec@ubuntu:~$ gcc a.c -o a -L . -ly -Wl,-rpath=xxx/
注意:此处xxx/代表程序在运行时,动态库所在的路径
修改系统默认库路径(!!危险!!):
gec@ubuntu:~$ sudo vi /etc/ld.so.conf.d/libc.conf
在以上文件中,添加动态库所在路径即可。
此处要小心编辑,一旦写错可能会导致系统无法启动,这是一种污染系统的做法,不推荐
数据结构
内核链表
为什么内核链表是大结构体里面有小结构体链表+数据的形式?
理解:内核链表中的链表元素不与特定类型相关,具有通用性。如果是结构链表+结构数据,还需要指定结构体数据的地址,那就需要确认结构体数据的形式。而且在项目封装的时候,如果第二次定义结构链表+结构数据的时候,需要全部重新修改程序封装 。但是内核链表的小结构体则是直接脱离了本身,内核链表可以小结构体独立走,然后任意形式的大结构体包住小结构体即可实现携带传输。但是必须得用malloc进行创建? 堆的地址分配是低到高 ,zh
利用小结构体获取大结构体的地址
/**
* list_entry – get the struct for this entry
* @ptr: the &struct list_head pointer.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_struct within the struct.
*/
#define list_entry(ptr, type, member) \
((type *)((char *)(ptr)-(unsigned long)(&((type *)0)->member)))
理解 :
(char *)(ptr):使得指针的加减操作步长为一字节(理解:不然减偏移量的时候就是移动结构体指针)
(unsigned long)(&((type *)0)->member):获取结构体中指向的member地址与该member所在结构体的基地址的偏移量。
> 测试代码typedef struct node
{int data; // 数据域 4 4+8+8struct list_head list; // 小结构体 16
}node;typedef struct node2
{struct list_head list; // 小结构体 16int data; // 数据域 4
}node2;
int main(void)
{node* a = (node*)malloc( sizeof(node) );if(a != NULL){// 数据域a->data = 123;// 小结构体要自己形成循环链表INIT_LIST_HEAD(&a->list);}node* p_a = ((node *)((char *)(&a->list)-(unsigned long)(&((node *)0)->list)));printf("address of a:%p\r\n",a);printf("address of data:%p\r\n",&a->data);printf("address of list:%p\r\n",&a->list);printf("address of (char *)&a->list:%p\r\n",(char *)&a->list);printf("address of ((node *)0)->list:%p\r\n",&((node *)0)->list);printf("(unsigned long)(&((node *)0)->list)=%ld\r\n",(unsigned long)(&((node *)0)->list));printf("address of (char *)(&a->list)-(unsigned long)(&((node *)0)->list:%p\r\n",\(char *)(&a->list)-(unsigned long)(&((node *)0)->list));printf("address of p_a:%p\r\n",p_a);printf("sizeof(a->data)=%ld\r\n",sizeof(a->data));printf("sizeof(a->list)=%ld\r\n",sizeof(a->list));node2* b = (node2*)malloc( sizeof(node2) );if(b != NULL){// 数据域b->data = 123;// 小结构体要自己形成循环链表INIT_LIST_HEAD(&b->list);}node2* p_b = ((node2 *)((char *)(&b->list)-(unsigned long)(&((node2 *)0)->list)));printf("address of b:%p\r\n",b);printf("address of data:%p\r\n",&b->data);printf("address of list:%p\r\n",&b->list);printf("address of (char *)b->list:%p\r\n",(char *)&b->list);printf("address of ((node2 *)0)->list:%p\r\n",&((node2 *)0)->list);printf("(unsigned long)(&((node2 *)0)->list)=%ld\r\n",(unsigned long)(&((node2 *)0)->list));printf("address of (char *)(&b->list)-(unsigned long)(&((node2 *)0)->list:%p\r\n",\(char *)(&b->list)-(unsigned long)(&((node2 *)0)->list));printf("address of p_b:%p\r\n",p_b);printf("sizeof(b->data)=%ld\r\n",sizeof(b->data));printf("sizeof(b->list)=%ld\r\n",sizeof(b->list));return 0;
}
结果
address of a:0x55ce33cc9260
address of data:0x55ce33cc9260
address of list:0x55ce33cc9268
address of (char *)&a->list:0x55ce33cc9268
address of ((node *)0)->list:0x8
(unsigned long)(&((node *)0)->list)=8
address of (char *)(&a->list)-(unsigned long)(&((node *)0)->list:0x55ce33cc9260
address of p_a:0x55ce33cc9260
sizeof(a->data)=4
sizeof(a->list)=16
address of b:0x55ce33cc9690
address of data:0x55ce33cc96a0
address of list:0x55ce33cc9690
address of (char *)b->list:0x55ce33cc9690
address of ((node2 *)0)->list:(nil)
(unsigned long)(&((node2 *)0)->list)=0
address of (char *)(&b->list)-(unsigned long)(&((node2 *)0)->list:0x55ce33cc9690
address of p_b:0x55ce33cc9690
sizeof(b->data)=4
sizeof(b->list)=16
四、linux系统文件操作(建立工程模板)
包含头文件
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>#include <sys/stat.h>
#include <sys/types.h>
#include <sys/mman.h>#include <linux/fb.h>
#include <linux/input.h>#include <string.h>
#include <errno.h>
#include <time.h>
#include <fcntl.h>
1.参数初始化(设计功能后,列一个特殊情况检查表格进行检查)
if(argc != 2){printf("参数错误,用法: <BMP图片>\n");exit(0);}// 判断命令行参数// 最终要显示的目标target,可能是当前文件夹(默认)// 也可能是用户指定的一个文件夹,或者图片char *target = ((argc==1) ? "." : argv[1]);struct stat info;bzero(&info, sizeof(info));stat(target, &info);if(S_ISREG(info.st_mode)){if(!isbmp(target)){printf("我只能显示BMP图片,再见!\n");exit(0);}struct node *picnode = new_node(target);display(picnode);}// 遍历文件夹else if(S_ISDIR(info.st_mode)){// 搞一个空链表struct node * head = init_list();DIR *dp = opendir(target);chdir(target);// 读取目录,将所有的BMP图片信息存入链表中(不读取RGB)struct dirent *ep;while(1){ep = readdir(dp);// 读完目录了if(ep == NULL)break;// 只挑BMP图片放入链表if(isbmp(ep->d_name)){printf("图片:[%s]入链表\n", ep->d_name);// 搞个新节点,并置入链表struct node * picnode = new_node(ep->d_name);head = list_add_tail(head, picnode);}}if(empty(head)){printf("你指定的目录中没有BMP图片,再见!\n");exit(0);}}elseprintf("我是相册程序,你指定的文件不是我的菜!\n");return 0;
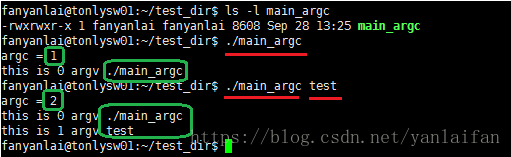
}1.1理解 argc argv参数之间的关系
2.打开文件
int pic = open(argv[1], O_RDONLY);
3.读取图片的格式头,获取其各种信息
3.1 bmp图片的读取
struct bitmap_header head;struct bitmap_info info;bzero(&head, sizeof(head));bzero(&info, sizeof(info));read(pic, &head, sizeof(head));read(pic, &info, sizeof(info));
3.2 读取触摸屏的数据
struct input_event buf;int x, y;int xnew, ynew;bool xready = false;bool yready = false;while(1){bzero(&buf, sizeof(buf));read(tp, &buf, sizeof(buf));if(buf.type == EV_ABS && buf.code == ABS_X){xnew = buf.value;xready = true;}if(buf.type == EV_ABS && buf.code == ABS_Y){ynew = buf.value;yready = true;}if(xready && yready && (xnew!=x && ynew!=y)){printf("(%d, %d)\n", xnew, ynew);xready = false;yready = false;x = xnew;y = ynew;}}
4.映射LCD的显存(对应3.1图片读取)
int lcd = open("/dev/ubuntu_lcd", O_RDWR);
if(lcd == -1)
{perror("打开LCD失败");exit(0);
}
char *p = mmap(NULL, 800*480*4, PROT_READ|PROT_WRITE,MAP_SHARED, lcd, 0);
if(p == MAP_FAILED)
{perror("映射内存失败");exit(0);
}
bzero(p, 800*480*4); // 清屏(纯黑色)
5. 将图片的RGB读出,并置入显存中
int rgb_size = head.size-sizeof(head)-sizeof(info);
char *rgb = calloc(1, rgb_size);// 将图片中的RGB放入rgb中
int total = 0;
while(1)
{int n = read(pic, rgb+total, rgb_size);if(n == 0)break;total += n;rgb_size -= n;
}// 计算每一行的无效字节数
int pad = (4 - ((info.width*3) % 4))%4; // 0-3// 将rgb指向最末一行的起始位置
rgb += (info.width*3 + pad) * (info.height-1);// 将太大的图片按比例缩小
int wt = info.width/801+1;
int ht = info.height/481+1;
int scale = wt>ht ? wt : ht; // >=1// 让图片居中显示
int x = (800-info.width/scale)/2;
int y = (480-info.height/scale)/2;
char *tmp = p + (y*800 + x)*4;// 将rgb中的数据,妥善地放入LCD显存
for(int j=0, m=0; j<480-y && m<info.height; j++, m+=scale)
{for(int i=0, k=0; i<800-x && k<info.width; i++, k+=scale){int lcd_offset = 4*i + 800*4*j;int rgb_offset = 3*k - (info.width*3+pad)*m;memcpy(tmp+lcd_offset, rgb+rgb_offset, 3);}
}
6.释放资源
munmap(p, 800*480*4);
close(lcd);
close(pic);
7.串口数据发送
// 通过串口向读卡器发送'A'指令(探测指令)tcflush (fd, TCIFLUSH);write(fd, PiccRequest_IDLE, PiccRequest_IDLE[0]);
tcflush() 丢弃要写入引用的对象,但是尚未传输的数据,或者收到但是尚未读取的数据,取决于 queue_selector 的值:
TCIFLUSH 刷新收到的数据但是不读
TCOFLUSH 刷新写入的数据但是不传送
TCIOFLUSH 同时刷新收到的数据但是不读,并且刷新写入的数据但是不传送
将输出缓冲器清空,把输入缓冲区清空。缓冲区里的数据都废弃。
五、LINUX系统编程
1. 创建进程
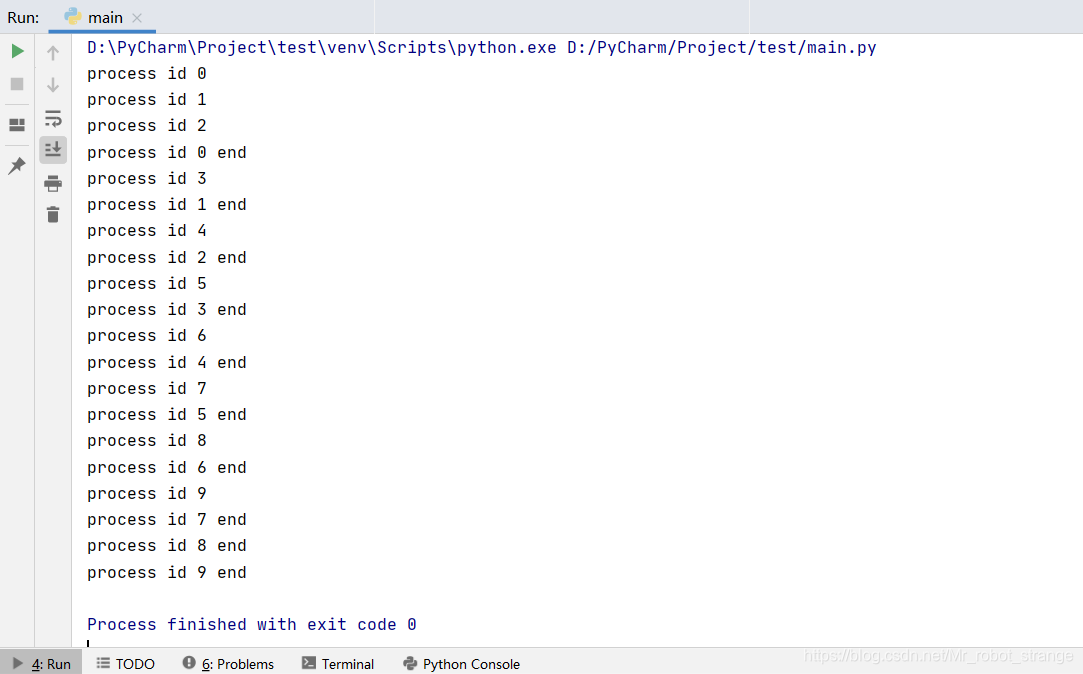
#include "common.h"int main()
{pid_t pid = fork();if(pid > 0){printf("PID:%d, PPID:%d\n", getpid(), getppid());// 判断子进程的退出值int status;wait(&status);switch (WEXITSTATUS(status)){case 0:printf("子进程成功执行了任务!\n");break;case 1:printf("子进程任务失败:xxx\n");break;case 2:printf("子进程任务失败:yyy\n");break;default:printf("子进程任务失败:不明原因\n");break;}}if(pid == 0){// exec函数族// 功能: 让进程加载一段新的代码(旧瓶装新酒),覆盖原有的代码// 其中:// "./childProcess" 是要加载的程序// "./childProcess", "ab", "12", NULL 是程序的参数列表
#if 0printf("%d\n", __LINE__);execl("./childProcess", "./childProcess", "ab", "12", NULL);printf("%d\n", __LINE__);
#endif#if 1// 没有获取环境变量PATH的值execl("/bin/ls", "/bin/ls", NULL);
#else// 从终端获取了环境变量PATH的值execlp("ls", "ls", NULL);
#endif}return 0;
}
理解:C程序调用shell脚本共有三种法子:system()、popen()、exec系列函数 。
system()不用你自己去产生进程,它已经封装了,直接加入自己的命令;exec 需要你自己 fork 进程,然后exec
自己的命令;popen()也可以实现执行你的命令,比system 开销小。
execl函数特点:: 当进程调用一种exec函数时,该进程完全由新程序代换,而新程序则从其main函数开始执行。因为调用exec并不创建新进程,所以前后的进程ID并未改变。exec只是用另一个新程序替换了当前进程的正文、数据、堆和栈段。
用另一个新程序替换了当前进程的正文、数据、堆和栈段。
当前进程的正文都被替换了,那么execl后的语句,即便execl退出了,都不会被执行。
1.1fork()函数(两个进程)
// 将本进程复刻一个子进程
// 1,fork函数将本进程复制一份,并使之成为独立的子进程
// 2,子进程拥有父进程拷贝过来的一切代码,但只从fork函数往下开始执行
// 3,父子进程同时并发运行,此刻无法确定他们的执行次序.
// 4,fork函数在父子进程两处,分别返回不同的值(大于0是父进程,等于0是子进程)
pid_t pid = fork();
理解:子进程内没有子进程,所以返回值为0
1.2 缓冲区中的数据
进程间的数据是独立的
printf("缓冲区中的数据");pid_t pid = fork();if(pid > 0){// 查看内存中各个区域的数据是否受到影响printf("global:%d\n", global);printf("x:%d\n", x);printf("*p:%d\n", *p);}
输出结果:
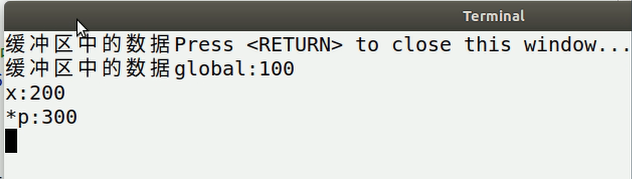
理解:因为`printf("缓冲区中的数据");`没有加换行,所以没有打印大屏幕,而且存储在内存中。
fork()就复制了一份子进程,然后下一个换行符一并打印出来。
1.3 kill(0,SIGKILL)杀死该进程所在进程组的所有进程(即父进程和所有子进程)。
C程序中,kill(0,SIGKILL)将会杀死该进程所在进程组的所有进程(即父进程和所有子进程)。
2.创建daemon进程(建立工程模板)
1.可以被kill结束
2.目的:脱离终端,类似tcp连接这些,伪系统进程
#include "daemon.h"int main(void)
{pid_t a;int max_fd, i;/*********************************************1. ignore the signal SIGHUP, prevent theprocess from being killed by the shutdownof the present controlling termination**********************************************/signal(SIGHUP, SIG_IGN);/***************************************2. generate a child process, to ensuresuccessfully calling setsid()****************************************/a = fork();if(a > 0)exit(0);/******************************************************3. call setsid(), let the first child process runningin a new session without a controlling termination*******************************************************/setsid();/*************************************************4. generate the second child process, to ensurethat the daemon cannot open a terminal fileto become its controlling termination**************************************************/a = fork();if(a > 0)exit(0);/*********************************************************5. detach the daemon from its original process group, toprevent any signal sent to it from being delivered**********************************************************/setpgrp();/*************************************************6. close any file descriptor to release resource**************************************************/max_fd = sysconf(_SC_OPEN_MAX);for(i=0; i<max_fd; i++)close(i);/******************************************7. clear the file permission mask to zero*******************************************/umask(0);/****************************************8. change the process's work directory,to ensure it won't be uninstalled*****************************************/chdir("/");// Congratulations! Now, this process is a DAEMON!//pause();openlog("daemon_test", LOG_CONS | LOG_PID, LOG_DAEMON);return 0;
}
3.dup2()文件描述符重定向
// int fd = open("a.txt", O_RDWR);// // 功能: 复制0号描述符为fd
// // 即从此之后,fd对应的文件与0一样
// dup2(0, fd);// char buf[50];
// bzero(buf, 50);
// read(fd, buf, 50);// printf("%s", buf);
int fd = open("b.txt", O_RDWR|O_CREAT|O_TRUNC, 0644);// 功能: 将1覆盖fd,fd丧失了原来的文件关联,fd就变成跟1一样dup2(1, fd);write(fd, "abc", 3); // 向屏幕输出abc
3.1重定向到管道文件进行通信,理解ls | wc
// 1,创建无名管道int fd[2];pipe(fd);// 2,创建子进程pid_t pid = fork();// 父进程if(pid > 0){// 将标准输出(1号描述符)重新定向到管道的写端dup2(fd[1], STDOUT_FILENO); // cp file1 file2// 此时,执行ls,他将会把数据写入1号描述符,即管道的写端execlp("ls", "ls", NULL);}// 子进程if(pid == 0){// 将标准输入(0号描述符)重新定向到管道的读端dup2(fd[0], STDIN_FILENO); // cp file1 file2close(fd[1]);// 此时,执行wc,他将会从0号描述符读取数据,即管道的读端execlp("wc", "wc", "-w", NULL);}
3.管道
3.1 无名管道
无名管道不存在管道文件,其借助于父子进程共享fork之前打开的文件描述符。(文件打开机制)其数据存储在内存中。
无名管道限制:只能使用于父子进程之间(无法跨越父子关系)
int main()
{// 创建无名管道int fd[2];pipe(fd);// 创建子进程pid_t pid = fork();// parentif(pid > 0){// 父进程只负责读取管道数据,所以最好关闭写端close(fd[1]);char buf[20];// 静静地等待子进程的消息...bzero(buf, 20);read(fd[0], buf, 20);printf("第一次收到子进程的消息:%s\n", buf);// 静静地等待子进程的消息...bzero(buf, 20);read(fd[0], buf, 20);printf("第二次收到子进程的消息:%s\n", buf);}// childif(pid == 0){// 子进程只负责将数据写入管道,所以最好关闭读端close(fd[0]);sleep(2);write(fd[1], "你好", 20);// 暂停
// pause();}return 0;
}
3.2 有名管道
写者
int main(void)
{// 1,创建有名管道mkfifo("/home/gec/fifo", 0666);/* // 设置为非阻塞int state = fcntl(fd, F_GETFL);state |= O_NONBLOCK;fcntl(fd, F_SETFL, state);*/// 2,打开管道int fd = open("/home/gec/fifo", O_RDWR);if(fd == -1){perror("打开管道失败");exit(0);}// 3,向对方说一句话write(fd, "abcd", 4);close(fd);return 0;
}
读者
// 1,创建有名管道mkfifo("/home/gec/fifo", 0666);// 2,打开管道int fd = open("/home/gec/fifo", O_RDONLY);if(fd == -1){perror("打开管道失败");exit(0);}// 3,等待对方的消息char buf[10];bzero(buf, 10);read(fd, buf, 10);printf("对方的消息: %s", buf);close(fd);return 0;
3.3管道的读写特性
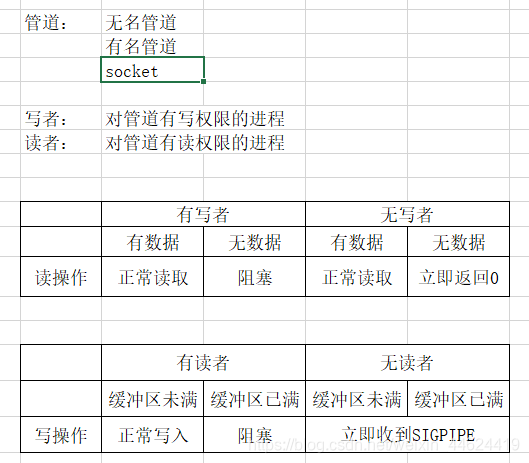
打开文件操作时,不允许管道以单边形式(只有一边,或者只读,或者只写)存在,这样会堵塞然后打不开。
堵塞等待写者:open(“xxx.fifo”,O_RDONLY);
4.信号
4.1sleep()延时函数会被信号的到来打断.
4.2 信号创建和处理(程序模板)
#include "common.h"// f是信号响应函数,注意接口是固定的
void f(int sig)
{// 回收了一个僵尸子进程int status;wait(&status);printf("%d号子进程已被回收\n", WEXITSTATUS(status));
}int main()
{// 关联信号与函数// 即: 将来如果我收到 SIGCHLD,就去执行fsignal(SIGCHLD, f);int n = 0;while(1){n++;pid_t pid = fork();// 父进程,1秒生一个孩子if(pid > 0){pause();sleep(1);continue;}// 子进程,生出来就死掉if(pid == 0){exit(n);}}return 0;
}
-
Unix系统提供了两种方式来改变信号处置:signal() 和 sigaction()。
signal() 的行为在不同Unix实现间存在差异,这也意味着对可移植性有所追求的程序绝不能使用此调用 来建立信号处理函数。故此,sigaction() 是建立信号处理器的首选API(强力推荐)。
-
同时SIGSTOP/SIGKILL这俩信号无法捕获和忽略。注意,经过实验发现,signal函数也会堵塞当前正在处理的signal,但是没有办法阻塞其它signal,比如正在处理SIG_INT,再来一个SIG_INT则会堵塞,但是来SIG_QUIT则会被其中断,如果SIG_QUIT有处理,则需要等待SIG_QUIT处理完了,SIG_INT才会接着刚才处理。
4.2.1细节:进程的信号挂起队列中,没有相同的信号(即相同的信号会被丢弃)。
理解:信号阻塞接触后,首先清零信号集中对应的信号位,然后执行信号处理函数
4.2.2进程在响应信号时,不同的信号会相互嵌套。
4.2.3挂起信号不会被子进程继承,但信号阻塞掩码会被继承。
4.2.4 getchar会被信号打断
判断代码
ch = getchar();
if (ch = -1 && errno == EINTR)
{printf("读操作被信号中断了");
}4.2 sigaction
- signal和sigaction的区别 下面所指的signal都是指以前的older
signal函数,现在大多系统都用sigaction重新实现了signal函数
1、signal在调用handler之前先把信号的handler指针恢复;sigaction调用之后不会恢复handler指针,直到再次调用sigaction修改handler指针。
:这样,(1)signal就会丢失信号,而且不能处理重复的信号,而sigaction就可以。因为signal在得到信号和调用handler之间有个时间把handler恢复了,这样再次接收到此信号就会执行默认的handler。(虽然有些调用,在handler的以开头再次置handler,这样只能保证丢信号的概率降低,但是不能保证所有的信号都能正确处理)
2、signal在调用过程不支持信号block;sigaction调用后在handler调用之前会把屏蔽信号(屏蔽信号中自动默认包含传送的该信号)加入信号中,handler调用后会自动恢复信号到原先的值。
(2)signal处理过程中就不能提供阻塞某些信号的功能,sigaction就可以阻指定的信号和本身处理的信号,直到handler处理结束。这样就可以阻塞本身处理的信号,到handler结束就可以再次接受重复的信号。
3、sigaction提供了比signal多的多的功能,可以参考man
分割
2. sigaction,这个相对麻烦一些,函数原型如下:
int sigaction(int sig, const struct sigaction *act, struct sigaction *oact);
函数到关键就在于struct sigaction
stuct sigaction
{void (*)(int) sa_handle;sigset_t sa_mask;int sa_flags;
}
1 #include <signal.h>2 #include <stdio.h>3 #include <unistd.h>4 5 6 void ouch(int sig)7 {8 printf("oh, got a signal %d\n", sig);9 10 int i = 0;11 for (i = 0; i < 5; i++)12 {13 printf("signal func %d\n", i);14 sleep(1);15 }16 }17 18 19 int main()20 {21 struct sigaction act;22 act.sa_handler = ouch;23 sigemptyset(&act.sa_mask);24 sigaddset(&act.sa_mask, SIGQUIT);25 // act.sa_flags = SA_RESETHAND;26 // act.sa_flags = SA_NODEFER;27 act.sa_flags = 0;28 29 sigaction(SIGINT, &act, 0);30 31 32 struct sigaction act_2;33 act_2.sa_handler = ouch;34 sigemptyset(&act_2.sa_mask);35 act.sa_flags = 0;36 sigaction(SIGQUIT, &act_2, 0);37 while(1){sleep(1);}38 return;}
-
阻塞,sigaction函数有阻塞的功能,比如SIGINT信号来了,进入信号处理函数,默认情况下,在信号处理函数未完成之前,如果又来了一个SIGINT信号,其将被阻塞,只有信号处理函数处理完毕,才会对后来的SIGINT再进行处理,同时后续无论来多少个SIGINT,仅处理一个SIGINT,sigaction会对后续SIGINT进行排队合并处理。
-
sa_mask,信号屏蔽集,可以通过函数sigemptyset/sigaddset等来清空和增加需要屏蔽的信号,上面代码中,对信号SIGINT处理时,如果来信号SIGQUIT,其将被屏蔽,但是如果在处理SIGQUIT,来了SIGINT,则首先处理SIGINT,然后接着处理SIGQUIT。
-
sa_flags如果取值为0,则表示默认行为。还可以取如下俩值,但是我没觉得这俩值有啥用。
SA_NODEFER,如果设置来该标志,则不进行当前处理信号到阻塞
SA_RESETHAND,如果设置来该标志,则处理完当前信号后,将信号处理函数设置为SIG_DFL行为
4.3 信号阻塞
// 2,阻塞信号XXX// 2.1 将要阻塞的信号们放入信号集中sigset_t sigs;sigemptyset(&sigs);sigaddset(&sigs, SIGINT);// 2.2 将信号集交给sigprocmaks去集中处理sigset_t oldsigs;sigprocmask(SIG_BLOCK, &sigs, &oldsigs);// 3,休眠15秒钟for(int i=15; i>0; i--){printf("%d\n", i);sleep(1);}// 4,解除信号XXX的阻塞sigprocmask(SIG_UNBLOCK, &sigs, &oldsigs);
5.flag操作
5.1 置位和清零
对应flag置位(使能)
flag |= O_NONBLOCK
对应flag清零
flag &= ~O_NONBLOCK
int fd[2];pipe(fd);char buf[10];bzero(buf, 10);// 将管道设置为非阻塞状态// a.获取当前文件的flagsint flags = fcntl(fd[0], F_GETFL);// b.在flags的基础上,设置非阻塞属性flags |= O_NONBLOCK;// c.将新的flags设置为文件的FLfcntl(fd[0], F_SETFL, flags);// 此处,管道是非阻塞的int n = read(fd[0], buf, 10);if(n > 0)printf("读取到数据: %s", buf);if(n == 0)printf("管道无写者,且无数据\n");if(n < 0)perror("读取管道失败");// 重新将管道设置为阻塞状态flags = fcntl(fd[0], F_GETFL);flags &= ~O_NONBLOCK;fcntl(fd[0], F_SETFL, flags);printf("试图读取管道内容...\n");n = read(fd[0], buf, 10);if(n > 0)printf("读取到数据: %s", buf);if(n == 0)printf("管道无写者,且无数据\n");if(n < 0)perror("读取管道失败");return 0;
}
5.共享内存
int main()
{// 0,创建一个专属的keykey_t key = ftok(PROJ_PATH, PROJ_ID);// 1,创建/打开共享内存int id = shmget(key, 1024, IPC_CREAT|0666);// 2,将共享内存映射到本进程内存空间// id: 你要映射的共享内存// NULL: 代表让系统帮你决定映射之后的入口地址// 0: 代表映射后对共享内存可读可写char *addr = shmat(id, NULL, 0);// 3,将数据写入共享内存printf("按回车给共享内存写入数据\n");getchar();snprintf(addr, 1024, "%s", "You jump, I jump!\n");// 4,解除共享内存的映射shmdt(addr);return 0;
}
读者
#include "common.h"int main()
{// 0,创建一个专属的keykey_t key = ftok(PROJ_PATH, PROJ_ID);// 1,创建/打开共享内存int id = shmget(key, 1024, IPC_CREAT|0666);// 2,将共享内存映射到本进程内存空间// id: 你要映射的共享内存// NULL: 代表让系统帮你决定映射之后的入口地址// 0: 代表映射后对共享内存可读可写char *addr = shmat(id, NULL, 0);// 3,将数据从共享内存中读出printf("按回车将共享内存中的数据打印出来\n");getchar();printf("%s", addr);// 4,解除共享内存的映射shmdt(addr);// 5,删除共享内存对象shmctl(id, IPC_RMID, NULL);return 0;
}
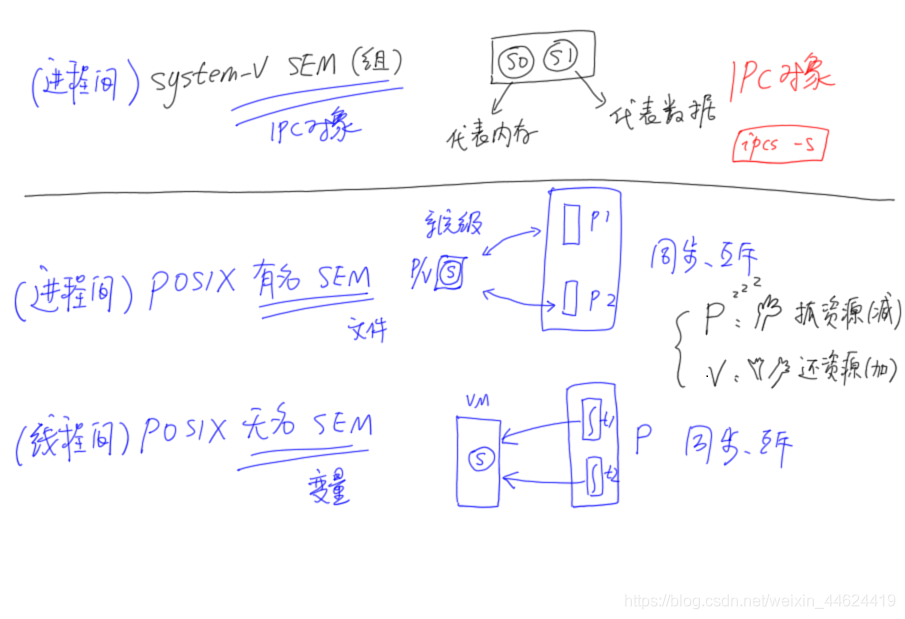
5.systemV
几个跟 system-V IPC 对象相关的命令:
ipcs -a:查看当前系统中存在的所有的 IPC 对象。
ipcs -q:查看当前系统中存在的 消息队列。
ipcs -m:查看当前系统中存在的 共享内存。
ipcs -s:查看当前系统中存在的 信号量。
删除 IPC 对象
ipcrm -Q key : 删除指定的消息队列
ipcrm -q id : 删除指定的消息队列
ipcrm -M key : 删除指定的共享内存
ipcrm -m id: 删除指定的共享内存
ipcrm -S key : 删除指定的信号量
ipcrm -s id: 删除指定的信号量
5.信号量
当同一资源的数量为N时,意味能够允许N个进程同时使用该资源,此时,可以设置相应信号量的初值为N。
如果资源只有一个,且互斥使用时,信号量的初值必须为1。
原子操作的概念与信号量的初值概念无关,说的是一小段程序操作不能被打断。
信号量用来进行资源的分配,当外设有被多个进程/线程进行访问的时候,为了防止进程/线程访问数据紊乱,需要进行类似于互斥锁,信号量的控制。因此每个这样的外设都应该有一个相近的命令的信号量进行控制,使用前进行p操作,使用后进行v操作
sem_init(&wholePic, 0, 0);
sem_init(&threadDone,0, 0);
5.1 信号量(组)
需要先定义
union semun
{int val;struct semid_ds *buf;unsigned short *array;struct seminfo *__buf;
};
#include "common.h"// 对信号量semid中的第n个元素,进行P操作
void sem_p(int semid, int n)
{struct sembuf buf;bzero(&buf, sizeof(buf));buf.sem_num = n; // 第n个元素buf.sem_op = -1;// 减操作buf.sem_flg = 0; // 默认的选项// 此处就是P操作,申请资源,可能会发生阻塞semop(semid, &buf, 1);
}// 对信号量semid中的第n个元素,进行V操作
void sem_v(int semid, int n)
{struct sembuf buf;bzero(&buf, sizeof(buf));buf.sem_num = n; // 第n个元素buf.sem_op = +1;// 加操作buf.sem_flg = 0; // 默认的选项// 此处就是V操作,增加资源,永不阻塞semop(semid, &buf, 1);
}int main()
{// 0,创建两个keykey_t key1 = ftok(PROJ_PATH, PROJ_SHM);key_t key2 = ftok(PROJ_PATH, PROJ_SEM);// 1,创建共享内存、信号量int shmid = shmget(key1, 256, IPC_CREAT|0666);int semid = semget(key2, 2, IPC_CREAT|0666);// 2,映射共享内存char *addr = shmat(shmid, NULL, 0);// 3,初始化信号量union semun a;// 将第0个信号量元素的值,设置为a.vala.val = 1;semctl(semid, 0, SETVAL, a);// 将第1个信号量元素的值,设置为a.vala.val = 0;semctl(semid, 1, SETVAL, a);// 4,不断往共享内存中写入数据while(1){// 对代表内存的第0个信号量元素进行P操作sem_p(semid, 0);// 直接往共享内存输入数据fgets(addr, 256, stdin);// 对代表数据的第1个信号量元素进程V操作sem_v(semid, 1);}return 0;
}5.2 有名信号量(进程间)
#include "common.h"int main()
{// 1,创建POSIX有名信号量sem_t *s = sem_open("/abc", O_CREAT, 0666, 1/*初始值*/);if(s == SEM_FAILED)perror("创建有名信号量失败");elseprintf("创建有名信号量成功");// 2,创建两个进程,使之使用以上信号量来进行协同pid_t p1, p2;p1 = fork();if(p1 > 0){p2 = fork();if(p2 > 0)exit(0);// 进程p2:else{while(1){// 进行P操作sem_wait(s);// 疯狂输出字母for(int i=0; i<26; i++){fprintf(stderr, "%c", 'a'+i);usleep(20*1000);}// 进程V操作sem_post(s);}}}// 进程p1:else{while(1){// 进行P操作sem_wait(s);// 疯狂输出数字for(int i=0; i<10; i++){fprintf(stderr, "%d", i);usleep(20*1000);}// 进程V操作sem_post(s);}}return 0;
}
5.3无名信号量(线程间)
#include "common.h"// 定义POSIX无名信号量
sem_t s;void *routine(void *arg)
{char *t = (char *)arg;if(strcmp(t, "t1")==0){while(1){// 进行P操作sem_wait(&s);// 疯狂输出字母for(int i=0; i<26; i++){fprintf(stderr, "%c", 'a'+i);usleep(20*1000);}// 进程V操作sem_post(&s);}}if(strcmp(t, "t2")==0){while(1){// 进行P操作sem_wait(&s);// 疯狂输出数字for(int i=0; i<10; i++){fprintf(stderr, "%d", i);usleep(20*1000);}// 进程V操作sem_post(&s);}}
}int main()
{// 1,初始化sem_init(&s, 0/*作用范围是线程间*/, 1/*初始值*/);// 2,搞两条线程去进程P/V操作pthread_t t1, t2;pthread_create(&t1, NULL, routine, "t1");pthread_create(&t1, NULL, routine, "t2");pthread_exit(NULL);
}6.消息队列(messageQueue)
// 消息结构体
struct msgbuf
{// 第一个成员是规定long型,是每个消息的标签long type;// 后续成员没有规定,想发什么数据就写什么char data[30];};// 自定义消息标签
#define J2R 1
#define R2J 2
写者
#include "common.h"int main()
{// 0,搞一个keykey_t key = ftok(PROJ_PATH, PROJ_ID);// 1,创建/打开一个消息队列// IPC_CREAT: 如果不存在就创建,如果存在就打开int id = msgget(key, IPC_CREAT | 0666);if(id == -1){perror("创建/打开消息队列失败");exit(0);}// 2,准备消息结构体struct msgbuf buf;bzero(&buf, sizeof(buf));buf.type = J2R;// 3,输入数据并发送fgets(buf.data, 30, stdin);msgsnd(id, &buf, strlen(buf.data)+1, 0/*阻塞型发送*/);return 0;
}读者
#include "common.h"int main()
{// 0,搞一个keykey_t key = ftok(PROJ_PATH, PROJ_ID);// 1,创建/打开一个消息队列// IPC_CREAT: 如果不存在就创建,如果存在就打开int id = msgget(key, IPC_CREAT | 0666);if(id == -1){perror("创建/打开消息队列失败");exit(0);}// 2,准备消息结构体来接收Jack的消息struct msgbuf buf;bzero(&buf, sizeof(buf));// 3,接收对方的消息并打印int n = msgrcv(id, &buf, 30, J2R, 0/*阻塞型接收*/);if(n == -1){perror("接收消息失败");exit(0);}elseprintf("Jack的消息: %s", buf.data);// 4,收完消息后,删除消息队列msgctl(id, IPC_RMID, NULL);return 0;
}6共享内存(建立工程模板)
// 0,创建一个专属的keykey_t key = ftok(PROJ_PATH, PROJ_ID);// 1,创建/打开共享内存int id = shmget(key, 1024, IPC_CREAT|0666);// 2,将共享内存映射到本进程内存空间// id: 你要映射的共享内存// NULL: 代表让系统帮你决定映射之后的入口地址// 0: 代表映射后对共享内存可读可写char *addr = shmat(id, NULL, 0);// 3,将数据从共享内存中读出printf("按回车将共享内存中的数据打印出来\n");getchar();printf("%s", addr);// 4,解除共享内存的映射shmdt(addr);// 5,删除共享内存对象shmctl(id, IPC_RMID, NULL);
6.1消息队列和管道的区别
管道一般用于父子进程间通信(有名管道除外,有名管道不限于父子进程通信)。而消息队列可用于你机器上的任何进程间通信(只要进程有权操作消息队列)。
7. 创建线程
常用命令
ps -uxH 查看当前用户的系统的线程数
7.0 线程的本质:
在Linux中,新建的线程并不是在原先的进程中,而是系统通过 一个系统调用clone()。该系统copy了一个和原先进程完全一样的进程,并在这个进程中执行线程函数。不过这个copy过程和fork不一样。 copy后的进程和原先的进程共享了所有的变量,运行环境。所以线程是共享全局变量和环境的。
7.1创建线程工程模板
void *routine(void *arg)
{int a = *(int *)arg;printf("a: %d\n", a);// 打印一些数字for(int i=0; i<10; i++){a++;fprintf(stderr, "%d", a);usleep(200*1000);}// 退出线程pthread_exit("abcdefg");// 线程一旦退出,立即就会变成僵尸线程
}int main()
{// 创建一条线程// 如果创建成功,系统会为这条线程分配一个ID号称为线程ID// tid: 存放线程ID// NULL: 不指定特定的线程属性,创建一条标准线程// routine: 线程的启动函数// &a: 传给线程的参数pthread_t tid;int a = 100;pthread_create(&tid, NULL, routine, (void *)&a);// 静静地等待回收子线程的资源... ...void *val;pthread_join(tid, &val); // 相当于wait()/waitpid()printf("返回值: %s\n", (char *)val);return 0;
}
7.2 子线程分离(系统回收线程资源)
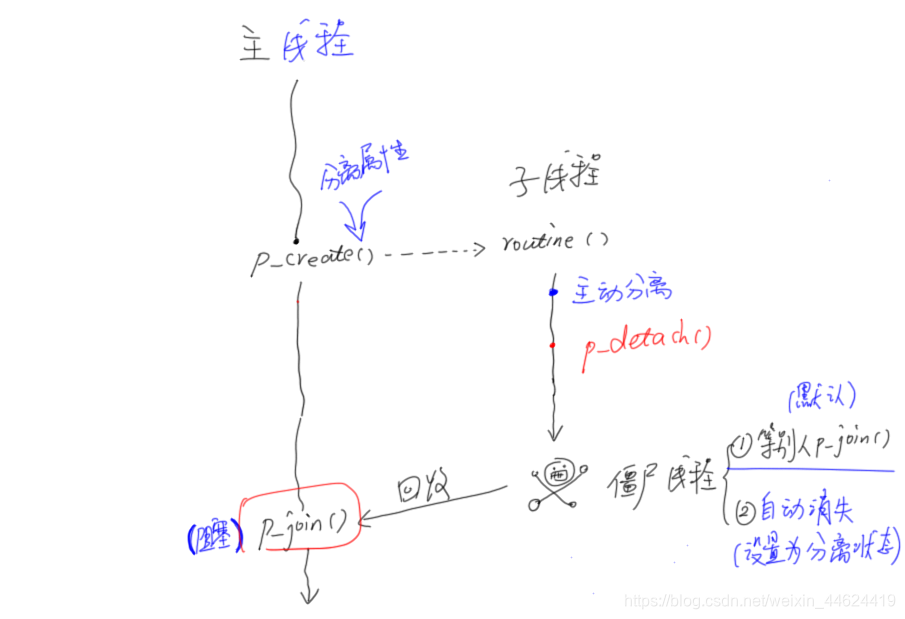
#include "common.h"
#include <errno.h>void *routine(void *arg)
{//第二种// 将自己分离出去pthread_detach(pthread_self());pthread_exit("abcd");
}int main()
{// 两种方法.第一种// 1,设置线程的属性变量pthread_attr_t attr;pthread_attr_init(&attr);pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED);// 2,根据属性变量来创建线程pthread_t tid;pthread_create(&tid, &attr, routine, NULL);void *val;int err = pthread_join(tid, &val);if(err == 0){printf("子线程返回值: %s\n", (char *)val);}else{printf("获取子线程失败: %s\n", strerror(err));}return 0;
}7.1 线程等待和唤醒 pthread_cond()
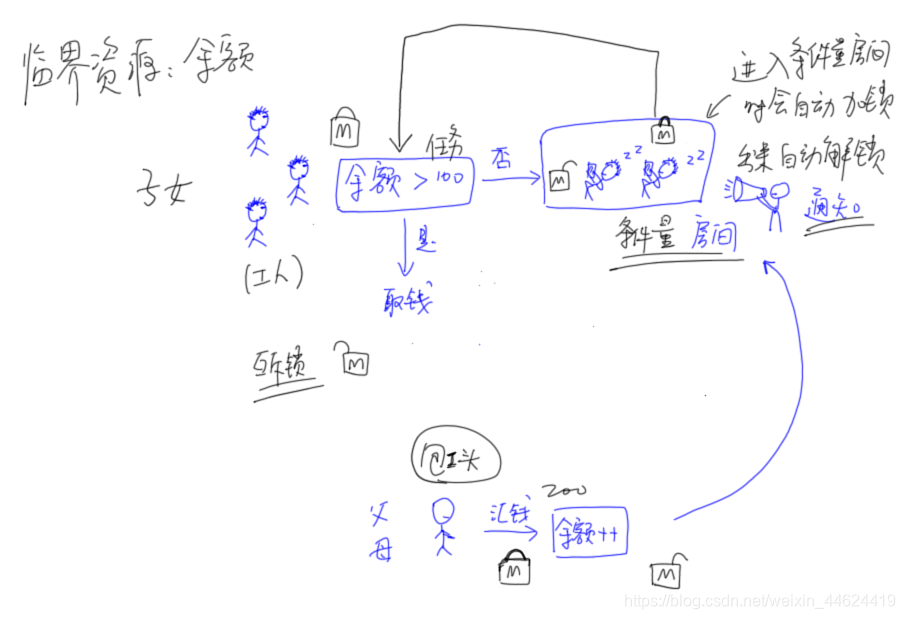
#include "common.h"// 余额
int balance = 0;// 互斥锁与条件量
pthread_mutex_t m;
pthread_cond_t v;// 所有的子线程的启动函数
void *routine(void *args)
{// 加锁pthread_mutex_lock(&m);// 判断余额while(balance <= 0){// 进入条件量v的等待房间// 进入以下函数,将自动解锁m// 退出以下函数,将自动加锁mpthread_cond_wait(&v, &m);}// 取钱balance -= 80;printf("我是第%d条线程,取了80元之后的余额是:%d\n", (int)args, balance);// 解锁pthread_mutex_unlock(&m);
}int main(int argc, char **argv) // ./main 10
{// 初始化pthread_mutex_init(&m, NULL);pthread_cond_init(&v, NULL);// 创建一些子女线程pthread_t tid;for(int i=0; i<atoi(argv[1]); i++){pthread_create(&tid, NULL, routine, (void *)i);}// 主线程充当了父母,去充钱pthread_mutex_lock(&m);balance += 500;pthread_mutex_unlock(&m);// 唤醒在条件量房间中睡觉的线程(们)
// pthread_cond_signal(&v); // 唤醒一个pthread_cond_broadcast(&v); // 唤醒全部// 退出主线程pthread_exit(NULL);
}
注意 : 无论哪种等待方式,都必须和一个互斥锁配合,以防止多个线程同时请求pthread_cond_wait()(或pthread_cond_timedwait(),下同)的竞争条件(Race Condition)。mutex互斥锁必须是普通锁(PTHREAD_MUTEX_TIMED_NP)或者适应锁(PTHREAD_MUTEX_ADAPTIVE_NP),且在调用pthread_cond_wait()前必须由本线程加锁(pthread_mutex_lock()),而在更新条件等待队列以前,mutex保持锁定状态,并在线程挂起进入等待前解锁。在条件满足从而离开pthread_cond_wait()之前,mutex将被重新加锁,以与进入pthread_cond_wait()前的加锁动作对应。
7.2互斥锁
互斥锁是s=1的二值信号量
同步是s=0的信号量 ,先执行的进行v操作,后执行的进行p操作(s=0进入睡眠状态)
7.2.1程序模板
#include "common.h"// 定义互斥锁
pthread_mutex_t m;void output(const char *s)
{while(*s != '\0'){putc(*s, stderr);usleep(1000);s += 1;}return;
}void *routine(void *arg)
{pthread_mutex_lock(&m);output("info output bu sub-thread.\n");pthread_mutex_unlock(&m);
}int main()
{// 初始化互斥锁pthread_mutex_init(&m, NULL);pthread_t tid;pthread_create(&tid, NULL, routine, NULL);pthread_mutex_lock(&m);output("message delivered by main thread.\n");pthread_mutex_unlock(&m);// 在main函数中return,相当于退出了进程,即所有的线程都被迫退出了// return 0;// 退出当前线程pthread_exit(NULL);
}7.2读写锁
#include "common.h"// 定义读写锁
pthread_rwlock_t rwlock;// 全局共享的数据
// 大家都可以访问的数据,通常被称为临界资源
int global = 100;void *routine1(void *arg)
{// 对临界资源发生操作的代码,称为临界代码// 由于以下代码对共享数据发生了读、写操作// 所以必须加写锁pthread_rwlock_wrlock(&rwlock);global += 1;printf("我是%s, global=%d\n", (char *)arg, global);sleep(1);// 离开了临界代码,必须解锁pthread_rwlock_unlock(&rwlock);pthread_exit(NULL);
}void *routine2(void *arg)
{pthread_rwlock_wrlock(&rwlock);global = 666;sleep(1);printf("我是%s, global=%d\n", (char *)arg, global);pthread_rwlock_unlock(&rwlock);pthread_exit(NULL);
}void *routine3(void *arg)
{pthread_rwlock_rdlock(&rwlock);if(global > 0)printf("我是%s,目前global>0\n");pthread_rwlock_unlock(&rwlock);pthread_exit(NULL);
}int main()
{// 初始化读写锁pthread_rwlock_init(&rwlock, NULL);// 创建一些线程pthread_t t1, t2, t3;pthread_create(&t1, NULL, routine1, "thread 1");pthread_create(&t2, NULL, routine2, "thread 2");pthread_create(&t3, NULL, routine3, "thread 3");// 主线程阻塞等待回收子线程,并销毁读写锁pthread_join(t1, NULL);pthread_join(t2, NULL);pthread_join(t3, NULL);pthread_rwlock_destroy(&rwlock);return 0;
}7.2.1互斥锁与读写锁的概念
删除线格式
一 点睛
先看看互斥锁,它只有两个状态,要么是加锁状态,要么是不加锁状态。假如现在一个线程a只是想读一个共享变量 i,因为不确定是否会有线程去写它,所以我们还是要对它进行加锁。但是这时又有一个线程b试图去读共享变量 i,发现被锁定了,那么b不得不等到a释放了锁后才能获得锁并读取 i 的值,但是两个读取操作即使是同时发生的,也并不会像写操作那样造成竞争,因为它们不修改变量的值。所以我们期望在多个线程试图读取共享变量的时候,它们可以立刻获取因为读而加的锁,而不是需要等待前一个线程释放。
读写锁可以解决上面的问题。它提供了比互斥锁更好的并行性。因为以读模式加锁后,当有多个线程试图再以读模式加锁时,并不会造成这些线程阻塞在等待锁的释放上。
读写锁是多线程同步的另外一个机制。在一些程序中存在读操作和写操作问题,对某些资源的访问会存在两种可能情况,一种情况是访问必须是排他的,就是独占的意思,这种操作称作写操作,另外一种情况是访问方式是可以共享的,就是可以有多个线程同时去访问某个资源,这种操作称为读操作。这个问题模型是从对文件的读写操作中引申出来的。把对资源的访问细分为读和写两种操作模式,这样可以大大增加并发效率。读写锁比互斥锁适用性更高,并行性也更高。
需要注意的是,这里只是说并行效率比互斥高,并不是速度一定比互斥锁快,读写锁更复杂,系统开销更大。并发性好对于用户体验非常重要,假设互斥锁需要0.5秒,使用读写锁需要0.8秒,在类似学生管理系统的软件中,可能90%的操作都是查询操作。如果突然有20个查询请求,使用的是互斥锁,则最后的查询请求被满足需要10秒,估计没人接收。使用读写锁时,因为读锁能多次获得,所以20个请求中,每个请求都能在1秒左右被满足,用户体验好的多。
二 读写锁特点
1 如果一个线程用读锁锁定了临界区,那么其他线程也可以用读锁来进入临界区,这样可以有多个线程并行操作。这个时候如果再用写锁加锁就会发生阻塞。写锁请求阻塞后,后面继续有读锁来请求时,这些后来的读锁都将会被阻塞。这样避免读锁长期占有资源,防止写锁饥饿。
2 如果一个线程用写锁锁住了临界区,那么其他线程无论是读锁还是写锁都会发生阻塞。
三 读写锁使用的函数
操作
相关函数说明
初始化读写锁
pthread_rwlock_init 语法
读取读写锁中的锁
pthread_rwlock_rdlock 语法
读取非阻塞读写锁中的锁
pthread_rwlock_tryrdlock 语法
写入读写锁中的锁
pthread_rwlock_wrlock 语法
写入非阻塞读写锁中的锁
pthread_rwlock_trywrlock 语法
解除锁定读写锁
pthread_rwlock_unlock 语法
销毁读写锁
pthread_rwlock_destroy 语法
读写锁是用来解决读者写者问题的,读操作可以共享,写操作是排他的,读可以有多个在读,写只有唯一个在写,同时写的时候不允许读。
具有强读者同步和强写者同步两种形式
强读者同步:当写者没有进行写操作,读者就可以访问;
强写者同步:当所有写者都写完之后,才能进行读操作,读者需要最新的信息,一些事实性较高的系统可能会用到该所,比如定票之类的。
读写锁的操作:
读写锁的初始化:
定义读写锁: pthread_rwlock_t m_rw_lock;函数原型: pthread_rwlock_init(pthread_rwlock_t * ,pthread_rwattr_t *);返回值:0,表示成功,非0为一错误码
读写锁的销毁:
函数原型: pthread_rwlock_destroy(pthread_rwlock_t* );返回值:0,表示成功,非0表示错误码
获取读写锁的读锁操作:分为阻塞式获取和非阻塞式获取,如果读写锁由一个写者持有,则读线程会阻塞直至写入者释放读写锁。
阻塞式:函数原型:pthread_rwlock_rdlock(pthread_rwlock_t*);非阻塞式:函数原型:pthread_rwlock_tryrdlock(pthread_rwlock_t*);返回值: 0,表示成功,非0表示错误码,非阻塞会返回ebusy而不会让线程等待
获取读写锁的写锁操作:分为阻塞和非阻塞,如果对应的读写锁被其它写者持有,或者读写锁被读者持有,该线程都会阻塞等待。
阻塞式:函数原型:pthread_rwlock_wrlock(pthread_rwlock_t*);非阻塞式:函数原型:pthread_rwlock_trywrlock(pthread_rwlock_t*);返回值: 0,表示成功
释放读写锁:
函数原型:pthread_rwlock_unlock(pthread_rwlock_t*);
总结(转):
互斥锁与读写锁的区别:
当访问临界区资源时(访问的含义包括所有的操作:读和写),需要上互斥锁;
当对数据(互斥锁中的临界区资源)进行读取时,需要上读取锁,当对数据进行写入时,需要上写入锁。
读写锁的优点:
对于读数据比修改数据频繁的应用,用读写锁代替互斥锁可以提高效率。因为使用互斥锁时,即使是读出数据(相当于操作临界区资源)都要上互斥锁,而采用读写锁,则可以在任一时刻允许多个读出者存在,提高了更高的并发度,同时在某个写入者修改数据期间保护该数据,以免任何其它读出者或写入者的干扰。
读写锁描述:
获取一个读写锁用于读称为共享锁,获取一个读写锁用于写称为独占锁,因此这种对于某个给定资源的共享访问也称为共享-独占上锁。
有关这种类型问题(多个读出者和一个写入者)的其它说法有读出者与写入者问题以及多读出者-单写入者锁。
————————————————
版权声明:本文为CSDN博主「不材之木」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/wonderisland/article/details/16940925
c++读写锁实现
https://blog.csdn.net/zxc024000/article/details/88814461
C++17,提供了shared_mutex。配合C++14,提供的shared_lock。及C++11,提供的 unique_lock, 可以方便实现读写锁。
但上述的前提是,允许你使用C++17。在国内的开发环境下,别说C++17,连C++11用的也不多。
所以,大多数时候,我们需要自己实现一套C++读写锁(C++11环境下)。
RWLock.h
#ifndef RWLOCK__H
#define RWLOCK__H#ifndef __cplusplus
# error ERROR: This file requires C++ compilation(use a .cpp suffix)
#endif#include <mutex>
#include <condition_variable>namespace linduo {class RWLock {public:RWLock();virtual ~RWLock() = default;void lockWrite();void unlockWrite();void lockRead();void unlockRead();private:volatile int m_readCount;volatile int m_writeCount;volatile bool m_isWriting;std::mutex m_Lock;std::condition_variable m_readCond;std::condition_variable m_writeCond;
};class ReadGuard {public:explicit ReadGuard(RWLock& lock);virtual ~ReadGuard();private:ReadGuard(const ReadGuard&);ReadGuard& operator=(const ReadGuard&);private:RWLock &m_lock;
};class WriteGuard {public:explicit WriteGuard(RWLock& lock);virtual ~WriteGuard();private:WriteGuard(const WriteGuard&);WriteGuard& operator=(const WriteGuard&);private:RWLock& m_lock;
};} /* namespace linduo */
#endif // RWLOCK__HRWLock.cpp
#include "RWLock.h"namespace linduo {RWLock::RWLock(): m_readCount(0), m_writeCount(0), m_isWriting(false) {}void RWLock::lockRead() {std::unique_lock<std::mutex> gurad(m_Lock);m_readCond.wait(gurad, [=] { return 0 == m_writeCount; });++m_readCount;
}void RWLock::unlockRead() {std::unique_lock<std::mutex> gurad(m_Lock);if (0 == (--m_readCount)&& m_writeCount > 0) {// One write can go onm_writeCond.notify_one();}
}void RWLock::lockWrite() {std::unique_lock<std::mutex> gurad(m_Lock);++m_writeCount;m_writeCond.wait(gurad, [=] { return (0 == m_readCount) && !m_isWriting; });m_isWriting = true;
}void RWLock::unlockWrite() {std::unique_lock<std::mutex> gurad(m_Lock);m_isWriting = false;if (0 == (--m_writeCount)) {// All read can go onm_readCond.notify_all();} else {// One write can go onm_writeCond.notify_one();}
}ReadGuard::ReadGuard(RWLock &lock): m_lock(lock) {m_lock.lockRead();
}ReadGuard::~ReadGuard() {m_lock.unlockRead();
}WriteGuard::WriteGuard(RWLock &lock): m_lock(lock) {m_lock.lockWrite();
}WriteGuard::~WriteGuard() {m_lock.unlockWrite();
}} /* namespace linduo */使用
RWLock m_Lock;void func() {// 写锁WriteGuard autoSync(m_Lock);
}void func() {// 读锁ReadGuard autoSync(m_Lock);
}
7.2 线程理解
7.2.1主线程main()函数pthread_exit(NULL)退出,不影响其他线程继续执行,进程没有结束,保留进程资源,供其他由main创建的线程使用,直至所有线程都结束。
7.2.1 在任何一个线程中调用exit函数都会导致进程结束。进程一旦结束,那么进程中的所有线程都将结束。
7.2.2 一个线程默认的状态是joinable,如果线程是joinable状态,当线程函数自己返回退出时或pthread_exit时都不会释放线程所占用堆栈和线程描述符
7.2.3 不能对一个已经处于detach状态的线程调用pthread_join
7.3线程调度策略
7.3.1 工程模板
void *routine(void *arg)
{if(*(char *)arg == 'A')nice(0);else if(*(char *)arg == 'B')nice(0);while(1){fprintf(stderr, "%c", *(char *)arg);}
}int main(int argc, char **argv)
{pthread_attr_t attr1;pthread_attr_t attr2;pthread_attr_init(&attr1);pthread_attr_init(&attr2);pthread_attr_setinheritsched(&attr1, PTHREAD_EXPLICIT_SCHED);//inherit 继承pthread_attr_setinheritsched(&attr2, PTHREAD_EXPLICIT_SCHED);//sched 时间表pthread_attr_setschedpolicy(&attr1, SCHED_RR);pthread_attr_setschedpolicy(&attr2, SCHED_RR);struct sched_param param1;struct sched_param param2;param1.sched_priority = 91;param2.sched_priority = 92;pthread_attr_setschedparam(&attr1, ¶m1);pthread_attr_setschedparam(&attr2, ¶m2);pthread_t tid1, tid2;pthread_create(&tid1, &attr1, routine, "A");pthread_create(&tid2, &attr2, routine, "B");pause();return 0;
}7.3.2 sudo才能操作pthread_attr_setschedparam(&attr1 ,SCHED_RR);
属于修改系统层面的优先级
7.3.2SCHED_RR 和SCHED_FIFO的param.sched_priority需要大于0才可以成功
7.3.2 函数nice(10)修改动态优先级
同样需要sudo执行程序
7.4线程取消函数pthread_cancel()(最好自身pthread_exit()😉
个人理解:最好自身pthread_exit();尽量不要用实现PTHREAD_CANCEL_DEFERRED属性,用一步取消属性,延迟取消属性需要遇到有取消点函数才能结束,例如fprintf
1.最好手动创建一个取消点 void pthread_testcancel(void) 检查本线程是否处于Canceld状态,如果是,则进行取消动作,否则直接返回。
此函数在线程内执行,执行的位置就是线程退出的位置,在执行此函数以前,线程内部的相关资源申请一定要释放掉,他很容易造成内存泄露。
//主函数发起
pthread_cancel(tid);
void *routine(void *avg)
{int a=0;// 关闭取消状态,即不可被取消// NULL: 代表不保留原来的状态
// pthread_setcancelstate(PTHREAD_CANCEL_DISABLE, NULL);// 将取消类型,设置为延迟//不延迟 :PTHREAD_CANCEL_ASYNCHRONOUS// NULL: 代表不保留原来的类型pthread_setcanceltype(PTHREAD_CANCEL_DEFERRED, NULL);// 拖时间/* unsigned long long i, j;long double f1, f2;for(i=0; i<10000; i++){for(j=0; j<80000; j++){f1 = f2;}}*/// 循环输出'x';while(1){// 以下函数是取消点,意味着本线程收到取消要求之后,// 在执行完取消点函数fprintf()执行之后之后,就退出。fprintf(stderr, "%c+%d", 'x',a);a++;printf("%d ",a);}
}
(未理解为什么)输出结果:
缓冲区溢出

//修改后(不稳定)fprintf(stderr, "%c+%d\r\n", 'x',a);a++;printf("%d \r\n",a);

7.4 pthread_kill
检测一个线程是否还活着的pthread函数
pthread_kill与kill有区别,是向线程发送signal。,大部分signal的默认动作是终止进程的运行,所以,我们才要用signal()去抓信号并加上处理函数。
int pthread_kill(pthread_t thread, int sig);
向指定ID的线程发送sig信号,如果线程代码内不做处理,则按照信号默认的行为影响整个进程,也就是说,如果你给一个线程发送了SIGQUIT,但线程却没有实现signal处理函数,则整个进程退出。
pthread_kill(threadid, SIGKILL)杀死整个进程。 如果要获得正确的行为,就需要在线程内实现signal(SIGKILL,sig_handler),一般是sigwait(&set, &signum),似乎signal。所以,如果int sig的参数不是0,那一定要清楚到底要干什么,而且一定要实现线程的信号处理函数,否则,就会影响整个进程。
pthread_kill的返回值:
线程仍然活着:0
线程已不存在:ESRCH
信号不合法:EINVAL
#include<stdio.h>
#include<unistd.h>
#include<signal.h>
#include<pthread.h>
#include<time.h>pthread_t tid;
sigset_t set;void myfunc()
{printf("hello\n:");
}void* mythread(void* p)
{int signum;while(1){sigwait(&set, &signum);if (SIGUSR1 == signum){myfunc();}else if (SIGUSR2 == signum){printf("I will sleep 2 seconds and exit\n");sleep(2); break;}}
}int main()
{char tmp;void *status;sigemptyset(&set);sigaddset(&set,SIGUSR1);sigaddset(&set,SIGUSR2);sigprocmask(SIG_SETMASK,&set,NULL);pthread_create(&tid,NULL,mythread,NULL);printf(":");while(1){ char* p = NULL;char str[255];scanf("%c",&tmp);p = gets(str);//printf("get %c\n", tmp);if('a'==tmp){pthread_kill(tid,SIGUSR1);//发送SIGUSR1,打印字符串。sleep(1);}else if('q'==tmp){//发出SIGUSR2信号,让线程退出,如果发送SIGKILL,线程将直接退出。pthread_kill(tid,SIGUSR2);//等待线程tid执行完毕,这里阻塞。pthread_join(tid,&status);printf("finish\n");break;}else{printf(":");}}return 0;
}
7.5线程遗言函数pthread_cleanup()(为了避免发生死互斥锁)
首先发起取消
功能:线程可以通过pthread_cancel来请求取消同一进程中的其它线程
pthread_cancel并不等待线程终止,它仅仅提出请求
pthread_cancel(t1);
void *routine(void *avg)
{// 关闭取消状态,即不可被取消// NULL: 代表不保留原来的状态
// pthread_setcancelstate(PTHREAD_CANCEL_DISABLE, NULL);// 将取消类型,设置为不延迟// NULL: 代表不保留原来的类型pthread_setcanceltype(PTHREAD_CANCEL_DEFERRED, NULL);// 拖时间/* unsigned long long i, j;long double f1, f2;for(i=0; i<10000; i++){for(j=0; j<80000; j++){f1 = f2;}}*/// 循环输出'x';while(1){// 以下函数是取消点,意味着本线程收到取消要求之后,// 在执行完取消点函数之后,就退出。fprintf(stderr, "%c", 'x');}
}
然后响应
void handler(void *arg)
{printf("我[%u]被取消了!\n", (unsigned)pthread_self());pthread_mutex_unlock(&m);
}void *routine(void *arg)
{// 写遗言// 如果将来我死了,请系统帮我执行以下handlerpthread_cleanup_push(handler, NULL);// 加锁之后,如果本线程有可能在解锁之前被杀死(或被取消)// 那么就必须先写好遗言pthread_mutex_lock(&m);printf("[%u]已经锁上了muext!,开始干活...\n", (unsigned)pthread_self());// 干一些事情...sleep(2);printf("[%u]活干完了,准备收工\n", (unsigned)pthread_self());pthread_mutex_unlock(&m);printf("[%u]锁已经解了,下班走人\n", (unsigned)pthread_self());// 如果此刻我还没死,那么后面我再死去也不怕了// 为了节省系统资源,要将刚刚写好的遗言清除// 0: 意味着清除遗言函数,并且不执行pthread_cleanup_pop(0);pthread_exit(NULL);
}
7.5线程管理:线程池
7.6进程间通信方式
管道
无名管道 pipe:适用于亲缘关系进程间的、一对一的通信
有名管道 fifo :适用于任何进程间的一对一、多对一的通信
套接字 socket:适用于跨网络的进程间通信
信号:异步通信方式
system-V IPC对象
共享内存:效率最高的通信方式
消息队列:相当于带标签的增强版管道
信号量
信号量组:参数复杂,功能强大到臃肿
POSIX有名信号量:适用于多进程,参数简单,接口明晰,老少咸宜
POSIX无名信号量:适用于多线程,参数简单,接口明晰,童叟无欺
无名管道
int pipe( int fd[2] )
功能:创建无名管道 pipe
注意:pipe 拥有两个文件描述符,一个专用于读fd[0],一个专用于写fd[1]
创建出来的 pipe 的描述符,只能通过子进程继承的方式传递给别的进程,因此只能用于亲缘进程间的通信,其他非亲缘进程无法获取 pipe 的描述符。
不能有多个进程同时对 pipe 进行写操作,否则数据有可能被覆盖
总结: pipe 适用于一对一的、具有亲缘关系的进程间的通信。
7.6.1线程间的通信方式
锁机制:包括互斥锁、条件变量、读写锁
互斥锁提供了以排他方式防止数据结构被并发修改的方法。
读写锁允许多个线程同时读共享数据,而对写操作是互斥的。
条件变量可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条件的测试是在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用。
信号量机制(Semaphore):包括无名线程信号量和命名线程信号量
信号机制(Signal):类似进程间的信号处理
线程间的通信目的主要是用于线程同步,所以线程没有像进程通信中的用于数据交换的通信机制
4).互斥锁是为了上锁而设计的,条件变量是为了等待而设计的,信号灯即可用于上锁,也可用于等待,因而可能导致更多的开销和更高的复杂性。
8.进程与线程的区别
看了一遍排在前面的答案,类似”进程是资源分配的最小单位,线程是CPU调度的最小单位“这样的回答感觉太抽象,都不太容易让人理解。
做个简单的比喻:进程=火车,线程=车厢
线程在进程下行进(单纯的车厢无法运行)
一个进程可以包含多个线程(一辆火车可以有多个车厢)
不同进程间数据很难共享(一辆火车上的乘客很难换到另外一辆火车,比如站点换乘)
同一进程下不同线程间数据很易共享(A车厢换到B车厢很容易)
进程要比线程消耗更多的计算机资源(采用多列火车相比多个车厢更耗资源)
进程间不会相互影响,一个线程挂掉将导致整个进程挂掉(一列火车不会影响到另外一列火车,但是如果一列火车上中间的一节车厢着火了,将影响到所有车厢)
进程可以拓展到多机,进程最多适合多核(不同火车可以开在多个轨道上,同一火车的车厢不能在行进的不同的轨道上)
进程使用的内存地址可以上锁,即一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。(比如火车上的洗手间)-“互斥锁”
进程使用的内存地址可以限定使用量(比如火车上的餐厅,最多只允许多少人进入,如果满了需要在门口等,等有人出来了才能进去)-“信号量”
引用出处
2.
这个答案是好多年前写的,其实很多谬误的地方。今天更新一下,不能再一知半解了。 2020年7月27日
不请自来。
看见上面几位的回答我真的是醉了。说几句我的理解。
首先来一句概括的总论:进程和线程都是一个时间段的描述,是CPU工作时间段的描述。
下面细说背景:
CPU+RAM+各种资源(比如显卡,光驱,键盘,GPS, 等等外设)构成我们的电脑,但是电脑的运行,实际就是CPU和相关寄存器以及RAM之间的事情。
一个最最基础的事实:CPU太快,太快,太快了,寄存器仅仅能够追的上他的脚步,RAM和别的挂在各总线上的设备完全是望其项背。那当多个任务要执行的时候怎么办呢?轮流着来?或者谁优先级高谁来?不管怎么样的策略,一句话就是在CPU看来就是轮流着来。
一个必须知道的事实:执行一段程序代码,实现一个功能的过程介绍 ,当得到CPU的时候,相关的资源必须也已经就位,就是万事俱备只欠CPU这个东风,这样的进程处于就绪队列,通过调度算法,某个进程得以执行,就是PC指针跳到改进程的代码开始,由CPU开始取指令,然后执行。
这里要引入一个概念:除了CPU以外所有的执行环境,主要是寄存器的一些内容,就构成了的进程的上下文环境。进程的上下文是进程执行的环境。当这个程序执行完了,或者分配给他的CPU时间片用完了,那它就要被切换出去,等待下一次CPU的临幸。在被切换出去做的主要工作就是保存程序上下文,因为这个是下次他被CPU临幸的运行环境,必须保存。
串联起来的事实:前面讲过在CPU看来所有的任务都是一个一个的轮流执行的,具体的轮流方法就是:先加载程序A的上下文,然后开始执行A,保存程序A的上下文,调入下一个要执行的程序B的程序上下文,然后开始执行B,保存程序B的上下文。。。。
========= 重要的东西出现了========
进程和线程就是这样的背景出来的,两个名词不过是对应的CPU时间段的描述,名词就是这样的功能。
进程就是上下文切换之间的程序执行的部分。是运行中的程序的描述,也是对应于该段CPU执行时间的描述。
在软件编码方面,我们说的进程,其实是稍不同的,软件进程更多的是一个无限loop,对应的是tcb块,所以和上面的cpu执行时间段还是不同的。
进程,与之相关的东东有寻址空间,寄存器组,堆栈空间等。即不同的进程,这些东东都不同,从而能相互区别。
线程是什么呢?
进程的颗粒度太大,每次的执行都要进行上下文的切换,执行,上下文切换调。如果我们把进程比喻为一个运行在电脑上的软件,那么一个软件的执行不可能是一条逻辑执行的,必定有多个分支和多个程序段,就好比要实现程序A,实际分成 a,b,c等多个块组合而成。那么这里具体的执行就可能变成:
程序A得到CPU =》CPU加载上下文,开始执行程序A的a小段,然后执行A的b小段,然后再执行A的c小段,最后CPU保存A的上下文。
这里a,b,c的执行是共享了A的上下文,CPU在执行的时候没有进行上下文切换的。这里的a,b,c就是线程,也就是说线程是共享了进程的上下文环境,的更为细小的CPU时间段。
更准确的说,线程主要共享的是进程的地址空间。
到此全文结束,再一个总结:
进程和线程都是一个时间段的描述,是CPU工作时间段的描述,不过是颗粒大小不同。
另外,注意本文说的进程线程概念和实际代码中所说的进程线程是有区别的。编程语言中的定义方式仅仅是语言自身为了的实现方式,是对进程线程概念的物化。
六、程序报错与代码调试
输出相同信息段的最好编号输出,按段分析
fprintf(stderr ,“.”);不缓冲
1. perror
2. errno:报告最近的一条系统错误
/*调用errno之前必须先将其清零*/
printf("%s\r\n", strerror(errno) );
3. 代码错误定位(常用)
颜色
http://blog.chinaunix.net/uid-28458801-id-4581042.html
printf("\033[0;34m""[%s:%d]\r\n", __FUNCTION__, __LINE__);
printf("%s:%d\n", __FILE__, __LINE__);4.显示进度
不写\n
只写\r
“已经下载了%d字节\r”
七、linux网络编程
7.1五种I/O 模式——阻塞(默认IO模式),非阻塞(常用语管道),I/O多路复用(IO多路复用的应用场景),信号I/O,异步I/O
五种I/O 模式——阻塞(默认IO模式),非阻塞(常用语管道),I/O多路复用(IO多路复用的应用场景),信号I/O,异步I/O
2018年10月28日 ⁄ 综合 ⁄ 共 3507字 ⁄ 字号 小 中 大 ⁄ 评论关闭
五种I/O 模式:
【1】 阻塞 I/O (Linux下的I/O操作默认是阻塞I/O,即open和socket创建的I/O都是阻塞I/O)
【2】 非阻塞 I/O (可以通过fcntl或者open时使用O_NONBLOCK参数,将fd设置为非阻塞的I/O)
【3】 I/O 多路复用 (I/O多路复用,通常需要非阻塞I/O配合使用)
【4】 信号驱动 I/O (SIGIO)
【5】 异步 I/O
一般来说,程序进行输入操作有两步:
1.等待有数据可以读
2.将数据从系统内核中拷贝到程序的数据区。
对于sock编程来说:
第一步: 一般来说是等待数据从网络上传到本地。当数据包到达的时候,数据将会从网络层拷贝到内核的缓存中;第二步: 是从内核中把数据拷贝到程序的数据区中。
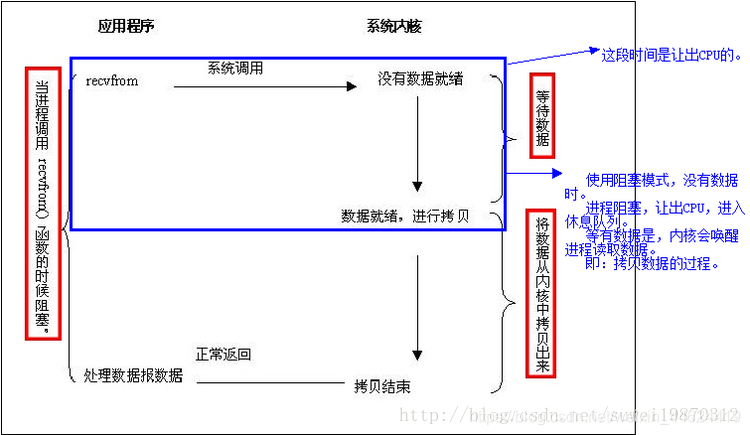
阻塞I/O模式 //进程处于阻塞模式时,让出CPU,进入休眠状态
阻塞 I/O 模式是最普遍使用的 I/O 模式。是Linux系统下缺省的IO模式。
大部分程序使用的都是阻塞模式的 I/O 。一个套接字建立后所处于的模式就是阻塞 I/O 模式。(因为Linux系统默认的IO模式是阻塞模式)
对于一个 UDP 套接字来说,数据就绪的标志比较简单:
(1)已经收到了一整个数据报
(2)没有收到。
而 TCP 这个概念就比较复杂,需要附加一些其他的变量。
一个进程调用 recvfrom ,然后系统调用并不返回知道有数据报到达本地系统,然后系统将数据拷贝到进程的缓存中。 (如果系统调用收到一个中断信号,则它的调用会被中断)
我们称这个进程在调用recvfrom一直到从recvfrom返回这段时间是阻塞的。当recvfrom正常返回时,我们的进程继续它的操作。
非阻塞模式I/O //非阻塞模式的使用并不普遍,因为非阻塞模式会浪费大量的CPU资源。
当我们将一个套接字设置为非阻塞模式,我们相当于告诉了系统内核: “当我请求的I/O 操作不能够马上完成,你想让我的进程进行休眠等待的时候,不要这么做,请马上返回一个错误给我。”
我们开始对 recvfrom 的三次调用,因为系统还没有接收到网络数据,所以内核马上返回一个 EWOULDBLOCK的错误。
第四次我们调用 recvfrom 函数,一个数据报已经到达了,内核将它拷贝到我们的应用程序的缓冲区中,然后 recvfrom 正常返回,我们就可以对接收到的数据进行处理了。当一个应用程序使用了非阻塞模式的套接字,它需要使用一个循环来不听的测试是否一个文件描述符有数据可读(称做 polling(轮询))。应用程序不停的 polling 内核来检查是否 I/O操作已经就绪。这将是一个极浪费 CPU资源的操作。这种模式使用中不是很普遍。
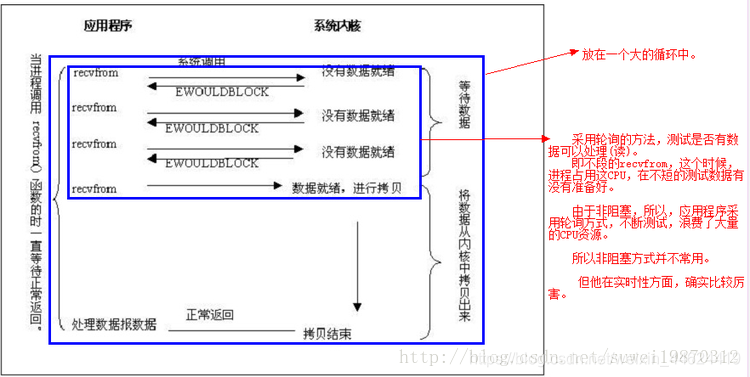
例如:
对管道的操作,最好使用非阻塞方式!
I/O多路复用 //针对批量IP操作时,使用I/O多路复用,非常有好。
在使用 I/O 多路技术的时候,我们调用 select()函数和 poll()函数或epoll函数(2.6内核开始支持),在调用它们的时候阻塞,而不是我们来调用 recvfrom(或recv)的时候阻塞。当我们调用 select函数阻塞的时候,select 函数等待数据报套接字进入读就绪状态。当select函数返回的时候, 也就是套接字可以读取数据的时候。 这时候我们就可以调用 recvfrom函数来将数据拷贝到我们的程序缓冲区中。对于单个I/O操作,和阻塞模式相比较,select()和poll()或epoll并没有什么高级的地方。而且,在阻塞模式下只需要调用一个函数:读取或发送函数。在使用了多路复用技术后,我们需要调用两个函数了:先调用 select()函数或poll()函数,然后才能进行真正的读写。多路复用的高级之处在于::它能同时等待多个文件描述符,而这些文件描述符(套接字描述符)其中的任意一个进入读就绪状态,select()函数就可以返回。
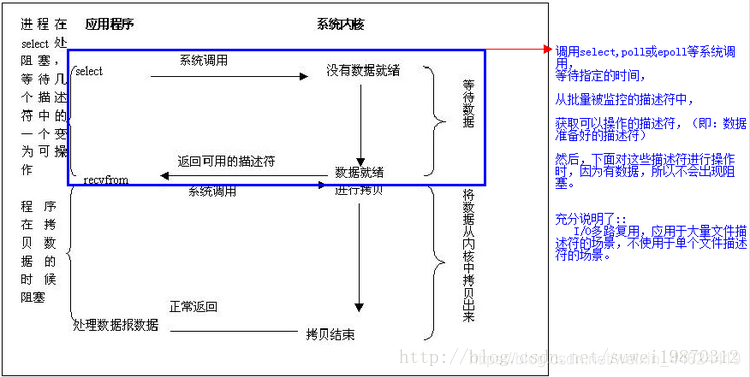
IO 多路技术一般在下面这些情况中被使用:
1、当一个客户端需要同时处理多个文件描述符的输入输出操作的时候(一般来说是标准的输入输出和网络套接字),I/O 多路复用技术将会有机会得到使用。
2、当程序需要同时进行多个套接字的操作的时候。
3、如果一个 TCP 服务器程序同时处理正在侦听网络连接的套接字和已经连接好的套接字。
4、如果一个服务器程序同时使用 TCP 和 UDP 协议。
5、如果一个服务器同时使用多种服务并且每种服务可能使用不同的协议(比如 inetd就是这样的)。
异步IO模式有::
1、信号驱动I/O模式
2、异步I/O模式
信号驱动I/O模式 //自己没有用过。
我们可以使用信号,让内核在文件描述符就绪的时候使用 SIGIO 信号来通知我们。我们将这种模式称为信号驱动 I/O 模式。
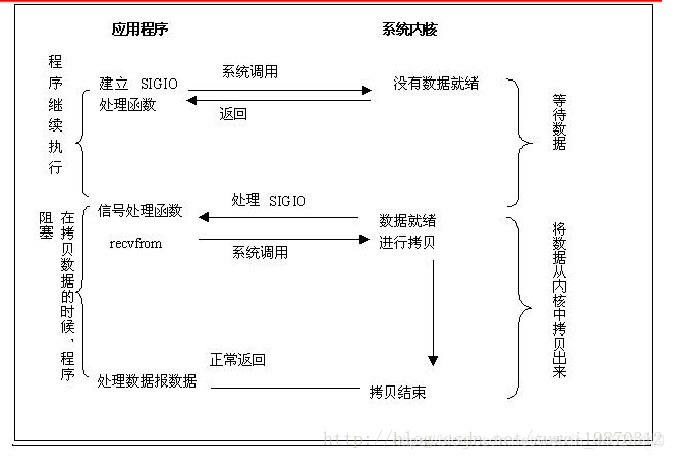
为了在一个套接字上使用信号驱动 I/O 操作,下面这三步是所必须的。
(1)一个和 SIGIO信号的处理函数必须设定。
(2)套接字的拥有者必须被设定。一般来说是使用 fcntl 函数的 F_SETOWN 参数来
进行设定拥有者。
(3)套接字必须被允许使用异步 I/O。一般是通过调用 fcntl 函数的 F_SETFL 命令,O_ASYNC为参数来实现。
虽然设定套接字为异步 I/O 非常简单,但是使用起来困难的部分是怎样在程序中断定产生 SIGIO信号发送给套接字属主的时候,程序处在什么状态。
1.UDP 套接字的 SIGIO 信号 (比较简单)
在 UDP 协议上使用SIGIO 非常简单.这个信号将会在这个时候产生:
1、套接字收到了一个数据报的数据包。
2、套接字发生了异步错误。
当我们在使用 UDP 套接字异步 I/O 的时候,我们使用 recvfrom()函数来读取数据报数据或是异步 I/O 错误信息。
2.TCP 套接字的 SIGIO 信号 (因为复杂,实际一般用的是socket的异步IO)
不幸的是,SIGIO 几乎对 TCP 套接字而言没有什么作用。因为对于一个 TCP 套接字来说,SIGIO 信号发生的几率太高了,所以 SIGIO 信号并不能告诉我们究竟发生了什么事情。
在 TCP 连接中, SIGIO 信号将会在这个时候产生:
l 在一个监听某个端口的套接字上成功的建立了一个新连接。
l 一个断线的请求被成功的初始化。
l 一个断线的请求成功的结束。
l 套接字的某一个通道(发送通道或是接收通道)被关闭。
l 套接字接收到新数据。
l 套接字将数据发送出去。
l 发生了一个异步 I/O 的错误。
一个对信号驱动 I/O 比较实用的方面是 NTP(网络时间协议 Network Time Protocol)服务器,它使用 UDP。这个服务器的主循环用来接收从客户端发送过来的数据报数据包,然后再发送请求。对于这个服务器来说,记录下收到每一个数据包的具体时间是很重要的。
因为那将是返回给客户端的值,客户端要使用这个数据来计算数据报在网络上来回所花费的时间。图 6-8 表示了怎样建立这样的一个 UDP 服务器。
异步I/O模式 //比如写操作,只需用写,不一定写入磁盘(这就是异步I/O)的好处。异步IO的好处效率高。
当我们运行在异步 I/O 模式下时,我们如果想进行 I/O 操作,只需要告诉内核我们要进行 I/O 操作,然后内核会马上返回。具体的 I/O 和数据的拷贝全部由内核来完成,我们的程序可以继续向下执行。当内核完成所有的 I/O 操作和数据拷贝后,内核将通知我们的程序。
异步 I/O 和 信号驱动I/O的区别是:
1、信号驱动 I/O 模式下,内核在操作可以被操作的时候通知给我们的应用程序发送SIGIO 消息。
2、异步 I/O 模式下,内核在所有的操作都已经被内核操作结束之后才会通知我们的应用程序。
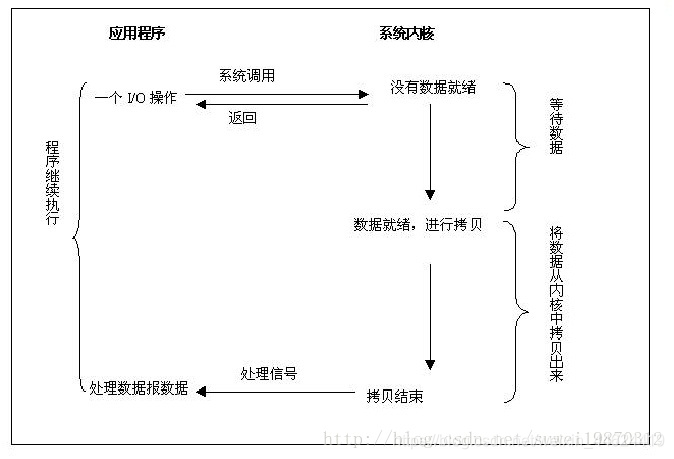
原地址:https://www.xuebuyuan.com/3256674.html
7.1 什么是套接字?套接字之读写:recvfrom()、read() 和sendto() 、write()(转载)
首先明白什么是套接字:
套接字(socket)是一个抽象层,应用程序可以通过它发送或接收数据,可对其进行像对文件一样的打开、读写和关闭等操作。套接字允许应用程序将I/O插入到网络中,并与网络中的其他应用程序进行通信。网络套接字是IP地址与端口的组合。
传输层实现端到端的通信,因此,每一个传输层连接有两个端点。那么,传输层连接的端点是什么呢?不是主机,不是主机的IP地址,不是应用进程,也不是传输层的协议端口。传输层连接的端点叫做套接字(socket)。根据RFC793的定义:端口号拼接到IP地址就构成了套接字。所谓套接字,实际上是一个通信端点,每个套接字都有一个套接字序号,包括主机的IP地址与一个16位的主机端口号,即形如(主机IP地址:端口号)。例如,如果IP地址是210.37.145.1,而端口号是23,那么得到套接字就是(210.37.145.1:23)
一般的网络系统提供了三种不同类型的套接字,以供用户在设计网络应用程序时根据不同的要求来选择。这三种套接为流式套接字(SOCK-STREAM)、数据报套接字(SOCK-DGRAM)和原始套接字(SOCK-RAW)。
(1)流式套接字。它提供了一种可靠的、面向连接的双向数据传输服务,实现了数据无差错、无重复的发送。流式套接字内设流量控制,被传输的数据看作是无记录边界的字节流。在TCP/IP协议簇中,使用TCP协议来实现字节流的传输,当用户想要发送大批量的数据或者对数据传输有较高的要求时,可以使用流式套接字。
(2)数据报套接字。它提供了一种无连接、不可靠的双向数据传输服务。数据报以独立的形式被发送,并且保留了记录边界,不提供可靠性保证。数据在传输过程中可能会丢失或重复,并且不能保证在接收端按发送顺序接收数据。在TCP/IP协议簇中,使用UDP协议来实现数据报套接字。在出现差错的可能性较小或允许部分传输出错的应用场合,可以使用数据报套接字进行数据传输,这样通信的效率较高。
(3)原始套接字。该套接字允许对较低层协议(如IP或ICMP)进行直接访问,常用于网络协议分析,检验新的网络协议实现,也可用于测试新配置或安装的网络设备。
转载地址
7.1 recv,write,send,read,recvfrom,sendto区别(转载)
recv(),recvfrom()调用被用于从套接字接收消息。 它们可用于在无连接和面向连接的套接字上接收数据。正如,recv()和read()之间的唯一区别是标志的存在,使用零标志参数时,recv()通常等效于read()。同理,recv(sockfd,buf,len,flags)等价于recvfrom(sockfd,buf,len,flags,NULL,NULL)。
成功完成后,这两个调用都将返回消息的长度。 如果消息太长而无法容纳在提供的缓冲区中,则多余的字节可能会被丢弃,此时,返回值则取决于接收消息的套接字类型。
转载链接
7.2udp互发
发送
bind绑定后是指定ip和端口,不bind则是系统自动分配
#include "common.h"int main(int argc, char **argv) // ./Jack 对方IP 对方端口
{// 1,创建UDP通信端点,区别点SOCK_DGRAMint sockfd = Socket(AF_INET, SOCK_DGRAM, 0);// 2,准备好对方的地址(IP+PORT)struct sockaddr_in addr;socklen_t len = sizeof(addr);bzero(&addr, len);addr.sin_family = AF_INET; // 指定协议族,这里是IPv4地址addr.sin_addr.s_addr = inet_addr(argv[1]); // IP地址addr.sin_port = htons(atoi(argv[2])); // PORT端口号// 3,给对方发去消息char buf[50];while(1){bzero(buf, 50);fgets(buf, 50, stdin);sendto(sockfd, buf, strlen(buf), 0,(struct sockaddr *)&addr, len);}return 0;
}接收
#include "common.h"int main(int argc, char **argv) // ./Rose 自身IP 自身端口
{// 1,创建UDP通信端点int sockfd = Socket(AF_INET, SOCK_DGRAM, 0);// 2,准备好要绑定的自身的地址(IP+PORT)struct sockaddr_in addr;socklen_t len = sizeof(addr);bzero(&addr, len);addr.sin_family = AF_INET; // 指定协议族,这里是IPv4地址addr.sin_addr.s_addr = inet_addr(argv[1]); // IP地址addr.sin_port = htons(atoi(argv[2])); // PORT端口号// 3,绑定地址Bind(sockfd, (struct sockaddr *)&addr, len);// 4,静静等待对方的数据char buf[50];while(1){bzero(buf, 50);recvfrom(sockfd, buf, 50, 0, NULL, NULL);//阻塞等待,知道接收到sendto的数据发送printf("收到对方消息:%s", buf);}return 0;
}
7.2 udp信号处理 -> 7.1文件状态原理
#include "wrap.h"int sockfd;// 信号处理函数
void readMsg(int sig)
{char buf[50];bzero(buf, 50);recvfrom(sockfd, buf, 50, 0, NULL, NULL);printf("收到信息: %s", buf);
}int main(int argc, char **argv) // ./main IP PORT
{// 1,创建UDP套接字sockfd = Socket(AF_INET, SOCK_DGRAM, 0);// 2,绑定IP、端口struct sockaddr_in addr;socklen_t len = sizeof(addr);bzero(&addr, len);addr.sin_family = AF_INET;addr.sin_addr.s_addr = inet_addr(argv[1]);addr.sin_port = htons(atoi(argv[2]));Bind(sockfd, (struct sockaddr *)&addr, len);// 3,准备使用信号驱动的方式来接收UDP数据// 3.1 关联信号及其处理函数signal(SIGIO, readMsg);// 3.2 将套接字的模式设定更为异步模式,从而触发信号int state = fcntl(sockfd, F_GETFL);state |= O_ASYNC;fcntl(sockfd, F_SETFL, state);// 3.3 设定信号的属主fcntl(sockfd, F_SETOWN, getpid());// 服务器现在可以去干别的了for(int i=0; ; i++){printf("%d\n", i);sleep(1);}return 0;
}7.3 UDP广播
7.3.1 可能需要不同物理网卡才能实现这个功能
#include "wrap.h"// 使用UDP发送广播消息int main(int argc, char **argv) // ./main 192.168.1.100 50001 --> 单播// ./main 192.168.1.255 50001 --> 广播
{// 1,准备好UDP通信端点int sockfd = Socket(AF_INET, SOCK_DGRAM, 0);struct sockaddr_in addr;socklen_t len = sizeof(addr);bzero(&addr, len);addr.sin_family = AF_INET;addr.sin_addr.s_addr = inet_addr(argv[1]);addr.sin_port = htons(atoi(argv[2]));// 2,使能广播int on = 1;int a = setsockopt(sockfd, SOL_SOCKET, SO_BROADCAST,&on, sizeof(on));if(a != 0){perror("使能广播失败");exit(0);}// 3,发送消息int b = sendto(sockfd, "abcd\n", 5, 0, (struct sockaddr *)&addr,len);printf("发送了%d个字节\n", b);return 0;
}7.4 TCP
- tcp基础协议 三次握手四次挥手
- listen(sockfd, 3)//最多可以接收1024个连接,但是现在设置为最多可接收3个
- accept函数会阻塞等待知道有客户端请求到达。调用accept()后当有一个新的连接是,它将返回一个新的套接字文件描述符,因此目前有两个套接字了,原来的一个还在侦听你的那个端口是否有新的连接,另外新的描述符则是可以read和write操作。
- FD_ISSET(sockfd, &rset) 判断是否有新的连接,rset属于connect请求就绪. FD_ISSET(p->connfd, &rset),判断是否发来数据,rset是读就绪
- 查看有几个tcp套接字 netstat -ant
- udp netstat -anu
7.4.1 发送
int ConnectServer(char* ip ,char* port)
{//create tcp socketint sockfd = socket(AF_INET, SOCK_STREAM, 0);if(sockfd == -1){perror("Failed to create UDP socket!");exit(0);}//define ip and protstruct sockaddr_in addr;socklen_t len = sizeof(addr);memset(&addr, 0, len);addr.sin_family = AF_INET;//指定协议族,选择ipv4addr.sin_addr.s_addr = inet_addr(ip);// ip addressaddr.sin_port = htons(atoi(port));//the port of connection//connet to the server and bind socketint connfd = connect(sockfd, (struct sockaddr *)&addr, len);if (connfd != 0){perror("Failed to create TCP connect!");exit(0);}return sockfd;
}
7.4.1 接收
int main(int argc, char **argv) // ./main IP PORT
{if(argc != 3){printf("参数错误!用法: <IP> <PORT>\n");exit(0);}// 1,创建TCP套接字int sockfd = Socket(AF_INET, SOCK_STREAM, 0);// 2,准备好地址结构体struct sockaddr_in addr;socklen_t len = sizeof(addr);bzero(&addr, len);addr.sin_family = AF_INET;addr.sin_addr.s_addr = inet_addr(argv[1]);addr.sin_port = htons(atoi(argv[2]));// 3,绑定套接字和地址Bind(sockfd, (struct sockaddr *)&addr, len);// 4,将套接字设置为监听状态,顺便设置最大同时连接个数listen(sockfd, 3);struct sockaddr_in peer;len = sizeof(peer);// 5,循环地接收远端连接pid_t pid;int connfd;while(1){bzero(&peer, len);connfd = accept(sockfd, (struct sockaddr *)&peer, &len);// 父进程持续监听连接请求if((pid=fork()) > 0){continue;}// 子进程专门去处理新建的已连接套接字connfdchar buf[100];while(1){bzero(buf, 100);if(read(connfd, buf, 100) > 0){printf("[%s:%hu]: %s", inet_ntoa(peer.sin_addr),ntohs(peer.sin_port), buf);}}}// 释放资源close(connfd);close(sockfd);return 0;
}
7.4.2服务器轮询接收
// TCP轮询服务器int main(int argc, char **argv) // ./main IP PORT
{if(argc != 3){printf("参数错误!用法: <IP> <PORT>\n");exit(0);}// 1,创建TCP套接字int sockfd = Socket(AF_INET, SOCK_STREAM, 0);// 2,准备好地址结构体struct sockaddr_in addr;socklen_t len = sizeof(addr);bzero(&addr, len);addr.sin_family = AF_INET;addr.sin_addr.s_addr = inet_addr(argv[1]);addr.sin_port = htons(atoi(argv[2]));// 3,绑定套接字和地址Bind(sockfd, (struct sockaddr *)&addr, len);// 4,将套接字设置为监听状态,顺便设置最大同时连接个数listen(sockfd, 3);// 5,将监听套接字设置为非阻塞状态int state = fcntl(sockfd, F_GETFL);state |= O_NONBLOCK;fcntl(sockfd, F_SETFL, state);struct sockaddr_in peer;len = sizeof(peer);// 6,循环地接收远端连接int connfd[100];bzero(connfd, sizeof(connfd));int k = 0;while(1){bzero(&peer, len);connfd[k] = accept(sockfd, (struct sockaddr *)&peer, &len);if(connfd[k] == -1)continue;printf("欢迎[%s:%hu]\n", inet_ntoa(peer.sin_addr),ntohs(peer.sin_port));// 将新的已连接套接字设置为非阻塞int state = fcntl(connfd[k], F_GETFL);state |= O_NONBLOCK;fcntl(connfd[k], F_SETFL, state);k++;char buf[100];for(int i=0; i<k; i++){// 跳过所有已经关闭了的客户端if(connfd[i] == -1)continue;bzero(buf, 100);int n = read(connfd[i], buf, 100);printf("n:%d\n", n);// 客户端发来了数据if(n > 0){printf("%s", buf);}// 客户端已经关闭了else if(n == 0){close(connfd[i]);connfd[i] = -1;}}}// 释放资源close(connfd);close(sockfd);return 0;
}7.4.3多路复用接收
int select(int nfds, fd_set* readset, fd_set* writeset, fe_set* exceptset, struct timeval* timeout);
参数:
nfds 需要检查的文件描述字个数readset 用来检查可读性的一组文件描述字。writeset 用来检查可写性的一组文件描述字。exceptset 用来检查是否有异常条件出现的文件描述字。(注:错误不包括在异常条件之内)timeout 超时,填NULL为阻塞,填0为非阻塞,其他为一段超时时间
返回值:
返回fd的总数,错误时返回SOCKET_ERROR
//每次循环都要清空,否则不能检测描述符变化
int chat_recv_process(int socket_fd)
{int read_return = 0;char chat_buf[100];int maxfd = 0;//1.reset rset wset esetFD_ZERO(&rset);FD_ZERO(&wset);FD_ZERO(&eset);maxfd = socket_fd;//bind socket_fd to rset ,when new connect coming then rset will set//把socket_fd 置入 rset集合,当有新的连接到来时,相应绑定的rset位会setFD_SET(socket_fd, &rset);list_for_each(temp_pos,&user_head->list){temp_p = list_entry(temp_pos, struct user, list);FD_SET(temp_p->connfd, &rset);maxfd = (maxfd > temp_p->connfd) ? maxfd : temp_p->connfd;}//2.select(maxfd+1, &rset, &wset, &eset, NULL);//a.judge whether there is a new connectionsocklen_t len = 0;if (FD_ISSET(socket_fd, &rset)){//get a new connection,create a new user list nodestruct user *newone = calloc(1, sizeof(struct user));len = sizeof(newone->addr_in);newone->connfd = accept(socket_fd, (struct sockaddr *)&newone->addr_in, &len);if (newone->connfd == -1){perror("Failed to accept socket");exit(0);}//put the new user list node to taillist_add_tail(&newone->list, &user_head->list);//distribute user idnewone->ID = ID;ID++;//notify all users that a new user has joined//send welcome and ID to new userchat_welcome(newone);//chat_server show message to screenprintf("[%s:%hu]上线了\n", inet_ntoa(newone->addr_in.sin_addr), ntohs(newone->addr_in.sin_port));}//b.judge whether there is user send massage//and judge if someuser had offlinelist_for_each_safe(temp_pos, temp_n, &user_head->list){temp_p = list_entry(temp_pos, struct user, list);//1.判断每个用户是否已发来数据//judge whether there is user send massageif ( FD_ISSET(temp_p->connfd, &rset) )//rset状态有变化 rset state had been changed{char private_filename[50];read_return = 0;char *private_strstr;memset(chat_buf, 0, sizeof(char)*100);if (priavate_file_flag == 0){read_return = read(temp_p->connfd, chat_buf, 100);//a.收到消息 receive massageif (read_return > 0){//处理接收文件命令//process receive file commandprivate_strstr = strstr(chat_buf, "+");if (private_strstr != NULL){sscanf(private_strstr,"+%ld %s", &private_recv_length, private_filename);priavate_file_flag = 1;printf("\n开始接收文件%s\n", private_filename); }}//b.没收到消息,有人下线了 get none massage, someone had offlineif (read_return == 0){printf("用户%d:下线了!\n", temp_p->ID);close(temp_p->connfd);list_del(&temp_p->list);free(temp_p);}//信号帧格式 :[ID] [chat_buf]//提取信号帧 ":"//signal frame format :[ID] [chat_buf]//get signal flag ":"private_strstr = strstr(chat_buf, ":");if (private_strstr == NULL)//群发{if (priavate_file_flag == 0){//群发消息broadcastMsg(temp_p, chat_buf);printf("已广播用户%d发来消息:%s\n",temp_p->ID, chat_buf);}}else//私聊{ private_chat(temp_p, atoi(private_strstr+1), private_strstr+3);} }//开始接收文件if (priavate_file_flag == 1){private_recv_file(temp_p, private_filename);}}}return 0;
}
7.4.4 oob
7.4.5 http实现
#include "cJSON/cJSON.h"int retCode(const char *httpResponse)
{char *version = "HTTP/1.1 ";char *p = strstr(httpResponse, version);if(p != NULL)return atoi(p + strlen(version));elsereturn -1;
}int getLen(const char *httpResponse)
{char *str = "Content-Length: ";char *p = strstr(httpResponse, str);if(p != NULL)return atoi(p + strlen(str));elsereturn -1;
}int main()
{// 1,获取服务器的IP地址struct hostent *he = gethostbyname("wuliu.market.alicloudapi.com");struct in_addr serverIP = *(struct in_addr *)he->h_addr_list[0];printf("服务器IP:%s\n", inet_ntoa(serverIP));// 2,发起TCP连接int sockfd = Socket(AF_INET, SOCK_STREAM, 0);struct sockaddr_in addr;socklen_t len = sizeof(addr);addr.sin_family = AF_INET;addr.sin_addr = serverIP;addr.sin_port = htons(80);Connect(sockfd, (struct sockaddr *)&addr, len);printf("连接服务器成功!\n");// 3,发送HTTP请求char *httpRequest = "GET /kdi?no=557000565428692 HTTP/1.1\r\n""Host: wuliu.market.alicloudapi.com\r\n""Authorization: APPCODE d487d937315848af80710a06f4592fee\r\n""\r\n";write(sockfd, httpRequest, strlen(httpRequest));printf("HTTP请求报文:\n%s", httpRequest);// 4,读取HTPP响应头部,并分析关键信息char *httpResponse = calloc(1, 1024);int total = 0;while(1){total += read(sockfd, httpResponse+total, 1);if(strstr(httpResponse, "\r\n\r\n"))break;}printf("响应头部:\n%s", httpResponse);int code = retCode(httpResponse);if(code < 200 || code >= 300){printf("HTTP响应失败");exit(0);}elseprintf("响应码:%d\n", code);// 5,读取HTTP响应正文(即JSON数据)并解析出关键信息int jsonLen = getLen(httpResponse);printf("json数据长度:%d\n", jsonLen);char *json = calloc(1, jsonLen);total = 0;while(jsonLen > 0){int n = read(sockfd, json+total, jsonLen);total += n;jsonLen -= n;}cJSON *root = cJSON_Parse(json);cJSON *result = cJSON_GetObjectItem(root, "result");cJSON *list = cJSON_GetObjectItem(result, "list");for(int i=0; i<cJSON_GetArraySize(list); i++){cJSON *item = cJSON_GetArrayItem(list, i);printf("时间: %s\n", cJSON_GetObjectItem(item, "time")->valuestring);printf("位置: %s\n\n", cJSON_GetObjectItem(item, "status")->valuestring);}return 0;
}八 shell
#!/bin/bashif [ $# -eq 1 ]
then echo params is right
elseecho wrong paramsexit 0
fiprime()
{n=2while [ $n -lt $1 ]dom=`expr $1 % $n`if [ $m -eq 0 ]thenreturn 1fin=$(($n+1))#echo ndonereturn 0
}i=1
while [ $i -le $1 ]
doprime $iif [ $? -eq 0 ]then echo $ifii=$(($i+1))done
m=`ls`
echo $m
exit 1shell -eq处理数值 == 处理字符
九 C++
9.1 全局变量作用域
cout<<::y<<endl;
using namespace std
using std::cout;
using std::cin;
9.2类型强转
(type-id)expression//转换格式1
type-id(expression)//转换格式2
9.3引用&
只能对变量取引用
引用不能单独定义
c++中引用可以作为函数形参调用后可以实现数据交换。但是c语言中变量不行,需要指针才能实现函数交换数据
引用的意义:
C++中的引用旨在大多数的情况下替代指针
功能性:可以满足多数需要使用指针的场合
安全性:可以避开由于指针操作不当带来的内存错误
操作性:简单易用,又不失功能强大
理解安全性:内存能初始化操作,避免野指针
引用可以看做是一个常量指针

问题:调用引用后的结构体的时候是p->a 还是p.a
定义
struct a
{
int g;
char b;
};
调用
struct a l;
struct a &h = l;
h.b = 2;
(&h)->b = 1;
9.4String
将c++标准字符串转化为C语言字符串
const char* p = s.c_str();
9.5函数重载
函数默认参数
不可以形成重载的情况:
- 函数的返回值类型差异不可作为重载的条件
- 两个函数名和函数参数列表完全一致(会报错)
- static函数声明不行
- 当函数参数是const的时候
普通const类型不可以
指针型可以 - 当函数参数是引用的时候,分情况
实参是常量的时候可以重载
实参为变量的时候不能重载
引用一般不作为重载的条件
9.6 new
如果调用类类型的话需要用new调用构造函数
同理delete 会调用类的析构函数
其他情况new 和malloc 一样 delete 和free一样
9.7 类
9.7.1深度拷贝
#include <iostream>
#include <cstring>using namespace std;class A
{int size;// 如果一个类中有指针,那么就意味着有类外资源(内存)存在// 此时需要注意几点:// 1,需要考虑深浅拷贝的问题// 2,必须重写析构函数int *p;public:// 类中默认就有的东西:// 1,无参构造函数A(){}A(int s):size(s){p = new int[size];}~A(){delete [] p;}// 2,拷贝构造函数(即参数为本类对象的构造函数)// 拷贝构造函数会默认将所有的类成员复制一份A(const A &r){size = r.size;// 默认浅拷贝: 只复制指针,没复制真正的内存
// p = r.p;// 深拷贝: 复制真正的内存p = new int[size];memcpy(p, r.p, size*sizeof(int));}// 3,赋值操作符函数// 赋值操作符函数会默认将所有的类成员复制一份A & operator=(const A &r){// 浅拷贝
// size = r.size;
// p = r.p;// 深拷贝size = r.size;delete [] p;p = new int[r.size];memcpy(p, r.p, size*sizeof(int));return *this;}// 关于this指针// 1,任何类方法,都有一个默认的隐藏指针: this// 2,this指针就指向调用该类方法的对象void f(){size = 100;this->size = 100;}
};int main()
{A a(100);A b(a);A c;c = a;// 定义类对象,会自动调用类构造函数
// A a;
// A b(a);// // 在C++中,任何操作符都是函数
// A c;
// c = a;
// c.operator=(a);return 0;
}第二个例子
#include <iostream>
using namespace std;class A
{
private:int a;
public:A(int i){a=i;} //内联的构造函数A(A &aa);int geta(){return a;}
};
A::A(A &aa) //拷贝构造函数
{a=aa.a;cout<<"拷贝构造函数执行!"<<endl;
}int get_a(A aa) //参数是对象,是值传递,会调用拷贝构造函数
{return aa.geta();
}int get_a_1(A &aa) //如果参数是引用类型,本身就是引用传递,所以不会调用拷贝构造函数
{return aa.geta();
}A get_A() //返回值是对象类型,会调用拷贝构造函数。会调用拷贝构造函数,因为函数体内生成的对象aa是临时的,离开这个函数就消失了。所有会调用拷贝构造函数复制一份。
{A aa(1);return aa;
}A& get_A_1() //会调用拷贝构造函数,因为函数体内生成的对象aa是临时的,离开这个函数就消失了。所有会调用拷贝构造函数复制一份。
{A aa(1);return aa;
}int _tmain(int argc, _TCHAR* argv[])
{A a1(1);A b1(a1); //用a1初始化b1,调用拷贝构造函数A c1=a1; //用a1初始化c1,调用拷贝构造函数int i=get_a(a1); //函数形参是类的对象,调用拷贝构造函数int j=get_a_1(a1); //函数形参类型是引用,不调用拷贝构造函数A d1=get_A(); //调用拷贝构造函数A e1=get_A_1(); //调用拷贝构造函数return 0;
}
https://blog.csdn.net/weixin_41066529/article/details/89671077
9.7.1 静态方法
.h定义
using std::string; //引入命名空间std中的符号string类型
class Tom
{/*private 只能在本类域中访问1,逻辑上,内部数据封装为私有才能保证安全性,也简化了使用接口2,语法上,私有成员只能被本类的方法访问,即只能在本类域内访问*/private:float weight;static int totalnumber;//静态变量const string _name; //初始化数据后不可以再更改void eat();//protected:public:enum gender{male , female} sex; //枚举Tom(float w = 10,enum gender s);//构造函数+默认参数~Tom();static float averageNumber(int number);};
.c文件
int Tom::totalnumber = 0;//静态成员数据,需要在类外初始化
Tom::Tom(float w,enum gender s, string name)
:_name(name)//1.先执行构造列表
{weight = w;//2.再执行初始化变量语句sex = s;totalnumber++;//创建一个成员后就+1
}
Tom::~Tom()
{totalnumber--;
}/*1. 在逻辑上,静态变量属于整个类,如果需要定义属于类的属性和方法,那么应该设计为静态成员2. 在语法上,在类内仅仅是声明,但是需要在类外部进行定义变量分配内存,内存是和具体对象的内存管理分开的*/static float Tom::averageNumber(int score)//静态方法只能访问静态变量
{return score/totalnumber;
}
void Tom::eat(void)
{//eat;
}
调用
Tom tom(20,Tom::male);
Tom::averageNumber();//静态方法直接用类名或者对象都可以
tom::averageNumber();
9.7.1类嵌套
class P1
{int _x;public : P1(int x):_x(x){cout << "构造了P1" << endl;}~P1(){cout << "析构了P1" << endl;}
}class P2
{int _x;public : P1(int x):_x(x){cout << "构造了P2" << endl;}~P1(){cout << "析构了P2" << endl;}
}class Whole
{Whole(int p1 ,int p2):_p1(p1),_p2(p2){cout << "构造了Whole" << endl;}~Whole(){cout << "析构了Whole" << endl;}private ://p1和p2的初始化条件必须在构造函数的初始化列表中进行提供才能初始化// p1和p2的初始化次序由它们的定义次序决定,跟初始化列表次序无关P1 _p1;P2 _p2;
}
结果:
构造了P1
构造了P2
构造了Whole
析构了Whole
析构了P2
析构了P1
示例代码三
定义
class card
{string bank;string name;string number;public:card(string bank, string name, string number);virtual void enquiry();virtual void deposit(float amount)=0;virtual bool widthdraw(float amount)=0;
};// 储蓄卡
class cashCard : public card
{float balance;public:cashCard(string bank, string name,string number, float balance);void enquiry();// 必须复写(override)父类的纯虚函数void deposit(float amount);bool widthdraw(float amount);
};
.cpp
// 储蓄卡
cashCard::cashCard(string bank, string name, string number, float balance):card(bank, name, number), balance(balance)
{
}
9.7.2继承
继承关系

class Animal
{}class Cat: public Animal//public继承方式
{
}
Cat cat;//先构造Animal 再构造cat 先析构cat 再析构annimal
9.7.3 虚继承
示例
#include <iostream>using namespace std;// 交通工具
class A
{
public:A(int id=0):ID(id){cout << "构造A" << endl;}int ID;
};class B : public A
{
public:// 以下语句中的A(id)是显式地调用A的构造函数// 当直接定义B对象的时候,显然会调用它// 但是如果是通过D触发,那么就不会调用B(int id=0):A(id){cout << "构造B" << endl;}
};class C : public A
{
public:C(int id=0):A(id){cout << "构造C" << endl;}
};class D : public B, public C
{
public:D(int id){cout << "构造D" << endl;}
};int main()
{D d(99);//d.ID = 99;//这句报错,不知道ID是B还是Ccout << d.ID << endl;return 0;
}输出:
构造A
构造B
构造A
构造C
构造D
不合理之处:A被构造了两次
解决:虚继承
#include <iostream>using namespace std;// 交通工具
class A
{
public:A(int id=0):ID(id){cout << "构造A" << endl;}int ID;
};class B : virtual public A
{
public:// 以下语句中的A(id)是显式地调用A的构造函数// 当直接定义B对象的时候,显然会调用它// 但是如果是通过D触发,那么就不会调用B(int id=0):A(id){cout << "构造B" << endl;}
};class C : virtual public A
{
public:C(int id=0):A(id){cout << "构造C" << endl;}
};class D : public B, public C
{
public:D(int id){cout << "构造D" << endl;}
};int main()
{D d(99);//d.ID = 99;//这句报错,不知道ID是B还是Ccout << d.ID << endl;return 0;
}
虚继承特点
三代之间:创建D的时候,B是实继承,会调用B的构造函数。A是虚继承,B不会调用A的构造函数,但是D去调用A的构造函数
两代:创建B,会调用A的构造函数
9.7.4多态(虚函数)
9.7.4.1 概念

9.7.4.2
#include <iostream>using namespace std;// 抽象基类: 是一个不完整的类
class F
{
public:// 普通的虚函数,他有默认行为virtual void fly(){cout << "默认飞行模式" << endl;}// 纯虚函数,他不提供默认的行为// 这是一个只有接口,没有内容的不完整的函数virtual float area()=0;
};class A : public F
{
public:// 掩盖了父类的fly, 此处的virtual可以省略void fly(){cout << "直升机盘旋" << endl;}// 必须要复写父类的纯虚函数,否则A也成为抽象基类float area(){return 1.2;}
};class B : public F
{
public:// 掩盖了父类的flyvoid fly(){cout << "轰炸机实弹飞行" << endl;}
};// 王牌飞行员
class polit
{
public:// 通过父类的指针或者引用,可以访问子类的虚函数版本// 如果子类没有重写虚函数fly的版本,那么f->fly()就是父类的版本void drivePlane(F *f){f->fly();}
};int main()
{polit Jack;F *x;// 如果是直升机,那么就按照直升机来非x = new A;Jack.drivePlane(x);// 如果是轰炸机,那么就按照轰炸机来飞x = new B;Jack.drivePlane(x);// 以后不管是什么类型的飞机,只要是飞行器的子类他都能开x = new ????;Jack.drivePlane(x);return 0;
}
// 王牌飞行员
class polit
{
public:
// 通过父类的指针或者引用,可以访问子类的虚函数版本
// 如果子类没有重写虚函数fly的版本,那么f->fly()就是父类的版本
void drivePlane(F *f){f->fly();}
};
1.接口fly()不变,但是传入的内存地址发生了改变,所以实现了多态
2.纯虚函数(没有默认行为):必须要复写父类的纯虚函数
示例代码2
#include <iostream>using namespace std;// 抽象基类: 没有通用的面积公式
class Shape
{
public:virtual float area()=0;
};// 圆
class Circle : public Shape
{
private:float radius;public:Circle(int r=0):radius(r){}// 必须复写父类的纯虚函数virtual float area(){return 3.14*radius*radius;}
};// 矩形
class Rectangle : public Shape
{
private:float width;float height;public:Rectangle(float w=0, float h=0):width(w), height(h){}// 必须复写父类的纯虚函数virtual float area(){return width*height;}};// 设计一个函数,可以输出任意形状的面积
void showArea(Shape &r)
{cout << "面积:" << r.area() << endl;
}int main()
{Circle c(2);Rectangle r(2, 3);// 以下该函数具备所谓的多态性// 你给他不同的形状,他就输出对应的数据// 关键点在于: 以后出现的新的形状,他也能支持showArea(c);showArea(r);return 0;
}9.7.5 深浅拷贝、运算符重载
this 指针指向调用该类方法的对象
=赋值操作符函数是默认就有的
示例代码
#include <iostream>
#include <cstring>using namespace std;class A
{int size;// 如果一个类中有指针,那么就意味着有类外资源(内存)存在// 此时需要注意几点:// 1,需要考虑深浅拷贝的问题// 2,必须重写析构函数int *p;public:// 类中默认就有的东西:// 1,无参构造函数A(){}A(int s):size(s){p = new int[size];}~A(){delete [] p;}// 2,拷贝构造函数(即参数为本类对象的构造函数)// 拷贝构造函数会默认将所有的类成员复制一份A(const A &r){size = r.size;// 默认浅拷贝: 只复制指针,没复制真正的内存
// p = r.p;// 深拷贝: 复制真正的内存p = new int[size];memcpy(p, r.p, size*sizeof(int));}// 3,赋值操作符函数// 赋值操作符函数会默认将所有的类成员复制一份// 返回值是实现b=a=c 三个等于号的时候需要返回值//返回值为const就是不支持b+c = aA & operator=(const A &r){// 浅拷贝
// size = r.size;
// p = r.p;// 深拷贝size = r.size;delete [] p;p = new int[r.size];memcpy(p, r.p, size*sizeof(int));return *this;}// 关于this指针// 1,任何类方法,都有一个默认的隐藏指针: this// 2,this指针就指向调用该类方法的对象void f(){size = 100;this->size = 100;}
};int main()
{A a(100);A b(a);A c;c = a;// 定义类对象,会自动调用类构造函数
// A a;
// A b(a);// // 在C++中,任何操作符都是函数
// A c;
// c = a;
// c.operator=(a);return 0;
}思考 b=a=c 的引用返回A &是指针型么? A a 类对象是不是指针
浅拷贝还是会复制内存指针,但是指向的是待复制内存指针,不是新的一块内存
9.7.5 .1 运算符重载
// 重载前置自增运算符函数 ++aMyClock & operator++(){sec++;if(sec == 60){sec = 0;min++;min %= 60;}return *this;}// 重载后置自增运算符 a++ 区别:参数需要为intconst MyClock operator++(int){MyClock tmp = *this;++(*this);return tmp;}
9.7.6 友元
C++语言允许使用友元,但是友元会破坏封装性。
问题 类可以重复定义么?两个.cpp 两个class TV 其他类型呢?
示例代码
tv.h
#ifndef TV_H
#define TV_H#include <iostream>
#include "remoter.h"//class Remoter;using namespace std;class TV
{string channel;int volume;public:TV(string c="CCTV-1", int v=0);// 提供调节频道、音量的公开接口void setChannel(string newChannel);void setVolume(int newVol);// 友元不受权限的限制,因为友元本来就不是类成员// 第1中友元: 友元类// 将遥控器类声明为为本类的友元:// 即遥控器类的任意类方法均拥有访问本类所有数据的权限
// friend class Remoter;// 第2中友元: 友元类方法friend void Remoter::setChannel(TV &tv, string newChannel);friend void Remoter::setVol(TV &tv, int newVol);// 第3种友元: 友元函数friend void mute(TV &tv);// 假装看电视状态接口void state();
};#endif // TV_Htv.cpp
#include "tv.h"
#include "remoter.h"TV::TV(string c, int v):channel(c), volume(v)
{
}void TV::setChannel(string newChannel)
{}void TV::setVolume(int newVol)
{}void TV::state()
{cout << "你正在看" << channel << endl;cout << "当前音量" << volume << endl;
}remoter.h
#ifndef REMOTER_H
#define REMOTER_H#include <iostream>
using namespace std;class TV;class Remoter
{
public:Remoter();void setChannel(TV &tv, string newChannel);void setVol(TV &tv, int newVol);void turnOnLight();void turnOffLight();
};#endif // REMOTER_Hremoter.cpp
#include "remoter.h"
#include "tv.h"Remoter::Remoter()
{}void Remoter::setChannel(TV &tv, string newChannel)
{tv.channel = newChannel;
}void Remoter::setVol(TV &tv, int newVol)
{tv.volume = newVol;
}void Remoter::turnOnLight()
{
}main.cpp
#include <iostream>
#include "tv.h"
#include "remoter.h"using namespace std;void mute(TV &tv)
{tv.volume = 0;
}int main()
{TV xiaomi("CCTV-5", 10);xiaomi.state();Remoter remoter;remoter.setChannel(xiaomi, "CCTV-1");xiaomi.state();mute(xiaomi);xiaomi.state();return 0;
}
9.8 异常
void f1(int a)
{try{f2(a);}catch(invalid_argument &e){cout << "处理异常1: " << e.what() << endl;}cout << "完成任务了" << endl;
}
void f2(int a)
{switch (a){// 不同的异常,是由抛出不同类型的对象来区分的case 1:// 简单的场合,直接使用系统提供的标准异常类throw invalid_argument("参数不可为1");break;case 2:// 复杂的场合,可以从系统标准异常类中派生子类throw err("张三疯", "折扣不合理");break;case 3:throw runtime_error("运行时错误");}cout << "很好,一切很正常,我收到了数据:" << a << endl;
}
9.9 模板函数
过程都大致一样,参数类型不一样就可以用模板函数
#include <iostream>using namespace std;// 如果你发现一堆重载的函数只有接口不同,算法和实现基本一致
// 那么他们很适合做成一个统一的模板//int maxValue(int a, int b)
//{
// return a>b ? a : b;
//}//float maxValue(float a, float b)
//{
// return a>b ? a : b;
//}class Student
{
public:int age;Student(int a):age(a){}
};// 函数模板: 函数生成器
// 函数模板在程序用到的时候才会实际产生一个具体的函数
template <typename T> // <类型参数列表>
T maxValue(T &a, T &b) // (数据参数列表)
{return a>b ? a : b;
}// 函数模板的特化
// 1,将特化了的类型参数,从模板中的类型参数列表剔除,但尖括号<>不能省
// 2,特化的函数模板的接口必须跟通用模板一致
template <> // <类型参数列表>
Student maxValue(Student &a, Student &b) // (数据参数列表)
{if(a.age > b.age)return a;elsereturn b;
}int main()
{int a = 1, b = 2;cout << maxValue(a, b) << endl;float f1 = 1.1;float f2 = 1.2;cout << maxValue(f1, f2) << endl;string s1 = "abc";string s2 = "aBc";cout << maxValue(s1, s2) << endl;Student Jack(21);Student Bill(28);cout << maxValue(Jack, Bill).age << endl;return 0;
}
9.10 类模板
只在.h文件定义
老代码
template <class T1, class T2>
class node
{T1 a;T2 b;
public:node(){cout << "通用版本" << endl;}
};
新标准
#ifndef NODE_H
#define NODE_H#include <istream>
using namespace std;// 模板代码一律写在头文件中,不能写到cpp文件// 类模板
template <typename T1, typename T2>
class node
{T1 a;T2 b;
public:node(){cout << "通用版本" << endl;}
};// 类模板的特化1
template <typename T1>
class node<T1, string> // 特化模板需要增加一个参数列表
{T1 a;string b;
public:node(){cout << "特化1" << endl;}
};// 类模板的特化2
template <typename T2>
class node<string, T2> // 特化模板需要增加一个参数列表
{string a;T2 b;
public:node(){cout << "特化2" << endl;}
};// 类模板的全特化
template <>
class node<double, string> // 特化模板需要增加一个参数列表
{double a;string b;
public:node(){cout << "全特化" << endl;}
};#endif // NODE_H
a.h
#ifndef A_H
#define A_H// 模板代码一律写在头文件中,不能写到cpp文件template <typename T>
class A
{static int count;T *p;public:A();~A();
};// 类的静态成员初始化
template <typename T>
int A<T>::count =0;// 类模板的构造函数
template<typename T>
A<T>::A()
{p = new T[100];
}// 类模板的析构函数
template<typename T>
A<T>::~A()
{delete [] p;
}#endif // A_H调用
#include <iostream>
using namespace std;#include "node.h"
#include "a.h"int main()
{// node是模板node<short, double> a;// 当第二个参数的类型是string,特化1node<int, string> b;// 当第一个参数的类型是string,特化2node<string, short> c;// 当两个参数的类型依次是double,string,全特化node<double, string> d;A<int> x;return 0;
}9.11 容器
std::sort(v.begin(), v.end(), cmp(cmp::SCORE));
cmp类只能operator()(参数)?
静态、动态数组
#include <iostream>
#include <array> // 静态数组
#include <vector> // 动态数组
#include <ctime>using namespace std;template <typename T>
void show(T container)
{// C语言: auto 是一个无用的关键字// C++: auto 代表自动获取数据的类型// 1,使用枚举化for循环遍历容器for(auto element : container)cout << element << '\t';cout << endl;// 2,使用迭代器遍历容器for(auto it=container.begin();it != container.end(); it++)cout << *it << '\t';cout << endl;
}//void show(vector<int> b)
//{
// for(int k : b)
// cout << k << '\t';
// cout << endl;
//}int main()
{array<int, 10> a;// 产生随机数srand(time(NULL));for(int i=0; i<a.size(); i++)a.operator [](i) = rand()%1000;show(a);// // 采用C语言数组下标来访问
// for(int i=0; i<a.size(); i++)
// cout << a[i] << '\t';
// cout << endl;// // 迭代器来访问
// cout << "正序:" << endl;
// for(array<int, 10>::iterator it=a.begin();
// it!=a.end(); it++)
// cout << *it << '\t';
// cout << endl;// cout << "反序:" << endl;
// for(array<int, 10>::reverse_iterator rit=a.rbegin();
// rit!=a.rend(); rit++)
// cout << *rit << '\t';
// cout << endl;// // 使用枚举化for循环来遍历容器元素
// for(int k : a)
// cout << k << '\t';
// cout << endl;// 动态数组vector<int> b;for(int k : a)b.push_back(2*k);show(b);// // 采用迭代器输出b的元素
// for(vector<int>::iterator it = b.begin();
// it != b.end(); it++)
// cout << *it << '\t';
// cout << endl;return 0;
}链表
#include <iostream>
#include <list> // 链表using namespace std;void show(list<int> numbers)
{for(int k : numbers)cout << k << '\t';cout << endl;for(list<int>::iterator it=numbers.begin();it!=numbers.end(); it++)cout << *it << '\t';cout << endl;
}int main()
{// 搞一个链表,并放入若干自然数list<int> numbers;int n;cin >> n;for(int i=1; i<=n; i++)numbers.push_back(i);show(numbers);// 奇偶数重排for(list<int>::reverse_iterator rit = numbers.rbegin();rit != numbers.rend(); rit++){// 偶数if(*rit%2 == 0){int tmp = *rit;numbers.remove(tmp);numbers.push_back(tmp);}// 奇数: 不动}show(numbers);return 0;
}键值对
#include <iostream>
#include <map>using namespace std;int main()
{// 1,key不能重复,是唯一的// 2,默认按key的升序排列map<string/*Key*/, string/*Value*/> contact;// contact[Key] = Valuecontact["Jack"] = "13528022880";contact["Bill"] = "18099990001";contact.insert(pair<string, string>("Rose", "18866659901"));contact.insert(pair<string, string>("Michael", "18866659901"));pair<map<string,string>::iterator, bool> a;a = contact.insert(pair<string, string>("Michael", "15891654883"));if(!a.second)cout << "插入失败" << endl;// 显示通讯录信息for(map<string, string>::iterator it = contact.begin();it != contact.end(); it++){cout << (*it).first << ":" << (*it).second << endl;}for(pair<string,string> person : contact){cout << person.first << ":" << person.second << endl;}return 0;
}10.编译
10.1 attribute((unused)):代表可能不会用到,消除编译警告
例子
void cleanup(int sig __attribute__((unused)))
{// 清除信号量semctl(semidModelReady, 0, IPC_RMID);semctl(semidTakePhoto, 0, IPC_RMID);semctl(semidPhotoReady, 0, IPC_RMID);// 清空所有子进程kill(0, SIGKILL);exit(0);
}
10.2 c/c++混合编程关键字设置
// 如果定义了__cplusplus(在g++编译环境下),那么就按照C++的规则编译如下C语言代码
// 如果没定义__cplusplus(在gcc编译环境下),那么就按照C的规则编译如下C语言代码
// 注: g++编译器内置定义了宏__cplusplus
#ifdef __cplusplus
extern "C" {
#endif//....
#ifdef __cplusplus
}
#endif
11.QT
11.1 关键词
// 写了以下宏定义,才能支持信号与槽
Q_OBJECT
11.2 ui_widget和widget的关系
//widget.h包含
#include <QpushButton>
//widget.cpp定义
Widget::Widget(QWidget *parent) :QWidget(parent),ui(new Ui::Widget)
{ui->setupUi(this);//定义ui_widget//代码实现widget,产生一个子控件pushBtnpushbtn = new QpushButton(this);//this指定为QWidget管控pushBtn->setText("确定");pushBtn->move(20, 30);}
11.3 信号与槽
sig(arg1) slot(arg2)
信号的参数要槽的参数要多
11.4 自定义槽函数
纯代码c++角度理解 1-3Code
private slot:
void onClicked();
初始化操作(添加按键快捷键)
Widget::Widget(QWidget *parent) :QWidget(parent),ui(new Ui::Widget)
{ui->setupUi(this);// 给按钮添加一个快捷键: 回车键 //鼠标Qt::Key_Return,f1f1打开帮助,ctrl+c返回ui->btnCalculate->setShortcut(Qt::Key_Return);// 程序一开始,将光标焦点设置到半径输入栏ui->lineEditRadius->setFocus();//2.// 给账号输入栏填入提示占位符信息ui->lineEditID->setPlaceholderText("请输入电子邮箱");// 禁用按钮ui->pushButton->setEnabled(false);// 密码输入栏不回显ui->lineEditPW->setEchoMode(QLineEdit::Password);ui->lineEditPWConfirm->setEchoMode(QLineEdit::Password);
}
11.5 QT内置类
#include <QDebug>
#include <QVariant>
#include <QRegExp>
#include <iostream>
#include <QTime>
#include <QDate>
#include <QList>
#include <QByteArray>
#include <QFile>
#include <QString>using namespace std;int main(int argc, char *argv[])
{// 1,调试信息qDebug() << "调试信息";// 2,可变类型(通用类型)QVariant v;v = 100;qDebug() << v.toInt();v = "abcd";qDebug() << v.toString();// 3,正则表达式QRegExp re("[a-zA-Z_]+[a-zA-Z0-9_]*"); // C++变量的命名规则string val;while(1){cin >> val;if(val == "0")break;if(re.exactMatch(val.c_str()))qDebug() << "合格";elseqDebug() << "不合格";}// 4,时间与日期qDebug() << QDate::currentDate().toString();qDebug() << QTime::currentTime().toString();// 获取当前日期QDate d = QDate::currentDate();qDebug() << d.day(); // 当前是几号qDebug() << d.month(); // 当前是几月qDebug() << d.year(); // 当前的年份qDebug() << d.dayOfWeek(); // 当前是本周第几天qDebug() << d.daysInMonth(); // 当月总共有几天// 获取当前事件QTime t = QTime::currentTime();qDebug() << qPrintable(QString("时:%1").arg(t.hour()));qDebug() << qPrintable(QString("分:%1").arg(t.minute()));qDebug() << qPrintable(QString("秒:%1").arg(t.second()));// 5,链表(模板)QList<int> list;list << 1;list << 2;list << 3;list.append(4);list.append(5);list.append(6);// C++风格的迭代器遍历容器for(QList<int>::iterator it = list.begin();it != list.end(); it++){qDebug() << *it;}// 枚举风格for循环遍历容器for(int a : list){qDebug() << a;}// Java风格遍历容器QListIterator<int> it(list);while(it.hasNext()){qDebug() << it.next();}// 6,字节数组(纯粹的数组)// 在一般存储字符串的场合中,QString是你的首选,使用QByteArra的理由:// a. 存储二进制数据// b. 内存空间资源紧张,对内存的要求苛刻QByteArray baText;QByteArray baBin;// 存放文本baText.append("100");// 存放二进制int a = 100;baBin.append((const char *)&a, sizeof(a));QFile fileText("a.txt");fileText.open(QIODevice::WriteOnly); // 以只写模式打开文件fileText.write(baText);fileText.close();QFile fileBin("b.bin");fileBin.open(QIODevice::WriteOnly); // 以只写模式打开文件fileBin.write(baBin);fileBin.close();// 7,字符串QString s1("abc");QString s2("www");qDebug() << s1+s2;QString s3 = QString("%1, %2, %3").arg(100).arg(3.14).arg("abc");qDebug() << s3;// c语言 --> C++// c语言 --> QStringchar *s4 = "abc";string s5 = s4;QString s6 = s4;// C++ --> C语言const char *s7 = s5.c_str();// QString --> C++QString s8("www.qqq.com");string s9 = s8.toStdString();// 总结:// 1,C语言是最原始的,也是最具兼容性的,即可以直接使用C语言字符串当做string或QString// 2,将string转换为C语言风格字符串: string::c_str()// 3,将QString转换为C++风格字符串: QString::toStdString()
}11.6 文件对话框
11.6.1 QT中LineEdit、TextEdit 、PlainTextEdit 三个控件的区别
QLineEdit是单行文本输入,一般用于用户名、密码等少量文本交互地方。
QTextEdit用于多行文本,也可以显示HTML格式文本。
QPlainTextEdit与QTextEdit很像,但它多用于需要与文本进行处理的地方,而QTextEdit多用于显示,可以说,QPlainTextEdit对于plain text处理能力比QTextEdit强。
文件对话框shi
widget.h
#ifndef WIDGET_H
#define WIDGET_H#include <QWidget>
#include <QString>namespace Ui {
class Widget;
}class Widget : public QWidget
{Q_OBJECTpublic:explicit Widget(QWidget *parent = 0);~Widget();private slots:void on_pushButton_clicked();private:Ui::Widget *ui;QString dir; // 保存选择文件的文件夹
};#endif // WIDGET_H
widget.cpp
void Widget::on_pushButton_clicked()
{QString filter = "所有(*);;""源码(*.cpp *.h);;""文本(*.txt)";// 1,弹出文件选择对话框QString pathname = QFileDialog::getOpenFileName(this, "选择文件", dir, filter);if(pathname.isNull())return;// 2,保存当前文件夹QFileInfo info(pathname); // 获得文件属性: 大小、类型、所在路径……dir = info.path();// 3,将文件的名称显示到输入栏中ui->lineEdit->setText(pathname);// 4,将文件的内容显示到文本框中QFile file(pathname);file.open(QIODevice::ReadOnly);ui->plainTextEdit->clear();ui->plainTextEdit->appendPlainText(file.readAll());
}
12.工程
12.1 车牌进出管理系统
// 主控程序
int main()
{signal(SIGINT, cleanup);signal(SIGCHLD,cleanup);// 1,为子模块提供统一IPCmkfifo(RFID2SQLiteIn, 0777);mkfifo(RFID2SQLiteOut, 0777);mkfifo(SQLite2audioWelcome, 0777);mkfifo(SQLite2audioPayment, 0777);// 2,准备各个信号量semidTakePhoto = semget(ftok(SEM_KEY_PATH, TAKE_PHOTO), 1, IPC_CREAT|0777);semidPhotoReady = semget(ftok(SEM_KEY_PATH, PHOTO_READY), 1, IPC_CREAT|0777);semidModelReady = semget(ftok(SEM_KEY_PATH, MODEL_READY), 1, IPC_CREAT|0777);semInit(semidTakePhoto);semInit(semidPhotoReady);semInit(semidModelReady);// 3,依次启动各个子模块if(fork() == 0)execl("./SQLite", "SQLite", nullptr);semWait(semidModelReady);cout << "【SQLite模块启动完毕】" << endl << endl;if(fork() == 0)execl("./video", "video", nullptr);semWait(semidModelReady);cout << "【video模块启动完毕】" << endl << endl;
12.2 串口初始化
void Widget::initTTY()
{// 根据下拉框选项初始化串口const char *tty = QString("/dev/%1").arg(ui->ComboBoxCOM->currentText()).toStdString().c_str();fd = open(tty, O_RDWR | O_NOCTTY);if(fd == -1){QMessageBox::critical(this, "错误", strerror(errno));exit(0);}//声明设置串口的结构体struct termios config;bzero(&config, sizeof(config));// 设置无奇偶校验// 设置数据位为8位// 设置为非规范模式(对比与控制终端)config.c_iflag &= ~IXON;//// 2. 输出:禁用自定义输出模式//// 3. 控制:数据字符长度为8位// 禁用校验码config.c_cflag &= ~CSIZE;config.c_cflag |= CS8;config.c_cflag &= ~PARENB;//设置波特率switch(ui->ComboBoxBaud->currentText().toInt()){case 9600 : cfsetspeed(&config, B9600); break;case 115200: cfsetspeed(&config, B115200); break;}// CLOCAL和CREAD分别用于本地连接和接受使能// 首先要通过位掩码的方式激活这两个选项。config.c_cflag |= CLOCAL | CREAD;// 一位停止位config.c_cflag &= ~CSTOPB;// 可设置接收字符和等待时间,无特殊要求可以将其设置为0config.c_cc[VTIME] = 0;config.c_cc[VMIN] = 1;// 用于清空输入/输出缓冲区tcflush (fd, TCIFLUSH);tcflush (fd, TCOFLUSH);//完成配置后,可以使用以下函数激活串口设置tcsetattr(fd, TCSANOW, &config);cout << "串口初始化完毕..." << endl;
}
12.3 接收网络文件
bool recvWAV(const char *fileName)
{// 1,接受文件的大小int size = 0;int n = read(tcpSock, &size, sizeof(int));if(n == -1 || n == 0 || size == 0){return false;}// 2,准备好文件fstream wav;wav.open(fileName, ios_base::out|ios_base::trunc);if(!wav.is_open()){return false;}// 3,接受文件的内容char *buf = new char[1024];while(size > 0){bzero(buf, 1024);n = read(tcpSock, buf, 1024);if(n == -1 || n == 0)break;wav.write(buf, n);size -= n;}wav.close();return true;
}
13.数据结构
单向链表
#include <time.h>
#include <errno.h>
#include <stdio.h>
#include <fcntl.h>
#include <stdlib.h>
#include <unistd.h>
#include <stdint.h>
#include <string.h>
#include <strings.h>
#include <stdbool.h>
#include <pthread.h>
#include <sys/stat.h>
#include <sys/time.h>
#include <sys/mman.h>
#include <sys/ioctl.h>
#include <sys/types.h>// 设计节点
struct node
{int data;struct node * next;
};struct node * init_list()
{return NULL;
}// 创建新节点
// 成功时,返回新节点的地址
// 失败时,返回NULL
struct node * new_node(int data)
{struct node *new = malloc(sizeof(struct node));if(new != NULL){// 初始化这个新节点new->data = data; // 数据域new->next = new; // 指针域}return new;
}// 判断单向循环链表(无头节点)是否为空
// 是就返回true
// 否就返回false
bool empty(struct node * head)
{return head == NULL;
}
struct single_node * ReverseList(struct single_node * pHead)
{struct single_node *p, *pre;pre = pHead->next;p = pre->next;while (p != pHead){pre->next = p->next;p->next = pHead->next;pHead->next = p;p = pre->next;}
}
// 将新节点new,插入到链表的末尾,称为新的尾节点
void add_list_tail(struct node * (*phead), struct node *new)
{// 边界情况if(empty(*phead)){*phead = new;return;}// 定义一个尾指针struct node * tail;// 让tail从头开始往后遍历,直到找到末尾节点为止tail = *phead;while(tail->next != *phead){tail = tail->next;}// 让原链表的末尾节点,指向新的尾节点tail->next = new;// 将新的尾节点,指向首节点new->next = *phead;
}// 输出整条链表的节点
void show(struct node * head)
{if(empty(head)){printf("链表是空的\n");return;}struct node * p = head;do{printf("%d\t", p->data);p = p->next;}while(p != head);printf("\n");
}// 将节点p从单向循环链表中剔除,并释放
// 返回p的下一个节点
struct node * del(struct node *p)
{// 1,找到你要删除的节点的前面的节点struct node * pre;pre = p;while(pre->next != p)pre = pre->next;// 2,让链表跳过要p,不带他玩pre->next = p->next;// 3,释放节点pfree(p);return pre->next;
}// 数3出局
// 将单循环链表中的节点依次数3出局
// 最后剩下最多不超过2个节点
struct node * count3(struct node * head)
{if(empty(head))return head;while(head != head->next->next){head = del(head->next->next);}return head;
}int main(int argc, char **argv)
{// 1,初始化一个空的循环链表struct node * head = init_list();// 2,将一些自然数插入循环链表的尾部printf("请输入你要的节点数量:\n");int n;scanf("%d", &n);for(int i=1; i<=n; i++){// a. 创建一个新节点newstruct node * new = new_node(i);if(new == NULL){perror("节点内存申请失败");exit(0);}// b. 将新节点插入到链表的尾部// 由于必须修改实参head,因此要传递&headadd_list_tail(&head, new);}show(head);// 3,数三出局head = count3(head);// 4,输出幸存者printf("幸存者:");show(head);#ifdef A // 5,销毁链表destroy(head);
#endifreturn 0;
}自己写的
#include <stdio.h>
#include <stdlib.h>struct single_node
{int data;struct single_node *next;
};struct single_node * init_head(void)
{struct single_node *head = calloc(1, sizeof(struct single_node) );if (head == NULL){printf("初始化失败\r\n");return 0;}head->next = head;return head;};int list_add_tail(struct single_node *head, struct single_node *new_node)
{struct single_node *p = head;while(p->next != head){p = p->next;}p->next = new_node;new_node->next = head;return 0;
}int list_show(struct single_node *head)
{struct single_node *p = head;if (p->next == head){printf("链表为空\r\n");return -1;}while (p->next != head){p = p->next;printf("%d ",p->data);}printf("\r\n");return 0;
}
int list_del_node(struct single_node *head, struct single_node *del_node)
{struct single_node *p = head;while (p->next != del_node){p = p->next;}p->next = del_node->next;free(del_node);return 0;
}int list_destroy(struct single_node *head)
{struct single_node *p = head;if (head->next == head){printf("链表为空\r\n");return -1;}while (head->next != head){p = head->next->next;free(head->next);head->next = p;}return 0;
}int list_sort_small2big(struct single_node *head)
{struct single_node *p, *pre, *tail;char exchange_flag = 1;tail = head;while(head->next != tail && exchange_flag){pre = head;p = head->next;exchange_flag = 0;while(p->next != tail){if (p->data > p->next->data){exchange_flag = 1;pre->next = p->next;p->next = pre->next->next;pre->next->next = p;}else{p = p->next;}pre = pre->next;}tail = p;}}void Insert(struct single_node *head)
{int testTime = 1;struct single_node *p,*pre,*q;p = head->next->next; // 先保存下L的第二个元素,因为下一步要将L变成只有一个元素的有序表。head->next->next = head; // 将L变成只有一个元素的有序表// 从L的第二个元素开始遍历整个L直至表尾while(p != head){q = p->next;pre = head; // 先用pre来保存L。while(pre->next !=head && pre->next->data < p->data) // 遍历pre所指向的有序表L,直至找到比p大的节点pre = pre->next;p->next = pre->next;pre->next = p;p = q;}
}
int main()
{int n, i;scanf("%d", &n);struct single_node *head = init_head();for(i = 0; i < n; i++){struct single_node *new_node = calloc(1, sizeof(struct single_node) );scanf("%d", &new_node->data);list_add_tail(head, new_node);}list_show(head);printf("\n");list_sort_small2big(head);//Insert(head);list_show(head);printf("\n");list_destroy(head);list_show(head);return 0;
}单向冒泡
int list_sort_small2big(struct single_node *head)
{struct single_node *p, *pre, *tail;char exchange_flag = 1;tail = head;while(exchange_flag && head->next != tail){pre = head;p = head->next;exchange_flag = 0;while(p->next != tail){if (p->data > p->next->data)//交换完后p也向后移动了{exchange_flag = 1;pre->next = p->next;p->next = pre->next->next;pre->next->next = p;}else{p = p->next;}pre = pre->next;}tail = p;}}双向链表
#include <time.h>
#include <errno.h>
#include <stdio.h>
#include <fcntl.h>
#include <stdlib.h>
#include <unistd.h>
#include <stdint.h>
#include <string.h>
#include <strings.h>
#include <stdbool.h>
#include <pthread.h>
#include <sys/stat.h>
#include <sys/time.h>
#include <sys/mman.h>
#include <sys/ioctl.h>
#include <sys/types.h>// 设计节点
struct node
{int data;struct node *prev;struct node *next;
};struct node * init_list(void)
{// 申请一个头结点堆内存空间struct node * head = malloc(sizeof(struct node));if(head != NULL){// 数据域不管// 指针域指向自身head->prev = head;head->next = head;}return head;
}struct node * new_node(int data)
{// 申请一个新结点堆内存空间struct node * new = malloc(sizeof(struct node));if(new != NULL){// 数据域不管new->data = data;// 指针域指向自身new->prev = new;new->next = new;}return new;
}// 将新节点new,置入链表head的末尾
void list_add_tail(struct node * head, struct node *new)
{new->prev = head->prev;new->next = head;head->prev->next = new;head->prev = new;
}bool empty(struct node * head)
{// 只有头结点,就代表链表为空return head->next == head;
}void show(struct node *head)
{if(empty(head)){printf("链表为空\n");return;}struct node *p;p = head->next;while(p != head){printf("%d\t", p->data);p = p->next;}printf("\n");
}// 功能:
// 将p节点从链表中剔除出去
void list_del(struct node *p)
{// a. 将p的前后两个节点绕过p,不带他玩p->prev->next = p->next;p->next->prev = p->prev;// b. 将p的两条腿置空,从此不跟链表有任何纠葛p->prev = NULL;p->next = NULL;
}// 功能:
// 将p指向的节点,移动到以head为首的链表的末尾
void list_move_tail(struct node * p, struct node * head)
{// a. 将p从链表中剔除list_del(p);// b. 将p插入链表的末尾list_add_tail(head, p);
}void rearrange(struct node *head)
{struct node *p, *k;for(p=head->prev, k=p; p!=head ;p=p->prev){if(p->data % 2 == 0) // 偶数{// 将p指向的节点,移动到链表的末尾list_move_tail(p, head);p = k;}else // 奇数{k = p;}}
}// 销毁链表:
// 1,将链表的有效节点全部删除并释放
// 2,最终链表回归初始化的状态
void destroy(struct node *head)
{struct node *p;for(p=head->next; p!=head; p=head->next){// 1, 剔除节点list_del(p);// 2,释放内存free(p);}
}int main(int argc, char **argv)
{// 1,初始化一条空的双向循环链表(容器)struct node * head = init_list();// 2,将一些自然数放入链表printf("请输入你要的节点个数:\n");int n;scanf("%d", &n);for(int i=1; i<=n; i++){// a. 创建新的节点newstruct node * new = new_node(i);// b. 将新节点new,置入链表的末尾list_add_tail(head, new);}show(head);// 奇偶数重排rearrange(head);show(head);// 销毁链表destroy(head);show(head);return 0;
}自己写的
#include <stdio.h>
#include <time.h>
#include <stdlib.h>struct node
{int data;struct node *prev;struct node *next;
};struct node * init_list_head(void)
{struct node *head = malloc(sizeof(struct node));if (head == NULL){printf("³õʼ»¯Ê§°Ü\r\n");return 0 ;}head->prev = head;head->next = head;return head;};void list_add_tail(struct node *head, struct node *new_node)
{new_node->prev = head->prev;new_node->next = head;head->prev->next = new_node;head->prev = new_node;
};void list_add_small2big(struct node *head, int n)
{struct node *p = head->next;while (p->data < n) p = p->next;struct node *k = calloc(1, sizeof(struct node) );k->prev = p->prev;k->next = p;p->prev->next = k;p->prev = k;k->data = n;};void list_show(struct node *head)
{if (head->next == head){printf("list is null\r\n");return ;}struct node *p = head;for(p = p->next; p != head; p = p->next){printf("%d ",p->data);}printf("\n");}void delete_node(struct node *p)
{p->prev->next = p->next;p->next->prev = p->prev;p->prev = NULL;p->next = NULL;
};void list_destroy(struct node *head)
{struct node *p = head;for(p = head->next; p != head; p = head->next){delete_node(p);free(p);}}void list_small2big_bubble(struct node *List_head)
{char exchange_flag = 1;struct node * head = List_head;struct node * tail = List_head;struct node * p = NULL;struct node * pre = NULL;while(exchange_flag){exchange_flag = 0;//每次向右冒出一个大数p = head->next;while(p->next != tail){pre = p->prev;if (p->data > p->next->data){exchange_flag = 1;p->prev = p->next;p->next->prev = pre;p->next->next->prev = p;pre->next = p->next;p->next = pre->next->next;pre->next->next = p;}else{p = p->next;}}tail = p;//反转回来,每次向左冒出一个小数p = tail->prev;while(exchange_flag && p->prev != head){pre = p->next;if (p->data < p->prev->data){exchange_flag = 1;p->next = p->prev;p->prev->next = pre;p->prev->prev->next = p;pre->prev = p->prev;p->prev = pre->prev->prev;pre->prev->prev = p;}else{p = p->prev;}}head = p;}};int main(void)
{int n, i, a;scanf("%d", &n);struct node *head = init_list_head();for(i = 0; i < n; i++){struct node *new_node = calloc(1, sizeof(struct node) );scanf("%d", &new_node->data);list_add_tail(head, new_node);}list_show(head);list_small2big_bubble(head);//TwoWayBubbleSort(head);list_show(head);list_destroy(head);list_show(head);return 0;
}双向冒泡排序
void TwoWayBubbleSort(struct node * List_head)//对存储在带头结点的双向链表L中的元素进行双向起泡排序。{char exchange = 1;//设标记struct node * head = List_head;//双向链表头,算法过程中是向下起泡的开始结点struct node * tail = List_head;//双向链表尾,算法过程中是向上起泡的开始结点struct node * p = NULL;struct node * temp = NULL;while(exchange){p = head->next;//p是工作指针,指向当前结点exchange = 0;//假定本趟无交换while (p->next != tail)//向下(右)起泡,一趟有一最大元素沉底{if (p->data > p->next->data)//交换两结点指针,涉及6条链{exchange = 1;//有交换temp = p->next;p->next = temp->next;if(temp->next)temp->next->prev = p;//先将结点从链表上摘下//attention!存在temp->next=NULL的可能,NULL->prev无法访问temp->next = p;p->prev->next = temp;//将temp插到p结点前temp->prev = p->prev;p->prev = temp;}else p = p->next;//无交换,指针后移}tail = p;p = tail->prev;while (exchange&&p->prev != head)//向上(左)起泡,一趟有一最小元素冒出{if (p->data < p->prev->data)//交换两结点指针,涉及6条链{exchange = 1;temp = p->prev;p->prev = temp->prev;temp->prev->next = p;temp->prev = p;p->next->prev = temp;temp->next = p->next;p->next = temp;}else p = p->prev;//无交换,指针前移}head = p;//准备向下起泡}}参考改装后
void list_small2big_bubble(struct node *List_head)
{char exchange_flag = 1;struct node * head = List_head;struct node * tail = List_head;struct node * p = NULL;struct node * pre = NULL;while(exchange_flag){exchange_flag = 0;//每次向右冒出一个大数p = head->next;while(p->next != tail){pre = p->prev;if (p->data > p->next->data){exchange_flag = 1;p->prev = p->next;p->next->prev = pre;p->next->next->prev = p;pre->next = p->next;p->next = pre->next->next;pre->next->next = p;}else{p = p->next;}}tail = p;//反转回来,每次向左冒出一个小数p = tail->prev;while(exchange_flag && p->prev != head){pre = p->next;if (p->data < p->prev->data){exchange_flag = 1;p->next = p->prev;p->prev->next = pre;p->prev->prev->next = p;pre->prev = p->prev;p->prev = pre->prev->prev;pre->prev->prev = p;}else{p = p->prev;}}head = p;}};
判断是不是循环链表
int IsCLinkList(List *head) {List *fast, *slow;fast = slow = head;while (fast && fast->next){slow = slow->next;fast = fast->next->next;if (slow == fast){break;}}return ((fast == NULL) || (fast->next == NULL));
}
排序
冒泡排序
void quick_pow(int n,int a[])
{for(int i=0;i<n-1;i++)//n个元素进行n-1次排序{for(int j=0;j<n-i-1;j++)//每趟排序比较的次数{if(a[j]>a[j+1]){int temp=a[j];a[j]=a[j+1];a[j+1]=temp;}}}
}
总体来说,两种排序比较的次数是相同的,但交换的次数,选择排序更少,虽然时间复杂度都是O(n^2),但通常选择排序更快一点,冒泡排序是每次都可能要交换,而选择排序是在比较时记下a[i]的位置 最后来交换 所以效率比冒泡高.
冒泡需要3个赋值,而排序只要一个赋值,我们知道每一个语句执行是有时间的,所以冒泡的总耗时会比插入多
选择排序
void quick_pow(int n,int a[])
{for(int i=0;i<n;i++){int pos=i;for(int j=i+1;j<n;j++){if(a[j]<a[pos])pos=j;}int temp=a[i];a[i]=a[pos];a[pos]=temp;}
}
插入排序
void quick_pow(int n,int a[])
{for(int i=1;i<n;i++)//从第二个元素开始插入,[0,i-1]都是有序数据{int temp=a[i];//要插入的元素int j;for(j=i-1;j>=0&&temp<a[j];j--)a[j+1]=a[j];//往右偏移,给插入的地方空出一个位置a[j+1]=temp;}
}
希尔排序
void quick_pow(int n,int a[])
{for(int k=n/2;k>0;k=k/2)//k是分组距离{for(int i=k;i<n;i++)//可以分成n-k组,轮流对每个分组进行插入排序{int temp=a[i];//int j;for(j=i-k;j>=0&&a[j]>temp;j=j-k)a[j+k]=a[j];//前面的元素大于右边,交换位置,a[j+k]=temp;}}
}
这项研究也表明“比较在希尔排序中是最主要的操作,而不是交换。”用这样步长序列的希尔排序比插入排序和堆排序都要快,甚至在小数组中比快速排序还快,但是在涉及大量数据时希尔排序还是比快速排序慢。
堆排序
堆排序方法对记录数较少的文件并不值得提倡,但对n较大的文件还是很有效的。因为其运行时间主要耗费在建初始堆和调整建新堆时进行的反复“筛选”上。
堆排序在最坏的情况下,其时间复杂度也为O(nlogn)。相对于快速排序来说,这是堆排序的最大优点。此外,堆排序仅需一个记录大小的供交换用的辅助存储空间
递归和迭代对比
由以上分析我们可以看到,递归在处理问题时要反复调用函数,这增大了它的空间和时间开销,所以在使用迭代可以很容易解决的问题中,使用递归虽然可以简化思维过程,但效率上并不合算。效率和开销问题是递归最大的缺点。
虽然有这样的缺点,但是递归的力量仍然是巨大而不可忽视的,因为有些问题使用迭代算法是很难甚至无法解决的(比如汉诺塔问题、快速排序算法)。这时递归的作用就显示出来了。
归并排序
迭代:
缺陷 需要知道数组长度,如果是链表版本的话更麻烦,需要先走一次确认长度,时间复杂度+n
void MergeSort(int n, int a[], int temp[])
{int i, next, le, Mid, MidAdd1, ri;for( i=1; i < n; i*=2 ) //i 为步长, 1, 2, 4, 8...{for( le=0; le < n-i; le = ri+1 )//从0开始,根据步长,向右分组排序{MidAdd1 = le + i;Mid = MidAdd1 - 1;ri = Mid + i;if( ri > n-1){ri = n-1;}next = 0;//将k[]数组中小的数据备份到temp[]数组中,//结束条件是left部分或者right部分有一个已经完全拷贝到temp[]中while( le <= Mid && MidAdd1 <= ri ){if( a[le] <= a[MidAdd1] ){temp[next++] = a[le++];}else{temp[next++] = a[MidAdd1++];}}//现在k[]数组中没有备份的都是大的数据,有两种可能性,//一种是left部分拷贝完成,另一种可能性是right部分拷贝完成,对于后一种情况,//无需考虑,因为right部分本来就排在k[]数组中靠后的位置,//也就是存放大数据的位置,这里只需要考虑第一种情况,将left部分的较大的数据,从k[Mid],开始,//覆盖到k[MidAdd1]的位置(k[MidAdd1]中的数据上一部已经拷贝到temp[]数组中)while( le <= Mid ){a[--MidAdd1] = a[Mid--];}while( next > 0 )//,将temp[]数组中备份的数据重新拷贝回k[]数组中{a[--MidAdd1] = temp[--next];}}}
}
递归:
void merge(int le,int mid,int ri,int a[],int temp[])//将数组a的左右两部分合并
{int MidAdd1=mid+1;int next=0;while(le<=mid&&MidAdd1<=ri)//a数组两端更小的先加进temp数组{if(a[le]<a[MidAdd1])temp[next++]=a[le++];elsetemp[next++]=a[MidAdd1++];}//把a数组剩下的部分加入temp数组while( le <= mid ){a[--MidAdd1] = a[mid--];}while( next > 0 )//,将temp[]数组中备份的数据重新拷贝回k[]数组中{a[--MidAdd1] = temp[--next];}
}void quick_pow(int le,int ri,int a[],int temp[])
{if(le>=ri)return ;int mid=(le+ri)/2;quick_pow(le,mid,a,temp);//使左边有序quick_pow(mid+1,ri,a,temp);//右边有序merge(le,mid,ri,a,temp);//左右有序的部分合并
}
单链表递归版本
struct ListNode* merge(struct ListNode* le, struct ListNode* ri)
{struct ListNode pre;struct ListNode *cur = ⪯while(le != NULL && ri != NULL){if (le->val <= ri->val){cur->next = le;le = le->next;}else{cur->next = ri;ri = ri->next;}cur = cur->next;}if (!le) {cur->next = ri;} else{cur->next = le;}return pre.next;
}struct ListNode* sortList(struct ListNode* head){if (head == NULL || head->next == NULL){return head;}struct ListNode *fast = head, *slow = head, *slowpre = head;while(fast != NULL && fast->next != NULL){fast = fast->next->next;slowpre = slow;slow = slow->next;}slowpre->next = NULL;return merge( sortList(head), sortList(slow) );
}
快速排序
int find(int le,int ri,int a[])//找基准元素位置
{int base=a[le];//基准元素while(le<ri){while(le<ri&&a[ri]>=base)//从序列右端开始处理,大于基准的不变ri--;a[le]=a[ri];//小于基准的交换到左边while(le<ri&&a[le]<=base)//处理左端,小于基准的不变le++;a[ri]=a[le];//大于基准的交换到右边}//当左边的元素都小于base,右边的元素都大于base时,此时base就是基准元素,le或ri就是基准元素的位置a[le]=base;return le;
}
void quick_pow(int le,int ri,int a[])
{if(le>=ri)return;int pos=find(le,ri,a);quick_pow(le,pos-1,a);quick_pow(pos+1,ri,a);
}
队列
连续内存
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>typedef int datatype;typedef struct // 队列管理结构体
{
datatype *queue; // 队列指针unsigned int size; // 队列空间大小int front; // 队头元素偏移量int rear; // 队尾元素偏移量}sequent_queue;bool queue_full(sequent_queue *q) // 判断队列是否已满{return q->front == (q->rear+1) % q->size;}bool queue_empty(sequent_queue *q) // 判断队列是否为空{return q->front == q->rear;}sequent_queue *init_queue(unsigned int size) // 初始化一个空队列{// 申请一块管理结构体内存sequent_queue *q = malloc(sizeof(sequent_queue));if(q != NULL){q->queue = calloc(size, sizeof(datatype)); // 申请队列内存q->size = size;q->front = 0;q->rear = 0;}return q;}bool en_queue(sequent_queue *q, datatype data){if(queue_full(q))return false;q->rear = (q->rear+1) % q->size; // 结果要对 size 求余q->queue[q->rear] = data;return true;}bool de_queue(sequent_queue *q, datatype *pdata){if(queue_empty(q))return false;q->front = (q->front+1) % q->size; // 结果要对 size 求余*pdata = q->queue[q->front];return true;}void show(sequent_queue *q){if(queue_empty(q))return;int tmp = (q->front + 1) % q->size;int flag = 0;while(tmp != q->rear){printf("%s%d", flag==0 ? "" : "-->", q->queue[tmp]);tmp = (tmp+1) % q->size;flag = 1;}printf("%s%d\n", flag==0 ? "" : "-->", q->queue[tmp]);}int main(void){sequent_queue *q;q = init_queue(10);int n, m, ret;while(1){ret = scanf("%d", &n);if(ret == 1){en_queue(q, n);}else if(ret == 0){de_queue(q, &m);while(getchar() != '\n');}show(q);}return 0;}
链表
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>typedef int datatype;struct node // 队列节点
{
datatype data;struct node *next;};typedef struct // 管理结构体{struct node *front;struct node *rear;unsigned int size;}linked_queue;linked_queue *init_queue(void) // 初始化一个空队列{linked_queue *q = malloc(sizeof(linked_queue));if(q != NULL){q->front = q->rear = NULL;q->size = 0;}return q;}struct node *new_node(datatype data) // 创建一个新节点{struct node *new = malloc(sizeof(struct node));if(new != NULL){new->data = data;new->next = NULL;}return new;}bool queue_empty(linked_queue *q) // 判断队列是否为空{return q->size == 0;}bool en_queue(linked_queue *q, struct node *new) // 入队{if(new == NULL)return false;if(queue_empty(q)) // 如果是第一个节点, 要额外处理{q->front = q->rear = new;}else{q->rear->next = new;q->rear = new;}q->size++; // size 记录了当前队列的元素个数, 入队需加 1return true;}bool singular(linked_queue *q) // 判断队列是否刚好只剩一个元素{return (!queue_empty(q)) && (q->front == q->rear);}bool de_queue(linked_queue *q, struct node **p) // 出队{if(queue_empty(q)) // 如果队列为空, 则立即出错返回return false;struct node *tmp = q->front;if(singular(q)) // 如果队列只剩一个节点, 则出队之后队列被置空{q->front = q->rear = NULL;}else{q->front = q->front->next;}if(p != NULL) // p 如果不为 NULL 则使 *p 指向原队头元素{tmp->next = NULL;*p = tmp;}else // p 如果为 NULL 则直接释放原队头元素{free(tmp);}q->size--;return true;}void show(linked_queue *q) // 显示队列元素{if(queue_empty(q))return;struct node *tmp = q->front;while(tmp != NULL){printf("%d\t", tmp->data);tmp = tmp->next;}printf("\n");}int main(void){linked_queue *q;q = init_queue(); // 初始化一个空队列int n, ret;while(1){ret = scanf("%d", &n); // 接收用户输入if(ret == 1) // 如果输入的是整数, 则将该整数入队{struct node *new = new_node(n);en_queue(q, new);show(q);}else if(ret == 0) // 如果输入非整数, 则将队头元素出队{struct node *tmp;de_queue(q, &tmp);show(q);while(getchar() != '\n');}}return 0;}
栈
连续内存
struct sequent_stack // 栈的管理结构体
{
int *stack; // 用 stack 指向一块连续的内存来存储栈元素
int size; // size 保存了该顺序栈的总大小
int top; // 用 top 来指示栈顶元素的偏移量
};struct sequent_stack *init_stack(int size) // 参数 size 表明空栈的初始大小
{
struct sequent_stack *s;
s = malloc(sizeof(struct seqent_stack)); // 申请栈管理结构体
if(s != NULL)
{
s->stack = calloc(size, sizeof(int)); // 申请栈空间, 并由 stack 指向
s->size = size;
s->top = -1; // 将栈顶偏移量置为-1, 代表空栈
}
return s;
}bool stack_full(struct sequent_stack *s)
{
return s->top >= s->size-1; // 判断栈是否已满
}
bool push(struct sequent_stack *s, int data)
{
if(stack_full(s)) // 如果栈已满, 则出错返回
return false;
s->top++;
s->stack[s->top] = data;
return true;
}bool stack_empty(struct sequent_stack *s)
{
return s->top == -1; // 判断栈是否为空
}
bool pop(struct sequent_stack *s, int *p) // p 指向存放栈顶元素的内存
{
if(stack_empty(s)) // 如果栈为空, 则出错返回
return false;
*p = s->stack[s->top];
s->top--;
return true;
}int main(void)
{
struct sequent_stack *s;
s = init_stack(10); // 初始化一个具有 10 个元素空间的顺序栈
int n;
scanf("%d", &n); // 让用户输入一个需要转换的十进制数
while(n > 0)
{
push(s, n%8); // 使用短除法将余数统统压栈
n /= 8;
}
int m;
while(!stack_empty(s)) // 只要栈不为空, 就继续循环
{
pop(s, &m); // 出栈并打印出来
printf("%d", m);
}
printf("\n");
return 0;
}
链式
struct node // 栈节点结构体
{
int data;
struct node *next;
};struct linked_stack // 栈管理结构体
{
struct node *top;
int size;
};struct linked_stack *init_stack(void)
{
struct linked_stack *s;
s = malloc(sizeof(struct linked_stack)); // 申请一个管理结构体
if(s != NULL)
{
s->top = NULL; // j 将栈置空
s->size = 0;
}
return s;
}struct node *new_node(int data) // 创建一个新的节点
{
struct node *new;
new = malloc(sizeof(struct node));
if(new != NULL)
{
new->data = data;
new->next = NULL;
}
return new;
}bool stack_empty(struct linked_stack *s) // 判断栈是否为空{return s->size == 0;}bool push(struct linked_stack *s, struct node *new) // 将新节点 new 压栈
{
if(s == NULL || new == NULL)
return false;
new->next = s->top; // 第①步(见上图)
s->top = new; // 第②步
s->size++;
return true;
}bool pop(struct linked_stack *s, int *p)
{
if(s == NULL || p == NULL || stack_empty(s))
return false;
struct node *tmp = s->top; // 第①步
*p = tmp->data; // 第②步
s->top = s->top->next; // 第③步
free(tmp); // 第④步
s->size--;
return true;
}
二叉树
BST
#include <time.h>
#include <errno.h>
#include <stdio.h>
#include <fcntl.h>
#include <stdlib.h>
#include <unistd.h>
#include <stdint.h>
#include <string.h>
#include <strings.h>
#include <stdbool.h>
#include <pthread.h>
#include <sys/stat.h>
#include <sys/time.h>
#include <sys/mman.h>
#include <sys/ioctl.h>
#include <sys/types.h>#include "drawtree.h"
#include "head4tree.h"// 一般而言,树不需要头结点
linktree init_bst()
{return NULL;
}bool empty(linktree root)
{return root==NULL;
}// 功能:
// 将数据data,插入以root为根的二叉树中
// 将插入了新数据的新的二叉树的根,返回
linktree bst_insert(linktree root, linktree new)
{if(empty(root))return new;if(new->data < root->data)root->lchild = bst_insert(root->lchild, new);else if(new->data > root->data)root->rchild = bst_insert(root->rchild, new);elseprintf("%ld已经存在,不能重复!\n", new->data);return root;
}// 功能:
// 在以root为根的BST中,试图找到data
// 如果找到了,就将它删除
// 如果找不到,就算了
// 返回值: 删除之后的新的二叉树的根
linktree bst_remove(linktree root, int data)
{if(empty(root))return NULL;if(data < root->data)root->lchild = bst_remove(root->lchild, data);else if(data > root->data)root->rchild = bst_remove(root->rchild, data);else{// a.有左子树if(root->lchild != NULL){// 找到左max,替换,删除左maxlinktree leftmax;for(leftmax=root->lchild;leftmax->rchild!=NULL;leftmax=leftmax->rchild);root->data = leftmax->data;root->lchild = bst_remove(root->lchild, leftmax->data);}// b.无左子树,但有右子树else if(root->rchild != NULL){// 找到右min,替换,删除右minlinktree rightmin;for(rightmin=root->rchild;rightmin->lchild!=NULL;rightmin=rightmin->lchild);root->data = rightmin->data;root->rchild = bst_remove(root->rchild, rightmin->data);}// c.没有子树,本身是叶子else{free(root);return NULL;}}return root;
}int main(int argc, char **argv)
{// 1.搞一个空BSTlinktree root = init_bst();// 2.增加一些节点int n;while(1){scanf("%d", &n);if(n == 0)break;// 插入节点if(n > 0){linktree new = new_node(n);root = bst_insert(root, new);}// 删除节点if(n < 0)root = bst_remove(root, -n);// 展示一棵树draw(root);}return 0;
}#include "commonheader.h"
#include "head4tree.h"#define QUEUE_NODE_DATATYPE linktree
#include "head4queue.h"/* the following functions for trees traveling are using
* a giving interface looks like:** void handler(linktree root);** therefor, any application which is intending to apply* these methods SHALL offer this kind of handler.*/void pre_travel(linktree root, void (*handler)(linktree)){if(root == NULL)return;handler(root); // 1: 访问根节点pre_travel(root->lchild, handler); // 2: 递归访问左子树pre_travel(root->rchild, handler); // 3: 递归访问右子树}// 中序遍历, root 是要遍历的树, handler 是遍历时回调的处理函数void mid_travel(linktree root, void (*handler)(linktree)){if(root == NULL)return;mid_travel(root->lchild, handler); // 1: 递归访问左子树handler(root); // 2: 访问根节点mid_travel(root->rchild, handler); // 2: 递归访问右子树}// 后序遍历, root 是要遍历的树, handler 是遍历时回调的处理函数void post_travel(linktree root, void (*handler)(linktree)){if(root == NULL)return;post_travel(root->lchild, handler); // 1: 递归访问左子树post_travel(root->rchild, handler); // 2: 递归访问右子树handler(root); // 3: 访问根节点}void level_travel(linktree root, void (*handler)(linktree)){if(root == NULL)return;linkqueue q;q = init_queue(); // 建立一个队列, 用以进行按层遍历en_queue(q, root); // 首先将根节点入队linktree tmp;while(1){if(!out_queue(q, &tmp)) // 出队失败则表示队列为空, 退出遍历break;handler(tmp); // 访问(处理) 队头元素if(tmp->lchild != NULL)en_queue(q, tmp->lchild);if(tmp->rchild != NULL)en_queue(q, tmp->rchild);}}
AVL
当树保持平衡时, 其搜索时间复杂度
是 O(log2n), 当树退化成链表时, 其搜索时间复杂度变成 O(n), 其他情况下树的平均搜
索时间复杂度就介于这两者之间。
linktree avl_insert(linktree root, linktree new){if(root == NULL) // 新节点 new 插入一棵空树, new 即为根return new;// 1: 按照 BST 原则插入新节点if(new->data < root->data) // 如果新节点比根小, 则插入其左子树中root->lchild = avl_insert(root->lchild, new);else if(new->data > root->data) // 否则插入其右子树中root->rchild = avl_insert(root->rchild, new);else{printf("%d is already exist.\n", new->data);}// 2: 检查插入之后树的平衡性是否遭受了破坏// 2.1: 左子树高度“超标”if(height(root->lchild) - height(root->rchild) == 2){if(new->data < root->lchild->data) // 发生了左-左不平衡root = avl_rotate_right(root);else if(new->data > root->lchild->data) // 发生了左-右不平衡root = avl_rotate_leftright(root);}// 2.2: 右子树高度“超标”else if(height(root->rchild) - height(root->lchild) == 2){if(new->data > root->rchild->data) // 发生了右-右不平衡root = avl_rotateleft(root);else if(new->data < root->rchild->data) // 发生了右-左不平衡root = avl_rotate_rightleft(root);}// 3: 重新计算根节点的高度root->height = MAX(height(root->lchild), height(root->rchild))+1;return root;}
红黑树
与 AVL 不同, 红黑树并不追求“绝对
的平衡” , 在毫无平衡性的 BST 和绝对平衡的 AVL 之间, 红黑树聪明地做了折中, 他的左
右子树的高度差可以大于 1, 但任何一棵子树的高度不会大于另一棵兄弟子树高度的两倍。
在这里插入代码片