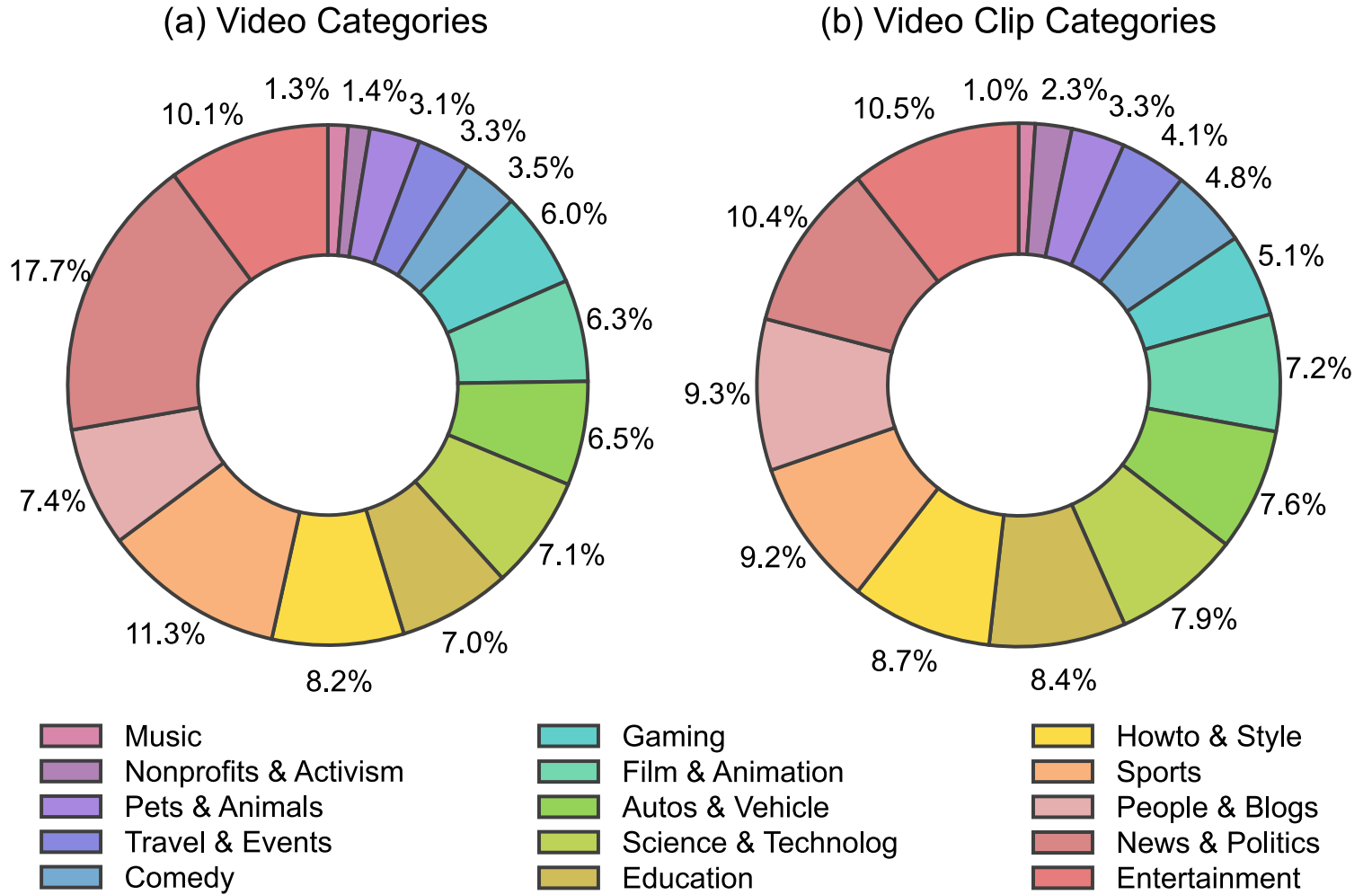
Few-shot Object Detection via Feature Reweighting(MetaYOLO)
出发点:不同属性以不同的权重组合,可以定义一个类别,所以检测特征是否属于某一类,只要检测特征对属性的响应度就可以。特征 —> 属性 —> 类别
网络的整体框架:

- 通过Feature Extractor提取待检测图片特征,每个通道表示一个属性。
- 通过Reweighting Module提取查询类别的特征过滤器,如图中,每个值过滤一个属性。
- 使用每个类别的特征过滤器过滤待检测图片特征,得到待检测图片与每个类别的响应特征,每个通道表示一个属性。
- 对每个响应特征进行分类检测
- 完成检测
Few-Shot Object Detection with Attention-RPN and Multi-Relation Detector
关键:提出了一个小样本数据集:数据集

步骤:
- 提取support img为一过滤特征
- 使用support img的特征来过滤query img,最后将过滤后的特征输入RPN网络中
- RPN网络层的输出,会进行多头判断,使用全局信息检测,使用局部信息检测,一对多检测
Attention-Based Region Proposal Network

Incremental Few-Shot Object Detection
目标:解决增量学习的小样本物体检测
关键点:参数预测的元学习;增量学习;CentreNet;
CentreNet是一个one-stage;anchor-free的物体检测器,并且每个类别对应一个检测类别,即每个类别对应一组分类参数,这种操作易于做小目标的增量学习。

步骤:
- 在第一阶段使用大量的base类训练网络的特征提取以及base类的分类器
- 在第二阶段,冻结特征提取模块的参数,基于base类构建大量task,以base类的分类参数作为label,使用元学习的方式训练分类参数生成器,在完成训练后class code generator模块能够根据少量的样本生成类别的分类参数。
- 完成训练
Multi-Scale Positive Sample Refinement for Few-Shot Object Detection参考
目标:解决小样本检测中的尺度分布不均衡问题;现有的特征金字塔与图像金字塔都不能很好的解决;
解决方案:通过在Faster-RCNN网络中融合改进的FPN网络,使模型整体能够捕捉不同触尺度的信息。换句话说,就是将图像金字塔与特征金字塔融合在小样本物体检测中

步骤:
- 通过在Faster R-CNN网络中加入FPN网络,使模型能够捕捉不同级别的特征。
- 使用Refinement Branch配合图像金字塔调整FPN网络,使模型能够捕捉不同图像尺度的特征。Refinement Branch的输入是同一物体不同尺度的图像,并且不同尺度与FPN不同级别的特征进行了强制捆绑。

对于3232的图像输入,使用FPN中的P2对原始RPN进行调整,使用P2对原始ROI进行调整* - 最后,在完成训练后,FPN已经具备捕捉不同尺度目标的能力,Refinement Branch会被移除。(Refinement Branch与Faster R-CNN中的FPN是共享参数的)
Meta-RCNN: Meta Learning for Few-Shot Object Detection
关键词:元学习;小样本;Faster RCNN

-
构建Task,K-way,N-shot
-
使用Faster RCNN对Task中support-set中的图片提取候选框,理想情况下,每个候选框应该对应一个物体。
-
对每个support-set中的所有候选框,根据其对应的类别归类取平均,由此得到每个类别对应的的原型。参考Prototypical Networks。

-
使用同样的Faster RCNN提取query-img的特征,并用第三步得到的原型对其进行过滤,留下相关的特征,过滤掉无关的特征,最终会得到K个Class-specific Feature Map。

-
将Class-specific Feature Map送入RPN网络,产生query-img对每个类别的候选框,在原始query-img特征上进行裁剪后,使用原型特征再度增强。
-
使用最后增强后的特征计算分类损失与回归损失。
Meta-Learning to Detect Rare Objects
关键点:基于参数预测的元学习;category-agnostic与category-speific参数
中心思想:将物体检测的参数分为category-agnostic与category-speific,前者在base类和novel类中通用,后者需要通过元学习来生成。

模型整体训练过程没整明白,总体来说就是,首先基于大量数据训练得到category-agnostic与category-speific两种参数,然后对category-agnostic在测试新类时可以直接使用。而新类的category-speific参数是通过元学习训练一个T模块得到。但是细节方面,着实搞不明白这篇论文。比较比较有意思的就是参数预测模块,使用这种方式的元学习相对来说在目标检测领域还是少的,可以借鉴。