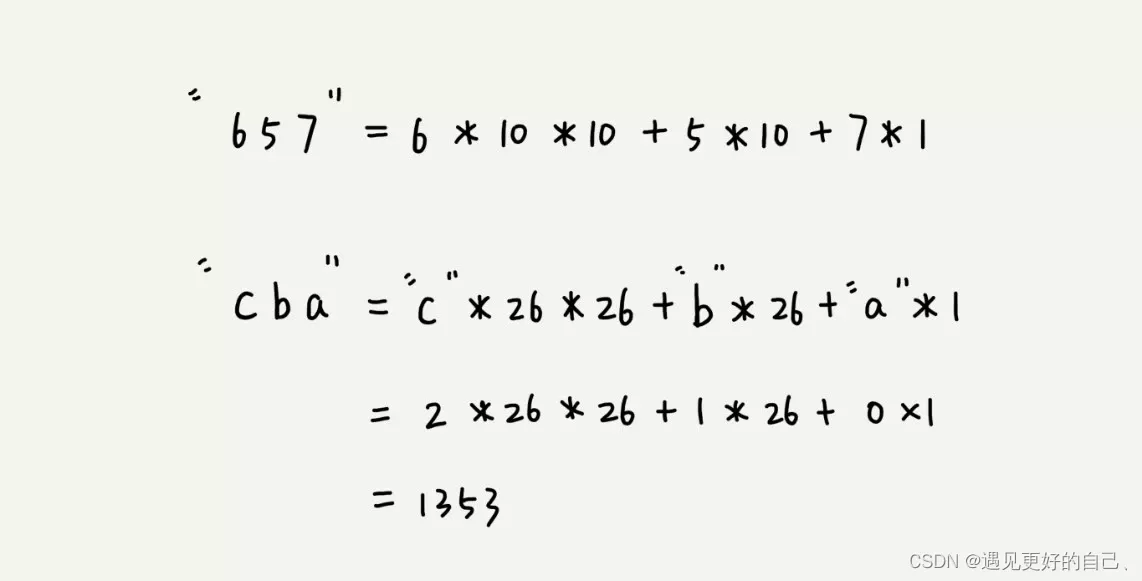文章目录
- 字符串匹配
- 一、基本概念
- 字符串匹配问题
- 符号和术语
- 后缀重叠引理
- 二、朴素字符串匹配算法
- 三、Rabin-Karp算法(字符串Hash算法)
- 进制Hash
- 质数Hash
- 四、利用有限自动机进行字符串匹配
- 有限自动机
- 字符串匹配自动机
- 计算状态转移函数
- 代码
- 五、Knuth-Morris-Pratt算法
- 模式的前缀函数
- 代码
- 六、Z-函数(扩展KMP)
字符串匹配
一、基本概念
字符串匹配问题
假设文本是一个长度为 n n n的数组 T [ 1 … n ] T[1 \ldots n] T[1…n],而模式是一个长度为 m m m的数组 P [ 1 … m ] P[1 \ldots m] P[1…m],其中 m ≤ n m \leq n m≤n,进一步假设 P P P和 T T T的元素都是来自一个有限的字母集 ∑ \sum ∑的字符。数组 T T T和 P P P通常被称为字符串。
如果 0 ≤ s ≤ n − m 0 \leq s \leq n-m 0≤s≤n−m,并且 T [ s + 1 … s + m ] = P [ 1 … m ] T[s+1 \ldots s+m]=P[1 \ldots m] T[s+1…s+m]=P[1…m],那么称模式 P P P在文本 T T T中出现过,且偏移为 s s s。如果 P P P在 T T T中以偏移 s s s出现,那么称 s s s为有效偏移,否则为无效偏移。
字符串匹配问题就是在 T T T中找到 P P P的所有有效偏移 s s s。
符号和术语
- 字符串集合:我们用 ∑ ∗ \sum^{*} ∑∗来表示包含所有有限长度的字符串的集合,该字符串是由字母表 ∑ \sum ∑中的字符串组成。在本文中,我们只考虑有限长度的字符串。长度为 0 0 0的字符串用 ϵ \epsilon ϵ表示,也属于 ∑ ∗ \sum^{*} ∑∗。
- 字符串的长度:一个字符串 T T T的长度用 ∣ T ∣ |T| ∣T∣表示。特别的, ∣ ϵ ∣ = 0 |\epsilon| = 0 ∣ϵ∣=0。
- 连结:两个字符串 x x x和 y y y的连结表示为 x y xy xy,意义为 x x x后接 y y y,长度为 ∣ x ∣ + ∣ y ∣ |x| + |y| ∣x∣+∣y∣。
- 前缀:如果对于三个个字符串 x = w y x=wy x=wy,那么称字符串 w w w是 x x x的前缀,记作 w ⊏ x w \sqsubset x w⊏x,且 ∣ w ∣ ≤ ∣ x ∣ |w| \leq |x| ∣w∣≤∣x∣。
- 后缀:如果对于三个个字符串 x = y w x=yw x=yw,那么称字符串 w w w是 x x x的后缀,记作 w ⊐ x w \sqsupset x w⊐x,且 ∣ w ∣ ≤ ∣ x ∣ |w| \leq |x| ∣w∣≤∣x∣。特别的,空字符串 ϵ \epsilon ϵ是任意一个字符串的前缀和后缀。
后缀重叠引理
假设 x x x, y y y和 z z z满足 x ⊐ z x \sqsupset z x⊐z和 y ⊐ z y \sqsupset z y⊐z。如果 ∣ x ∣ ≤ ∣ y ∣ |x| \leq |y| ∣x∣≤∣y∣,那么 x ⊐ y x \sqsupset y x⊐y,反过来如果 ∣ y ∣ ≤ ∣ x ∣ |y| \leq |x| ∣y∣≤∣x∣,那么 y ⊐ x y \sqsupset x y⊐x。如果 ∣ x ∣ = ∣ y ∣ |x| = |y| ∣x∣=∣y∣,那么 x = y x = y x=y。
为了符号简洁,我们把模式 P [ 1 … m ] P[1 \ldots m] P[1…m]的由 k k k个字符串组成的的前缀 P [ 1 … k ] P[1 \ldots k] P[1…k],记作 P k P_{k} Pk。因此 P 0 = ϵ , P m = P = P [ 1 … m ] P_{0} = \epsilon, P_{m}=P=P[1 \ldots m] P0=ϵ,Pm=P=P[1…m]。与此类似,我们把文本 T T T中由 k k k个字符组成的前缀记作 T k T_{k} Tk。
字符串匹配问题转化为:找到所有的偏移 s ( 0 ≤ s ≤ n − m ) s(0 \leq s \leq n-m) s(0≤s≤n−m),使得 P ⊐ T s + m P \sqsupset T_{s+m} P⊐Ts+m。
二、朴素字符串匹配算法
朴素字符串算法是通过一个循环找到所有的有效偏移,该循环对 n − m + 1 n-m+1 n−m+1个可能的 s s s值进行检测,看是否满足条件 P [ 1 … m ] = T [ s + 1 … s + m ] P[1 \ldots m]=T[s+1 \ldots s+m] P[1…m]=T[s+1…s+m]。
NAIVE-STRING-MATCHER(T,P):n = T.lengthm = P.lengthfor s = 0 to n-m:if P[1...m] = T[s+1 ... s+m]:print "Pattern occurs whit shift",s
伪代码中的循环枚举 s s s的位置,for中的判断隐含了一个循环,这个循环检测偏移 s s s是否为有效偏移。
在最坏情况下,朴素算法的运行时间为 O ( ( n − m + 1 ) m ) O((n-m+1)m) O((n−m+1)m)。如果 m = n / 2 m = n/2 m=n/2,则运行时间为 Θ ( n 2 ) \Theta(n^{2}) Θ(n2)。
我们看到,朴素字符串匹配算法不是解决该问题的最佳过程。是因为当其他无效的 s s s值存在时,他只关心一个有效的 s s s的值,而完全忽略了检测无效的 s s s值的时候所带来的有用信息。例如对于 P = a a a b P=aaab P=aaab并且我们发现 s = 0 s=0 s=0是一个有效的偏移值,由于 T [ 4 ] = b T[4] = b T[4]=b,所以 s = 1 , 2 , 3 s=1,2,3 s=1,2,3都不是有效的。
三、Rabin-Karp算法(字符串Hash算法)
进制Hash
Rabin-Karp算法运用了初等数论的知识,其实就是对字符串进行 H a s h Hash Hash运算,比较每一位上的 H a s h Hash Hash值是否相等即可。
为了便于说明,我们假设 ∑ = { 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 } \sum = \{0,1,2,3,4,5,6,7,8,9\} ∑={0,1,2,3,4,5,6,7,8,9},这样每个字符都是十进制数字。(在通常情况下,可以假定每个字符都是以 d d d为基数表示的数字,其中 ∣ ∑ ∣ = d |\sum| = d ∣∑∣=d),每一个字符串就是相当与一个十进制数,其长度为 k k k。
给定一个模式 P [ 1 … m ] P[1 \ldots m] P[1…m],令 p p p为表示的十进制数。类似的,有字符串 T [ 1 … n ] T[1 \ldots n] T[1…n],假设 t s t_{s} ts表示子串 T [ s + 1 … s + m ] T[s+1 \ldots s+m] T[s+1…s+m]对应的十进制数。当然,只有当 s s s是一个有效偏移的时候, p = t s p = t_{s} p=ts,如果能在时间 Θ ( m ) \Theta(m) Θ(m)内计算出 p p p的值,并且在总时间 Θ ( n − m + 1 ) \Theta(n-m+1) Θ(n−m+1)内计算出所有的 t s t_{s} ts值,那么通过比较 t s t_{s} ts和 p p p的值就可以在时间 Θ ( m ) + Θ ( n − m + 1 ) = Θ ( n ) \Theta(m) + \Theta(n-m+1) = \Theta(n) Θ(m)+Θ(n−m+1)=Θ(n)时间内找到所有的有效偏移。
其实这是一种 H a s h Hash Hash运算,根据霍纳法则,我们可以在规定的时间内计算出 p p p:
p = P [ m ] + 10 ( P [ m − 1 ] + 10 ( P [ m − 2 ] + … + 10 ( P [ 2 ] + 10 P [ 1 ] ) … ) ) p = P[m] + 10(P[m-1] + 10(P[m-2] + \ldots + 10(P[2] + 10P[1]) \ldots )) p=P[m]+10(P[m−1]+10(P[m−2]+…+10(P[2]+10P[1])…))
类似的,我们可以通过规定的时间计算出 t 0 t_{0} t0的值,并且能在 O ( 1 ) O(1) O(1)的时间内利用 t 0 t_{0} t0的值计算出 t 1 t_{1} t1的值,依次类推,总结出递推公式:
t s + 1 = 10 ( t s − 1 0 m − 1 T [ s + 1 ] ) + T [ s + m + 1 ] t_{s+1} = 10(t_{s}-10^{m-1}T[s+1])+T[s+m+1] ts+1=10(ts−10m−1T[s+1])+T[s+m+1]
减去 1 0 m − 1 T [ s + 1 ] 10^{m-1}T[s+1] 10m−1T[s+1],表示减去最高位的数字,乘以十表示将这个数向左移动一位,加上 T [ s + m + 1 ] T[s+m+1] T[s+m+1],表示加上最低位。
预先计算出常数 1 0 m − 1 10^{m-1} 10m−1,可以使用快速幂计算。
到目前为止,我们就始终在回避一个问题,如果 m m m的值过大,则 t i t_{i} ti的值就可能很大,以至于超过了运算的范围,因此我们就需要运用数论的知识,将其进行取模运算。
选定一个素数 q q q,使得 d q dq dq在一个机器字长内,我们就可以进行取余运算:
t s + 1 = ( d ( t s − h T [ s + 1 ] ) + T [ s + m + 1 ] ) m o d q t_{s+1} = (d(t_{s}-hT[s+1])+T[s+m+1]) \mod q ts+1=(d(ts−hT[s+1])+T[s+m+1])modq
其中 d d d为 d d d进制, h h h为 h ≡ d m − 1 m o d q h \equiv d^{m-1} \mod q h≡dm−1modq。
但是这种结果并不是很完美,因为 t s ≡ p m o d q t_{s} \equiv p \mod q ts≡pmodq,并不能说明 t s = p t_{s} = p ts=p,因此,我们还必须仿照朴素算法那样,验证一下这个答案。
如果 q q q是一个素数,并且这个 q q q足够大,这种伪命中点的概率发生的几率很小。
Rabin-Karp算法的期望时间复杂度为 O ( n ) + O ( m ( v + n / q ) ) O(n) + O(m(v+n/q)) O(n)+O(m(v+n/q))。预计较好的情况(有效偏移比较少,素数大, m m m远远小于 n n n)。这个算法的时间复杂度为 O ( n ) O(n) O(n)。
还可以使用链接法或开放寻址法来进行无错Hash。
同时,我们可以定义 h [ 0 ] = s [ 0 ] h[0] = s[0] h[0]=s[0], h [ k ] = ( h [ k − 1 ] A + s [ k ] ) m o d B h[k] = (h[k-1]A + s[k]) \mod B h[k]=(h[k−1]A+s[k])modB,位权 p [ 0 ] = 1 p[0] = 1 p[0]=1, p [ k ] = ( p [ k − 1 ] A ) m o d B p[k] = (p[k-1]A) \mod B p[k]=(p[k−1]A)modB。
这样我们就能在 O ( 1 ) O(1) O(1)的时间内计算出某个子串 S [ a … b ] S[a \ldots b] S[a…b]的hash值 ( h [ b ] − h [ a − 1 ] p [ b − a + 1 ] ) m o d B (h[b]-h[a-1]p[b-a+1]) \mod B (h[b]−h[a−1]p[b−a+1])modB。
质数Hash
如果我们想判断两个单词是不是同体词(即两个字符串每个字母出现的次数都相同,例如eat和ate)。此时我们将每一个字母替换成一个唯一的质数,那么根据算数基本定理,我们就可以把一个字符串看成是一个由多个质数相乘得到的唯一的整数,那么如果两个单词是同体词,那么这个两个Hash值一定相等。
四、利用有限自动机进行字符串匹配
有限自动机
一个有限自动机 M M M是一个五元组 ( Q , q 0 , A , ∑ , δ ) (Q,q_{0},A,\sum,\delta) (Q,q0,A,∑,δ),其中:
- Q Q Q是状态的有限集合
- q 0 ∈ Q q_{0} \in Q q0∈Q是初始状态
- A ⊆ Q A \subseteq Q A⊆Q是一个特殊接受状态的集合
- ∑ \sum ∑是有限输入字母表
- δ \delta δ是一个从 Q × ∑ Q \times \sum Q×∑到 Q Q Q的函数,称为 M M M的转移函数
有限自动机状态开始于 q 0 q_{0} q0,读入一个字符 a a a,则他从状态 q q q变成了状态 δ ( q , a ) \delta(q,a) δ(q,a)。当自动机的状态属于 Q Q Q的时候,我们说自动机接受了迄今为止所有的字符。
有限自动机 M M M引入一个终态函数 ϕ ( w ) \phi(w) ϕ(w),他是一个从 ∑ ∗ \sum^{*} ∑∗到 Q Q Q的一个函数,函数的值为自动机 M M M处理完字符串 w w w之后所处的最终状态。因此当且仅当 ϕ ( w ) ∈ A \phi(w) \in A ϕ(w)∈A的时候, M M M接受字符串 w w w。存在递归定义:
ϕ ( ϵ ) = q 0 ϕ ( w a ) = δ ( ϕ ( w ) , a ) \phi(\epsilon)=q_{0} \\ \phi(wa) = \delta(\phi(w),a) ϕ(ϵ)=q0ϕ(wa)=δ(ϕ(w),a)
字符串匹配自动机
对于给定一个模式 P P P,我们可以进行预处理构造一个有限状态自动机,之后,对于字符串 T T T,就可以在 O ( n ) O(n) O(n)的时间内求出所有的有效偏移。
为了构造自动机,我们要先定义后缀函数 σ ( x ) \sigma(x) σ(x),函数是一个从 ∑ ∗ \sum^{*} ∑∗到 { 0 , 1 , 2 , 3 , … , m } 的 映 射 函 数 \{0,1,2,3,\ldots,m\}的映射函数 {0,1,2,3,…,m}的映射函数:
给定模式 P P P,模式 P P P的后缀函数为
σ ( x ) = max ( k : P k ⊐ x ) \sigma(x)=\max(k:P_{k} \sqsupset x) σ(x)=max(k:Pk⊐x)
也就是说存在一个最大长度的子串,既是 P P P的前缀又是 x x x的后缀,子串的长度就是后缀函数的值。
给定模式 P [ 1 … m ] P[1 \ldots m] P[1…m]对应的字符串匹配自动机为:
- 状态集合 Q Q Q为 { 0 , 1 , 2 , 3 , … , m } \{0,1,2,3,\ldots,m\} {0,1,2,3,…,m}。开始状态 q 0 q_{0} q0为 0 0 0,并且只有状态 m m m是唯一的接受状态。
- 对于任意的状态 q q q和字符 a a a,转移状态函数 δ ( q , a ) \delta(q,a) δ(q,a)的定义为 δ ( q , a ) = σ ( P q a ) \delta(q,a)=\sigma(P_{q}a) δ(q,a)=σ(Pqa)
也就是说,存在有效偏移 s s s,那么 P P P一定是 T s + m T_{s+m} Ts+m的后缀,状态机的状态就是后缀函数的值。并且存在有效偏移 s s s,当且仅当状态 q = m q=m q=m。
状态机维护一个不变式:
ϕ ( T i ) = σ ( T i ) \phi(T_{i}) = \sigma(T_{i}) ϕ(Ti)=σ(Ti)
T i T_{i} Ti表示 T [ 1 … i ] T[1 \ldots i] T[1…i]。

图片中描述了模式 P = a b a b a c a P=ababaca P=ababaca的自动机的 D A G DAG DAG模型,除了这个模型,还有二维表模型。
考虑一下两种情况:
- a = P [ q + 1 ] a=P[q+1] a=P[q+1],此时我们可以放心的把状态转移到 σ ( P q a ) = q + 1 \sigma(P_{q}a)=q+1 σ(Pqa)=q+1,这个状态沿着主轴的方向进行。
- a ≠ P [ q + 1 ] a \neq P[q+1] a=P[q+1],这时我们必须找到一个更小的子串,确保这个子串满足 σ ( P q a ) \sigma(P_{q}a) σ(Pqa)
此时,构造完自动机,我们就可以根据自动机处理文本 T T T,找到状态 q = m q=m q=m的时候,偏移 i − m i-m i−m就是有效偏移。
为了证明有限自动机的正确性,我们首先要说明两个引理。
后缀不等式:对于任意字符串 x x x和字符 a a a, σ ( x a ) ≤ σ ( x ) + 1 \sigma(xa) \leq \sigma(x) + 1 σ(xa)≤σ(x)+1。
也就是说如果字符 a a a正好是下一个字符,等号成立,如果不是,那么后缀不可能再长了。
后缀函数递归定理:对任意字符串 x x x和字符 a a a,若 q = σ ( x ) q=\sigma(x) q=σ(x),则 σ ( x a ) = σ ( P q a ) \sigma(xa)=\sigma(P_{q}a) σ(xa)=σ(Pqa)。
也就是说, P q P_{q} Pq这个后缀已经到了左边界,即从左边界开始求即可。
定理:如果 ϕ \phi ϕ是有限自动机的终态函数,那么 ϕ ( T i ) = σ ( T i ) \phi(T_{i}) = \sigma(T_{i}) ϕ(Ti)=σ(Ti)。
证明对 i i i进行归纳即可。
计算状态转移函数
先确定一个 k k k的上界,然后在缩小范围即可,这种方式效率很低,接下来的 K M P KMP KMP算法可以优化这个思路。
代码
int sp[100][10];int eval(const string & p)
{for(int q = 0; q<=p.size(); q++){for(char a = '0'; a<='9'; a++){int k = q + 1;string x = p.substr(0,q) + a;while(1){bool ok = true;for(int i = x.size() - 1,j=k-1; j>=0; i--,j--){if(p[j] != x[i]){ok = false;break;}}if(ok) break;else k--;}sp[q][a] = k;}}
}void match(const string & t,int end)
{int q = 0;for(int i = 0; i<t.size(); i++){q = sp[q][t[i]];if(q == end) cout << i - end + 1 << endl;}
}int main()
{string p = "01011";string t = "0101111010111010101011111";int end = p.size();eval(p);match(t,end);return 0;
}
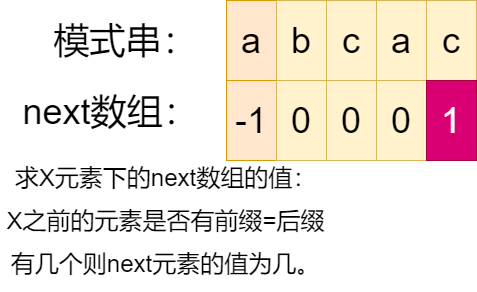
五、Knuth-Morris-Pratt算法
现在来介绍一种线性的字符串匹配算法 K M P KMP KMP算法。和自动机算法相比,他只需要用到一个辅助函数 π \pi π,而且这个函数和字符集无关,不需要遍历字符集。并且在 O ( m ) O(m) O(m)的时间计算出所有的函数值以留备用,在 O ( n ) O(n) O(n)的时间内完成匹配。
模式的前缀函数

面对一个偏移 s s s,匹配长度为 q q q,字符 q + 1 q+1 q+1匹配失败,按照朴素算法,我们应该测试下一个偏移 s + 1 s+1 s+1,但是我们知道,偏移 s + 1 s+1 s+1必然失败,因为 P [ 1 ] P[1] P[1]必然不可能匹配 T [ s + 2 ] T[s+2] T[s+2],可以匹配的最短偏移为 s + 2 s+2 s+2。这个 2 2 2我们可以通过计算前缀函数计算出来。
也就是说,假设模式字符串 P [ 1 … q ] P[1 \ldots q] P[1…q]与文本字符串 T [ s + 1 … s + q ] T[s+1 \ldots s+q] T[s+1…s+q]匹配, s ′ s' s′是最小的偏移量, s ′ > s s' \gt s s′>s,那么对某些 k < q k \lt q k<q满足:
P [ 1 … k ] = T [ s ′ + 1 … s ′ + k ] P[1 \ldots k] = T[s'+1 \ldots s'+k] P[1…k]=T[s′+1…s′+k]
的最小偏移 s ′ s' s′是多少,其中 s ′ + k = s + q s' + k=s+q s′+k=s+q。
这时,我们就需要借助前缀函数 π ( q ) \pi(q) π(q),其值为存在最长的子串,既是 P P P的前缀,又是 P q P_{q} Pq的真后缀。
已知一个模式 P [ 1 … m ] P[1 \ldots m] P[1…m],模式 P P P的前缀函数是函数 π : { 1 , 2 , 3 , 4 , … , m } → { 0 , 1 , … , m − 1 } \pi: \{1,2,3,4,\ldots,m\} \to \{0,1,\ldots,m-1\} π:{1,2,3,4,…,m}→{0,1,…,m−1}的一个函数,满足:
π [ q ] = m a x ( k : k < q ∣ P k ⊐ P q ) \pi[q]=max(k: k < q | P_{k} \sqsupset P_{q}) π[q]=max(k:k<q∣Pk⊐Pq)
之后我们就可以利用辅助函数匹配文本。
代码
#include <bits/stdc++.h>using namespace std;#define FR freopen("in.txt", "r", stdin)typedef long long ll;int nxt[1000005];void buildNext(string &p)
{nxt[0] = 0;for (int i = 1; i < p.size(); i++){nxt[i] = nxt[i - 1];while (p[nxt[i]] != p[i] && nxt[i] > 0){nxt[i] = nxt[nxt[i] - 1];}nxt[i] = p[nxt[i]] == p[i] ? nxt[i] + 1 : 0;}
}void kmp(string &t, string &p)
{int ti = 0;int pi = 0;while (ti < t.size()){if (t[ti] == p[pi]){if (pi == p.size() - 1){cout << ti + 2 - p.size() << endl;pi = nxt[pi];}else{pi++;}ti++;}else if (pi == 0){ti++;}else{pi = nxt[pi - 1];}}
}int main()
{string s1, s2;cin >> s1 >> s2;buildNext(s2);kmp(s1, s2);for (int i = 0; i < s2.size(); i++){cout << nxt[i] << " ";}return 0;
}
六、Z-函数(扩展KMP)
定义 Z Z Z数组 Z [ i ] Z[i] Z[i]为,字符串 s [ 0 … i − 1 ] s[0 \ldots i - 1] s[0…i−1]和字符串 s [ i … n − 1 ] s[i \ldots n-1] s[i…n−1]的最长公共前缀长度。特别的 Z [ 0 ] = 0 Z[0] = 0 Z[0]=0。
我们有线性时间 O ( n ) O(n) O(n)的算法来计算Z-函数,叫做Z-算法。