目录
1 PTX (Parallel Thread Execution)
2 MMA (Matrix Multiply Accumulate) PTX
3 LDMATRIX PTX
4 示例
5 底层代码
6 其他
6.1 HGEMM优化
1 PTX (Parallel Thread Execution)
PTX是什么,Nvidia官方描述为a low-level parallel thread execution virtual machine and instruction set architecture (ISA),直面意思是低级并行线程执行虚拟机和指令集架构。
怎么理解其直面意思,有两个方法。
一个方法是借鉴LLVM,熟悉LLVM的知道其全称是Low Level Virtual Machine,这里不在意LLVM的主干项目与其底层虚拟机的命名渐行渐远,主要关注LLVM的核心概念IR(Intermediate Representation),其行为与PTX有几分相似。IR连接了前端编程语言和后端目标代码,不仅可以比较容易地实现新的编程语言,还可以方便地生成不同硬件平台上的目标代码,同时还可以做一些通用性的编译优化和运行时优化。PTX是上承GPU编程语言CUDA C++,下启GPU硬件SASS指令,可以借助NVRTC实现运行时优化,某些层面上来说可以称之为GPU设备无关代码,因此PTX可以理解为”CUDA IR“。
另一个方法是不用太理解,毕竟Nvidia闭源的出发点就是让开发者难得糊涂。
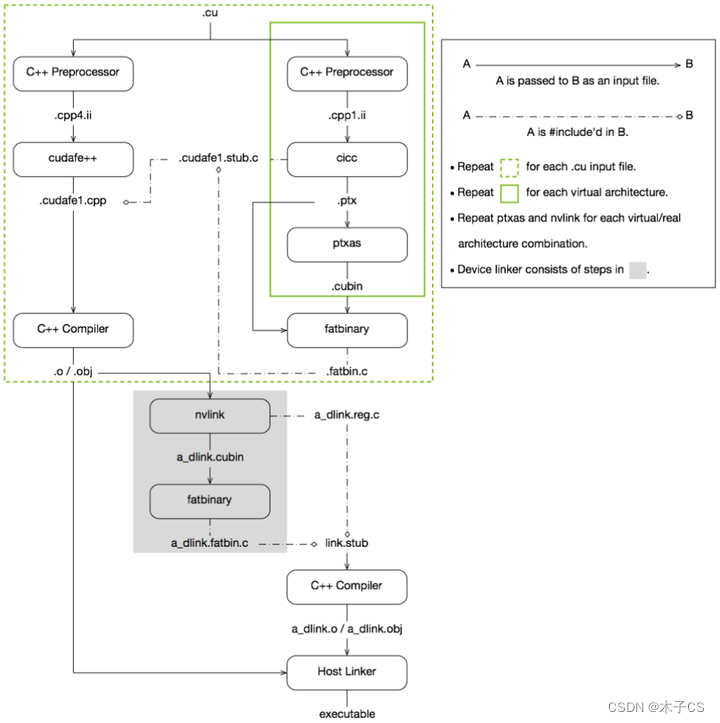
再回到PTX本身,习惯了CUDA C++编程,PTX似乎不曾看到过,但它其实一直都在。如下图所示为NVCC编译CUDA的过程,可以发现.cu文件的编译分为两个部分,一部分是编译主机代码,另一部分是编译设备代码,设备代码的编程过程中会生成.ptx文件,而通常关注的是编译生成的最终产物。NVCC的编译流程在这里就不展开了,后续有机会再聊。
2 MMA (Matrix Multiply Accumulate) PTX
对于计算能力在7.0及以上的CUDA设备,可以使用MMA PTX指令调用Tensor Core,支持形如D = AB + C的混合精度的矩阵乘运算。
mma.sync.aligned.m8n8k4.alayout.blayout.dtype.f16.f16.ctype d, a, b, c;
mma.sync.aligned.m16n8k8.row.col.dtype.f16.f16.ctype d, a, b, c;
mma.sync.aligned.m16n8k16.row.col.dtype.f16.f16.ctype d, a, b, c;以m16n8k16 FP16为例,每个tile中的元素在warp内线程上的计算分布如下图所示,可以明显发现每个线程计算的fragment都是不连续的。
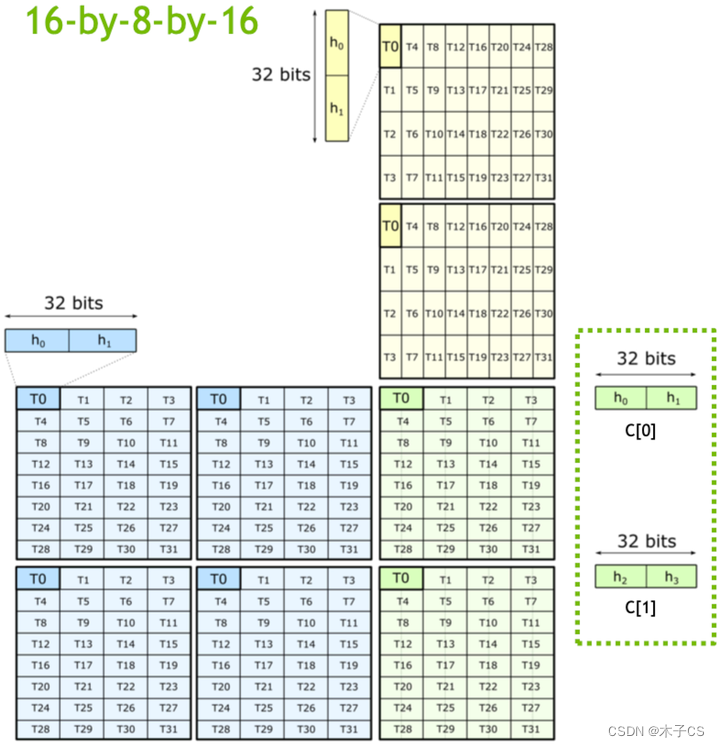
矩阵A fragment的行和列的索引可以按如下方式计算:
groupID = %laneid >> 2
threadID_in_group = %laneid % 4row = groupID for ai where 0 <= i < 2 || 4 <= i < 6groupID + 8 Otherwisecol = (threadID_in_group * 2) + (i & 0x1) for ai where i < 4(threadID_in_group * 2) + (i & 0x1) + 8 for ai where i >= 4矩阵B fragment的行和列的索引可以按如下方式计算:
groupID = %laneid >> 2
threadID_in_group = %laneid % 4row = (threadID_in_group * 2) + (i & 0x1) for bi where i < 2 (threadID_in_group * 2) + (i & 0x1) + 8 for bi where i >= 2col = groupID矩阵C或D fragment的行和列的索引可以按如下方式计算:
groupID = %laneid >> 2
threadID_in_group = %laneid % 4row = groupID for ci where i < 2groupID + 8 for ci where i >= 2col = (threadID_in_group * 2) + (i & 0x1) for ci where i = {0,..,3}3 LDMATRIX PTX
由于MMA PTX指令计算tile时,warp内线程计算的fragment不连续,索引计算较为复杂,所以Nvidia提供了LDMATRIX PTX指令用来配合MMA PTX指令。
ldmatrix.sync.aligned.shape.num{.trans}{.ss}.type r, [p];.shape = {.m8n8};
.num = {.x1, .x2, .x4};
.ss = {.shared};
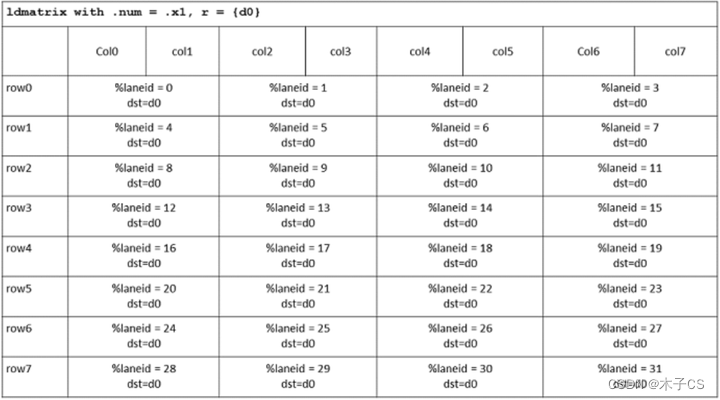
.type = {.b16};LDMATRIX PTX是warp级别的数据加载指令,其读取连续的行不需要连续地存储在内存中。每个矩阵所需的8个地址由8个线程提供,具体取决于.num的值。每个地址对应于一个矩阵行的开始。地址addr0-addr7对应第一个矩阵的行,地址addr8-addr15对应第二个矩阵的行,依此类推,如下表所示。

当读取8x8的矩阵时,一组连续的四个线程加载16个字节。矩阵地址必须相应地对齐。warp中的每个线程加载一行的fragment,线程0接收寄存器r中的第一个fragment,以此类推。由四个线程组成的一组将加载矩阵的一整行,如下表所示。可以发现,LDMATRIX PTX指令在warp内线程上的数据分布与MMA PTX指令一致。
值得注意的是,首先LDMATRIX PTX指令只能从shared memory中加载数据;其次对于计算能力在sm_75及以下的CUDA设备,LDMATRIX PTX指令中的所有线程必须包含有效地址。否则,行为是未定义的。.num为.x1和.x2时,低线程中包含的地址可以复制到高线程中,以实现预期的行为。
4 示例
Talk is cheap,show me the code。与Nvidia Tensor Core-WMMA API编程入门类似,以m16n8k16为例,实现HGEMM:C = AB,其中矩阵A(M * K,row major)、B(K * N,col major)和C(M * N,row major)的精度均为FP16。
MMA PTX的编程思路类似于WMMA API,都是按照每个warp处理一个矩阵C的tile的思路来构建naive kernel。首先确定当前warp处理矩阵C的tile坐标,声明计算tilie所需的shared memory和寄存器,再以MMA_K为步长遍历K并从global memory经shared memory由LDMATRIX PTX加载所需A、B矩阵tile到寄存器参与计算,最后将计算结果从寄存器经shared memory写回矩阵C。所有block计算完成之后即可得到矩阵C。这个例子有难度,但不多。源码在cuda_hgemm。
#include <mma.h>#define DIV_CEIL(x, y) (((x) + (y) - 1) / (y))#define MMA_M 16
#define MMA_N 8
#define MMA_K 16#define WARP_SIZE 32__global__ void mma16816NaiveKernel(const half *__restrict__ A, const half *__restrict__ B, half *__restrict__ C,size_t M, size_t N, size_t K) {const size_t K_tiles = DIV_CEIL(K, MMA_K);const size_t warpRow = blockIdx.x * MMA_M;const size_t warpCol = blockIdx.y * MMA_N;if (warpRow >= M || warpCol >= N) {return;}__shared__ half shmem_A[MMA_M][MMA_K];__shared__ half shmem_B[MMA_N][MMA_K];__shared__ half shmem_C[MMA_M][MMA_N];const size_t laneId = threadIdx.x % WARP_SIZE;uint32_t RA[4];uint32_t RB[2];uint32_t RC[2] = {0, 0};for (size_t i = 0; i < K_tiles; ++i) {*((int4 *)(&shmem_A[laneId / 2][0]) + laneId % 2) =*((int4 *)(&A[(warpRow + laneId / 2) * K + i * MMA_K]) + laneId % 2);if (laneId < MMA_N * 2) {*((int4 *)(&shmem_B[laneId / 2][0]) + laneId % 2) =*((int4 *)(&B[i * MMA_K + (warpCol + laneId / 2) * K]) + laneId % 2);}__syncthreads();uint32_t shmem_A_lane_addr = __cvta_generic_to_shared(&shmem_A[laneId % 16][(laneId / 16) * 8]);asm volatile("ldmatrix.sync.aligned.x4.m8n8.shared.b16 {%0, %1, %2, %3}, [%4];\n": "=r"(RA[0]), "=r"(RA[1]), "=r"(RA[2]), "=r"(RA[3]): "r"(shmem_A_lane_addr));uint32_t shmem_B_lane_addr = __cvta_generic_to_shared(&shmem_B[laneId % 8][((laneId / 8) % 2) * 8]);asm volatile("ldmatrix.sync.aligned.x2.m8n8.shared.b16 {%0, %1}, [%2];\n": "=r"(RB[0]), "=r"(RB[1]): "r"(shmem_B_lane_addr));asm volatile("mma.sync.aligned.m16n8k16.row.col.f16.f16.f16.f16 {%0, %1}, {%2, %3, %4, %5}, {%6, %7}, {%8, %9};\n": "=r"(RC[0]), "=r"(RC[1]): "r"(RA[0]), "r"(RA[1]), "r"(RA[2]), "r"(RA[3]), "r"(RB[0]), "r"(RB[1]), "r"(RC[0]), "r"(RC[1]));*((uint32_t *)(&shmem_C[laneId / 4][0]) + laneId % 4) = RC[0];*((uint32_t *)(&shmem_C[laneId / 4 + 8][0]) + laneId % 4) = RC[1];__syncthreads();}if (laneId < MMA_M) {*((int4 *)(&C[(warpRow + laneId) * N + warpCol])) = *((int4 *)(&shmem_C[laneId][0]));}__syncthreads();
}void hgemmMmaNaive(half *A, half *B, half *C, size_t M, size_t N, size_t K) {dim3 block(WARP_SIZE);dim3 grid(DIV_CEIL(M, MMA_M), DIV_CEIL(N, MMA_N));mma16816NaiveKernel<<<grid, block>>>(A, B, C, M, N, K);
}5 底层代码
我们再对上述MMA naive kernel做进一步探索,看一下它在RTX A6000(sm_86,CUDA 11.3)上对应的SASS。
IMAD.MOV.U32 R1, RZ, RZ, c[0x0][0x28] S2R R36, SR_CTAID.Y IMAD.MOV.U32 R7, RZ, RZ, c[0x0][0x188] S2R R34, SR_CTAID.X IMAD.SHL.U32 R36, R36, 0x8, RZ IMAD.SHL.U32 R34, R34, 0x10, RZ ISETP.GE.U32.AND P0, PT, R36, c[0x0][0x180], PT ISETP.GE.U32.AND P1, PT, R34, c[0x0][0x178], PT ISETP.GE.U32.AND.EX P0, PT, RZ, c[0x0][0x184], PT, P0 ISETP.GE.U32.OR.EX P0, PT, RZ, c[0x0][0x17c], P0, P1
@P0 EXIT IADD3 R7, P0, R7, 0xf, RZ S2R R6, SR_TID.X ULDC.64 UR6, c[0x0][0x118] IMAD.X R8, RZ, RZ, c[0x0][0x18c], P0 SHF.R.U64 R7, R7, 0x4, R8 SHF.R.U32.HI R8, RZ, 0x4, R8 ISETP.NE.U32.AND P0, PT, R7, RZ, PT ISETP.NE.AND.EX P0, PT, R8, RZ, PT, P0 LOP3.LUT R33, R6, 0x1f, RZ, 0xc0, !PT
@!P0 BRA 0x7fc374fcb660 IMAD.SHL.U32 R0, R6, 0x20, RZ IADD3 R3, P0, R7, -0x1, RZ IMAD.SHL.U32 R5, R6, 0x4, RZ LOP3.LUT R2, R33, 0x10, RZ, 0xc0, !PT IMAD.SHL.U32 R4, R33, 0x4, RZ LOP3.LUT R31, R0, 0x1e0, RZ, 0xc0, !PT UMOV UR4, URZ LOP3.LUT R30, R0, 0xe0, RZ, 0xc0, !PT UMOV UR5, URZ ISETP.GE.U32.AND P1, PT, R3, 0x3, PT IMAD.SHL.U32 R3, R6, 0x2, RZ IADD3.X R0, R8, -0x1, RZ, P0, !PT IMAD.IADD R31, R31, 0x1, R2 LOP3.LUT R5, R5, 0xc, RZ, 0xc0, !PT IMAD.SHL.U32 R2, R6, 0x10, RZ LOP3.LUT R4, R4, 0x70, RZ, 0xc0, !PT CS2R R20, SRZ ISETP.GE.U32.AND.EX P1, PT, R0, RZ, PT, P1 LOP3.LUT R3, R3, 0x10, RZ, 0xc0, !PT IMAD.IADD R27, R4, 0x1, R5 SHF.R.U64 R5, R33, 0x1, RZ LOP3.LUT R0, R7, 0x3, RZ, 0xc0, !PT IMAD.IADD R30, R30, 0x1, R3 LOP3.LUT R32, R2, 0x10, RZ, 0xc0, !PT IADD3 R3, P2, R34, R5, RZ IADD3 R4, P3, R36, R5, RZ IMAD R32, R5, 0x20, R32 ISETP.NE.U32.AND P0, PT, R0, RZ, PT IMAD.X R5, RZ, RZ, RZ, P2 LOP3.LUT R2, R33, 0x1, RZ, 0xc0, !PT IMAD.X R6, RZ, RZ, RZ, P3 ISETP.NE.AND.EX P0, PT, RZ, RZ, PT, P0
@!P1 BRA 0x7fc374fcb390 IADD3 R24, P1, -R0, R7, RZ IMAD.SHL.U32 R26, R2, 0x10, RZ ISETP.GT.U32.AND P2, PT, R33, 0xf, PT CS2R R20, SRZ SHF.L.U64.HI R25, R2, 0x4, RZ UMOV UR4, URZ IADD3.X R7, R8, -0x1, RZ, P1, !PT UMOV UR5, URZ USHF.L.U32 UR8, UR4, 0x4, URZ IMAD R8, R5, c[0x0][0x188], RZ USHF.L.U64.HI UR9, UR4, 0x4, UR5 IMAD R11, R3, c[0x0][0x18c], R8 IMAD.U32 R12, RZ, RZ, UR8 IMAD.U32 R13, RZ, RZ, UR9 IMAD.WIDE.U32 R8, R3, c[0x0][0x188], R12 IMAD.IADD R9, R9, 0x1, R11 LEA R41, P1, R8, c[0x0][0x160], 0x1 LEA.HI.X R8, R8, c[0x0][0x164], R9, 0x1, P1 IADD3 R40, P1, R26, R41, RZ IMAD.X R41, R25, 0x1, R8, P1 LDG.E.128.CONSTANT R8, [R40.64] IMAD R15, R6, c[0x0][0x188], RZ IMAD.WIDE.U32 R12, R4, c[0x0][0x188], R12 IMAD R15, R4, c[0x0][0x18c], R15 LEA R39, P1, R12, c[0x0][0x168], 0x1 IMAD.IADD R13, R13, 0x1, R15 LEA.HI.X R12, R12, c[0x0][0x16c], R13, 0x1, P1 IADD3 R38, P1, R39, R26, RZ IMAD.X R39, R12, 0x1, R25, P1
@!P2 LDG.E.128.CONSTANT R16, [R38.64]
@!P2 LDG.E.128.CONSTANT R12, [R38.64+0x20] STS.128 [R32], R8 LDG.E.128.CONSTANT R8, [R40.64+0x20]
@!P2 STS.128 [R32+0x200], R16 BAR.SYNC 0x0 LDSM.16.M88.2 R22, [R30+0x200] LDSM.16.M88.4 R16, [R31] HMMA.16816.F16 R20, R16, R22, R20 NOP STS [R27+0x300], R20 STS [R27+0x380], R21 BAR.SYNC 0x0
@!P2 STS.128 [R32+0x200], R12
@!P2 LDG.E.128.CONSTANT R12, [R38.64+0x40] STS.128 [R32], R8 BAR.SYNC 0x0 LDSM.16.M88.2 R28, [R30+0x200] LDSM.16.M88.4 R16, [R31] LDG.E.128.CONSTANT R8, [R40.64+0x40] HMMA.16816.F16 R28, R16, R28, R20 LDG.E.128.CONSTANT R16, [R40.64+0x60]
@!P2 LDG.E.128.CONSTANT R20, [R38.64+0x60] NOP STS [R27+0x300], R28 STS [R27+0x380], R29 BAR.SYNC 0x0
@!P2 STS.128 [R32+0x200], R12 IADD3 R24, P1, R24, -0x4, RZ IADD3.X R7, R7, -0x1, RZ, P1, !PT ISETP.NE.U32.AND P1, PT, R24, RZ, PT ISETP.NE.AND.EX P1, PT, R7, RZ, PT, P1 UIADD3 UR4, UP0, UR4, 0x4, URZ UIADD3.X UR5, URZ, UR5, URZ, UP0, !UPT STS.128 [R32], R8 BAR.SYNC 0x0 LDSM.16.M88.2 R12, [R30+0x200] LDSM.16.M88.4 R8, [R31] HMMA.16816.F16 R12, R8, R12, R28 NOP STS [R27+0x300], R12 STS [R27+0x380], R13 BAR.SYNC 0x0 STS.128 [R32], R16
@!P2 STS.128 [R32+0x200], R20 BAR.SYNC 0x0 LDSM.16.M88.2 R14, [R30+0x200] LDSM.16.M88.4 R8, [R31] HMMA.16816.F16 R20, R8, R14, R12 NOP STS [R27+0x300], R20 STS [R27+0x380], R21 BAR.SYNC 0x0
@P1 BRA 0x7fc374fcaee0
@!P0 BRA 0x7fc374fcb660 SHF.L.U64.HI R11, R2, 0x3, RZ IMAD.SHL.U32 R10, R2, 0x8, RZ USHF.L.U32 UR8, UR4, 0x4, URZ IMAD R13, R6, c[0x0][0x188], RZ USHF.L.U64.HI UR4, UR4, 0x4, UR5 IMAD.WIDE.U32 R8, R4, c[0x0][0x188], R10 IADD3 R0, P3, RZ, -R0, RZ IMAD R2, R5, c[0x0][0x188], RZ IADD3 R22, P1, R8, UR8, RZ IMAD.WIDE.U32 R6, R3, c[0x0][0x188], R10 IMAD R13, R4, c[0x0][0x18c], R13 IMAD R5, R3, c[0x0][0x18c], R2 IADD3 R3, P0, R6, UR8, RZ IMAD.X R18, RZ, RZ, -0x1, P3 IADD3.X R9, R13, UR4, R9, P1, !PT LEA R19, P1, R22, c[0x0][0x168], 0x1 LEA R2, P2, R3, c[0x0][0x160], 0x1 IADD3.X R6, R5, UR4, R7, P0, !PT LEA.HI.X R22, R22, c[0x0][0x16c], R9, 0x1, P1 LEA.HI.X R3, R3, c[0x0][0x164], R6, 0x1, P2 ISETP.GT.U32.AND P0, PT, R33, 0xf, PT LDG.E.128.CONSTANT R4, [R2.64]
@!P0 IMAD.MOV.U32 R8, RZ, RZ, R19
@!P0 IMAD.MOV.U32 R9, RZ, RZ, R22
@!P0 LDG.E.128.CONSTANT R8, [R8.64] IADD3 R2, P2, R2, 0x20, RZ IADD3 R19, P1, R19, 0x20, RZ IMAD.X R3, RZ, RZ, R3, P2 IMAD.X R22, RZ, RZ, R22, P1 STS.128 [R32], R4
@!P0 STS.128 [R32+0x200], R8 BAR.SYNC 0x0 LDSM.16.M88.2 R16, [R30+0x200] LDSM.16.M88.4 R12, [R31] IADD3 R0, P0, R0, 0x1, RZ IMAD.X R18, RZ, RZ, R18, P0 ISETP.NE.U32.AND P0, PT, R0, RZ, PT ISETP.NE.AND.EX P0, PT, R18, RZ, PT, P0 HMMA.16816.F16 R20, R12, R16, R20 NOP STS [R27+0x300], R20 STS [R27+0x380], R21 BAR.SYNC 0x0
@P0 BRA 0x7fc374fcb4e0 ISETP.GT.U32.AND P0, PT, R33, 0xf, PT BSSY B0, 0x7fc374fcb760
@P0 BRA 0x7fc374fcb750 LEA R4, R33, 0x300, 0x4 IMAD.MOV.U32 R37, RZ, RZ, RZ IADD3 R33, P0, R34, R33, RZ LDS.128 R4, [R4] IMAD.X R0, RZ, RZ, RZ, P0 IMAD.WIDE.U32 R36, R33, c[0x0][0x180], R36 IMAD R0, R0, c[0x0][0x180], RZ LEA R2, P0, R36, c[0x0][0x170], 0x1 IMAD R3, R33, c[0x0][0x184], R0 IMAD.IADD R3, R37, 0x1, R3 LEA.HI.X R3, R36, c[0x0][0x174], R3, 0x1, P0 STG.E.128 [R2.64], R4 BSYNC B0 BAR.SYNC 0x0 EXIT BRA 0x7fc374fcb780NOPNOPNOPNOPNOPNOPNOPNOPNOPNOPNOPNOPNOPNOPNOP可以发现与WMMA161616 API类似,MMA16816 PTX指令底层实现也是HMMA16816指令。
6 其他
6.1 HGEMM优化
与WMMA API类似,学习MMA PTX的目标在于调用Tensor Core优化HGEMM,相比于cublas,MMA的性能究竟如何?我们后续再聊。可以参考开源代码cuda_hgemm。