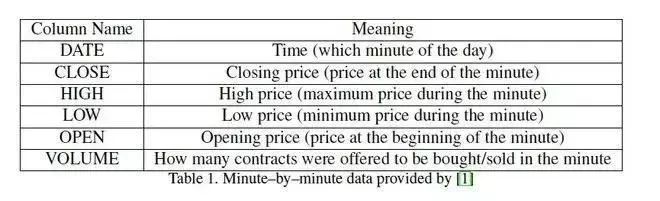
来源:脑极体
作者:藏狐
经历了漫长熊市的A股,在农历新年后迎来了一个超乎想象的春天。最能够代表牛市来临的信号,不是领跑全球的历史性涨幅,而是连你老家的大妈都准备拿出首付甚至卖房抄底了,各路股神纷纷出来指点江山了,大数据分析、人工智能选股之类的炒股秘籍也集体重现江湖了。
与“玄学炒股”和“内部消息”等方式不同,量化投资、机器模型之类的技术名词一摆出来,可信度噌地就上去了。
不过,利用人工智能模型预测股市,到底会让散户们跑赢大盘赚到怀疑人生,还是被以“技术”为名的镰刀精准收割?事情的真相恐怕与大家想象的相去甚远。
靠人工智能预测股市,方法有哪些?
首先我们先来搞搞清楚,那些所谓的人工智能预测股市,到底都应用了哪些技术。
在AI大规模应用之前,利用大数据等数字工具,结合经验甚至周易的天干地支来预测股市行情,已经是高科技的代表了。但自从2016年AlphaGo击败李世石之后,机器学习技术就取代大数据成为预测股市的最强选手。
现在,市面上有许多证券公司推出了人工智能预测股市的工具、模型,甚至基金。接下来我们就追根溯源,来聊聊这些应用型产品都是依托那些机器学习算法/模型来工作的。
1.卷积神经网络
2016年,来自斯坦福大学计算机系的Ashwin Siripurapu发表了一篇文章,《Convolutional Networks for Stock Trading》,这是首次提出使用卷积神经网络来进行股票交易预测的方法。
该方法采用标普500etf分钟级数据作为历史数据(包括交易时间、每分钟收盘价、最高价、最低价、开盘价和交易量等),然后通过历史股价波动的图片,训练出了一个卷积神经网络模型,并试图通过这个模型来预测未来股价的运行。
最后验证的结果是,使用该模型预测股价还不如瞎猜。
2. 时间序列预测
尽管前文中的初级版卷积神经网络模型的实际预测效果不尽如人意,但其提出的利用时间序列建模的想法,就成为接下来机器预测股市的常用方式。
不过,ARIMA、SARIMA等模型都需要进行大量的数据预处理(比如K线图片识别等等)才能建立预测数据集,并且常常忽视股市波动的季节周期性差异。因此,Facebook设计和开发的时间序列预测库Prophet(先知)很快就被引入了训练之中。
研究人员试图让Prophet从过去的数据中捕捉趋势和季节性。但从试验效果来看,该模型并没有达到预期的效果。
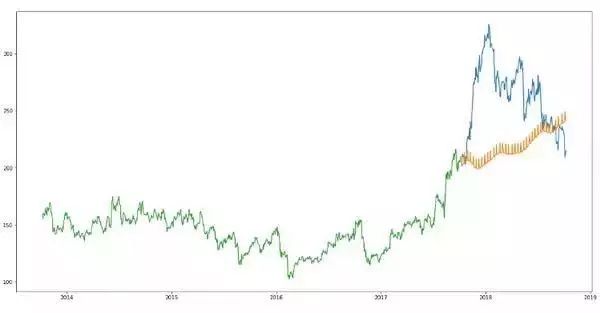
3.长短期记忆网络(LSTM)
单纯的时间序列并没有取得很好的效果,但如果机器能自己划重点呢?LSTM 算法在序列预测问题中的优秀表现,就引起了重视。主要是它们能够存储重要的既往信息,并且忽略那些不重要的信息。
从训练结果来看,LSTM模型可以对各种参数进行调优,在股市历史数据的预测匹配度上,表现果然超越了前面的所有算法。
但想通过LSTM 来预测股票价格的未来走势,不好意思它依然做不到。因为它只会认数据,看不懂那些很可能大幅度影响股价的新闻和非货币行为。
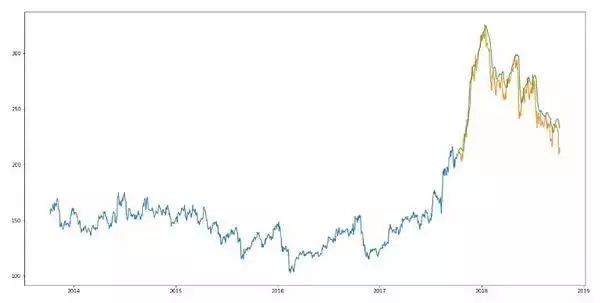
4.NLP特征提取
既然LSTM看不懂非数字的重要指征,那在此基础上让机器学会“认字”不就得了。
NLP技术能够对包括新闻、资讯、社交媒体等文字图片信息进行自动特征提取和情绪分析,有了这些数据,神经网络不就能分析基本面了吗?至此,一个简略版的机器学习股市预测模型就成型了。
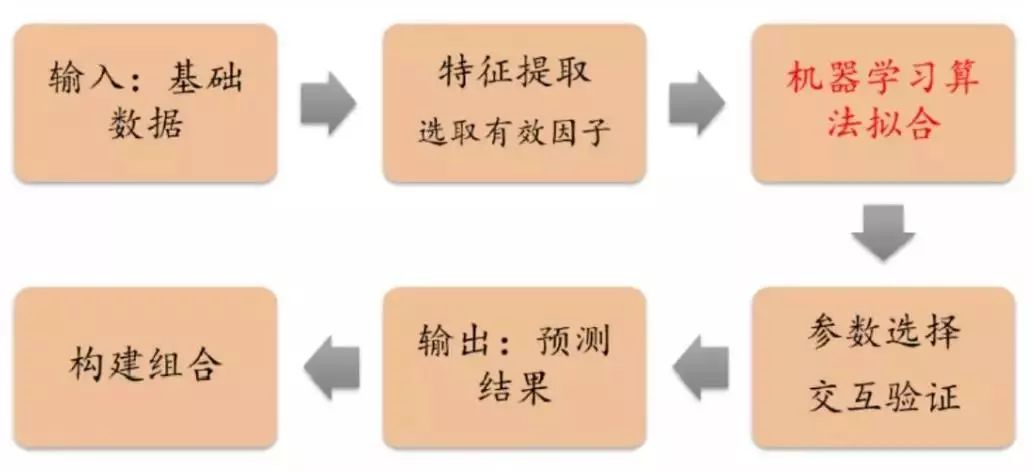
简单解释一下它的基础逻辑:输入股市的历史数据和实时结构化信息,特征提取选出那些有价值的信息,再通过深度神经网络训练出基本模型,通过预训练调整参数,这样就得到一个终极预测模型,可以一次来构建选股组合。当然,在实际的训练过程中可能还需要反复调参测试。
目前市面上用来选股的主流算法,比如随机森林、朴素贝叶斯、XGBoost、Stacking等,基本都是按照这一逻辑运行的。
具体效果怎么样呢?我们不妨用一个实际案例说明一下。
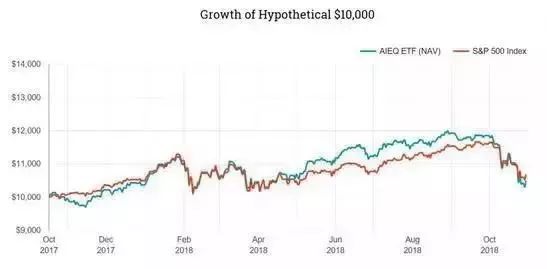
2017年,EquBot LLC、ETF Managers Group共同推出了全球第一只使用机器选股的基金AI Powered Equity ETF(AIEQ.US),这只基金不仅能够拥有认知和大数据处理能力,还能够阅读大量的文本线索,比如从年报、每日新闻中显露的经济形势、趋势以及公司重大事件等信息进行分析,然后挑选出相应的投资组合。
而它的表现,用“平平无奇”来说已经很善良了。短期投资“成功”跑输大盘(上市12日的表现比标普500指数低了3个点),至于长期价值投资嘛……价值投资还得靠机器,这水平基本也就告别股市了吧???
02
为什么人工智能预测股市,
总是遭遇滑铁卢?
不难看出,想要靠人工智能模型来预测股市,虽然理论上可行,但在实际操作过程中,模型们也并没有展现出比“玄学”强得多的技术。
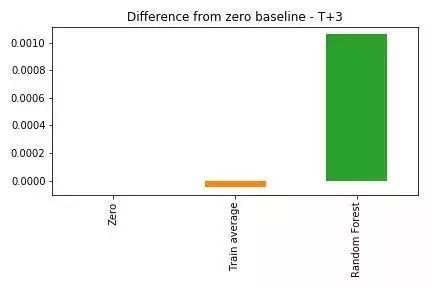
前不久,科学家Mario Filho就将这些预测模型一锅端了。他以这些模型为基础建立了一个数据集python version of TA-LIB,用以此训练了一个新的机器学习模型,并分别在一天和三天后检验了不同模型的预测效果。
实验结果显示,这些五花八门的AI预测模型,得到的效果也是随心所欲,有的居然还“消极罢工”了。
比如“随机森林”(The Random Forest)模型,其结果无论是和零预测还是平均值都相去甚远,这意味着,它虽然从数据中学到了一些东西,但在实际的验证过程中却完全没有体现出来。
目前看来,靠机器学习模型来预测股市,现实中基本不可能不亏钱。为什么无往而不利的AI遇上股市就束手无策了呢?主要有四个方面的阻碍:
一是历史数据更新不及时。机器学习的运算处理能力和信息深度都比个人强很多,这是不争的事实。但预测行为往往涉及一系列实时的动态因素,新闻事件、经济、政治、监管、自然灾害、个人心理等等,都会对最终的结果产生影响,在高波动的市场行情下,AI也很难准确预测。
二是自然语言理解技术的限制。理想情况下,好的深度学习模型是可以从社交媒体、财经新闻、金融信号(比如黄金、外汇等)的动态变化中寻找规律、把握情绪的。但现实情况是,这些数据往往是模糊的、非结构化的,在少量数据集的前提下训练出的模型自然也就无法得到很好的分析效果。
三是数据集的本土差别太大。即使数据集足够大,但不同的资本市场数据往往有着很强的个性化模式特征,并不存在一种“放之四海而皆准”的模型,可以在任何市场、任何时间段都表现出极高的性能。

因此想要依靠AI算法来提高收益,只能进行独立探索并找出某一模型最强优势并与本土特色相结合。这就导致了另一个问题,那就是研究资源不足。
大部分预测模型都是由个人开发者或者投资组织在研究和开发,很多在NLP、深度增强学习领域技术比较强的科技算法公司,研究重心还是放在通过AI预测改革更有民生价值的领域。
比如运用算法改进工厂发电效率、智能决策(DI)检测欺诈性交易等等,谷歌甚至在临床应用深度机器学习算法进行诊断和预测死亡时间。
相比这些多赢的业务,预测股价这类技术上不成熟、业务逻辑复杂、于民生又没有太大收益的应用场景,吸引不大足够的人才和资源去攻破,自然进步有限。
总而言之,股市本质上是零和博弈游戏,最终是依靠信息的不对称,从信息匮乏的一方身上赚钱。这种情况下,人工智能作为基础的技术工具,决定了只能是锦上添花。
散(韭)户(菜)们想要将抄底赚钱的希望放在各种似是而非的智能选股模型身上,怕是要失望到怀疑人生了。
既然选股不靠谱,
AI还能有点别的用吗?
既然依靠人工智能来预测股市目前还不可能,但并不代表那些荐股模型背后的技术没有用武之地。实际上,不少金融生活场景正在比股市更快地成为人工智能的“应许之地”。
比如借助金融类数据帮助实体商业项目进行风险控制。
传统模式下,银行在评估某些开发商项目时,仅仅针对开发商信用资质、还款能力等评估风险,却很难去考察项目所在区域的消费能力、经济活跃度及周边配套的发展情况,而后者才是影响项目的最大风险因子。
而借助阿里、京东、腾讯等超级平台每天产生的庞大数据,就会涉及商场、物流、理财、支付、信用等各类金融数据。在这些实时结构化数据的基础上,通过深度神经网络实现“经济体征”的全面量化,实时监测预警,就能根据具体区域经济、消费相关的发展变化,进行精准预测,避免“一叶障目”带来的资源风险。

另外,还有很多机构利用机器学习、LSTM等技术来训练模型以预防网络诈骗。
Sift Sciencee就从6000多家欺诈检测网站收集了大量数据,利用智能引擎关联了多源数据点,包括付款信息、交易频率、行为习惯等等,以此为基准采集和建立优质用户行为模型,对每笔交易进行比较和评估。
这样做的好处是,既避免了高风险控制带来的误判,防止请求失败造成用户流失,同时又能够有效地检测欺诈性交易。
上述应用更多是围绕多元结构化数据展开的,实际上,利用NLP和机器学习算法提供个性化的智能客服服务,在金融领域也越来越普及。
目前,中国的5大国有银行和12家全国性股份制商业银行已经全部上线智能客服。
而随着NLP技术的进步,智能客服也开始告别传统印象中的程式化服务,逐渐在情感分析、多轮对话等应用中发挥出不错的水平。
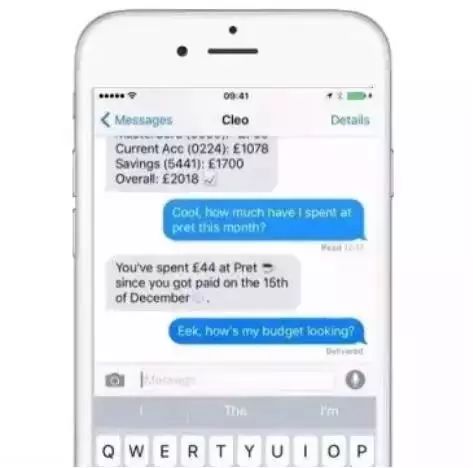
比如英国开发者设计的智能助手Cleo,在授予账户信息全线之后,就能够通过深度学习技术学习并适应用户的个人习惯与偏好。在对话的同时帮助用户进行理财指导和资金规划。
未来,使用AI来预测和解读市场与用户,将是金融公司的必备技能之一。不过对比机器学习在股市上的失利,以及其他场景中的可圈可点,或许我们可以得出一个基本结论:
每种机器学习算法的优缺点和应用表现各有不同,但总的来说,作为先锋技术,人工智能更应该被用在那些可用Availabl、可靠Reliable、可知Comprehensiblee、可控Controllable的地方(简称ARCC)。在这种共识之上,AI短时间内既不能让基金经理下岗,也无法帮散户们精准抄底。
或许是宿命的悖论吧:越清楚技术的能量有多大,就越无法理解人性的贪婪。

往期推荐

你们把AI吹上了天 但它却依然没4岁的小孩聪明

▲点击图片观看
惊了!谷歌建筑未来城市的六个疯狂细节
 ▲点击图片观看
▲点击图片观看 霍金“徒孙”朱珑

▲点击图片观看
- 加入社群吧 -
网易智能AI社群(AI芯片、医疗AI、金融AI、电商AI、自动驾驶、教育AI、AIoT、机器人等12个社群)火热招募中,对AI感兴趣的小伙伴,添加智能菌微信 kaiwu_club,说明身份即可加入。