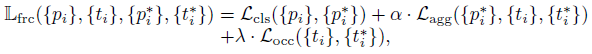今天学习运动物体检测
一:帧差法
捕获摄像头的运动的手
import cv2
import numpy as np# 如果我们想捕获一些运动的物体,每一帧图像中,不动的部分称之为背景,运动的物体称之为前景
# 假如我们的视频捕捉窗口是不动的,比如摄像头放着不动,保证了背景是基本不发生变化的,但是我们怎么捕获前景和背景啊?
# 第一部分: 帧差法
# 通过前后两帧的差值来捕捉运动的物体(一般用时间t的帧减去时间t-1的帧),超过某个阈值,则判断是前景,否则是背景
# 这个方法很简单,但是会带来巨大的噪声(微微震动,零星点)和空洞(运动物体非边缘部分也被判断成了背景)cap = cv2.VideoCapture(0) # 其参数0表示第一个摄像头,一般就是笔记本的内建摄像头。
# cap = cv2.VideoCapture('images/kk 2022-01-23 18-21-21.mp4') # 来自vedio视频的# 获取第一帧
ret, frame = cap.read()
frame_prev = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 将彩色图像转成灰度图kernel1 = np.ones((5, 5), np.uint8) # 为了开运算使用
while (1):# 获取每一帧ret, frame = cap.read()if frame is None:print("camera is over...")breakframe = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 将彩色图像转成灰度图diff = frame - frame_prev # 肯定有一些是负数,全是灰度值的相减diff_abs = cv2.convertScaleAbs(diff) # 取绝对值,保留我们的差异值_, thresh1 = cv2.threshold(diff_abs, 100, 255, cv2.THRESH_BINARY) # 二值化处理MORPH_OPEN_1 = cv2.morphologyEx(thresh1, cv2.MORPH_OPEN, kernel1) # 开运算,去除噪声和毛刺# erosion_it2r_1 = cv2.dilate(MORPH_OPEN_1, kernel1, iterations=2) # 膨胀操作# cv2.imshow("capture", thresh1) # 展示该图像cv2.imshow("capture", MORPH_OPEN_1) # 展示该图像frame_prev = frame # 更新前一帧# 进行等待或者退出判断if cv2.waitKey(1) & 0xFF == 27:break
cap.release()
cv2.destroyAllWindows()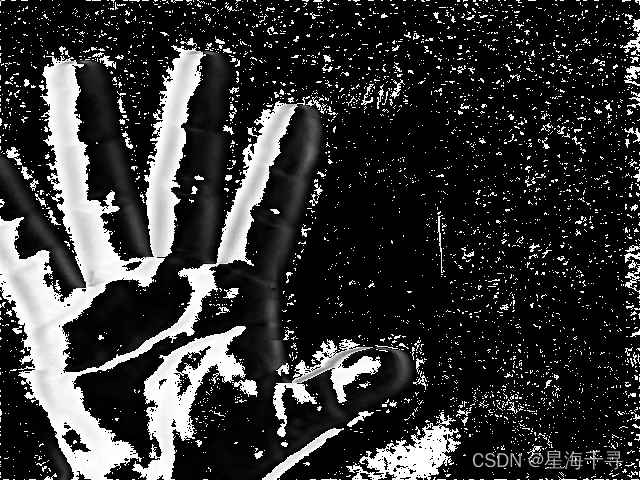

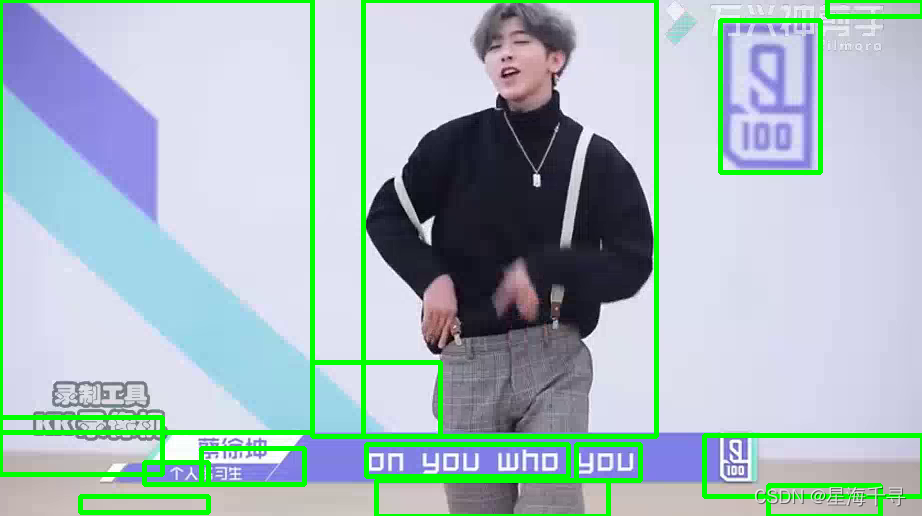
捕捉视频的帧,捕获坤坤的打篮球和跳舞
import cv2
import numpy as np# 如果我们想捕获一些运动的物体,每一帧图像中,不动的部分称之为背景,运动的物体称之为前景
# 假如我们的视频捕捉窗口是不动的,比如摄像头放着不动,保证了背景是基本不发生变化的,但是我们怎么捕获前景和背景啊?
# 第一部分: 帧差法
# 通过前后两帧的差值来捕捉运动的物体(一般用时间t的帧减去时间t-1的帧),超过某个阈值,则判断是前景,否则是背景
# 这个方法很简单,但是会带来巨大的噪声(微微震动,零星点)和空洞(运动物体非边缘部分也被判断成了背景)cap = cv2.VideoCapture('images/kk 2022-01-23 18-21-21.mp4') # 来自vedio视频的# 获取第一帧
ret, frame = cap.read()
frame_prev = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 将彩色图像转成灰度图# kernel1 = np.ones((5, 5), np.uint8) # 为了开运算使用
while (1):# 获取每一帧ret, frame = cap.read()if frame is None:print("camera is over...")breakframe = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 将彩色图像转成灰度图diff = frame - frame_prev # 肯定有一些是负数,全是灰度值的相减diff_abs = cv2.convertScaleAbs(diff) # 取绝对值,保留我们的差异值_, thresh1 = cv2.threshold(diff_abs, 100, 255, cv2.THRESH_BINARY) # 二值化处理# MORPH_OPEN_1 = cv2.morphologyEx(thresh1, cv2.MORPH_OPEN, kernel1) # 开运算,去除噪声和毛刺# erosion_it2r_1 = cv2.dilate(MORPH_OPEN_1, kernel1, iterations=2) # 膨胀操作cv2.imshow("capture", diff_abs) # 展示该图像# cv2.imshow("capture", thresh1) # 展示该图像# cv2.imshow("capture", MORPH_OPEN_1) # 展示该图像frame_prev = frame # 更新前一帧# 进行等待或者退出判断if cv2.waitKey(24) & 0xFF == 27:break
cap.release()
cv2.destroyAllWindows()
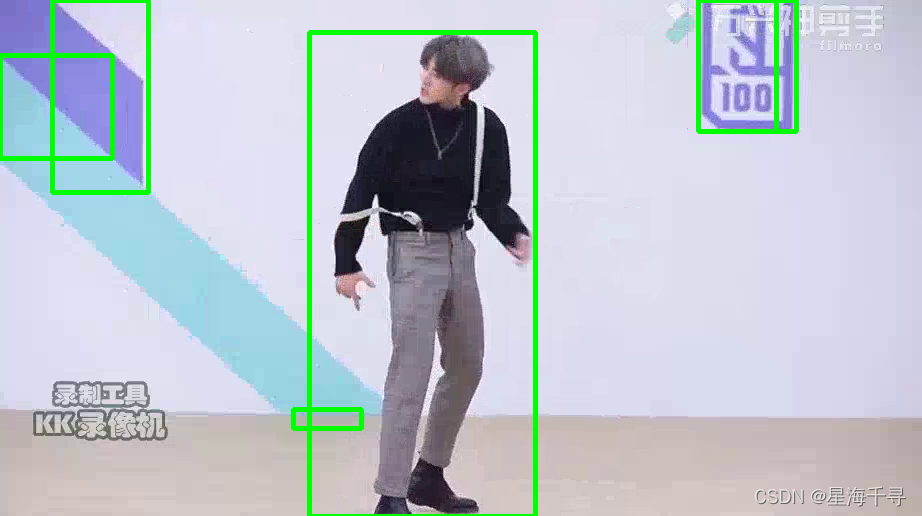
效果如下:


总体而言,帧差法的效果真的是不忍直视。
二:高斯混合模型(GMM)
在进行前景检测前,先进行背景的学习和训练,对图像的每一个背景采用一个GMM进行模拟,每个背景的混合高斯模型是可以训练的,是自适应的。在测试阶段,对新来的像素进行GMM检测,如果像素值匹配某个高斯模型(进行概率值计算,看看和哪个高斯模型接近,或者看看和均值的偏离程度),则认为是背景,否则认为是前景(剧烈变化的像素,属于异常而原理GMM模型)。由于整个过程中GMM模型在不断的更新学习,多以对动态背景有一定的鲁棒性。
我们的视频中的每一帧的像素点不可能是一成不变的(理想很丰满),总会有空气密度导致的变化,吹一吹风,或者摄像头的微微抖动。但是正常情况下,我们都认为背景中的像素点都是满足一个高斯分布,在一定的概率下抖动是正常的。
我们的背景实际上也应当是多个高斯分布的混合分布,且每个高斯模型也是可以带权重的。因为背景有蓝天,建筑,树木花草,马路等。这些都是一些分布。
至于GMM和EM算法的内容和关系,我们在之前学习过,这里就不再讲述了。EM算法是求解GMM的一个方法。
运用在图像中的话,是怎么做的呢?步骤如下:
1:首先初始化每个高斯模型矩阵参数,初始的方差都是假设的(比如设置为5)。
2:先给T帧图像进行训练GMM,来了第一个像素后把他当成第一个高斯分布,比如作为均值。
3:后面再来一个像素,和当前的高斯分布作对比,如果该像素值和与当前的高斯模型的均值的差值在3倍的方差以内,就认为是属于该高斯分布,并对高斯分布参数进行更新。
4:如果该像素不满足该高斯分布。则用这个新的像素建立一个新的高斯分布(用它做均值,假设一个方差(比如设置为5))。但是一个像素位置不要太多个高斯分布,太多了会造成计算量巨大。3~5个基本够了。
GMM测试步骤:
对于新来的像素值,和GMM的的多个高斯分布的均值分别作比较,其差值在2倍的方差之内,则认为是背景,否则是前景。前景像素点设置为255,背景像素点设置为0,行成了一个二值图像。
import cv2
import numpy as npcap = cv2.VideoCapture('images/kk 2022-01-23 18-21-21.mp4') # 来自vedio视频的kernel1 = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (5, 5))
mog = cv2.createBackgroundSubtractorMOG2() # 创建混合高斯模型来用于北京建模while (1):# 获取每一帧ret, frame = cap.read()if frame is None:print("camera is over...")breakfmask = mog.apply(frame) # 判断哪些是前景和背景MORPH_OPEN_1 = cv2.morphologyEx(fmask, cv2.MORPH_OPEN, kernel1) # 开运算,去除噪声和毛刺contours, _ = cv2.findContours(fmask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 只检测外边框for cont in contours:# 计算各个轮廓的面积len = cv2.arcLength(cont, True)if len > 300: # 去除一些小的噪声点# 找到一个轮廓x,y,w,h = cv2.boundingRect(cont)# 画出这个矩形cv2.rectangle(frame, (x,y), (x+w, y+h), color=(0,255,0), thickness=3)# 画出所有的轮廓cv2.imshow('frame', frame)cv2.imshow('fmask', fmask)# 进行等待或者退出判断if cv2.waitKey(24) & 0xFF == 27:breakcap.release()
cv2.destroyAllWindows()
效果如下:


三:KNN
也是根据每个像素点的历史信息进行统计额比较,来判断新来的像素值是不是背景。具体的原理后面补充。
import cv2
import numpy as npcap = cv2.VideoCapture('images/kk 2022-01-23 18-21-21.mp4') # 来自vedio视频的kernel1 = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (5, 5))
knn = cv2.createBackgroundSubtractorKNN() # 创建KNN模型while (1):# 获取每一帧ret, frame = cap.read()if frame is None:print("camera is over...")breakfmask = knn.apply(frame) # 判断哪些是前景和背景MORPH_OPEN_1 = cv2.morphologyEx(fmask, cv2.MORPH_OPEN, kernel1) # 开运算,去除噪声和毛刺contours, _ = cv2.findContours(fmask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 只检测外边框for cont in contours:# 计算各个轮廓的面积len = cv2.arcLength(cont, True)if len > 200: # 去除一些小的噪声点# 找到一个轮廓x,y,w,h = cv2.boundingRect(cont)# 画出这个矩形cv2.rectangle(frame, (x,y), (x+w, y+h), color=(0,255,0), thickness=3)# 画出所有的轮廓cv2.imshow('frame', frame)cv2.imshow('fmask', fmask)# 进行等待或者退出判断if cv2.waitKey(24) & 0xFF == 27:breakcap.release()
cv2.destroyAllWindows()
效果如下: