推荐电子书:Apache Spark 2.x入门 - 从入门到制作
前言:
使用Apache Spark 2.0及更高版本,实现了很大的改进,使Spark更容易编程和执行更快:
- Spark SQL和Dataset / DataFrame API通过Spark SQL优化的执行引擎提供易用性,空间效率和性能提升。
- Spark ML提供了一套统一的高级API,构建于DataFrame之上,旨在使机器学习具有可扩展性和易用性。
您可以在电子书 Spark 2.x中了解有关使用Spark 2.x机器学习进行编程的更多信息:started-apache-spark-v2。

什么是机器学习?
机器学习使用算法来查找数据中的模式,然后使用识别这些模式的模型来对新数据进行预测。

机器学习通常分为两个阶段:
- 数据发现:第一阶段涉及对历史数据的分析,以构建和训练机器学习模型。
- 使用模型进行分析:第二阶段在新数据的生产中使用模型。
在生产中,需要在需要时使用新模型持续监控和更新模型。

通常,机器学习可以分为两种类型:监督,无监督,以及两者之间。监督学习算法使用标记数据; 无监督学习算法在未标记数据中找到模式。半监督学习使用标记和未标记数据的混合。强化学习训练算法以基于反馈最大化奖励。

机器学习三种常用技术
机器学习技术的三种常见类别是分类,聚类和协同过滤。

- 分类:Gmail使用称为分类的机器学习技术,根据电子邮件的数据指定电子邮件是否为垃圾邮件:发件人,收件人,主题和邮件正文。分类采用具有已知标签的一组数据,并学习如何基于该信息标记新记录。
- 群集:Google新闻使用一种称为群集的技术,根据标题和内容将新闻文章分组到不同的类别。聚类算法发现数据集合中出现的分组。
- 协作过滤:亚马逊使用称为协同过滤(通常称为推荐)的机器学习技术,根据用户的历史记录和与其他用户的相似性来确定用户会喜欢哪些产品。
监督学习:分类和回归
监督算法使用标记数据,其中输入和目标结果或标签都被提供给算法。

监督学习也称为预测建模或预测分析,因为您构建了一个能够进行预测的模型。
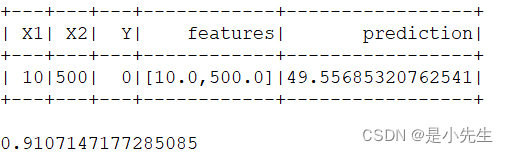
预测建模的一些示例是分类和回归。分类基于已知项目的标记示例(例如,已知为欺诈的交易或非欺诈)来识别项目属于哪个类别(例如,交易是否是欺诈欺诈)。逻辑回归预测概率(例如,欺诈的概率)。线性回归预测数值(例如,欺诈量)。

分类和回归示例
分类和回归采用具有已知标签和预定特征的一组数据,并学习如何基于该信息标记新记录。功能是你问的“如果问题”。标签是这些问题的答案。

回归示例
让我们来看一个汽车保险欺诈的例子:
- 我们想要预测什么?
- 这是标签:欺诈的数量
- 您可以使用哪些“问题”或属性进行预测?
- 这些是功能:要构建分类器模型,您需要提取最有助于分类的感兴趣的功能。
- 在这个简单的例子中,我们将使用索赔的金额。

线性回归模拟Y“标签”和X“特征”之间的关系,在这种情况下,欺诈量与索赔金额之间的关系。系数衡量特征,索赔金额和标签上的欺诈金额的影响。
多元线性回归模拟两个或多个“特征”与响应“标签”之间的关系。例如,如果我们想模拟欺诈数量与申请人年龄,索赔金额和事故严重程度之间的关系,多元线性回归函数将如下所示:
Yi = β0 + β1X1 + β2X2 + · · · + βp Xp + Ɛ
金额欺诈=拦截+(系数1 年龄)+(系数2 要求金额)+(系数3 *严重性)+错误。
系数衡量每个特征的欺诈数量的影响。
线性回归的一些例子包括:
- 鉴于历史汽车保险欺诈性索赔和索赔的特征,例如索赔人的年龄,索赔金额和事故严重程度,预测欺诈金额。
- 鉴于历史房地产销售价格和房屋特征(平方英尺,卧室数量,位置等),预测房屋的价格。
- 根据历史街区犯罪统计数据,预测犯罪率。
分类示例
让我们来看一个借记卡欺诈的例子:
- 我们想要预测什么?
- 这是标签:欺诈的可能性
- 您可以使用什么“如果问题”或属性进行预测?
- 今天花费的金额是>历史平均值吗?
- 今天在多个国家都有交易吗?
- 今天的交易数量>历史平均值?
- 今天新商家类型的数量是否与过去3个月相比较高?
- 今天是否有来自具有风险类别代码的商家的多次购买?
- 与历史上使用pin相比,今天是否有不寻常的签约活动?
- 与过去3个月相比,是否有新的州购买?
- 与过去3个月相比,今天是否有外国购买?
要构建分类器模型,您需要提取最有助于分类的感兴趣的特征。

逻辑回归通过使用逻辑函数估计概率来测量Y“标签”和X“特征”之间的关系。该模型预测概率,用于预测标签类。
一些分类示例包括:
- 鉴于历史汽车保险欺诈性索赔和索赔的特征,例如索赔人的年龄,索赔金额和事故的严重程度,预测欺诈的可能性。
- 根据患者特征,预测充血性心力衰竭的可能性。
- 信用卡欺诈检测(欺诈,而非欺诈)
- 信用卡申请(信誉良好,信用不良)
- 垃圾邮件检测(垃圾邮件,而不是垃
- 文本情绪分析(快乐,不开心)
- 预测患者风险(高风险患者,低风险患者)
- 肿瘤分类(恶性,非恶性)
Spark监督算法总结
分类
- 逻辑回归
- 决策树分类器
- 随机森林分类器
- 梯度提升树分类器
- 多层感知器分类器
- 线性支持向量机
- 朴素贝叶斯
回归
- 线性回归
- 广义线性回归
- 决策树回归
- 随机森林回归
- 梯度提升树回归
- 生存回归
- 等渗回归
无监督学习
无监督学习(有时也称为描述性分析)没有提前提供标记数据。这些算法发现输入数据中的相似性或规律性。无监督学习的一个例子是根据购买数据对类似客户进行分组。

聚类
在聚类中,算法通过分析输入示例之间的相似性将输入分类。一些集群用例包括:
- 搜索结果分组
- 对类似客户进行分组
- 对类似患者进行分组
- 文本分类
- 网络安全异常检测(异常发现不相似的东西,这意味着来自群集的异常值)

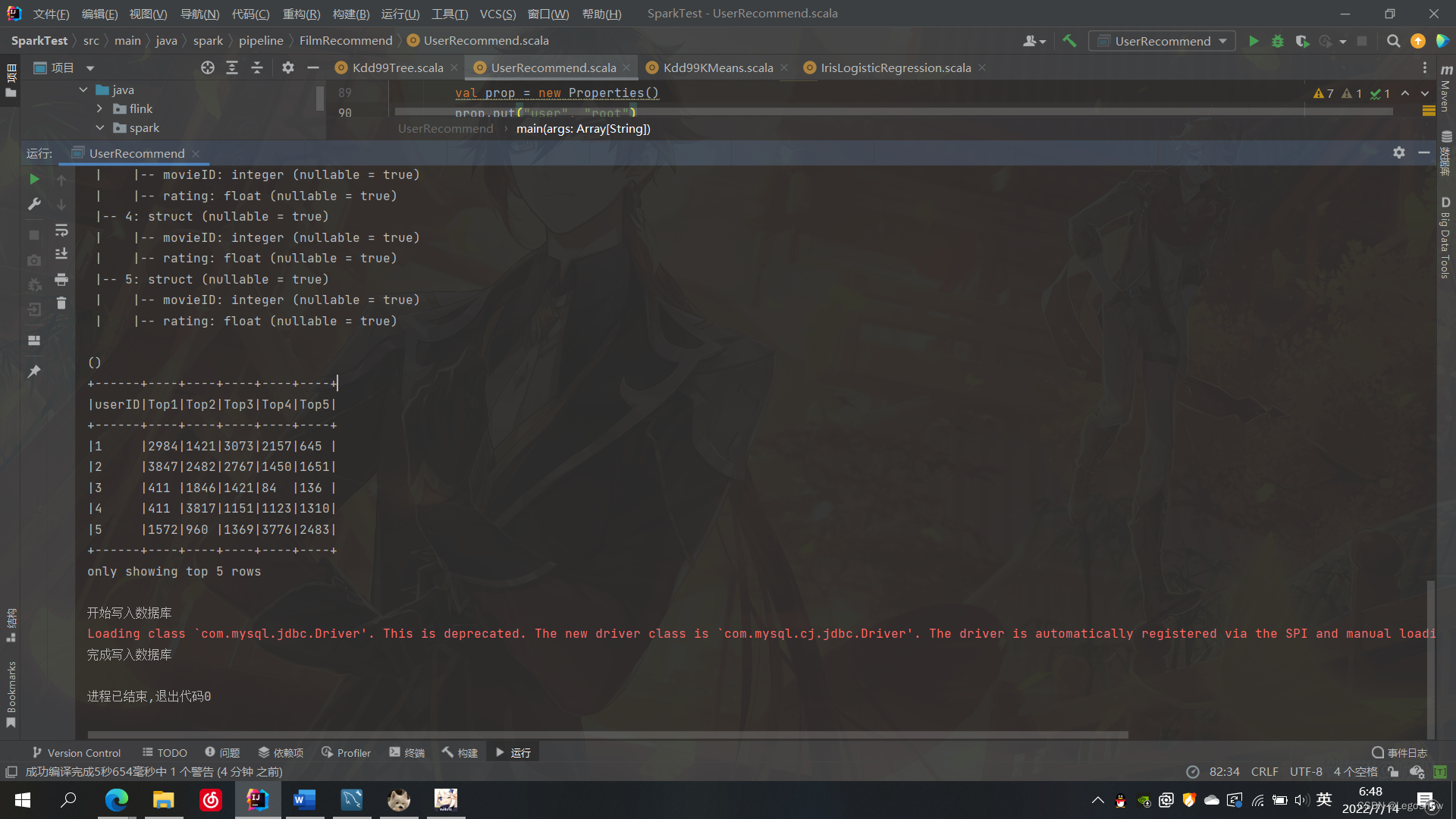
所述ķ -means算法组观测到ķ其中每个观测属于具有从它的聚类中心的最近均值群集的群集。

集群的一个例子是希望对其客户进行细分以便更好地定制产品和产品的公司。客户可以按人口统计和购买历史等功能进行分组。无监督学习的聚类通常与监督学习相结合,以获得更有价值的结果。例如,在该银行客户360用例中,首先根据调查的答案对客户进行聚类。分析客户组,然后标记客户角色。接下来,角色标签通过客户ID与客户功能(例如帐户类型和购买)链接。最后,有监督的机器学习被应用并与标记的客户一起测试,允许它将调查客户角色与他们的银行行为联系起来并提供见解。

频繁模式挖掘,关联,共同发生,市场篮子建议
频繁模式或关联规则挖掘发现项目集合中的频繁共现关联,例如通常一起购买的产品。关于关联规则挖掘的着名故事是“啤酒和尿布”的故事。对杂货店购物者行为的分析发现,购买尿布的男性也经常购买啤酒。

沃尔玛开采了他们庞大的零售交易数据库,以了解他们的客户在飓风到来之前真正想要购买的东西。他们发现一个特定项目的销售额比正常购物天数增加了7倍,这对于现实世界的案例来说是一个巨大的提升因素。这个项目不是瓶装水,电池,啤酒,手电筒,发电机,或者你可能想象的任何常见的东西:它是草莓挞!

另一个例子来自Target,它分析了当女性开始购买无香味的乳液,维生素补充剂和其他一些物品的组合时,它表明她可能怀孕了。不幸的是,Target向一名青少年发送了婴儿用品的优惠券,其父亲质疑她收到此类优惠券的原因。

共现分析对于:
- 商店布局
- 确定哪些产品可以加入特价商品,促销活动,优惠券等。
- 确定医疗保健患者,就像我的同伙一样
协同过滤
协同过滤算法基于来自许多用户的偏好信息(这是协作部分)推荐项目(这是过滤部分)。协同过滤方法基于相似性; 过去喜欢类似商品的人将来会喜欢类似的商品。协作过滤算法的目标是从用户获取偏好数据并创建可用于推荐或预测的模型。Ted喜欢电影A,B和C. Carol喜欢电影B和C.我们将这些数据用于运行算法来构建模型。然后,当我们有新数据时,例如Bob喜欢电影B,我们使用该模型来预测C是Bob的可能推荐。

Spark无监督算法总结
聚类
- k -means
- 潜在Dirichlet分配(LDA)
- 高斯混合模型(GMM)
协同过滤
- 交替最小二乘法(ALS)
频繁模式挖掘
- FP增长算法
深度学习
深度学习是多层神经网络的名称,多层神经网络是由输入和输出之间的几个节点“隐藏层”组成的网络。神经网络有很多变种,你可以在这个神经网络备忘单上学到更多。 改进的算法,GPU和大规模并行处理(MPP)已经产生了具有数千层的网络。每个节点获取输入数据和权重,并将置信度分数输出到下一层中的节点,直到到达输出层,其中计算得分的误差。

在称为梯度下降的过程内部进行反向传播时,错误将再次通过网络发回,并调整权重,从而改进模型。该过程重复数千次,调整模型的权重以响应其产生的错误,直到错误不再减少为止。

在此过程中,层学习模型的最佳特征,其优点是不需要预先确定特征。但是,这样做的缺点是模型的决策无法解释。因为解释决策很重要,研究人员正在开发新方法来理解深度学习的黑盒子。
深度学习算法有不同的变体,可以与MapR的分布式深度学习快速入门解决方案一起使用,以构建数据驱动的应用程序,如下所示:
- 深度神经网络改进传统算法
- 财务:通过识别更复杂的模式来增强欺诈检测
- 制造:基于更深的异常检测,增强缺陷识别
- 用于图像的卷积神经网络
- 零售:用于衡量流量的视频的店内活动分析
- 卫星图像:标记地形,分类对象
- 汽车:识别道路和障碍物
- 医疗保健:X射线,扫描等诊断机会
- 保险:根据照片估算索赔严重程度
- 用于测序数据的递归神经网络
- 客户满意度:将语音数据转换为文本以进行NLP分析
- 社交媒体:社交和产品论坛帖子的实时翻译
- 照片字幕:搜索图像档案以获得新的见解
- 财务:通过时间序列分析预测行为(也是增强的推荐系统)
用Spark深度学习
可以与Spark一起使用的深度学习库或框架包括:
- BigDL
- Spark Deep Learning Pipelines
- TensorFlowOnSpark
- dist-keras
- H2O Sparkling Water
- PyTorch
- Caffe
- MXNet
使用SPARK ML
使用Apache Spark 2.0及更高版本,实现了很大的改进,使Spark更容易编程和执行更快:
- Spark SQL和Dataset / DataFrame API提供易用性,空间效率和性能提升。
- Spark ML提供了一套统一的高级API,构建于DataFrame之上,旨在使机器学习具有可扩展性和易用性。在DataFrames之上构建ML API可以提供分区数据处理的可扩展性,并且易于使用SQL进行数据操作。

您可以使用Spark ML Pipeline通过变换器传递数据以提取特征,生成模型的估算器和评估模型的评估器。

在MapR电子书入门第2-9章Spark 2.x入门:从初始到制作,您可以浏览一些Spark机器学习示例并下载相应的代码。
原文地址:https://mapr.com/blog/apache-spark-machine-learning-tutorial/