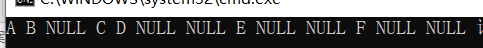一、二叉树
在计算机科学中,树是一种重要的非线性数据结构,直观地看,它是数据元素(在树中称为结点)按分支关系组织起来的结构。二叉树是每个节点最多有两个子树的有序树。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。二叉树常被用于实现二叉查找树和二叉堆。值得注意的是,二叉树不是树的特殊情形。在图论中,二叉树是一个连通的无环图,并且每一个顶点的度不大于3。有根二叉树还要满足根结点的度不大于2。有了根结点后,每个顶点定义了唯一的根结点,和最多2个子结点。然而,没有足够的信息来区分左结点和右结点。二叉树的每个结点至多只有二棵子树(不存在度大于2的结点),二叉树的子树有左右之分,次序不能颠倒。二叉树的第i层至多有2的 i -1次方个结点;深度为k的二叉树至多有2^(k) -1个结点;对任何一棵二叉树T,如果其终端结点数(即叶子结点数)为n0,度为2的结点数为n2,则n0 = n2 + 1。
二、二叉树的遍历
前序遍历(DLR)
前序遍历也叫做先根遍历,可记做根左右。前序遍历首先访问根结点然后遍历左子树,最后遍历右子树。在遍历左、右子树时,仍然先访问根结点,然后遍历左子树,最后遍历右子树。
若二叉树为空则结束返回,否则:
( 1 )访问根结点
( 2 )前序遍历左子树
( 3 )前序遍历右子树
注意的是:遍历左右子树时仍然采用前序遍历方法。
中序遍历(LDR)
中序遍历也叫做中根遍历,可记做左根右。
中序遍历首先遍历左子树,然后访问根结点,最后遍历右子树。在遍历左、右子树时,仍然先遍历左子树,再访问根结点,最后遍历右子树。即:
若二叉树为空则结束返回,否则:
(1)中序遍历左子树
(2)访问根结点
(3)中序遍历右子树。
注意的是:遍历左右子树时仍然采用中序遍历方法。
后序遍历(LRD)
后序遍历也叫做后根遍历,可记做左右根。后序遍历首先遍历左子树,然后遍历右子树,最后访问根结点。在遍历左、右子树时,仍然先遍历左子树,再遍历右子树,最后访问根结点。即:
若二叉树为空则结束返回,否则:
( 1 )后序遍历左子树。
( 2 )后序遍历右子树。
( 3 )访问根结点。
注意的是:遍历左右子树时仍然采用后序遍历方法。
层次遍历
按照从上至下,从左至右的顺序遍历二叉树。

前序遍历,也叫先根遍历,遍历的顺序是,根,左子树,右子树
遍历结果:A,B,E,F,C,G
中序遍历,也叫中根遍历,顺序是 左子树,根,右子树
遍历结果:E,B,F,A,G,C
后序遍历,也叫后根遍历,遍历顺序,左子树,右子树,根
遍历结果:E,F,B,G,C,A
层次遍历结果:A,B,C,E,F,G
二叉树的链式存储结构是一类重要的数据结构,其形式定义如下:
//二叉树结点
typedef struct BiTNode{
//数据
char data;
//左右孩子指针
struct BiTNode *lchild,*rchild;
}BiTNode,*BiTree; 二叉树的创建:
通过读入一个字符串,建立二叉树的算法如下:
//按先序序列创建二叉树
int CreateBiTree(BiTree &T){
char data;
//按先序次序输入二叉树中结点的值(一个字符),‘#’表示空树
scanf("%c",&data);
if(data == '#'){
T = NULL;
}
else{
T = (BiTree)malloc(sizeof(BiTNode));
//生成根结点
T->data = data;
//构造左子树
CreateBiTree(T->lchild);
//构造右子树
CreateBiTree(T->rchild);
}
return 0;
}注意:创建二叉树的算法中,字符串的输入必须是按先序次序输入,先序遍历二叉树时空树以#代替,以图1-1为例,应该输入的字符串顺序为:ABE##F##CG###(最后一个#是结束符),“#”表示空树,如下图所示:

二叉树的遍历:
遍历是对树的一种最基本的运算,所谓遍历二叉树,就是按一定的规则和顺序走遍二叉树的所有结点,使每一个结点都被访问一次,而且只被访问一次。由于二叉树是非线性结构,因此,树的遍历实质上是将二叉树的各个结点转换成为一个线性序列来表示。
递归算法:
输出二叉树的字符序列,以 '#' 结束。先访问根节点,然后访问左节点,再访问右节点。
//输出
void Visit(BiTree T){
if(T->data != '#'){
printf("%c ",T->data);
}
}
//先序遍历
void PreOrder(BiTree T){
if(T != NULL){
//访问根节点
Visit(T);
//访问左子结点
PreOrder(T->lchild);
//访问右子结点
PreOrder(T->rchild);
}
}中序遍历,先访问左节点,然后访问根节点,再访问右节点。
void InOrder(BiTree T){
if(T != NULL){
//访问左子结点
InOrder(T->lchild);
//访问根节点
Visit(T);
//访问右子结点
InOrder(T->rchild);
}
}后序遍历,先访问左节点,然后访问右节点,再访问根节点。
void PostOrder(BiTree T){
if(T != NULL){
//访问左子结点
PostOrder(T->lchild);
//访问右子结点
PostOrder(T->rchild);
//访问根节点
Visit(T);
}
}非递归算法:
<1>先序遍历:
【思路】:访问T->data后,将T入栈,遍历左子树;遍历完左子树返回时,栈顶元素应为T,出栈,再先序遍历T的右子树。其实每次都是走树的左分支(left),直到左子树为空,然后开始从递归的最深处返回,然后开始恢复递归现场,访问右子树。
/* 先序遍历(非递归)思路:访问T->data后,将T入栈,遍历左子树;遍历完左子树返回时,栈顶元素应为T,出栈,再先序遍历T的右子树。
*/
void PreOrder2(BiTree T){
stack<BiTree> stack;
//p是遍历指针
BiTree p = T;
//栈不空或者p不空时循环
while(p || !stack.empty()){
if(p != NULL){
//存入栈中
stack.push(p);
//访问根节点
printf("%c ",p->data);
//遍历左子树
p = p->lchild;
}
else{
//退栈
p = stack.top();
stack.pop();
//访问右子树
p = p->rchild;
}
}//while
} <2>中序遍历
【思路】:T是要遍历树的根指针,中序遍历要求在遍历完左子树后,访问根,再遍历右子树。
先将T入栈,遍历左子树;遍历完左子树返回时,栈顶元素应为T,出栈,访问T->data,再中序遍历T的右子树。
void InOrder2(BiTree T){
stack<BiTree> stack;
//p是遍历指针
BiTree p = T;
//栈不空或者p不空时循环
while(p || !stack.empty()){
if(p != NULL){
//存入栈中
stack.push(p);
//遍历左子树
p = p->lchild;
}
else{
//退栈,访问根节点
p = stack.top();
printf("%c ",p->data);
stack.pop();
//访问右子树
p = p->rchild;
}
}//while
} <3>后序遍历
【思路】:T是要遍历树的根指针,后序遍历要求在遍历完左右子树后,再访问根。需要判断根结点的左右子树是否均遍历过。
//后序遍历(非递归)
typedef struct BiTNodePost{
BiTree biTree;
char tag;
}BiTNodePost,*BiTreePost;
void PostOrder2(BiTree T){
stack<BiTreePost> stack;
//p是遍历指针
BiTree p = T;
BiTreePost BT;
//栈不空或者p不空时循环
while(p != NULL || !stack.empty()){
//遍历左子树
while(p != NULL){
BT = (BiTreePost)malloc(sizeof(BiTNodePost));
BT->biTree = p;
//访问过左子树
BT->tag = 'L';
stack.push(BT);
p = p->lchild;
}
//左右子树访问完毕访问根节点
while(!stack.empty() && (stack.top())->tag == 'R'){
BT = stack.top();
//退栈
stack.pop();
BT->biTree;
printf("%c ",BT->biTree->data);
}
//遍历右子树
if(!stack.empty()){
BT = stack.top();
//访问过右子树
BT->tag = 'R';
p = BT->biTree;
p = p->rchild;
}
}//while
}<4>层次遍历
【思路】:按从顶向下,从左至右的顺序来逐层访问每个节点,层次遍历的过程中需要用队列。
//层次遍历
void LevelOrder(BiTree T){
BiTree p = T;
//队列
queue<BiTree> queue;
//根节点入队
queue.push(p);
//队列不空循环
while(!queue.empty()){
//对头元素出队
p = queue.front();
//访问p指向的结点
printf("%c ",p->data);
//退出队列
queue.pop();
//左子树不空,将左子树入队
if(p->lchild != NULL){
queue.push(p->lchild);
}
//右子树不空,将右子树入队
if(p->rchild != NULL){
queue.push(p->rchild);
}
}
}以图1-1为测试用例
输入:ABE##F##CG###
输出结果:

完整代码:
// BinaryTree.cpp : 定义控制台应用程序的入口点
#include "stdafx.h"
#include<iostream>
#include<stack>
#include<queue>
using namespace std;//二叉树结点
typedef struct BiTNode{//数据char data;//左右孩子指针struct BiTNode *lchild,*rchild;
}BiTNode,*BiTree;//按先序序列创建二叉树
int CreateBiTree(BiTree &T){char data;//按先序次序输入二叉树中结点的值(一个字符),‘#’表示空树scanf("%c",&data);if(data == '#'){T = NULL;}else{T = (BiTree)malloc(sizeof(BiTNode));//生成根结点T->data = data;//构造左子树CreateBiTree(T->lchild);//构造右子树CreateBiTree(T->rchild);}return 0;
}
//输出
void Visit(BiTree T){if(T->data != '#'){printf("%c ",T->data);}
}
//先序遍历
void PreOrder(BiTree T){if(T != NULL){//访问根节点Visit(T);//访问左子结点PreOrder(T->lchild);//访问右子结点PreOrder(T->rchild);}
}
//中序遍历
void InOrder(BiTree T){ if(T != NULL){ //访问左子结点 InOrder(T->lchild); //访问根节点 Visit(T); //访问右子结点 InOrder(T->rchild); }
}
//后序遍历
void PostOrder(BiTree T){if(T != NULL){//访问左子结点PostOrder(T->lchild);//访问右子结点PostOrder(T->rchild);//访问根节点Visit(T);}
}
/* 先序遍历(非递归)
思路:访问T->data后,将T入栈,遍历左子树;遍历完左子树返回时,栈顶元素应为T,出栈,再先序遍历T的右子树。
*/
void PreOrder2(BiTree T){stack<BiTree> stack;//p是遍历指针BiTree p = T;//栈不空或者p不空时循环while(p || !stack.empty()){if(p != NULL){//存入栈中stack.push(p);//访问根节点printf("%c ",p->data);//遍历左子树p = p->lchild;}else{//退栈p = stack.top();stack.pop();//访问右子树p = p->rchild;}}//while
}
/* 中序遍历(非递归)
思路:T是要遍历树的根指针,中序遍历要求在遍历完左子树后,访问根,再遍历右子树。
先将T入栈,遍历左子树;遍历完左子树返回时,栈顶元素应为T,出栈,访问T->data,再中序遍历T的右子树。
*/
void InOrder2(BiTree T){stack<BiTree> stack;//p是遍历指针BiTree p = T;//栈不空或者p不空时循环while(p || !stack.empty()){if(p != NULL){//存入栈中stack.push(p);//遍历左子树p = p->lchild;}else{//退栈,访问根节点p = stack.top();printf("%c ",p->data);stack.pop();//访问右子树p = p->rchild;}}//while
}//后序遍历(非递归)
typedef struct BiTNodePost{BiTree biTree;char tag;
}BiTNodePost,*BiTreePost;void PostOrder2(BiTree T){stack<BiTreePost> stack;//p是遍历指针BiTree p = T;BiTreePost BT;//栈不空或者p不空时循环while(p != NULL || !stack.empty()){//遍历左子树while(p != NULL){BT = (BiTreePost)malloc(sizeof(BiTNodePost));BT->biTree = p;//访问过左子树BT->tag = 'L';stack.push(BT);p = p->lchild;}//左右子树访问完毕访问根节点while(!stack.empty() && (stack.top())->tag == 'R'){BT = stack.top();//退栈stack.pop();BT->biTree;printf("%c ",BT->biTree->data);}//遍历右子树if(!stack.empty()){BT = stack.top();//访问过右子树BT->tag = 'R';p = BT->biTree;p = p->rchild;}}//while
}
//层次遍历
void LevelOrder(BiTree T){BiTree p = T;//队列queue<BiTree> queue;//根节点入队queue.push(p);//队列不空循环while(!queue.empty()){//对头元素出队p = queue.front();//访问p指向的结点printf("%c ",p->data);//退出队列queue.pop();//左子树不空,将左子树入队if(p->lchild != NULL){queue.push(p->lchild);}//右子树不空,将右子树入队if(p->rchild != NULL){queue.push(p->rchild);}}
}
int main()
{BiTree T;CreateBiTree(T);printf("先序遍历:\n");PreOrder(T);printf("\n");printf("先序遍历(非递归):\n");PreOrder2(T);printf("\n");printf("中序遍历:\n");InOrder(T);printf("\n");printf("中序遍历(非递归):\n");InOrder2(T);printf("\n");printf("后序遍历:\n");PostOrder(T);printf("\n");printf("后序遍历(非递归):\n");PostOrder2(T);printf("\n");printf("层次遍历:\n");LevelOrder(T);printf("\n");system("pause");return 0;
}
以上实例在VS2008上编译通过。
参考:http://blog.csdn.net/sjf0115/article/details/8645991