在说HashSet集合之前先讲一讲Set集合
Set 接口也是 Collection 的子接口,与 List 接口最大的不同在于,Set 接口里面的内容是不允许重复的。
Set 接口并没有扩充任何的 Collection 接口中的内容,所以使用的方法全部都是 Collection 接口定义而来的。因为此接口没有 List 接口中定义 的 get(int index)方法,所以无法使用循环进行输出,关于集合的遍历点击
那么在此接口中有两个常用的子类:HashSet、TreeSet

HashSet
HashSet 属于散列的存放类集,里面的内容是无序存放的。
java.util.HashSet 是 Set 接口的一个实现类,它所存储的元素是不可重复的,并且元素都是无序的(即存取顺序不一致)。
java.util.HashSet 底层的实现其实是一个 java.util.HashMap 支持。
HashSet 是根据对象的哈希值来确定元素在集合中的存储位置,因此具有良好的存取和查找性能。
保证元素唯一性的方式依赖于: hashCode 与 equals 方法。
我们先来使用一下Set集合存储,看下现象,再进行原理的讲解:
import java.util.HashSet;
import java.util.Iterator;
public class HashSetDemo {/** 如果要想判断两个对象是否相等,则必须使用 Object 类中的 equals()方法。* 从最正规的来讲,如果要想判断两个对象是否相等,则有两种方法可以完成: ·* 第一种判断两个对象的编码是否一致,这个方法需要通过 hashCode()完成,即:每个对象有唯一的编码* 还需要进一步验证对象中的每个属性是否相等,需要通过 equals()完成。* 所以此时需要覆写 Object类中的 hashCode()方法,此方法表示一个唯一的编码,一般是通过公式计算出来的。*/public static void main(String[] args) {HashSet<String> set = new HashSet<>();// add方法是map.putset.add(new String("123"));boolean flag1 = set.add("锄禾日当午");set.add("汗滴禾下土");set.add("谁知盘中餐");set.add("粒粒皆辛苦");boolean flag2 = set.add("锄禾日当午");// add返回一个布尔值,因为set集合不允许重复元素,返回true表示成功,false表示存储失败System.out.println(flag1);System.out.println(flag2);// 对集合遍历三种方法:forEach、toArray、Iterator迭代Iterator<String> iterator = set.iterator();while(iterator.hasNext()){System.out.println(iterator.next());}for(String s:set){System.out.print(s+"、");}}
}
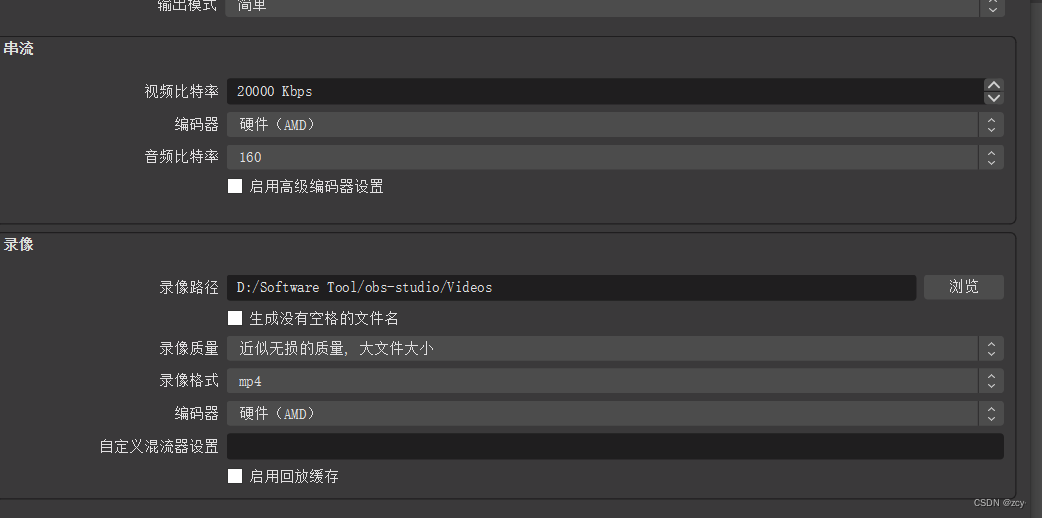
HashSet集合存储数据的结构(哈希表)
什么是哈希表呢?

在JDK1.8之前,哈希表底层采用数组+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率
较低。而JDK1.8中,哈希表存储采用数组+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
简单的来说,哈希表是由数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,如下图所示。

看到这张图就有人要问了,这个是怎么存储的呢?
为了方便大家的理解给出存储流程图:

总而言之,JDK1.8引入红黑树大程度优化了HashMap的性能,那么对于我们来讲保证HashSet集合元素的唯一,其实就是根据对象的hashCode和equals方法来决定的。
如果我们往集合中存放自定义的对象,那么保证其唯一,就必须复写hashCode和equals方法建立属于当前对象的比较方式。
LinkedHashSet
我们知道HashSet保证元素唯一,可是元素存放进去是没有顺序的,那么我们要保证有序,怎么办呢?
在HashSet下面有一个子类 java.util.LinkedHashSet ,它是链表和哈希表组合的一个数据存储结构。

可以看到输入和输出时的元素顺序是一样的