相信大家在学习tensorflow的过程中,会想要自己动手来试试加载我们的数据集,而不再局限于从datasets上下载数据集。但是往往一个模型的训练就需要很庞大的数据集,因此写下这篇博客教大家如何用爬虫爬取图片,制作自己的数据集,本博客只教大家爬取原始图片数据,数据增强方面博主会再写一篇博客教大家常用的一些图片处理方法。
博主用的是pycharm2021.3,谷歌浏览器,第三方库文件如下。
import requests
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from time import sleep
import re
import os另外大家还需要下载一个驱动文件,chromedriver.exe,下载链接http://chromedriver.storage.googleapis.com/index.html
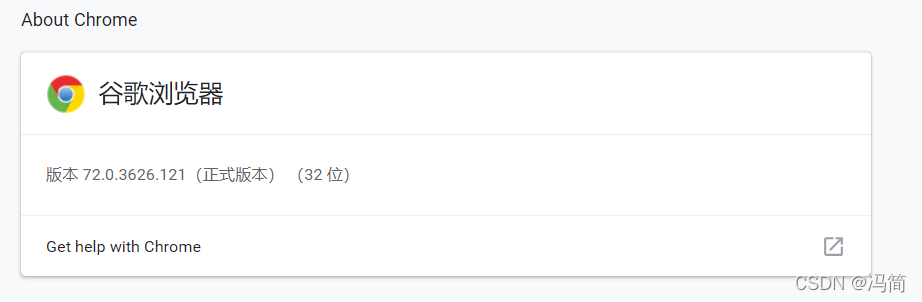
下载之前大家先查看一下自己浏览器的版本,在设置里的About chrome就可以查看,下载完成之后,推荐大家放在和爬虫文件同目录下。
下面用爬取跑车和卡车图片的例子来教大家。
第一步,模拟加载网页
这里是用到了 selenium.webdriver.chrome.service 这个库,作用为爬取瀑布流网页源码数据,因为瀑布流网页的图片数据是实时加载出来的,所以使用 selenium中的模拟鼠标滚轮下滑,加载出网页的图片数据,方便我们后面爬取。
#模拟加载网页s = Service('./chromedriver.exe')driver = webdriver.Chrome(service=s)driver.get('https://image.baidu.com/search/index?tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&dyTabStr=MCwzLDYsMSw0LDUsMiw4LDcsOQ%3D%3D&word=%E8%B7%91%E8%BD%A6')for i in range(0,3):driver.execute_script("window.scrollTo(0,document.body.scrollHeight);")sleep(1)sleep(3)page = driver.page_source其中的for循环限制了爬取多少图片,博主设置(0,3)是当时测试用,大家酌情调整。
这里的设置的sleep是为了给网页加载的时间,不然会出现爬取不到数据的情况。
第二步,匹配图片地址
用到了正则表达式,将图片地址保存在列表中。
#匹配图片地址ex = 'data-imgurl="(.*?)"'img_src_list = re.findall(ex,page, re.S)print(img_src_list)第三步,遍历地址,下载图片
#遍历地址,下载图片for src in img_src_list:img_data = requests.get(src).contentimg_name = re.search('[0-9]*', src.split(',')[-1])img_name = img_name.group(0)img_path = 'image/img_pao' + '/' + img_name + '.jpg'with open(img_path, 'wb') as fp:fp.write(img_data)print('ok')我这里img_path是使用的我自己的文件名称,大家可以改成自己的。
需要注意的地方是,这一句中,我的image和img_pao这两个文件夹是已经创建好的。
img_path = 'image/img_pao' + '/' + img_name + '.jpg'然后我们运行,就大功告成了。

这里我们项目跑起来之后,浏览器会自动打开,并且提示受到自动测试软件控制,大家不用管,只需要看着它帮你爬取就好了。
运行结束文件夹中就会出现爬取成功的图片了。