2020/07/09 -
引言
《Learning Spark》过程中只是简单介绍了mllib中的东西,没有一个完整的实践过程,暂时还没有去找有没有专门做这种的书,好像我看《spark in action》是有这部分内容,后续在看。本篇文章就利用这个鸢尾花的数据集来简单说明一下spark机器学习的过程,只是简单打下一个轮廓,然后记录使用过程中遇到的问题以及解决方案。
在本文中,主要使用新版面向DataFrame的机器学习接口ml,有时候也会涉及老版借口mllib。
简单总结
这部分代码不算麻烦,但是主要存在一下几个问题。
- 没有看到交叉验证的东西,数据集的划分也是自己来划分的(是不是有接口?)
- 中间提到了LabeledPoint在ml中没有找到,是不是说有更好的处理办法,就是面向df的方式
- spark的算法没有办法处理字符串性质的东西?如果是某个特征是字符串,那我转换成向量,里面是数值的,这样不就他会使用回归的方式来使用数据吗?
- 注意,这里的整个流程都是我自己来弄的, 最开始是参考文章[1],然后适配了自己的场景;但是可以看出,他最后使用的评估方式是spark自带的,我当时使用了一下,感觉有点费劲,就采用了sklearn的方式。
主要流程
列举一下机器学习的主要流程,这个算是老生长谈了,对于无需解释的部分,直接就在这里插入代码了。
- 加载数据,使用DataFrame的方式
这里数据已经被加载到了hdfs的相应路径
iris_data = spark.read.options(inferschema='true').csv("/VChao/mllib_test/iris.data")
iris_data.printSchema()- 预处理
这里的预处理不是针对数据内容的预处理,将数据格式转化为spark能够处理的。 - 选择算法
这里算法选择随机森林。 - 学习过程,性能评估
这部分的接口跟sklearn这种还不太一样,需要稍微调整。
预处理部分
(这里按照书《Learning Spark》上的说法,输入的变量应该是LabeledPoint形式,但是我看ml中没有这个东西,我才是不是他改变了一些处理方式,这里先不管,还是使用之前的方式)
预处理部分需要将DataFrame格式的数据转化为vector形式,首先要处理的就是,数据的类别是字符串,但LabeledPoint的label必须是浮点型,所以只能进行转换,其实,我感觉是不是这里不太对啊,按说机器学习的算法应该支持这种形式,还是说,sklearn只是帮我把这个工作给做了。
from pyspark.ml.feature import StringIndexerclass_label = StringIndexer(inputCol="_c4", outputCol="class")
index_model = class_label.fit(iris_data)
iris_data = index_model.transform(iris_data)
iris_data = iris_data.drop("_c4").cache()此时的iris_data其中的类别已经是浮点类型的数据了,可以后续转化为LabelPointed形式。
转化为LabeledPoint
from pyspark.mllib.regression import LabeledPoint
from pyspark.mllib.linalg import Vectorsdata = iris_data.rdd.map(lambda row: LabeledPoint(row[-1], Vectors.dense(row[:-1])))切分数据
train_ratio = 0.8
splits =[train_ratio, 1 - train_ratio]
train_data,test_data = data.randomSplit(splits)
选择算法并训练
from pyspark.mllib.tree import RandomForest
rf_model =RandomForest.trainClassifier(train_data,numClasses=3,numTrees=10, \categoricalFeaturesInfo={},featureSubsetStrategy='auto',impurity="gini")从这里可以看出,直接就是一个训练过程,是不是我没有选对?
测试数据
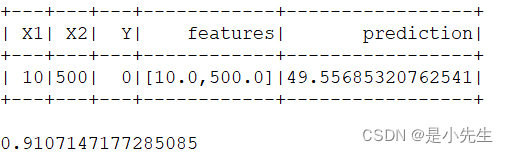
predictions = rf_model.predict(test_data.map(lambda x:x.features))import numpy as np
pre = predictions.collect()
np_pre = np.array(pre)
labels = test_data.map(lambda x:x.label).collect()
np_labels = np.array(labels)利用sklearn来显示性能
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_reportprint confusion_matrix(np_labels, np_pre)
print classification_report(np_labels, np_pre,target_names=index_model.labels)整体代码已经上传至githubspark-machine-learning
参考文章
Spark实战:基于Spark的随机森林分类算法分析
相关文章
spark机器学习笔记:(一)Spark Python初探
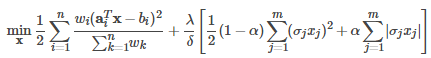
Spark Machine Learning(SparkML):机器学习(部分三)

spark机器学习算法研究

手把手带你玩转Spark机器学习-使用Spark进行数据处理和数据转换

手把手带你玩转Spark机器学习-使用Spark构建分类模型

手把手带你玩转Spark机器学习-Spark的安装及使用

手把手带你玩转Spark机器学习-深度学习在Spark上的应用

Spark Machine Learning(SparkML):机器学习(部分一)
手把手带你玩转Spark机器学习-使用Spark构建聚类模型
Spark机器学习解析

Spark大数据处理系列之Machine Learning
大数据笔记--Spark机器学习(第一篇)

iis 重启 (三种方法)

IIS中应用程序池自动停止,重启报错
服务器上系统怎么启动iis,IIS服务器如何重新启动

解决:IIS 假死,运行一段时间服务器上所有网站打不开,必须要重启服务器才行,重启IIS都没用。怎么解决,解决方案

iis服务器 关闭自动启动,设置IIS服务器定时自动重启的方法
C#实现对IIS网站和应用程序池实时监测(网站停止后自动重启)

bat脚本重启IIS中的网站
