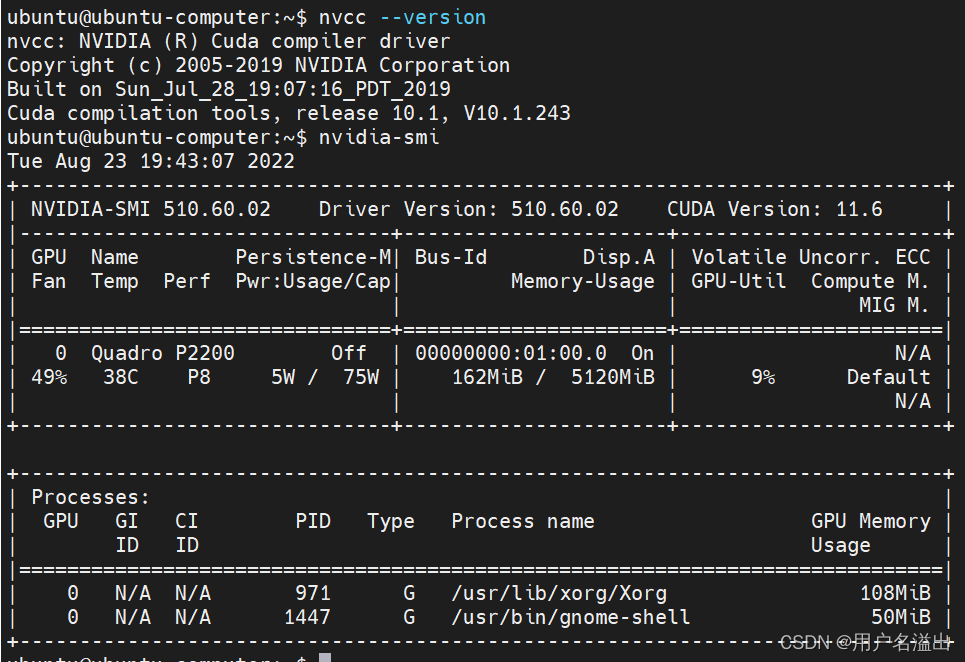
原环境:Windows 10, gpu 3090, TF 1.15,cuda_10.0.130_411.31_win10,cuDNN 7.6.5.32
mask-rcnn框架,运行train.py报错信息如下:

image_id 333
image_id 32
image_id 58
2022-01-01 19:03:07.415032: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cublas64_100.dll
2022-01-01 19:03:07.940270: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudnn64_7.dll
2022-01-01 19:03:10.735250: W tensorflow/stream_executor/cuda/redzone_allocator.cc:312] Internal: Invoking ptxas not supported on Windows
Relying on driver to perform ptx compilation. This message will be only logged once.
2022-01-01 19:03:11.407229: E tensorflow/core/kernels/gpu_utils.cc:81] Detected cudnn out-of-bounds write in convolution buffer! This is likely a cudnn bug. We will skip this algorithm in the future, but your GPU state may already be corrupted, leading to incorrect results. Within Google, no action is needed on your part. Outside of Google, please ensure you're running the latest version of cudnn. If that doesn't fix the problem, please file a bug with this full error message and we'll contact nvidia.
2022-01-01 19:03:11.407917: E tensorflow/core/kernels/gpu_utils.cc:89] Redzone mismatch in RHS redzone of buffer 0x23a0b14e00 at offset 2074880; expected ffffffffffffffff but was c36a9040c1c7adfd.
2022-01-01 19:03:13.088660: E tensorflow/stream_executor/cuda/cuda_blas.cc:428] failed to run cuBLAS routine: CUBLAS_STATUS_EXECUTION_FAILED
2022-01-01 19:03:13.092186: I tensorflow/stream_executor/stream.cc:4925] [stream=0000020D32A8C060,impl=0000020D483DE380] did not memcpy device-to-host; source: 000000287B820400
2022-01-01 19:03:13.092398: I tensorflow/stream_executor/stream.cc:4963] [stream=0000020D32A8C060,impl=0000020D483DE380] did not memzero GPU location; source: 000000B14A13DED8
2022-01-01 19:03:13.093517: I tensorflow/stream_executor/stream.cc:316] did not allocate timer: 000000B14A13DE80
2022-01-01 19:03:13.092790: I tensorflow/stream_executor/stream.cc:5418] [stream=0000020D32A8C060,impl=0000020D483DE380] Internal: stream did not block host until done; was already in an error state
2022-01-01 19:03:13.093984: I tensorflow/stream_executor/stream.cc:1964] [stream=0000020D32A8C060,impl=0000020D483DE380] did not enqueue 'start timer': 000000B14A13DE80
2022-01-01 19:03:13.094764: W tensorflow/core/kernels/gpu_utils.cc:65] Failed to check cudnn convolutions for out-of-bounds reads and writes with an error message: 'stream did not block host until done; was already in an error state'; skipping this check. This only means that we won't check cudnn for out-of-bounds reads and writes. This message will only be printed once.
2022-01-01 19:03:13.095431: I tensorflow/stream_executor/stream.cc:1976] [stream=0000020D32A8C060,impl=0000020D483DE380] did not enqueue 'stop timer': 000000B14A13DE80
2022-01-01 19:03:13.097421: F tensorflow/stream_executor/gpu/gpu_timer.cc:65] Check failed: start_event_ != nullptr && stop_event_ != nullptr Process finished with exit code -1073740791 (0xC0000409)
解决方法:
TF 1.12.0/CUDA 9.0/cuDNN 7.3.1.20
Invoking ptxas not supported on Windows · Issue #7640 · tensorflow/models · GitHub