日萌社
日萌社
人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新)
大数据组件使用 总文章
- kafka 生产/消费API、offset管理/原理、kafka命令
- kafka 命令、API
- Kafka 安装、原理、使用
- mapreduce 实时消费 kafka 数据
1.使用控制台运行
1.创建一个topic主题 cd /root/kafka chmod 777 /root/kafka/bin/kafka-topics.sh格式:bin/kafka-topics.sh --create --zookeeper IP:2181 --replication-factor 副本数 --partitions 分片数/分区数 --topic 主题名例子:bin/kafka-topics.sh --create --zookeeper NODE1:2181 --replication-factor 1 --partitions 1 --topic order
2.编写代码启动一个生产者,生产数据
cd /root/kafka chmod 777 /root/kafka/bin/kafka-console-producer.sh格式:bin/kafka-console-producer.sh --broker-list IP:9092 --topic 主题名例子:bin/kafka-console-producer.sh --broker-list NODE1:9092 --topic order
3.编写代码启动给一个消费者,消费数据
cd /root/kafka chmod 777 /root/kafka/bin/kafka-console-consumer.sh格式:bin/kafka-console-consumer.sh --zookeeper IP:2181 --from-beginning --topic 主题名例子:bin/kafka-console-consumer.sh --zookeeper NODE1:2181 --from-beginning --topic order
4.Kafka 常用操作命令
1.查看当前服务器中的所有 topiccd /root/kafka格式:bin/kafka-topics.sh --list --zookeeper zookeeper的IP:2181例子:bin/kafka-topics.sh --list --zookeeper NODE1:21812.创建 topiccd /root/kafka格式:bin/kafka-topics.sh --create --zookeeper zookeeper的IP:2181 --replication-factor 副本数 --partitions 分片数/分区数 --topic 主题名例子:bin/kafka-topics.sh --create --zookeeper NODE1:2181 --replication-factor 1 --partitions 1 --topic test3.删除 topic需要在kafka集群中的每个kafka服务器中的 vim /root/kafka/config/server.properties 中设置 delete.topic.enable=true 否则只是标记删除或者直接重启cd /root/kafka格式:bin/kafka-topics.sh --delete --zookeeper zookeeper的IP:2181 --topic 主题名例子:bin/kafka-topics.sh --delete --zookeeper NODE1:2181 --topic test4.通过 shell 命令发送消息cd /root/kafka格式:bin/kafka-console-producer.sh --broker-list kafka的IP:9092 --topic 主题名例子:bin/kafka-console-producer.sh --broker-list NODE1:9092 --topic test5.通过 shell 消费消息cd /root/kafka格式:bin/kafka-console-consumer.sh --zookeeper zookeeper的IP:2181 --from-beginning --topic 主题名例子:bin/kafka-console-consumer.sh --zookeeper NODE1:2181 --from-beginning --topic test6.查看消费位置cd /root/kafka格式:bin/kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --zookeeper zookeeper的IP:2181 --group testGroup例子:bin/kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --zookeeper NODE1:2181 --group testGroup7.查看某个 Topic 的详情cd /root/kafka格式:bin/kafka-topics.sh --topic 主题名 --describe --zookeeper zookeeper的IP:2181例子:bin/kafka-topics.sh --topic 主题名 --describe --zookeeper NODE1:21818.对分区数进行修改cd /root/kafka格式:bin/kafka-topics.sh --zookeeper zookeeper的IP --alter --partitions 2 --topic 主题名例子:bin/kafka-topics.sh --zookeeper NODE1 --alter --partitions 分片数/分区数 --topic 主题名消费者:
旧版:kafka-console-consumer --zookeeper cdh01:2181,cdh02:2181,cdh03:2181 --topic test --from-beginning新版:新版中仍然使用旧版的消费者命令会报错:zookeeper is not a recognized optionkafka-console-consumer --bootstrap-server cdh01:9092,cdh02:9092,cdh03:9092 --topic test --from-beginning指定消费者组:kafka-console-consumer --bootstrap-server cdh01:9092,cdh02:9092,cdh03:9092 --group testGroup --topic test --from-beginning查看消费位置
指定消费者组:kafka-consumer-groups --bootstrap-server cdh01:9092,cdh02:9092,cdh03:9092 --describe --group testGroup kafka-consumer-groups --bootstrap-server cdh01:9092,cdh02:9092,cdh03:9092 --describe --group testGroup --all-topics
2.使用Java api运行
1.java工程-maven,依赖<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>0.11.0.1</version></dependency>2.生产者(先启动消费者等待接收数据,然后再启动生产者进行发送数据)//kafka生产者:订单的生产者代码public class OrderProducer{public static void main(String[] args) throws InterruptedException{// 通过Properties配置文件的方式 配置"连接集群"的信息Properties props = new Properties();props.put("bootstrap.servers", "NODE1:9092");props.put("acks", "all");props.put("retries", 0);props.put("batch.size", 16384);props.put("linger.ms", 1);props.put("buffer.memory", 33554432);props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");//kafka生产者KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(props);for (int i = 0; i < 10000; i++){//数据分发策略:可以指定数据发往哪个partition,当ProducerRecord 的构造参数中有partition的时候,就可以发送到对应partition上// new ProducerRecord<String, String>("topic主题名",partition,"key", "value")ProducerRecord<String, String> partition = new ProducerRecord<String, String>("order", 0, "key", "订单"+i);//数据分发策略:如果生产者没有指定partition,但是发送消息中有key,根据key的hash值的方式发送数据到那个partition分区/分片中// new ProducerRecord<String, String>("topic主题名","key", "value")ProducerRecord<String, String> key = new ProducerRecord<String, String>("order", "key", "value"+i);//数据分发策略:既没有指定partition,也没有key的情况下如何发送数据。使用轮询的方式发送数据到那个partition分区/分片中// new ProducerRecord<String, String>("topic主题名", "value")ProducerRecord<String, String> value = new ProducerRecord<String, String>("order", "订单信息!"+i);//kafka生产者发送数据kafkaProducer.send(value);}}}3.消费者(先启动消费者等待接收数据,然后再启动生产者进行发送数据) //kafka消费者:订单的消费者代码public class OrderConsumer{public static void main(String[] args){//1.通过Properties配置文件的方式 配置"连接集群"的信息Properties props = new Properties();props.put("bootstrap.servers", "NODE1:9092");//配置group.id:多个Consumer的group.id都相同的话,表示多个Consumer都在同一个消费组group中props.put("group.id", "test");props.put("enable.auto.commit", "true");props.put("auto.commit.interval.ms", "1000");props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");// Kafka消费者KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(props);//2.订阅某个topic主题下的相关消息数据用于消费。可以订阅多个topic主题,封装到一个 List中,可以使用Arrays.asList进行封装kafkaConsumer.subscribe(Arrays.asList("order"));while (true){//jdk queue的操作方法:offer插入元素、poll获取元素。//blockingqueue的操作方法:put插入元素,take获取元素。ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(100);for (ConsumerRecord<String, String> record : consumerRecords){//此处需要等待到有数据才能消费进行获取打印System.out.println("消费的数据为:" + record.value());}}}}
3.topic主体中的分区partition 和 group.id消费者组 的关系
Consumer Group(CG)消费者组:这是 kafka 用来实现一个 topic(主题) 消息的广播(发给所有的 consumer消费者)和 单播(发给任意一个 consumer消费者)的手段。一个 topic(主题) 可以有多个 CG消费者组。topic(主题) 的消息会复制(不是真的复制,是概念上的)到所有的 CG消费者组,但每个 partion(分区) 只会把消息发给该 CG 中的一个consumer消费者。如果需要实现广播,只要每个 consumer消费者 有一个独立的 CG 就可以了。要实现单播只要所有的 consumer 在同一个 CG。用 CG消费者组 还可以将 consumer消费者 进行自由的分组,而不需要多次发送消息到不同的 topic(主题)。Broker:一台 kafka 服务器就是一个 broker(中间人)。一个kafka集群(cluster) 由多个 broker(中间人) 组成。一个 broker 可以容纳多个 topic(主题)。Partition(分区):为了实现扩展性,一个非常大的 topic(主题) 可以分布到多个 broker(即服务器)上,一个topic(主题) 可以分为多个 partition(分区),每个 partition(分区) 是一个有序的队列(Queue)。partition(分区) 中的每条消息都会被分配一个有序的 id(offset)。kafka 只保证按一个 partition(分区) 中的顺序 将消息发给 consumer消费者,不保证一个 topic 的整体(多个 partition分区 间)的顺序
情况一:同一个topic的一个partition只能被同一个customerGroup的一个customer消费;group里多于partition数量的customer会空闲;
情况二:同一个topic的partition数量多于同一个customerGroup的customer数量时,会有一个customer消费多个partition,这样也就没法保证customer接收到的消息的顺序性,kafka只保证在一个partition上数据是有序的,无法保证topic全局数据的顺序性;
情况三:一个topic 的partitions被多个customerGroup消费时,可以并行重复消费;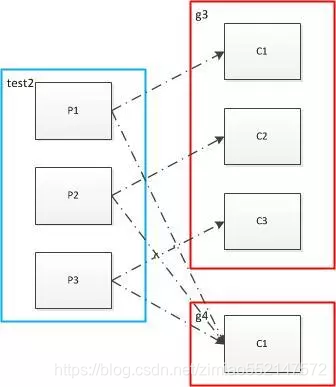
kafka topic partition被同一个GROUPID的多个消费者消费,只有一个能收到消息的原因一般有如下:1.只有一个partition分区;同一个topic的同一个partition分区只允许同一个customerGroup的一个消费者消费信息,一个partition上不允许同一个消费者组的多个消费者并发,但同一个partition上是可以多个不同消费者组种的消费者并发消费的;2.多个partition分区,但是,消息在生产时只发往到了一个partiton上;key的hashCode%partitionNum相同导致,或者自定义了分区策略;导致这种严重的数据倾斜;
1.发送到Kafka的消息会根据key,发送到对应topic的partition中,有默认的分发规则(也可以自己重写分发规则),基本上就是相同的key发送到一个partition中,不同的key有可能发送到相同的partition中。2.group是消费者中的概念,按照group(组)对消费者进行区分。对于每个group,需要先指定订阅哪个topic的消息,然后该topic下的partition会平均分配到group下面的consumer上。所以会出现以下这些情况:1.一个topic被多个group订阅,那么一条消息就会被不同group中的多个consumer处理。如果需要实现广播,只要每个 consumer消费者 有一个独立的 CG 就可以了。一个 topic(主题) 可以有多个 CG消费者组。topic(主题) 的消息会复制(不是真的复制,是概念上的)到所有的 CG消费者组,但每个 partion(分区) 只会把消息发给该 CG 中的一个consumer消费者。2.同一个group中,每个partition只会被一个consumer处理,这个consumer处理的消息不一定是同一个key的。所以需要在处理的地方判断。要实现单播只要所有的 consumer 在同一个 CG。3.例子,现在有一个用户信息修改的回调消息扔到消息队列里,有两个业务要处理,一个是更新数据库,一个是更新es索引信息topic:user_update_topickey:user_update_key_cid //cid标志公司的区分信息这样子的话,同一个公司的用户更新会被分配到一个partition中,同一个公司的用户更新能保证前后顺序不变group1中的consumer更新数据库,group:consumer1_groupgroup2中的consumer更新es索引信息,group:consumer2_groupgroup1、group2这个两个group会分别消费这个topic下的数据,对于每个group,内部的consumer会平分topic下的partition,相当于group中的每个consumer会处理多个公司的数据,但处理的公司不会有重叠。以上是topic中partition多余group中的消费者的时候,如果group下面有3个消费者,但是分区partition只有一个,那么三个消费者中只有一个会消费消息。
消费者组 (Consumer Group)consumer group是kafka提供的可扩展且具有容错性的消费者机制。既然是一个组,那么组内必然可以有多个消费者或消费者实例(consumer instance),它们共享一个公共的ID,即group ID。组内的所有消费者协调在一起来消费订阅主题(subscribed topics)的所有分区(partition)。当然,每个分区只能由同一个消费组内的一个consumer来消费(当然该分区还可以同时分配给其他group中的某个consumer来消费)。个人认为,理解consumer group记住下面这三个特性就好了:1.consumer group下可以有一个或多个consumer instance,consumer instance可以是一个进程,也可以是一个线程2.group.id是一个字符串,唯一标识一个consumer group3.consumer group下订阅的topic下的每个分区只能分配给某个group下的一个consumer,当然该分区还可以同时分配给其他group中的某个consumer来消费。kafka consumer:消费者可以从多个broker中读取数据。消费者可以消费多个topic中的数据。因为Kafka的broker是无状态的,所以consumer必须使用partition offset来记录消费了多少数据。如果一个consumer指定了一个topic的offset,意味着该consumer已经消费了该offset之前的所有数据。consumer可以通过指定offset,从topic的指定位置开始消费数据。consumer的offset存储在Zookeeper中。offset:用来保存消费进度。offset表示在当前topic,当前groupID下消费到的位置。offset为earliest并不代表offset=1。在不进行过期配置的情况下,kafka消息默认7天时间就会过期。过期后其offset也就随之发生变化,使得用数字进行配置的消费进度并不准确。1.earliest:自动重置到最早的offset。2.latest:看上去重置到最晚的offset。3.none:如果边更早的offset也没有的话,就抛出异常给consumer,告诉consumer在整个consumer group中都没有发现有这样的offset。groupID:一个字符串用来指示一组consumer所在的组。相同的groupID表示在一个组里。相同的groupID消费记录offset时,记录的是同一个offset。所以,此处需要注意 (1)如果多个地方都使用相同的groupid,可能造成个别消费者消费不到的情况(2)如果单个消费者消费能力不足的话,可以启动多个相同groupid的consumer消费,处理相同的逻辑。
produce方面:如果有多个分区,发送的时候按照key值hashCode%partitionNum哈希取模分区数来决定该条信息发往哪个partition, 这里可以自定义partition的分发策略,只要实现Partitioner接口就好,可以自定义成随机分发或者fangwang发往指定分区;customer方面:对于topic中的partition来说,一个partition只允许一个customer来消费,同一个partition上不允许customer并发;Partition数量 > customer数量时:一个consumer会对应于多个partitions,这里主要合理分配consumer数和partition数,否则会导致partition里面的数据被取的不均匀 。最好partiton数目是consumer数目的整数倍,所以partition数目很重要,比如取24,就很容易设定consumer数目 。Partition数量 < customer数量时:就会有剩余的customer闲置,造成浪费;如果一个consumer从多个partition读到数据,不保证数据间的顺序性,kafka只保证在一个partition上数据是有序的,但多个partition,根据你读的顺序会有不同;kafka只保证在一个上数据是有序的(每个partition都有segment文件记录消息的顺序性),无法保证topic全局数据的顺序行;增减consumer,broker,partition会导致rebalance,所以rebalance后consumer对应的partition会发生变化。
4.storm消费kafka时并行度设置问题
1.首先明确的一点是,storm的并行度都是executor即线程级别的并行;包括work(进程),executor(线程)的设置,具体体现在works,spout,bolt设置上,同一个executor上设置多个task还是会串行化执行,并不能提高执行效率,这也是由于并行是线程并行,一个线程的多个task肯定是有先后执行顺序的,有顺序那就不是并行;关于node,work,executor,task关系和work,spout,bolt,并行度设置网上有很多资料,挺详细;2.这里记录下我遇到的自己关系的另外两个问题:一个是从kafka消费消息是spout并行度设置,另一个ack响应开启的是线程还是进程以及如何设置其数量;1.第一个问题:其实理解了上面kafka customer和partition的关系第一个问题也就解决了,spout的并发度实例数量设置最好和partition数量一样,这样能保证一个spout消费者实例对应一个partition,即实现了一个partition中消息消费的顺序性(有时消息的顺序性要求并不是很高)也能很好地提高整个topology的执行效率,至少对拓扑执行效率来说,瓶颈不会卡在spout(数据源)这里;2.第二个问题:通过Storm UI发现,work和spout,bolt并行度不变的情况下,多开几个acker_executors,works的数量并没有增加,反而是executors数量增加,这样就确定了acker_executors如其名一样只是线程,并不像有些网友说的ack的执行是会单独开启ack进程再在该进程里运行ack响应线程。他其实就是一个普通的ack线程,运行在已有的work进程里;3.另外通过测试发现,我设置了4个work,4个spout,4个bolt,没有设置acker_executors,Storm UI上显示Num workers是4,Num executors却是12(4个spout,4个bolt 这里一共是8个executors),所以默认情况下一个work里会有一个acker_executors。4.默认情况下 一个work会有一个executor,一个executor会有一个task,如果设置了他们的数量,就会按照设置的数量来生成对应实例;如开了4个work,2个spout,3个bolt,那spout和bolt的executors一共就会有5个(spout executors 2个,bolt executors 3个,),相当于有2个work里的每个work都有1个spout executor和1个bolt executor,另外还有1个work里只有1个bolt executor,另外还有一个work里啥也没有;其实这种配置会导致多开一个啥活也不干的work进程,有些浪费;
5.kafka 多个消费者在同一个groupID消费者组中,只有一个消费者能收到消息,解决方案如下
1.业务需求:将一个业务逻辑分拆出来单独部署多个服务器上,然后与主程序之间通过kafka队列通信,每个业务实例上都有一个消费者在监听队列,且他们的groupid相同。我们的原意是主程序 往 队列上发送的命令参数(数据值)会被其中随机的一个消费者收到,从而实现一个负载均衡的效果,但是后来发现主程序发送往队列上的控制消息(数据值)始终是被其中固定的一个服务器上的消费者收到,其他的消费者从头到尾没有收到过。这样自然就达不到我们负载均衡的效果了。2.后来发现,造成这个结果的原因可能有两个:1.分区数(Partition)设成了12.发送消息的时候指定了key值3.原因一的解决方案:1.原因:分区数(Partition)设成了12.分析:因为kafka为了保证了消息的一致性,同一个分区的消息只会被于此关联的同一个消费者接收到(大致就是这个意思)。如果只有一个分区的话,如果第一条消息被其中一个消费者收到后,后面的消息始终会被这个消费者收到。所以应保证分区的数目大于消费者的数目。3.解决方案:#查看partition数据bin/kafka-topics.sh --zookeeper zk1,zk2,zk3 --describe --partitions 20 --topic topic_test#增加partition数目#增加partition数目后,如果使用的是java的kafka-client的Producer的话,会由于producer内部的缓存机制,#导致过几分钟后才被producer感知到partition数目的变化bin/kafka-topics.sh --zookeeper zk1,zk2,zk3 --alter --partitions 20 --topic topic_test4.原因二的解决方案:1.原因:发送消息的时候指定了key值2.分析:我们改了partitions 的数目后,再次测试,还是始终被其中一个消费者收到。后来查看了producer的send方法,发现了是因为我们把key设置为了””,也就是指定了key值为空字符串。3.send方法发送 代码分析:producer.send(new ProducerRecord<String, String>("test","",""),new Callback() {@Overridepublic void onCompletion(RecordMetadata metadata, Exception exception) {// TODO Auto-generated method stub}});4.send方法的实现 和 partition方法的调用 代码分析:@Overridepublic Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {try {// first make sure the metadata for the topic is availablelong waitedOnMetadataMs = waitOnMetadata(record.topic(), this.maxBlockTimeMs);long remainingWaitMs = Math.max(0, this.maxBlockTimeMs - waitedOnMetadataMs);byte[] serializedKey;try {serializedKey = keySerializer.serialize(record.topic(), record.key());} catch (ClassCastException cce) {throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +" specified in key.serializer");}byte[] serializedValue;try {serializedValue = valueSerializer.serialize(record.topic(), record.value());} catch (ClassCastException cce) {throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +" specified in value.serializer");}//可以看出 生产者往哪个partition分区 发送消息,实际是由 partition()方法得出的int partition = partition(record, serializedKey, serializedValue, metadata.fetch());int serializedSize = Records.LOG_OVERHEAD + Record.recordSize(serializedKey, serializedValue);ensureValidRecordSize(serializedSize);TopicPartition tp = new TopicPartition(record.topic(), partition);log.trace("Sending record {} with callback {} to topic {} partition {}", record, callback, record.topic(), partition);RecordAccumulator.RecordAppendResult result = accumulator.append(tp, serializedKey, serializedValue, callback, remainingWaitMs);if (result.batchIsFull || result.newBatchCreated) {log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);this.sender.wakeup();}return result.future;// handling exceptions and record the errors;// for API exceptions return them in the future,// for other exceptions throw directly} catch (ApiException e) {log.debug("Exception occurred during message send:", e);if (callback != null)callback.onCompletion(null, e);this.errors.record();return new FutureFailure(e);} catch (InterruptedException e) {this.errors.record();throw new InterruptException(e);} catch (BufferExhaustedException e) {this.errors.record();this.metrics.sensor("buffer-exhausted-records").record();throw e;} catch (KafkaException e) {this.errors.record();throw e;}}5.partition方法的实现 和 ProducerRecord对象 代码分析:private int partition(ProducerRecord<K, V> record, byte[] serializedKey , byte[] serializedValue, Cluster cluster) {Integer partition = record.partition();if (partition != null) {List<PartitionInfo> partitions = cluster.partitionsForTopic(record.topic());int numPartitions = partitions.size();// they have given us a partition, use itif (partition < 0 || partition >= numPartitions)throw new IllegalArgumentException("Invalid partition given with record: " + partition+ " is not in the range [0..."+ numPartitions+ "].");return partition;}return this.partitioner.partition(record.topic(), record.key(), serializedKey, record.value(), serializedValue,cluster);}如果发送的时候已经指定了parition的话,就会发送到指定的partition上。怎么指定呢??我们发送的是一个ProducerRecoed对象。看它的构造方法,第二个参数就是partition。public ProducerRecord(String topic, Integer partition, K key, V value) {if (topic == null)throw new IllegalArgumentException("Topic cannot be null");this.topic = topic;this.partition = partition;this.key = key;this.value = value;}如果没有指定的parition的话,就调用:this.partitioner.partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster)如果没有配置partitioner.class的话,那么partitioner默认是org.apache.kafka.clients.producer.internals.DefaultPartitioner的一个对象(参考文章末尾),查看一下它的partition()方法:public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);int numPartitions = partitions.size();if (keyBytes == null) {int nextValue = counter.getAndIncrement();List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);if (availablePartitions.size() > 0) {int part = DefaultPartitioner.toPositive(nextValue) % availablePartitions.size();return availablePartitions.get(part).partition();} else {// no partitions are available, give a non-available partitionreturn DefaultPartitioner.toPositive(nextValue) % numPartitions;}} else {// hash the keyBytes to choose a partitionreturn DefaultPartitioner.toPositive(Utils.murmur2(keyBytes)) % numPartitions;}}从上面代码就看出了如果指定了key值的话,partition的值实际上是由Utils.murmur2(keyBytes)哈希计算出来,这样自然每次都是被同一个消费者接收到。如果没有指定的话,就会通过轮询的方式逐个发送。这里有个问题就是,如果我们每次都打印出partition的值的话,可能会看到peoducer发送并不一定会按照1、2、3、4、5这样的顺序发送,这个从上面代码中能看出最终返回的不是part的值,而是availablePartitions.get(part).partition()的值,而availablePartitions里的PartitionInfo的顺序本身就不一定是严格按照顺序排列的。在org.apache.kafka.clients.producer.ProducerConfig类中可以看到kafkaproducer的配置以及默认值,其中有这么一行:.define(PARTITIONER_CLASS_CONFIG,Type.CLASS,DefaultPartitioner.class.getName(),Importance.MEDIUM, PARTITIONER_CLASS_DOC)其中静态变量 PARTITIONER_CLASS_CONFIG的值是”partitioner.class”,可以看出其默认对应的类是 DefaultPartitioner.class,当然,这里可以自定义partition的分发策略,只要实现Partitioner接口就好,例如下面代码实现了随机选择partition。public class MyPartitioner implements Partitioner{@Overridepublic void configure(Map<String, ?> configs) {// TODO Auto-generated method stub}@Overridepublic int partition(String topic, Object key, byte[] keyBytes,Object value, byte[] valueBytes, Cluster cluster) {List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);int numPartitions = partitions.size();int randomNum = new Random().nextInt(numPartitions);return partitions.get(randomNum).partition();}@Overridepublic void close() {// TODO Auto-generated method stub}}