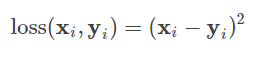在我们自学神经网络神经网络的损失函数的时候会发现有一个思路就是交叉熵损失函数,交叉熵的概念源于信息论,一般用来求目标与预测值之间的差距。比如说我们在人脑中有一个模型,在神经网络中还有一个模型,我们需要找到神经网络模型跟人脑模型最相近的那一个,那就需要找到一个方法需要定量的去看待两个模型的差异。
文章目录
- 1 交叉熵
- 1.1熵
- 1.1.1信息量
- 1.2相对熵,kl散度
- 2 交叉熵函数的应用分析
- 2.1 交叉熵函数单分类问题应用
- 2.2交叉熵在多分类问题中的使用
- 2.3学习过程与优缺点
- 2.3.1二分类情况
- 2.3.2优缺点
- 2.3.1.2优点
- 2.3.1.3缺点
- 总结
1 交叉熵
交叉熵其实就是运用了熵的概念先把模型转化为熵的数值然后用数值去比较模型之间的差异。
那为什么要用熵?熵是指一个模型体系的混乱程度。如果两个模型是同一类的比如说都是高斯分布,这样可以直接进行比较。那如果一个是高斯分布一个是泊松分布那就无法直接进行比较。同时人脑模型跟神经网络模型一样也有混乱度,要理解交叉熵,需要先了解下面几个概念。
1.1熵
熵在物理学跟信息论当中都有定义当然我们看的是深度学习 我们还是运用信息论中的概念。我们先引入信息量
1.1.1信息量
举个例子比如说让你再做一遍你小学二年级都会的十以内的加减法,你就会说都会了写了没用,这种情况就是信息量很低。还有一种情况比如说马云今天吃了个苹果是山东烟台产的红富士,这个消息你不知道但是知道了好像对于你并没有多大的帮助这种情况也算是信息量很低。所以看一个信息信息量到底大不大不是看你知道不知道还要看给你带来多少确定性。比如说羽毛球男单比赛

现在有八支球队进行比赛,现在中国人夺冠概率是八分之一。过两天比赛结果出来发现中国人夺冠了。那么概率之前为八分之一不确定的事情到现在百分之一百确定了 那这个事情信息量很高。如果说中国队进了决赛,那这件事概率由八分之一到二分之一 ,这件事也有信息量但没有夺冠的信息量高。因为这件事只是从八分之一到二分之一不是到百分之百,所以不同的信息含有的信息量是不一样的。那么怎么去求信息量呢我们定义一下:
f(x): = (信息量)
f(中国队赢得比赛)=f(中国队进决赛)+f(中国队赢得比赛)
中国队赢得比赛信息量等于中国队进决赛的信息量加上中国队赢得比赛得信息量相加。

我们可以得出f(1/8)=f(1/4)+f(1/2)
那么我们应该怎么写才能自洽 这里我们可以知道1/8,1/4,1/2,都是概率。
p(中国队夺冠)=p(中国队进决赛)p(中国队赢得决赛)
所以这几个式子完全满足才能自洽。得出
f(x1x2)=f(x1)+f(x2)
那么相乘怎么得出相加呢,所以这个f(x): = (信息量)必须有一个log
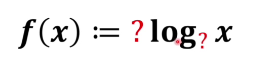
那为什么是log 因为就是定义 只要满足体系自洽就行,作为定义本身就是赋予含义。
所以这个式子有两个地方不清楚一个是系数另外一个是以几为底。
我们可以想一下x自变量越小 这件事信息量就越大 这是一个相反的关系,所以前面系数可以赋值为-1。
那么log以几为底合适呢其实到这里自洽已经很满足了,以几为底都是比较随意的,这里可以以2为底也可以以e为底。这里就以2为底得出
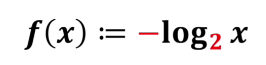
f(1/8)=f(1/4)+f(1/2)
我们可以算出中国队夺冠信息量为3
比如说有两场比赛 日本队跟韩国队比赛获胜概率都是1/2

中国队跟韩国队获胜的概率分别是99/100和1/100

那么可以得出日本队信息量为
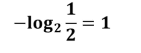
中国队信息量为
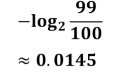
韩国队信息量为
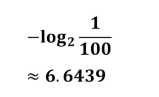
仔细想一下在这里信息量是不能直接相加的这里是各个球队赢球的话信息量是这么多所以前面要乘以概率得出各个球队队系统贡献量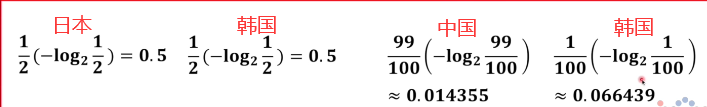
观察上面公式子可以得出信息量乘以占比再相加 ,就是相当于求期望然后我们可以对熵进行定义。假如说一个概率系统p
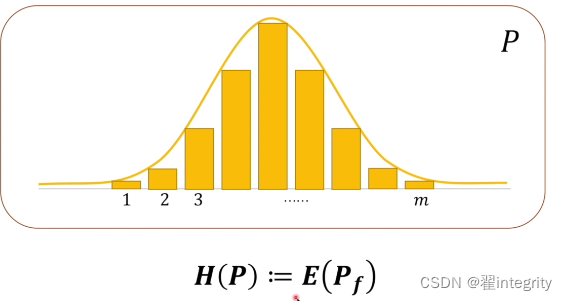
我们·可以求这个概率系统的熵 熵就是定义成对这个系统求期望
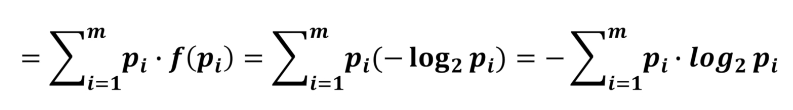
这个就是熵的定义,通过熵的定义我们可以看出这是对整体系统的衡量衡量的结果也能反映出模型的不确定程度。
1.2相对熵,kl散度
通过上面我们知道可以通过计算熵的大小来衡量不同模型混乱程度的区别 但是人脑模型的熵不太好计算那怎么办?我们引入相对熵的概念,也叫kl散度。KL散度 = 交叉熵 - 信息熵
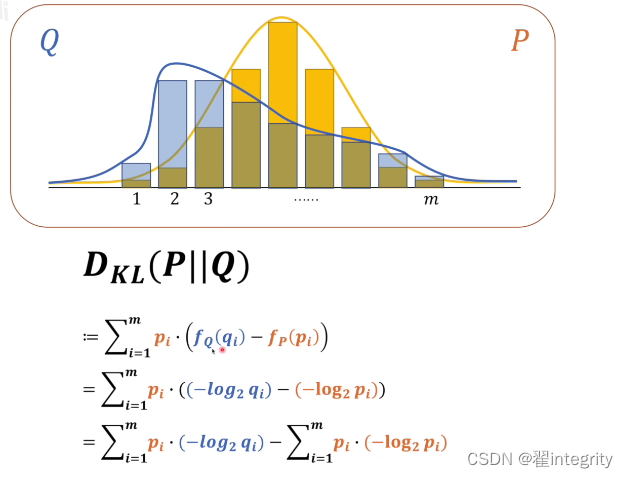
这里两个不同系统p跟q,比较两个系统差异性
下面就是kl散度 kl散度越小证明越接近 , p在q前代表以p为基准去考虑p跟q相差多少
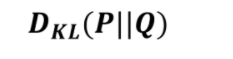
这个是q系统的信息量减去p系统的信息量的差值求整体期望
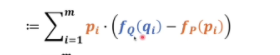
最后化简 我们可以发现后面这个式子就是系统p的熵,在前面我们把p系统当成基准所以p的熵是恒定的
所以我们看q是不是跟p的差异比较小是要看前面部分,公式前面部分就叫交叉熵。
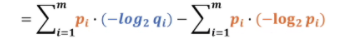
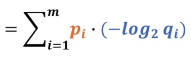
我们可以用H(p,q)来表示交叉熵函数
前面我们说kl散度越趋近于零代表模型越接近 那么我们可以发现后面p的熵肯定大于零,交叉熵的值越小kl散度越大,交叉熵的值越大kl的散度也越大,这样就给我们判断带来难题。我们希望交叉熵只占一边,这样用它做损失函数会简单很多。通过吉布斯不等式我们可以看出kl散度绝对是大于零的。

当q 跟p相等的时候等于零,不等的时候大于零。所以这个公式前面一定大于后面也就是说交叉熵函数值越小两个模型越接近。
剩下的就是我们要把交叉熵应用到神经网络里面
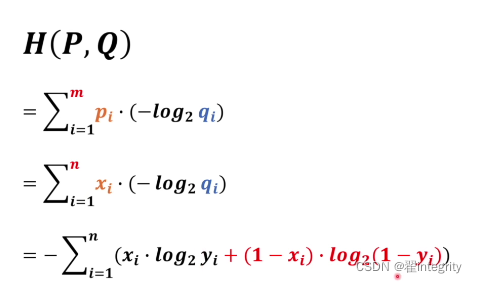
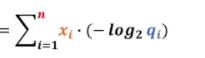
在这里面xi 有两种情况一种是猫一种不是猫,yi 则表示有多像猫有很多情况。
交叉熵函数的n就定义为两个不同系统当中变量更多的那一个。
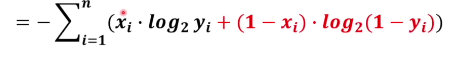
把m换成n,n就是训练用的图片个数,xi就是训练用的图片打的标签是猫或者不是猫。yi代表的就是有多像猫所以xi要跟yi对应起来当xi等于0的时候,yi就是有多像猫。当xi等于0的时候,yi代表有多不像猫。
2 交叉熵函数的应用分析
2.1 交叉熵函数单分类问题应用
被分类物体只能归属于唯一一个类别;
该物体的所有类别预测概率之和为1。
二分类问题就是比如说今天小丁打王者农药与不打王者农药两种选择那么公式简化为
*loss=–[y*log 2^a+(1- y)log2^(1-a)]
打农药标签值为1,不打则为0.根据小丁以往的表现今天打农药的概率为0.7,然后事实证明今天她打农药了那么真实值为1,
那么通过计算loss值为loss= -[1*log 2^0.7+(1- 1)*log2^(1-0.7)]**=-log 2^0.7
| 序号 | 事件 | 概率p |
|---|---|---|
| A | 小丁打王者 | 0.7 |
| B | 小丁不打王者 | 0.3 |
对应一个batch的为 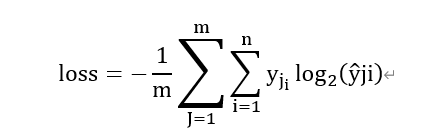
2.2交叉熵在多分类问题中的使用
多分类任务中,被分类对象可以拥有多个标签,例如图二的标签为狗、猫。此时每个类别之间相互独立。
这里的多类别是指,每一张图像样本可以有多个类别,比如同时包含一只猫和一只狗,和单分类问题的标签不同,多分类的标签是n-hot。
| 猪 | 猫 | 狗 | |
|---|---|---|---|
| 标签 | 1 | 1 | 0 |
| 概率 | 0.1 | 0.7 | 0.8 |
值得注意的是,这里的Pred不再是通过softmax计算的了,这里采用的是sigmoid。将每一个节点的输出归一化到[0,1]之间。所有Pred值的和也不再为1。换句话说,就是每一个Label都是独立分布的,相互之间没有影响。所以交叉熵在这里是单独对每一个节点进行计算,每一个节点只有两种可能值,所以是一个二项分布。前面说过对于二项分布这种特殊的分布,熵的计算可以进行简化。同样的,交叉熵的计算也可以简化,即
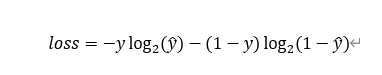
loss猪=-1log 2^0.1
loss猫=-1log2^0.7
loss狗=-1*log2^0.2
loss=loss猫+loss狗+loss猪
所以每一个batch的loss就是
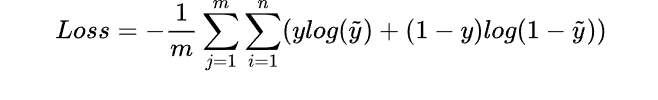
这里log是以2为底(问题不大)
式中m为当前batch中的样本量,n为类别数。
单分类时,每张图片的损失是一个交叉熵,交叉熵针对的是所有类别(所有类别概率和是1)。 多分类时,每张图片的损失是N个交叉熵之和(N为类别数),交叉熵针对的是单个类别(单个类别概率和是1)。
2.3学习过程与优缺点
交叉熵损失函数经常用于分类问题中,特别是在神经网络做分类问题时,也经常使用交叉熵作为损失函数,此外,由于交叉熵涉及到计算每个类别的概率,所以交叉熵几乎每次都和sigmoid(或softmax)函数一起出现。
我们用神经网络最后一层输出的情况,来看一眼整个模型预测、获得损失和学习的流程:
神经网络最后一层得到每个类别的得分scores(也叫logits);
该得分经过sigmoid(或softmax)函数获得概率输出;
模型预测的类别概率输出与真实类别的one hot形式进行交叉熵损失函数的计算。
学习任务分为二分类和多分类情况,我们分别讨论这两种情况的学习过程。
2.3.1二分类情况

如上图所示,求导过程可分成三个子过程,即拆成三项偏导的乘积: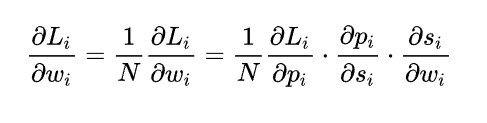
计算第一项:
pi 表示样本i预测为正类的概率
yi为符号函数,i样本为正类时取1 ,否则取0 ;
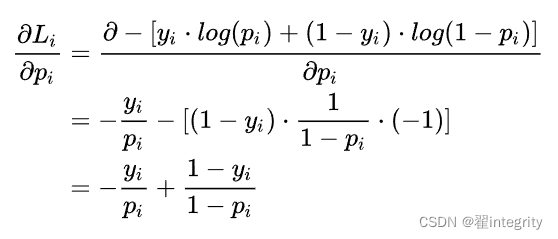
计算第二项:
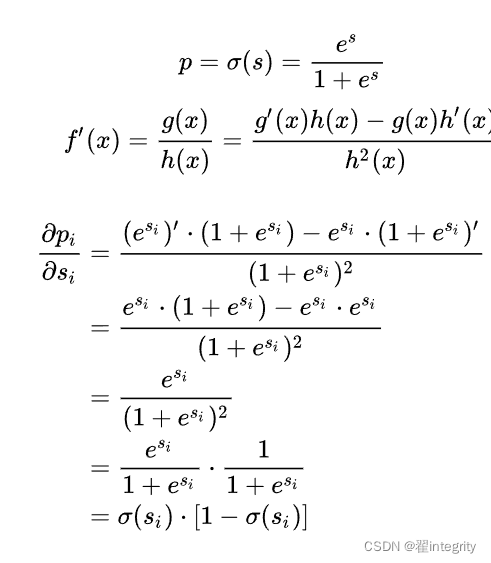
计算第三项:
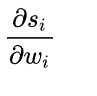
一般来说,scores是输入的线性函数作用的结果,所以有:
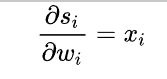
计算结果:
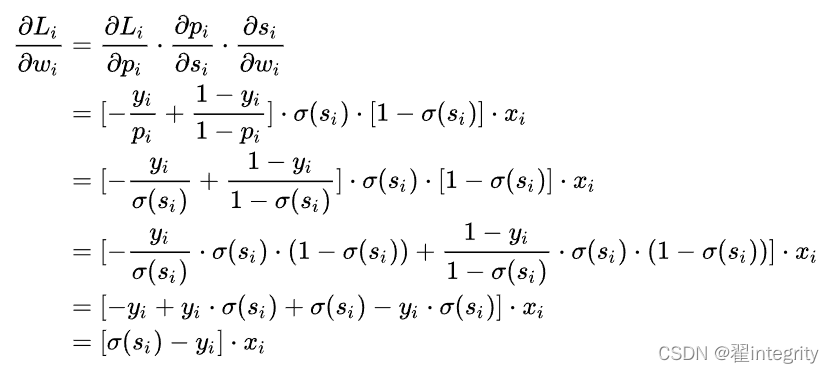
2.3.2优缺点
2.3.1.2优点
在用梯度下降法做参数更新的时候,模型学习的速度取决于两个值:一、学习率;二、偏导值。其中,学习率是我们需要设置的超参数,所以我们重点关注偏导值。从上面的式子中,我们发现,偏导值的大小取决于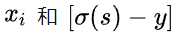
,我们重点关注后者,后者的大小值反映了我们模型的错误程度,该值越大,说明模型效果越差,但是该值越大同时也会使得偏导值越大,从而模型学习速度更快。所以,使用逻辑函数得到概率,并结合交叉熵当损失函数时,在模型效果差的时候学习速度比较快,在模型效果好的时候学习速度变慢。
2.3.1.3缺点
Deng [4]在2019年提出了ArcFace Loss,并在论文里说了Softmax Loss的两个缺点:1、随着分类数目的增大,分类层的线性变化矩阵参数也随着增大;2、对于封闭集分类问题,学习到的特征是可分离的,但对于开放集人脸识别问题,所学特征却没有足够的区分性。对于人脸识别问题,首先人脸数目(对应分类数目)是很多的,而且会不断有新的人脸进来,不是一个封闭集分类问题。
另外,sigmoid(softmax)+cross-entropy loss 擅长于学习类间的信息,因为它采用了类间竞争机制,它只关心对于正确标签预测概率的准确性,忽略了其他非正确标签的差异,导致学习到的特征比较散。基于这个问题的优化有很多,比如对softmax进行改进,如L-Softmax、SM-Softmax、AM-Softmax等。
https://www.bilibili.com/video/BV15V411W7VB?from=search&seid=776334875013814966&spm_id_from=333.337.0.0
https://blog.csdn.net/tsyccnh/article/details/79163834
https://zhuanlan.zhihu.com/p/95386061
总结
以上就是今天要讲的内容,本文仅仅简单介绍了熵,信息量,相对熵的概念,以及应用分析希望大家多多交流共同学习!!!