这篇文章从对聚类的感性认识到聚类算法的实现:
k个初始中心点的选择,中心点的迭代,直到算法收敛得到聚类结果。
但有几个问题需要回答:
如何判断数据是否适合聚类?
k类是如何确定的?
遇到数据集小的时候,如何得到直观的聚类图?
遇到非凸集数据,聚类要如何实现?
//
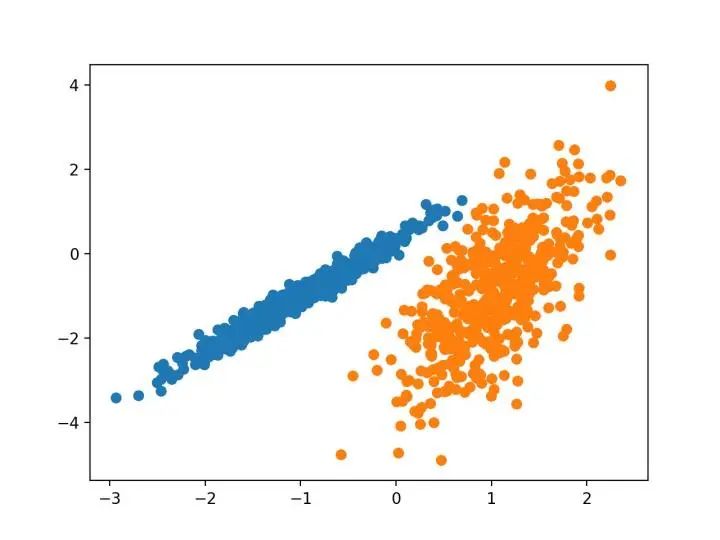
先看一幅以R语言绘制的图,适合聚类吗?
//
> library(fMultivar)
> set.seed(1234)
> df<-rnorm2d(1000,rho=.5)
> df<-as.data.frame(df)
> plot(df,main="bivariable normal distribution with rho=0.5")
显然,这幅图中的数据不适合聚类!因为数据是从相关系数为0.5的正态分布中抽取了1000个观测值!
//
如果采用中心点的聚类方法PAM,那么情况是否一致???
//
> library(cluster)
> library(ggplot2)
> fit<-pam(df,k=2)
> df$clustering<-factor(fit$clustering)
> ggplot(data=df,aes(x=V1,y=V2,color=clustering,shape=clustering))+geom_point()+ggtitle("clustering of Bivariate normal data")
> plot(nc$All.index[,4],type="o",ylab="CCC",xlab="number of clusters",col="blue")
通过对正态分布数据作基于中心点的聚类,我们发现出现了单峰分布,这表明数据是人为划分的,而不是”真实意义的类“。
事实上,聚类方法是无监督方法,到底靠不靠谱还是得看是否符合常识,现在又增加了一个方法: 如果多种方法都倾向于相似的聚类,那么聚类结果会更加稳健!
//
k值是如何确定的了?
//
> wssplot<-function(data,nc=15,seed=1234){
+ wss<-(nrow(data)-1)*sum(apply(data,2,var))
+ for (i in 2:nc){
+ set.seed(seed)
+ wss[i]<-sum(kmeans(data,centers=i)$withinss)}
+ plot(1:nc,wss,type="b",xlab="number of clusters",ylab="within groups sum of squares")}
> wssplot(df)
> library("NbClust")
> nc<-NbClust(df,min.nc=2,max.nc = 15,method="kmeans")wssplot()推荐聚类个数选择2,或3较为合适!3之后,斜率下降越来越平缓,意味着继续增加类别,并不能带来多大的提升!
NbClust()推荐聚类个数为2,或3;意味着26个评价指标中,其中8项倾向选择2,5项选择3类!
//
如何选出最佳聚类个数的?
//
包中定义了几十个评估指标,聚类数目从2~15(自己设定),然后遍历聚类数目,通过看这些评估指标在多少聚类个数时达到最优。
基于五种营养标准的27类鱼、禽、肉的相同点和不同点是什么?是否有一种方法能把这些食物分成若干个有意义的类?
> data(nutrient,package="flexclust") #加载数据
> row.names(nutrient)<-tolower(row.names(nutrient))#将行名改为小写
> nutrient.sacled<-scale(nutrient) #标准化处理
> d<-dist(nutrient.sacled) #计算欧几里得距离
> fit.average<-hclust(d,method="average")#采用平均联动法进行聚类
> plot(fit.average,hang=-1,cex=.8,main="average linkage clustering")#绘制最后的聚类图对于数据量较小时,聚类图可以很好展示类之间的界限!
解读聚类图:从下向上看;最开始所有的观测值都是一类,两两合并,最终成为一类
//
k-means聚类的缺点及改进
//
均值的使用意味着所有的变量必须是连续的,并且这个方法很有可能被异常值影响(所以有了k-medoids和k-medians)。
k-medoids基于中位数进行聚类,虽然可以排除异常值影响,但找中心点需要排序,所以计算速度很慢!
它在非凸聚类(例如U型)情况下也会变得很差(所以有了kernel k-means)。
数据集大时容易出现局部最优,需要预先选定k个中心点,对K个中心点选择敏感(所以有了k-means++ )
因为要算均值,所以只限于数值型数据;不适用categorical类型数据(分类型数据,比如男,女;商品类型;后来有了k-modes)
//
其它的聚类方法
//
PAM,围绕中心点的划分(PAM),在异常值上表现的很稳健;
K均值聚类一般选择欧几里得距离,要求数据类型是数值型且是连续变量;而PAM可以使用任意的距离计算;可以容纳混合数据类型,不仅限于连续变量;
与k-means一样,PAM也需要提前确定k类
中心点是动态变化的:通过计算中心点到每个观测值之间的距离的总和最小来选择中心点;直到最后中心点不再变化;
//
层次划分聚类
//
层次划分聚类最大的优点:可解释性好,能产生高质量的类(小而美),
缺点:时间复杂度高,不能跑大型数据集(改进的算法有BIRCH,数据类型是numerical);在某种意义上分层算法是贪婪的,一旦一个观测值被分配给一个类,它就不能在后面的过 程中被重新分配;容错机制弱,一步错步步错;
k-means中的观测值不会永远被分配到一类中。
//
Mean-Shift聚类
//
Mean shift算法,又称均值漂移算法,这是一种基于核密度估计的爬山算法,可用于聚类、图像分割、跟踪等。它的工作原理基于质心,这意味着它的目标是定位每个簇/类的质心,即先算出当前点的偏移均值,将该点移动到此偏移均值,然后以此为新的起始点,继续移动,直到满足最终的条件(找出最密集的区域)。
优点:不需要提前确定k类
这里还有更多的问题:
相似性/相异性的度量:数据本身的相似性,或特征的相似性。度量方法:距离,余弦距离等
聚类算法如何选择:根据数据特点和想要的聚类个数作选择。
数据如何作处理:离散傅里叶变换可以提取数据的频域信息,离散小波变换除了频域之外,还可以提取到时域信息。
降维,比如常见的PCA与SVD作为线性方法,受到广泛的应用,还有基于非线性的方法比如流形学习等。降维与聚类算法结合最好的莫过是谱聚类(先将数据转换成邻接矩阵,再转换成Laplacian矩阵,再对Laplacian矩阵进行特征分解,把最小的K个特征向量排列在一起作为特征,然后适用k-means聚类)。
End.
作者:求知鸟
来源:知乎