1. 物体检测技术概念
物体检测技术,通常是指在一张图像中检测出物体出现的位置及对 应的类别,主要包括物体类别、 x m i n x_{min} xmin、 y m i n y_{min} ymin、 x m a x x_{max} xmax与 y m a x y_{max} ymax。它是一项非常基础的任 务,图像分割、物体追踪、关键点检测等通常都要依赖于物体检测。
2. 图像分类、物体检测与图像分割的区别
- 图像分类:输入图像往往仅包含一个物体,目的是判断每张图像 是什么物体,是图像级别的任务,相对简单,发展也最快。
- 物体检测:输入图像中往往有很多物体,目的是判断出物体出现 的位置与类别,是计算机视觉中非常核心的一个任务。 ·
- 图像分割:输入与物体检测类似,但是要判断出每一个像素属于 哪一个类别,属于像素级的分类。图像分割与物体检测任务之间有很多 联系,模型也可以相互借鉴
3. 传统的物体检测
传统的物体检测,不涉及深度学习之前,通常分 为区域选取、特征提取与特征分类这3个阶段
- 区域选取:首先选取图像中可能出现物体的位置,由于物体位 置、大小都不固定,因此传统算法通常使用滑动窗口(Sliding Windows)算法,但这种算法会存在大量的冗余框,并且计算复杂度 高
- 特征提取:在得到物体位置后,通常使用人工精心设计的提取器 进行特征提取,如SIFT和HOG等。由于提取器包含的参数较少,并且 人工设计的鲁棒性较低,因此特征提取的质量并不高。
- ·特征分类:最后,对上一步得到的特征进行分类,通常使用如 SVM、AdaBoost的分类器。
4. 深度学习时代的物体检测
深度神经网络大 量的参数可以提取出鲁棒性和语义性更好的特征,并且分类器性能也更 优越。
2014年的RCNN(Regions with CNN features)算是使用深度学习 实现物体检测的经典之作,从此拉开了深度学习做物体检测的序幕。
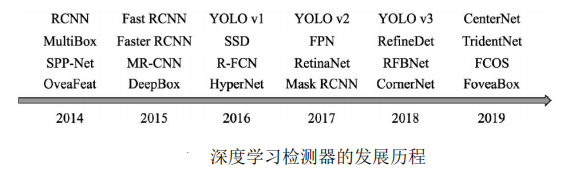
- 在RCNN基础上,2015年的Fast RCNN实现了端到端的检测与卷积 共享,Faster RCNN提出了锚框(Anchor)这一划时代的思想,将物体 检测推向了第一个高峰。在2016年,YOLO v1实现了无锚框(Anchor- Free)的一阶检测,SSD实现了多特征图的一阶检测,这两种算法对随 后的物体检测也产生了深远的影响
- 在2017年,FPN利用特征金字塔实现了更优秀的特征提取网络, Mask RCNN则在实现了实例分割的同时,也提升了物体检测的性能。 进入2018年后,物体检测的算法更为多样,如使用角点做检测的 CornerNet、使用多个感受野分支的TridentNet、使用中心点做检测的 CenterNet等。
- 在物体检测算法中,物体边框从无到有,边框变化的过程在一定程 度上体现了检测是一阶的还是两阶的。
- 两阶:两阶的算法通常在第一阶段专注于找出物体出现的位置, 得到建议框,保证足够的准召率,然后在第二个阶段专注于对建议框进 行分类,寻找更精确的位置,典型算法如Faster RCNN。两阶的算法通 常精度准更高,但速度较慢。当然,还存在例如Cascade RCNN这样更 多阶的算法。
- 一阶:一阶的算法将二阶算法的两个阶段合二为一,在一个阶段里完成寻找物体出现位置与类别的预测,方法通常更为简单,依赖于特 征融合、Focal Loss等优秀的网络经验,速度一般比两阶网络更快,但 精度会有所损失,典型算法如SSD、YOLO系列等
锚框(Anchor)这一划时代的思想,,最早出现在Faster RCNN中,其本质 上是一系列大小宽高不等的先验框,均匀地分布在特征图上,利用特征 去预测这些Anchors的类别,以及与真实物体边框存在的偏移。Anchor 相当于给物体检测提供了一个梯子,使得检测器不至于直接从无到有地 预测物体,精度往往较高,常见算法有Faster RCNN和SSD等。
当然,还有一部分无锚框的算法,思路更为多样,有直接通过特征 预测边框位置的方法,如YOLO v1等。最近也出现了众多依靠关键点来 检测物体的算法,如CornerNet和CenterNet等。
5. 技术应用领域
- 安防(行人与车辆的检测。将检测技术融入到摄像头中, 形成智能摄像头)
- 自动驾驶(行人、车辆等障碍物的检测)
- 机器人(工业机器人自动分拣,识别要分拣的物体或部件;移动智能机器人用于检测各种障碍物,以实现安全的避障与导航)
- 搜索推荐(对于包含特定物体的图像过滤、筛选、推荐和水印处理)
- 医疗诊断(对CT、MR等医疗图 像中特定的关节和病症进行诊断)
6. 评价指标
(1)评价指标需要针对不同的运用给出不同的指标
- 图像分类
对于图像分类任务来讲,由于其输出是很简单的图像 类别,因此很容易通过判断分类正确的图像数量来进行衡量。 - 物体检测
对于具 体的某个物体来讲,我们可以从预测框与真实框的贴合程度来判断检测 的质量,通常使用IoU(Intersection of Union)来量化贴合程度。
(2) 物体检测指标:IoU
① IoU的计算方式如图:
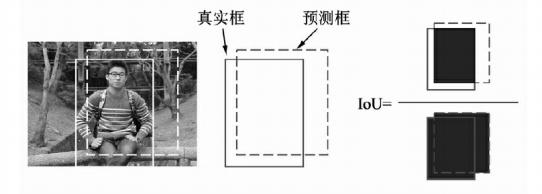
它通过使用两个边框的交集与并集的比 值,就可以得到IoU,公式如下:
I o U A , B = S A ∩ S B S A ∪ S B IoU_{A,B}=\frac{S_A \cap S_B}{S_A \cup S_B} IoUA,B=SA∪SBSA∩SB显而易见,IoU的取值区间是[0,1],IoU值越大,表明两个框重合越好
② Python实现IoU的计算

备注:个人觉得,这参考代码是以左上角为原点。
源码:
# -*- coding: utf-8 -*-
def iou(boxA, boxB):# 计算重合部分的上、下、左、右4个边的值,注意最大最小函数的使用left_max = max(boxA[0], boxB[0])top_max = max(boxA[1], boxB[1])right_min = min(boxA[2], boxB[2])bottom_min = min(boxA[3], boxB[3])# 计算重合部分的面积inter = max(0, (right_min-left_max)) * max(0, (bottom_min-top_max))Sa = (boxA[2]-boxA[0]) * (boxA[3]-boxA[1]) # A的面积Sb = (boxB[2]-boxB[0]) * (boxB[3]-boxB[1]) # B的面积# 计算所有区域的面积并计算iou,如果是Python 2,则要增加浮点化操作union = Sa + Sb - inter # 不重叠部分的面积iou = inter / unionreturn iou
对于IoU而言,通常会选取一个阈值,如0.5,来确定预测框是 正确的还是错误的。当两个框的IoU大于0.5时,我们认为是一个有效的 检测,否则属于无效的匹配。
关于检测评测,可以先读这篇文字:分类效果评价
结合分类效果评级,我们可以得到如下图左侧的部分知识
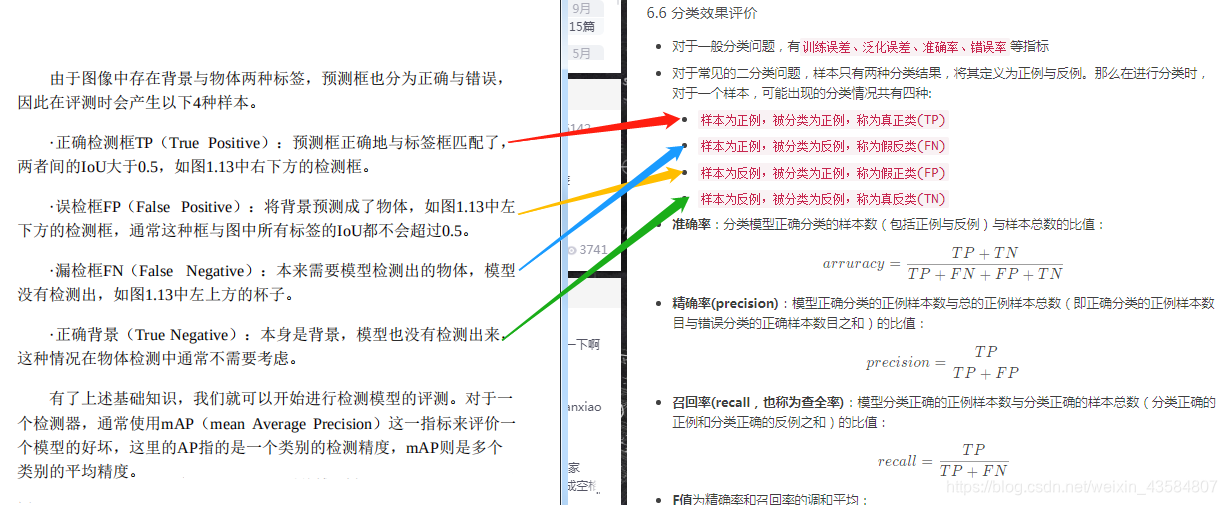
评测需要每张图片的预测值与标签值,对于某一个实 例,二者包含的内容分别如下: ·
- 预测值(Dets):物体类别、边框位置的4个预测值、该物体的得分。
- 标签值(GTs):物体类别、边框位置的4个真值。
在预测值与标签值的基础上,AP的具体计算过程如下:
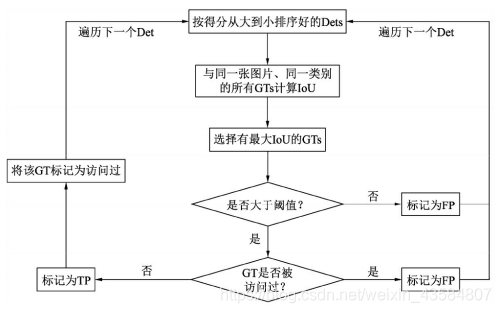
我们首先将所有的预测框按照得分从高到低进行排序(因为得分越高的边框其对于真实物体的概率往往越大),然后从高到低遍历预测框
对于遍历中的某一个预测框,计算其与该图中同一类别的所有标签框GTs的IoU,并选取拥有最大IoU的GT作为当前预测框的匹配对象。如果该IoU小于阈值,则将当前的预测框标记为误检框FP。
如果该IoU大于阈值,还要看对应的标签框GT是否被访问过。如果 前面已经有得分更高的预测框与该标签框对应了,即使现在的IoU大于 阈值,也会被标记为FP。如果没有被访问过,则将当前预测框Det标记 为正确检测框TP,并将该GT标记为访问过,以防止后面还有预测框与 其对应
在遍历完所有的预测框后,我们会得到每一个预测框的属性,即TP 或FP。在遍历的过程中,我们可以通过当前TP的数量来计算模型的召 回率(Recall,R),即当前一共检测出的标签框与所有标签框的比值,
R = T P l e n ( G T s ) R=\frac{TP}{len(GTs)} R=len(GTs)TP也可以计算准确率(Precision,P),即当 前遍历过的预测框中,属于正确预测边框的比值 P = T P T P + F P P=\frac{TP}{TP+FP} P=TP+FPTP
遍历到每一个预测框时,都可以生成一个对应的P与R,这两个值 可以组成一个点(R,P),将所有的点绘制成曲线,即形成了P-R曲线,如图:
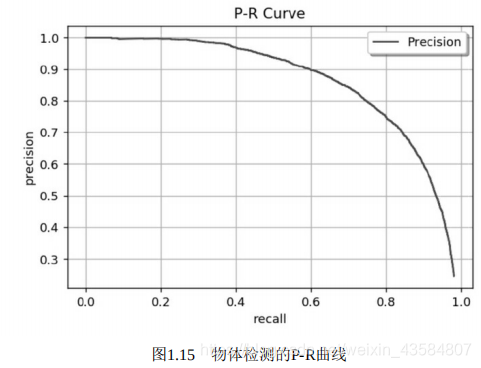
从图中可以看出,如果直接取曲线 上的点,在哪里选取都不合适,因为召回率高的时候准确率会很低,准 确率高的时候往往召回率很低。这似乎与我们想要的P越高的同时R也越大互相矛盾,但是我们可以使用AP,AP顾名思义就是平均精准度,简单来说就是对PR曲线上的Precision值求均值
A P = ∫ 0 1 P d R AP=\int^1_0 PdR AP=∫01PdR从公式中可以看出,AP代表了曲线的面积,每个类别的AP是相互独立 的,将每个类别的AP进行平均,即可得到mAP。严格意义上讲,还需 要对曲线进行一定的修正,再进行AP计算。除了求面积的方式,还可 以使用11个不同召回率对应的准确率求平均的方式求AP。