弗林分类法
根据弗林分类法,计算机结构主要分为
- SIMD----单指令、多数据
- MIMD---多指令、多数据
- SISD----单指令、单数据
- MISD---多指令、单数据
一般的串行程序中为SISD,即在单核CPU下任何时间和地点只有一个指令处理一个数据,其所谓的多线程实际上是采用时分方法,以使人感觉是在同时运行
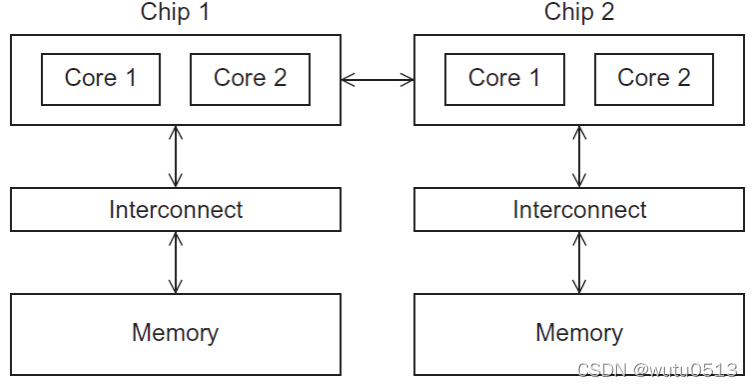
而现在大多数多核计算机一般为MIMD,操作系统复杂多线程或进程的调度,将线程或进程分布在不同的CPU上,每个线程都具有独立的指令和数据
SIMD是对SISD提出的一个改进,虽然只有一个指令但是能够一次性处理多个数据,典型代表Arm的Neon指令集,X86 SSE指令集,在硬件能够批量处理数据
MISD比较少见,与MIMD相比,性价比并不高、
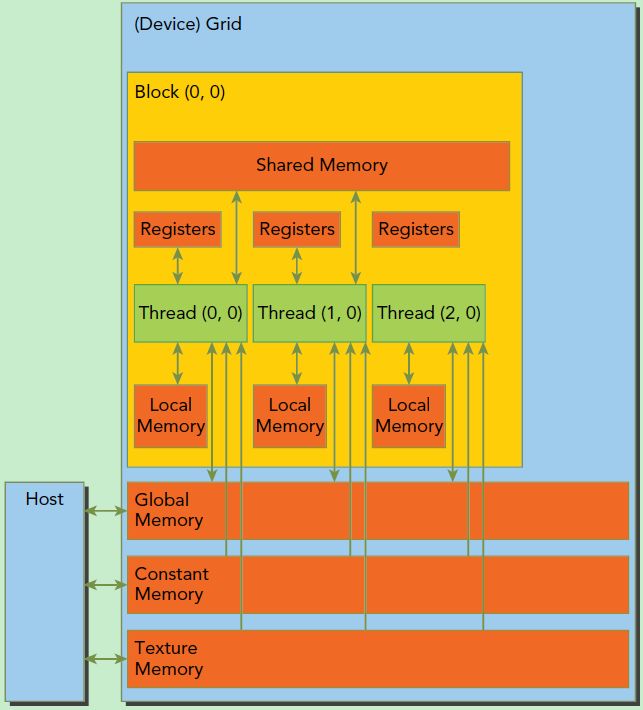
与上述应对的,英伟达在GPU的实现被称为SIMT(single Instruction Mutiple Thread)单指令多线程,与CPU相比每个线程的指令(相当于kernel)不是固定的,是由开发人员编写kernel制定时间工程内容。
并行计算
并行计算是相对与串行程序来讲,能够同时处理多个任务,提高计算效率,比如:
设 有数组A 和 数组 B,数组中A的每个元素乘以数组B的每个元素,串行程序的编写思路:
for (int index = 0; index < ArraySize; index++)
{Result[inxex] = A[index] * B[index];
}假设A和B的数组非常的大,超过了千万次 甚至亿次,即使只是两个元素相乘,计算时间也非常耗时,为了提高计算效率,使用线程增加实际的并行数:
Task 1:for (int index = 0; index < ArraySize/2; index++)
{Result[inxex] = A[index] * B[index];
}Task 2:for (int index = ArraySize/2; index < ArraySize; index++)
{Result[inxex] = A[index] * B[index];
}计算效率比之前提高了越一半,继续增加并行处理能力:
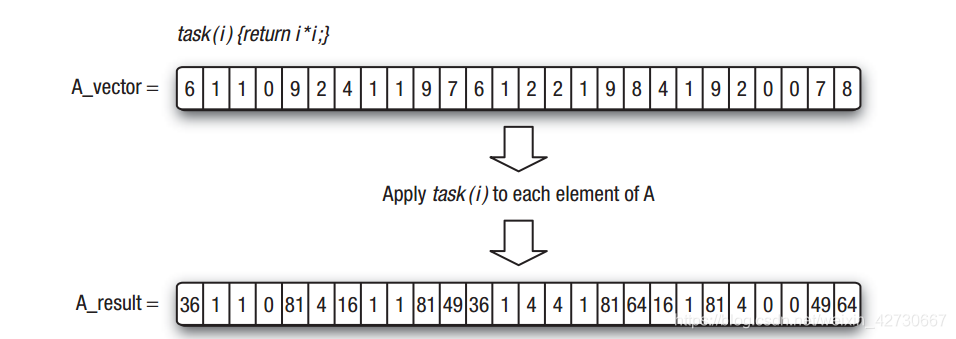
当增加到实际并行处理能力 和数组大小一样,那每个任务的实际处理指令仅为
Result[inxex] = A[index] * B[index];其效率相比之前有了根本性的提高。
所谓并行计算就是将串行中的指令或数据进行分解使之能够同时处理更多的数据,以此来减少串行单个计算问题所需要的实际。实际上能够并行处理的数目与使用的硬件有关,比如CPU或者GPU的core数目。GPU的硬件整个设计理念都是与并行计算密不可分的,通过增加硬件核数来增加并行能力,以此来提高效率。
并发性
并发性的核心即内涵,对于一个特定的问题,无需考虑用哪种并行计算来求解,而只需关注求解方法中哪些操作是可以并行的,以及数据之间的相关性进行解耦
数据的易并行即将每一个输出数据都表示成其其他数据或者步骤无关即数据之间没有太多的关联性,这是并发执行的核心,再常见的操作中,比如矩阵乘法,其每个矩阵的元素的输出结果与其他元素的输出结果无关,没有相关性,所有在进行并行计算中 矩阵的相关操作很容易实现并行计算。
在有些算法中可能有一个阶段不是“易并行”吗,但某一步或某几步还是能够用实现并行计算,也是有很大框架,那么该算法的最大瓶颈就是串行执行部分。
并行处理的类型
常见的并行处理的类型主要有两种基于任务或基于数据。
基于任务的并行处理
所谓任务的并行处理,有一种前提各个进程不同、无关的,如下图所示:
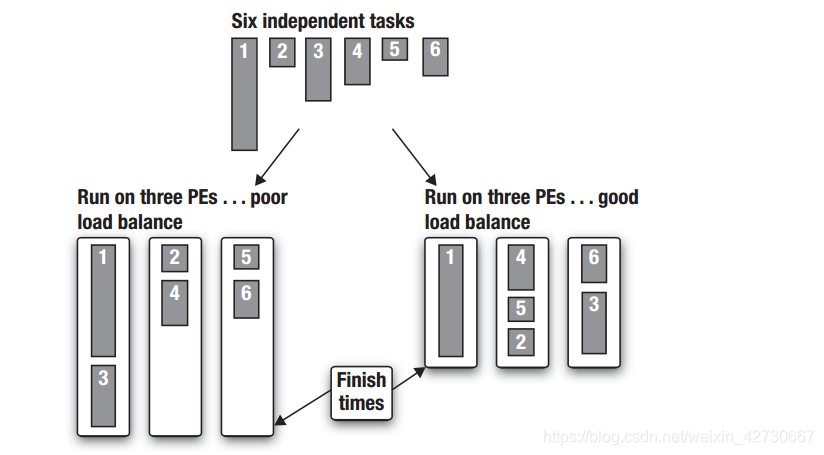
有6个任务,任务之前的相互之间是独立的,没有关联,在单核处理器中一般都需要按照顺序依次进行,其运行的总时间为6个任务的总时间。而在一个3核CPU中,可以通过将不同的任务分布到不同的CPU中以提高程序效率。在分配方法一中,分别将1和3、2和4以及5和6上分布到三个核上吗,此时耗时取决于执行时间最长的CPU即1和3 分布的任务。对该方案进一步改进,将4和5以及2三个执行时间比较短的任务分布在一个CPU上, 任务1单独分布在一个CPU上,这样总体时间相对来说进一步减小。
任务并行的最大难处,需要开发人员根据实际需求进行手工调整,其运行时间取决于耗时最长的CPU。
但是在实际开发过程中,上述任务直接相互独立这种理想场景很难见到,一般任务直接都会涉及到交互,最坏的一种情况是本任务的输入都依赖于上一个任务的输出,例如:
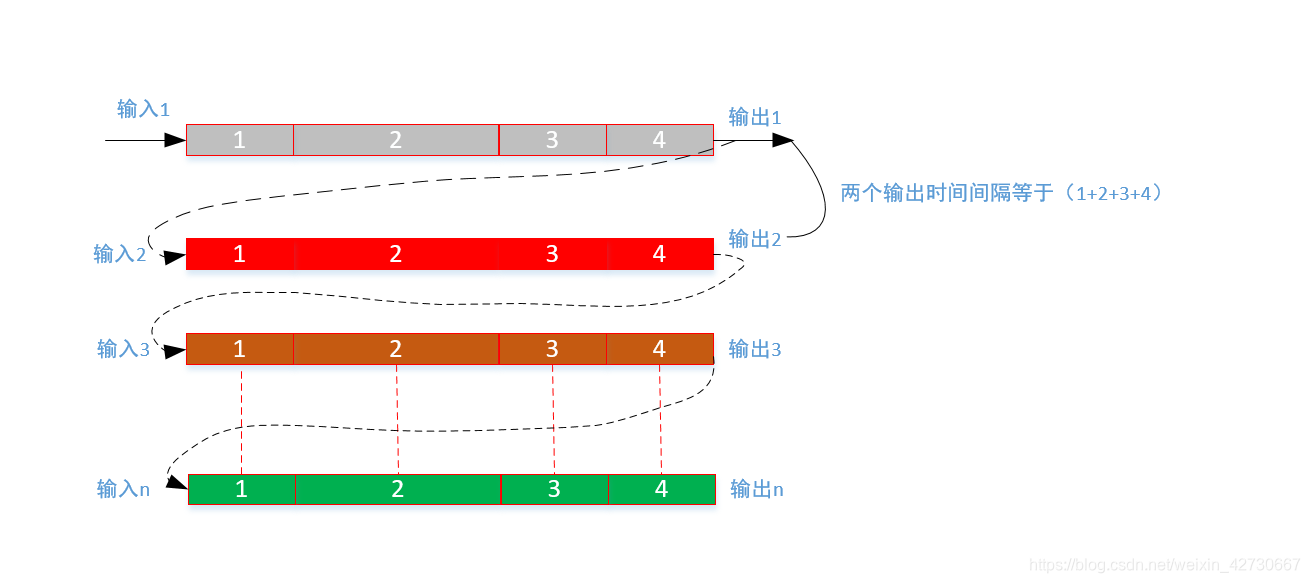
有1、2、3和4共四个任务,每个任务的输出都依赖于前面的输入,整个任务的处理完全是一个串行程序,上述场景在我们实际的开发中经常遇到,在实际开发中经常根据整个业务流程处理,将其切割成不同的模块来进行处理,模块之前的输入和输出相互存在依赖关心,整个业务流程完全处理完成需要的时间非常长,两个输出的间隔时间为(1+2+3+4).处理完整个业务流程过程中,任务1处理完成之后交给任务2,任务2处理完成交给任务3... 如此以来任务1在处理完成之后到接收到下一个任务数据输入时,其等待时间为2、3、4的总和时间这段时间完全处于忙等待时间,极大浪费的CPU等硬件资源。
为了解决串行任务中的并行问题,以及提高整个资源的使用率,采用流水线并行处理(pipeline parallelism)技术,在1处理完成之后,将数据交接给任务2时,任务1继续接收下一个数据,以此类推构成一个流水线形式,如下图 :
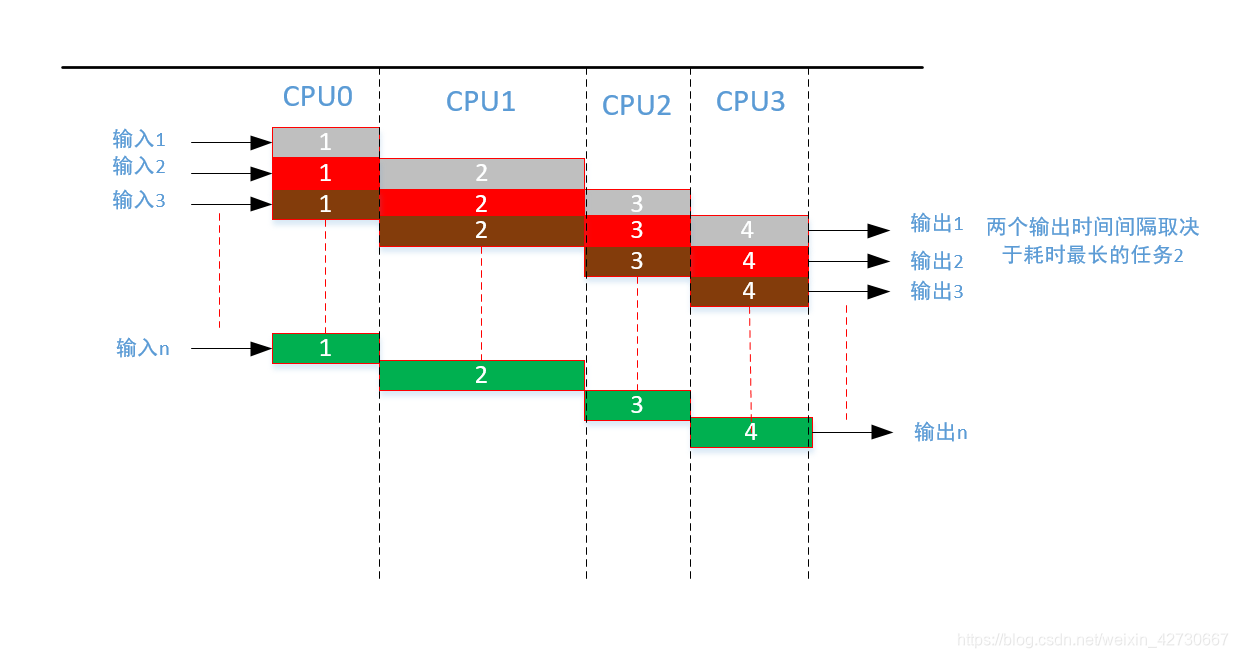
经过并行流水线改进之后,两个输出的时间间隔为流水线中耗时任务最长的任务2 ,相比于之前的效率有了很大的提高。经过流水线的改造之后,其短板取决于耗时最长的任务,那么对最长的任务继续进行分解,增加整个流水线的长度如下:
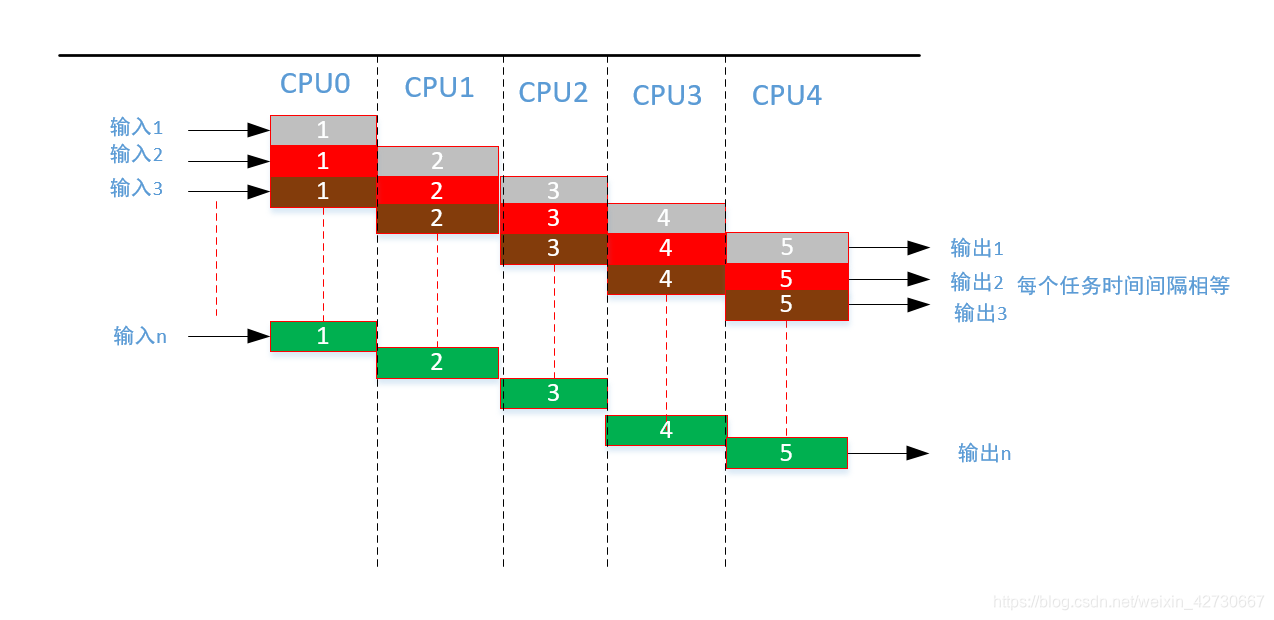
对任务2进行分解,分解成两个相等的任务,这样整个流水线的每个任务耗时比较均衡,两个输出时间间隔为一个任务的处理耗时,理论上对于串行程序实现并行改进,通过增加流水线处理,可以提高整个程序的并行能力,并提高资源利用率。
基于数据的并行
随着过去几十年的芯片的发展,所能获得的计算能力不断增长,但是,跟不上计算能力增长步伐的是数据的访问。基于数据并行的思路是首先关注数据及其所需要的变换,而不是待执行的任务。
比如一个对4个不同且无关的等长数组分别进行不同变换的例子,假设有4个CPU和一个带有4个SM的GPU(SM在GPU内部主要负责线程块的调度),在基于任务的并行处理中,将产生4个线程或进程来完成任务,如果要在在GPU上,则将使用4个线程块,并把每个数组的地址分别送给1个块,基于任务或者数据变换来考虑。
而基于数据的分解则是将第一个数组分成4个数据块,CPU中的一个核或者GPU中的1一个SM分别处理数组中的1数据块。处理完成完毕后,再按照相同的方式处理剩下的3个数组。对采用GPU处理而言,将产生4个内核程序,每个内核程序包含4个或者更多的数组块。对问题的这种并行分解是再考虑数据后再考虑变换的思路下进行的。
如上图所示,就是将数组A的数据进行分解,然后再考虑数据结果的转换。
缓存一致性问题
在进行基于数据分解过程中,CPU和GPU最大的差别就是缓存一致性问题。 在CPU内部由于为了加快数据的存取速度,一般都有一块缓存,用于临时存储常用的数据,这样做能够减少对内存的读写加快数据操作速度,现在CPU中做三级缓存也是非常常见,如果在一个多核的系统中,对一个内存的写操作需要通知所有核以及对应的各级别的缓存,来同步更新数组。因此无论何时,所有处理器看到的内存视图时完全一样的。随着现在处理器的CPU核数越来越多,这个“通知”的开销迅速增大,使得“缓存一致性”成为限制一个处理器中核数不能太多的一个重要因素。“缓存一致”系统中最坏的情况是,一个内存写操作会强迫每个核的缓存都进行更新,进而每个核都要对相邻的内存单元进行写操作。
相比之下,非“缓存一致”系统不会自动地更新其他核缓存。它需要开发人员写清楚各个处理器核输出得各自不同的目标区域。从程序的视角看,这支持一个核仅负责一个输出或者一个小的输出集。通常,CPU遵循“缓存一致”原则,而GPU则不是。故GPU能够扩展到一个芯片内具有大数量的核心(流处理器簇)。
常见的并行解决模式
实际上并不是所有的算法或代码都适合并行方式进行解决,这是限制并行计算发展的一大瓶颈。将串行程序用并行方式来解决,是十分考验耐心和经验的,尤其是算法在当前的硬件中跑的实际效果 再换另外一种硬件实际效果并不是很好,可移植性比较差,往往要获得最佳性能,需要开发人员去花大量时间去熟悉使用的硬件,而且随着当前的硬件的更新或者退出市场,再换另外一种硬件 其知识的可复制性可能并不是很高。但是对常见的串行程序中,还是可以总结出一些常用并行解决办法。
基于循环模式
循环在程序中是最常见的处理方式,主要由for、while等语法数据结构,是最容易实现并行计算的模型之一。
循环一
常见的最简单的循环方式中 就是迭代之间没有依赖 ,不依赖之前迭代计算的结果即前一个循环处理的结果,如下图:
每个数组结果元素之间是没有依赖, 相互之间没有依赖。对该类问题上实质分解就需要根据使用硬件可用的处理单元数组,对CPU而言 就是可用的逻辑硬件线程数目;对于GPU而言,就是流处理器簇(SM)的数量乘以每个SM的最大工作负载,与具体的算法无关,只与 硬件数目有关,通过相应的硬件数目将最大的并行能力部署到每个运算单元中、
循环二
在循环迭代中最坏的情况就是 循环的一次迭代依赖于之前或多次先前迭代结果。由于循环迭代之间结果有依赖,所以将要完全实现并行算法非常困难。这时首先就是要发现迭代之前的依赖关系,尽最大努力消除之前的依赖,如果不能消除,通常可以将循环分解成若干个循环块,块内的迭代可以并行执行。循环块0执行完后将结果送给循环1,然后送给循环块2,以此类推。
在并行算法中规约就是利用的这种方法:
规约是一类并行算法,对传入的N个数据,使用一个二元的符合结合律的操作符⊕,生成1个结果。这类操作包括取最小、取最大、求和、平方和、逻辑与/或、向量点积.
例如对于N个输入数据和操作符+,规约可表示为:
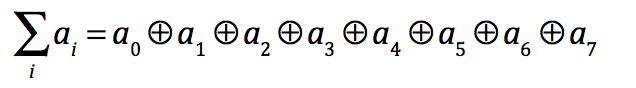
按照一般串行思维其实现如下:
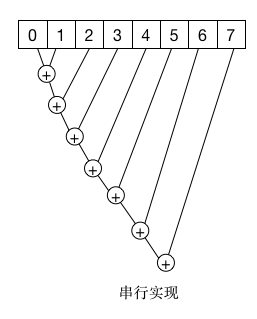
上述本次迭代的结果都依赖于上次的输出结果, 按照上述讲述的方法可以将上述数据分块计算求和,分别计算块内的和,然后再通过规约将每个块的和相加:
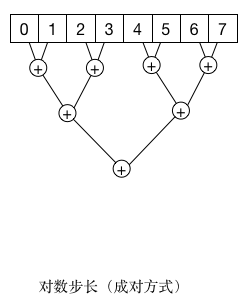
该方式是典型的分治思想,将数据按照块进行分割,然后在计算块内的和,但是该方法 有一个严重的缺点就是不能对内存访问进行合并,造成对内存读写性能比较差。
对上述方法进一步改进,采用SIMD思维,将数据库按平等分配,然后分别求对应位置两个快的数据和,如下:

该方法 为规约性能表现最好的一面,下面为在CUDA中的一个执行改进算法:

循环进行并行处理一个串行程序,最关键及重要的就是发现隐藏中的依赖关系,对依赖进行解耦,确保每一次迭代的计算结果不会被后面的迭代使用。
循环三
在循环处理中还有另外一个情况就是多层循环。针对多层循环一般的处理方法就是将最外层循环进行并行处理,因为最外层的循环最容易解耦数据之间的关系依赖。
例如在求两个二维数组的和,一般串行处理如下:
AddSum(int *A, int * B, int *c, int Row, int Col)
{for(int RowIndex=0 ; RowIndex < Row; RowIndex++)for(int ColIndex=0; ColIndex < Col; ColIndex++)C[RowIndex][ColIndex]= A[RowIndex][ColIndex] + B[RowIndex][ColIndex]
}在做并行计算时 很容易对外层循环进行并行处理,其伪代码处理结果如下:
kernel ParaAddSum1(int *A, int * B, int *c, int Col)
{int RowIndex = ThreadId;for(int ColIndex=0; ColIndex < Col; ColIndex++)C[RowIndex][ColIndex]= A[RowIndex][ColIndex] + B[RowIndex][ColIndex];
}如果多层循环即使是最内层循环数据之间也没有相关性,可以将双层循环同时进行并行,
kernel ParaAddSum2(int *A, int * B, int *c, int Col)
{int RowIndex = ThreadId.x;int ColIndex = ThreadId.y;int Index = RowIndex*Col + ColIndex;C[Index]= A[Index] + B[Index];
}还可以进一步最外层循环和最内层循环一起结合,这样能够最大实现并行化以及相邻之间的线程能够访问相邻之间内存,提供存储效率,伪代码处理结果为:
kernel ParaAddSum3(int *A, int * B, int *c)
{int Index = ThreadId;C[Index]= A[Index] + B[Index];
}派生/汇集模式
派生/汇集是另外一种常见的并行处理模式,主要是针对串行程序中仅有一部分可以进行并行处理,即首先运行串行代码,当运行到某一点时会遭遇到一个并行区,这个并行区的工作可以按照某种方式进行并行处理,这时就回首先“派生”(fork)出N个可以并行处理的线程,这N个线程相互独立,完成工作之后再将结果“汇集”(jion)起来,如下图:

该模式并行处理的最关键就是尽力寻找发现其中的并行处理部分。
分条/分块分解法
分条/分块分解法要求程序员把问题分成若干个小块,即分条/分块,绝大多数并行处理方法都可以以不同形式来使用条/块模型,可以很直观的展示并发性的概念。
在二维空间里可以很容易想象一个问题-数据的一个平面组织,它可理解为将一个网格覆盖在问题空间上,在三维空间里可以想象一个问题,就想一个魔方,可以把它理解为把一组块映射到问题空间中。
CUDA或者opencl提供是简单二维网络模型,如果在一个块内,算法或者任务是线性分布的,则可以很好的将其分解为CUDA块。由于在一个SM内,最多可以分配16个块,而在一个GPU内有16个SM,则可以把问题分成256个或者更多的块。
分而治之
分而治之模式同样也是把大问题分解成小问题模式,每个小问题都可以控制,通过把这些小的、单独的计算汇集在一起,就可以很顺利的将大问题解决。
常见的分而治之的算法使用“递归”来实现,快速排序法就是一个典型的例子。该算法反复递归把数据一分为二,一部分是位于支点之上的那些点,另外一部分是位于支点之下的那些点。最后,当某部分仅包含两个数据时,则对他们做比较和交互处理。
绝大多数递归算法可以用迭代模型来表示。由于迭代模型较适合于GPU基本的条块划分模型,所以该模型易于映射到GPU上。
递归算法较于理解,与将其转换成一个迭代的方法相比,编码实现递归算法比较容易。但是所有的递归调用都需要把所有的形参和全部的局部变量入栈。GPU和CPU实现栈的方法都是相同的,都是从全局内存中划出一块存储区间作为栈,与使用寄存器传递数据相比,还是比较慢。所以在可能的情况下 最好还是使用迭代的方法,这样可以获得更好的执行性能,并可以在更大范围的GPU硬件上运行。
参考书目
《OpenCL Programming Guide》
《CUDA并行程序设计GPU编程指南》