SVO 从名字来看,是半直接视觉里程计,所谓半直接是指通过对图像中的特征点图像块进行直接匹配来获取相机位姿,而不像直接匹配法那样对整个图像使用直接匹配。整幅图像的直接匹配法常见于RGBD传感器,因为RGBD传感器能获取整幅图像的深度。
虽然semi-direct方法使用了特征,但它的思路主要还是通过direct method来获取位姿,这和feature-method不一样。同时,semi-direct方法和direct method不同的是它利用特征块的配准来对direct method估计的位姿进行优化。
和常规的单目一样,SVO算法分成两部分: 位姿估计,深度估计。本文对论文内容用自己的理解进行解读,并对一些关键内容会推荐一些参考文献帮助大家更进一步的学习SVO。
位姿估计
svo 方法中motion estimation的步骤可以简单概括如下:
- 对稀疏的特征块使用direct method 配准,获取相机位姿;
- 通过获取的位姿预测参考帧中的特征块在当前帧中的位置,由于深度估计的不准导致获取的位姿也存在偏差,从而使得预测的特征块位置不准。由于预测的特征块位置和真实位置很近,所以可以使用牛顿迭代法对这个特征块的预测位置进行优化。
- 特征块的预测位置得到优化,说明之前使用直接法预测的有问题。利用这个优化后的特征块预测位置,再次使用直接法,对相机位姿(pose)以及特征点位置(structure)进行优化。
下面结合作者forster的原论文对motion estimation进行更详细的讨论。
1.sparse model-based image alignment
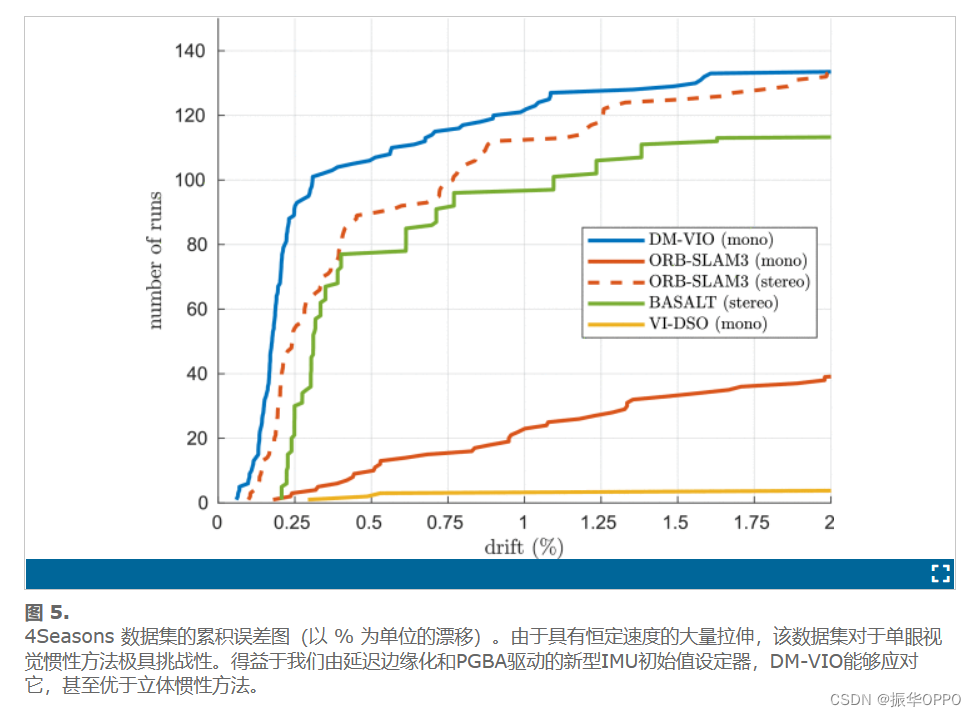
使用直接法最小化图像块重投影残差来获取位姿。如图所示:其中红色的 Tk,k−1 为位姿,即优化变量。
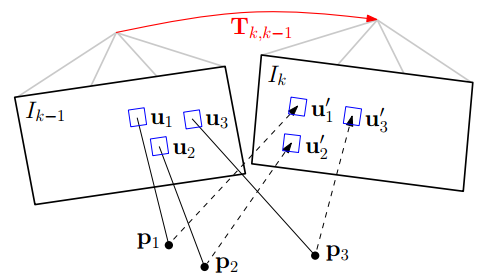
step1. 准备工作。假设相邻帧之间的位姿 Tk,k−1 已知,一般初始化为上一相邻时刻的位姿或者假设为单位矩阵。通过之前多帧之间的特征检测以及深度估计,我们已经知道第k-1帧中特征点位置以及它们的深度。
step2. 重投影。知道 Ik−1 中的某个特征在图像平面的位置 (u,v) ,以及它的深度 d ,能够将该特征投影到三维空间
step3. 迭代优化更新位姿 。按理来说对于空间中同一个点,被极短时间内的相邻两帧拍到,它的亮度值应该没啥变化。但由于位姿是假设的一个值,所以重投影的点不准确,导致投影前后的亮度值是不相等的。不断优化位姿使得这个残差最小,就能得到优化后的位姿 Tk,k−1 。
将上述过程公式化如下:通过不断优化位姿 Tk,k−1 最小化残差损失函数。
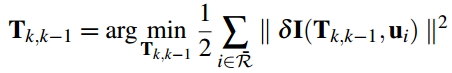
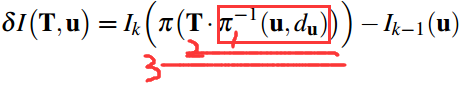
上面的非线性最小化二乘问题,可以用高斯牛顿迭代法求解,位姿的迭代增量 ξ (李代数)可以通过下述方程计算:
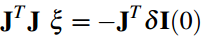
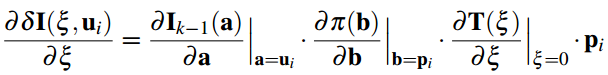
好了,先别在旁枝末叶上耗费精力,继续回到主题。到这里,我们已经能够估计位姿了,但是这个位姿肯定不是完美的。导致重投影预测的特征点在 Ik 中的位置并不和真正的吻合,也就是还会有残差的存在。如下图所示:
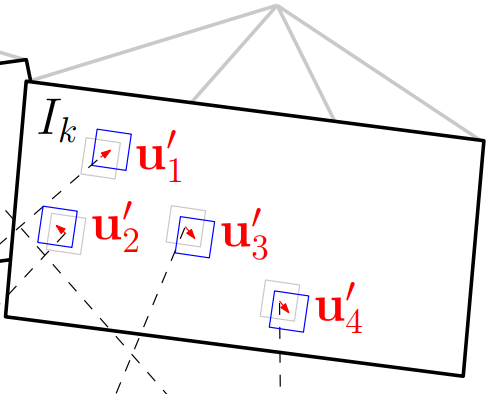
2.Relaxation Through Feature Alignment
通过第一步的帧间匹配能够得到当前帧相机的位姿,但是这种frame to frame估计位姿的方式不可避免的会带来累计误差从而导致漂移。所以,应该通过已经建立好的地图模型,来进一步约束当前帧的位姿。
地图模型通常来说保存的就是三维空间点,因为每一个Key frame通过深度估计能够得到特征点的三维坐标,这些三维坐标点通过特征点在Key Frame中进行保存。所以SVO地图上保存的是Key Frame 以及还未插入地图的KF中的已经收敛的3d点坐标(这些3d点坐标是在世界坐标系下的),也就是说地图map不需要自己管理所有的3d点,它只需要管理KF就行了。先看看选取KF的标准是啥?KF中保存了哪些东西?当新的帧new frame和相邻KF的平移量超过场景深度平均值的12%时(比如四轴上升),new frame就会被当做KF,它会被立即插入地图。同时,又在这个新的KF上检测新的特征点作为深度估计的seed,这些seed会不断融合新的new frame进行深度估计。但是,如果有些seed点3d点位姿通过深度估计已经收敛了,怎么办?map用一个point_candidates来保存这些尚未插入地图中的点。所以map这个数据结构中保存了两样东西,以前的KF以及新的尚未插入地图的KF中已经收敛的3d点。
通过地图我们保存了很多三维空间点,很明显,每一个new frame都是可能看到地图中的某些点的。由于new frame的位姿通过上一步的直接法已经计算出来了,按理来说这些被看到的地图上的点可以被投影到这个new frame中,即图中的蓝色方框块。上图中分析了,所有位姿误差导致这个方框块在new frame中肯定不是真正的特征块所处的位置。所以需要Feature Alignment来找到地图中特征块在new frame中应该出现的位置,根据这个位置误差为进一步的优化做准备。基于光度不变性假设,特征块在以前参考帧中的亮度应该和new frame中的亮度差不多。所以可以重新构造一个残差,对特征预测位置进行优化:
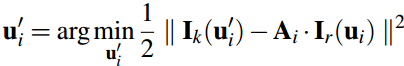
这时候的迭代量计算方程和之前是一样的,只不过雅克比矩阵变了,这里的雅克比矩阵很好计算:
通过这一步我们能够得到优化后的特征点预测位置,它比之前通过相机位姿预测的位置更准,所以反过来,我们利用这个优化后的特征位置,能够进一步去优化相机位姿以及特征点的三维坐标。所以位姿估计的最后一步就是Pose and Structure Refinement。
3.Pose and Structure Refinement
在一开始的直接法匹配中,我们是使用的光度误差,这里由于优化后的特征位置和之前预测的特征位置存在差异,这个能用来构造新的优化目标函数。
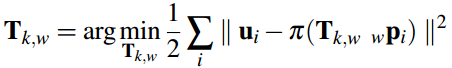
Discussion:
作者在论文discussion中简单阐述了他的motion estimationg 方法和直接使用直接法的优点,也说明了对比直接使用光流跟踪再优化位姿的优点,可以简单看看。
depth估计
最基本的深度估计就是三角化,这是多视角几何的基础内容(可以参看圣经Hartly的《Multiple View Geometry in Computer Vision》中的第十二章structure computation;可以参看我的相应博客)。我们知道通过两帧图像的匹配点就可以计算出这一点的深度值,如果有多幅图像,那就能计算出这一点的多个深度值。这就像对同一个状态变量我们进行了多次测量,因此,可以用贝叶斯估计来对多个测量值进行融合,使得估计的不确定性缩小。如下图所示:
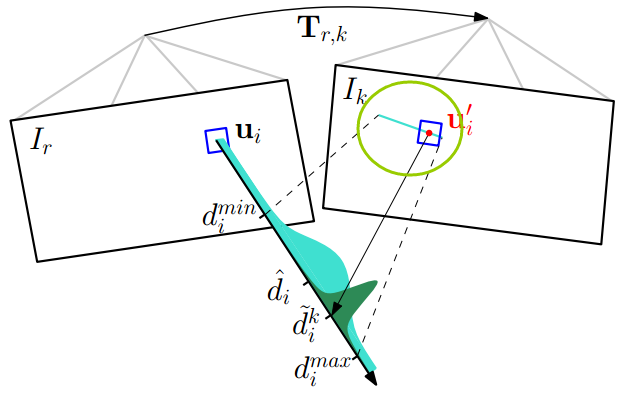
在这里,先简单介绍下svo中的三角化计算深度的过程,主要是极线搜索确定匹配点。在参考帧 Ir 中,我们知道了一个特征的图像位置,假设它的深度值在 [dmin,dmax] 之间,那么根据这两个端点深度值,我们能够计算出他们在当前帧 Ik 中的位置,如上图中草绿色圆圈中的线段。确定了特征出现的极线段位置,就可以进行特征搜索匹配了。如果极线段很短,小于两个像素,那直接使用上面求位姿时提到的Feature Alignment光流法就可以比较准确地预测特征位置。如果极线段很长,那分两步走,第一步在极线段上间隔采样,对采样的多个特征块一一和参考帧中的特征块匹配,用Zero mean Sum of Squared Differences 方法对各采样特征块评分,那个得分最高,说明他和参考帧中的特征块最匹配。第二步就是在这个得分最高点附近使用Feature Alignment得到次像素精度的特征点位置。像素点位置确定了,就可以三角化计算深度了。
得到一个新的深度估计值以后,用贝叶斯概率模型对深度值更新。在LSD slam中,假设深度估计值服从高斯分布,用卡尔曼滤波(贝叶斯的一种)来更新深度值。这种假设中,他认为深度估计值效果很棒,很大的概率出现在真实值(高斯分布均值)附近。而SVO的作者采用的是Vogiatzis的论文《Video-based, real-time multi-view stereo》提到的概率模型:
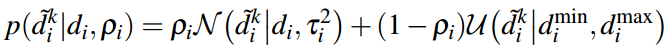
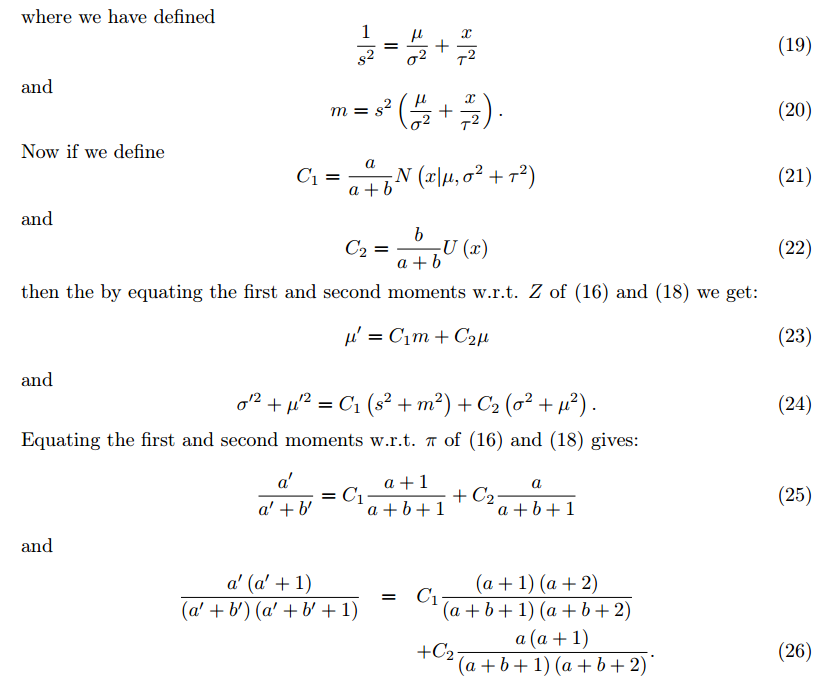
在深度估计的过程中,除了计算深度值外,这个深度值的不确定性也是需要计算的,它在很多地方都会用到,如极线搜索中确定极线的起始位置和长度,如用贝叶斯概率更新深度的过程中用它来确定更新权重(就像卡尔曼滤波中协方差矩阵扮演的角色),如判断这个深度点是否收敛了,如果收敛就插入地图等等。SVO的作者Forster作为第二作者发表的《REMODE: Probabilistic, Monocular Dense Reconstruction in Real Time》中对由于特征定位不准导致的三角化深度误差进行了分析,如下图:
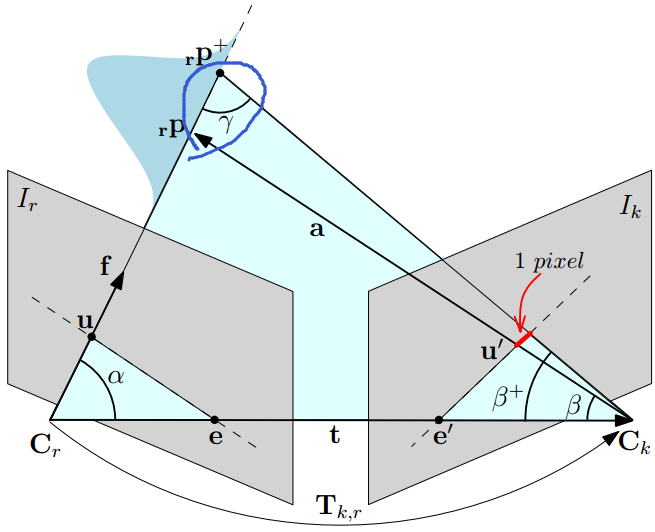
它是通过假设特征点定位差一个像素偏差,来计算深度估计的不确定性。具体推导见原论文,简单的几何关系。
最后,简单说下SVO的初始化过程:它假设前两个关键帧所拍到的特征点在一个平面上(四轴飞行棋对地面进行拍摄),然后估计单应性H矩阵,并通过三角化来估计初始特征点的深度值。SVO初始化时triangulation的方法具体代码是vikit/math_utils.cpp里的triangulateFeatureNonLin()函数,使用的是中点法,关于这个三角化代码算法的推导见github issue。还有就是SVO适用于摄像头垂直向下的情况(也就是无人机上,垂直向上也可以,朝着一面墙也可以),为什么呢?1.初始化的时候假设的是平面模型 2.KF的选择是个极大的限制,除了KF的选择原因外摄像头水平朝前运动的时候,SVO中的深度滤波做的不好,这个讨论可以看看github issue,然而在我的测试中,不知道修改了哪些参数,稍微改动了部分代码,发现前向运动,并且对着非平面SVO也是很溜的。
这里简单理顺了svo的思路,并补充了看svo所需的材料,这样看代码就能够顺很多。同时我也对svo的代码加了一些中文注释,后续会放到github上,希望帮助大家加快理解svo。最后,祝大家好运,一起分享知识。
如有错误请指出。– 白巧克力