文章目录
- 1. 基本用法
- 1.1 添加依赖
- 1.2 创建DataSource
- 1.3 获取连接
- 2. 源码分析
- 2.1 API
- 2.2 Pool
- 2.2.1 获取连接
- 2.2.2 添加连接
- 2.2.3 维护连接
- 2.3 metrics
- 2.3.1 dropwizard
- 2.3.2 prometheus
- 3. 最佳实践
HikariCP是一个快速,简单可靠的JDBC连接池,SpringBoot2.0开始默认使用该数据库连接池。JDBC连接池是一种管理多连接请求的机制,换句话说,它对数据库连接进行缓存,促使连接的重用。
1. 基本用法
要使用HikariCP, 先要添加依赖,再创建DataSource来获得连接,如果现在的DataSource过期了,也可以关闭它。
1.1 添加依赖
如果不是基于SpringBoot2.0及以上版本开发应用,就需要显式添加HikariCP依赖,以HikariCP 2.6.1为例:
<dependency><groupId>com.zaxxer</groupId><artifactId>HikariCP</artifactId><version>2.6.1</version>
</dependency>
1.2 创建DataSource
HikariCP作为数据库连接池,提供实现了DataSource接口的HikariDataSource,使用HikariCP要构造HikariDataSource实例,有许多方式可以创建:
- 默认构造器,需要额外设置配置
HikariDataSource ds = new HikariDataSource();
ds.setJdbcUrl("jdbc:mysql://localhost:3306/test");
ds.setUsername("root");
ds.setPassword("123456");
- 通过
HikariConfig初始化:
HikariConfig config = new HikariConfig();
config.setJdbcUrl("jdbc:mysql://localhost:3306/test");
config.setUsername("root");
config.setPassword("123456");
HikariDataSource ds = new HikariDataSource(config);
1.3 获取连接
然后可以通过ds获取Connection实例,并用它执行查询:
try (Connection connection = ds.getConnection();Statement st = connection.createStatement()
) {ResultSet rs = st.executeQuery("show tables;");if (rs.next()) {System.out.println(rs.getString(1));}
} catch (Exception e) {// handle exception
}
// if any required
ds.close();
2. 源码分析
HikariCP主要包含3大组件,如下所示:
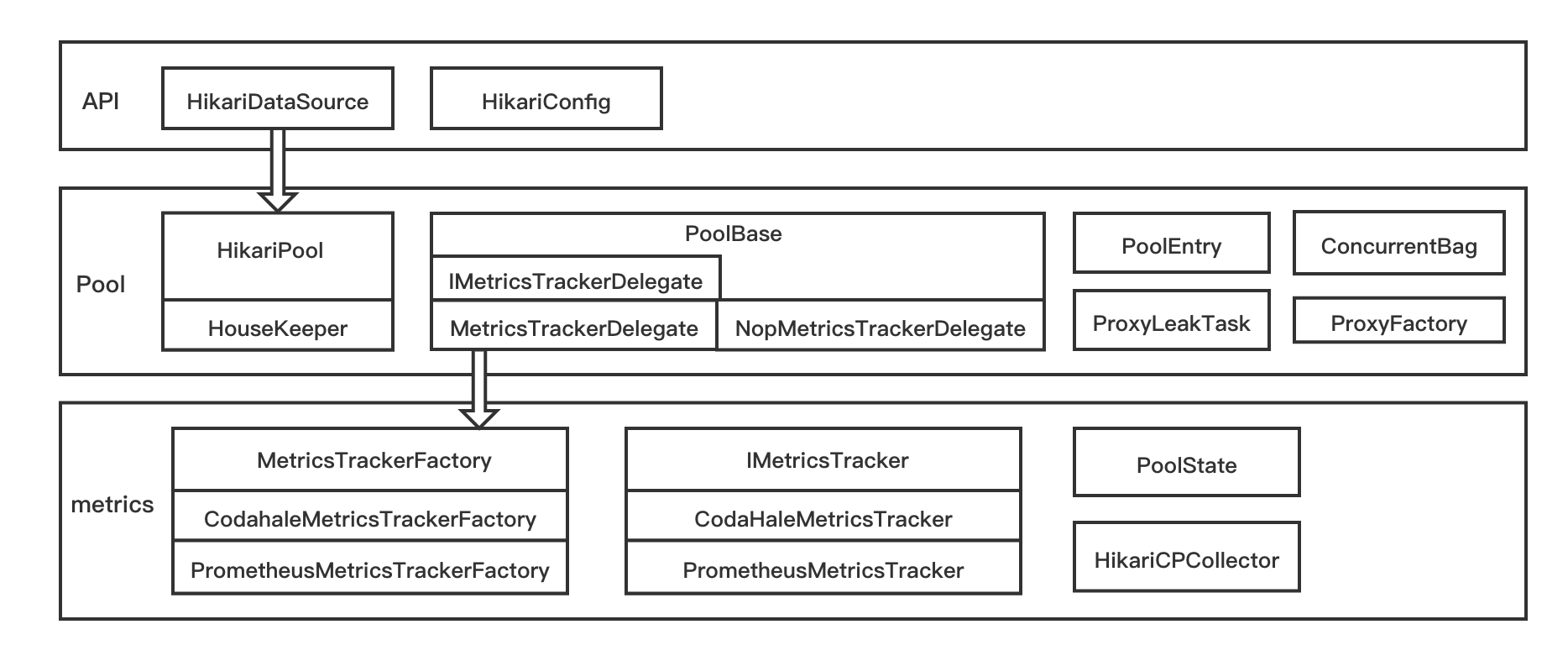
- API
HikariDataSource代表目标DataSourceHikariConfig用于进行数据库相关的配置
- Pool
HikariPool提供基本的连接池行为,维护一定数量的连接并关闭过期的连接ConcurrentBag将新建的元素保存在sharedList中,将返还的连接保存在threadList中PoolEntry在ConcurrentBag中用于维护真实Connection实例
- metrics
MetricsTrackerFactory接口来创建IMetricsTrackerIMetricsTracker接口来记录连接相关的metrics
各模块主要的UML如下图所示:

2.1 API
HikariDataSource是HikariCP的核心api, 它实现了DataSource并且有2个构造器:
// fastPathPool由final修饰且可以被缓存,在带参构造器中被创建private final HikariPool fastPathPool;// pool由volatile修饰,懒加载且每次都要从内存中读取private volatile HikariPool pool;// 默认构造器,使用 setters 配置改连接池public HikariDataSource(){// HikariConfig构造器super();// 不带预加载连接池fastPathPool = null;}public HikariDataSource(HikariConfig configuration){// 验证并拷贝现在的池的配置configuration.validate();configuration.copyState(this);LOGGER.info("{} - Starting...", configuration.getPoolName());// eager loading pool// 预加载连接池pool = fastPathPool = new HikariPool(this);LOGGER.info("{} - Start completed.", configuration.getPoolName());}
默认构造器只能初始化基本的配置,需要通过set()方法配置其他参数,它使用懒加载方式创建HikariPool。相反,带参构造器会创建fastPathPool来直接使用(预加载)。
HikariDataSource实现了DataSource接口的getConnection()方法,并且从fastPathPool或pool中获取真实的连接:
public Connection getConnection() throws SQLException{// 关闭的连接池不能再获取连接if (isClosed()) {throw new SQLException("HikariDataSource " + this + " has been closed.");}// 从预加载的fastPathPool中获取if (fastPathPool != null) {return fastPathPool.getConnection();}// 从懒加载的pool中获取// See http://en.wikipedia.org/wiki/Double-checked_locking#Usage_in_JavaHikariPool result = pool;if (result == null) {synchronized (this) {result = pool;// 双重检查poolif (result == null) {// 验证配置validate();LOGGER.info("{} - Starting...", getPoolName());try {// 创建HikariPool实例pool = result = new HikariPool(this);}catch (PoolInitializationException pie) {if (pie.getCause() instanceof SQLException) {throw (SQLException) pie.getCause();}else {throw pie;}}LOGGER.info("{} - Start completed.", getPoolName());}}}// 从HikariPool中获取连接return result.getConnection();}
我们从fastPathPool或pool中获取连接,fastPathPool可能比pool更快一点因为它可以被缓存,所以更建议用带参构造器初始化HikariDataSource.
2.2 Pool
HikariPool是主要的连接池类,为HikariCP提供基本的连接池行为。
/* HikariPool主要字段 */// LinkedBlockingQueue用于保存添加连接的任务private final Collection<Runnable> addConnectionQueue;// 线程池用于执行添加连接的任务private final ThreadPoolExecutor addConnectionExecutor;// 线程池用于执行关闭过期连接的任务private final ThreadPoolExecutor closeConnectionExecutor;// connectionBag维护PoolEntry内部真实的连接private final ConcurrentBag<PoolEntry> connectionBag;// 线程池用于关闭和维护最少idle连接private ScheduledExecutorService houseKeepingExecutorService;
ConcurrentBag是核心集合,并发维护连接池内所有连接。
/* HikariPool主要字段 */// sharedList所有线程都可以borrow的连接private final CopyOnWriteArrayList<T> sharedList;// threadList只能被当前线程borrow的连接private final ThreadLocal<List<Object>> threadList;// listener 就是HikariPool实例private final IBagStateListener listener;// 等待获取连接的数量private final AtomicInteger waiters;// 阻塞队列保存PoolEntry实例private final SynchronousQueue<T> handoffQueue;
2.2.1 获取连接
HikariPool用getConnection()方法获取连接,它从connectionBag中借已经存在的PoolEntry来获取连接:
public Connection getConnection(final long hardTimeout) throws SQLException{// 限制请求的连接的最大数量suspendResumeLock.acquire();final long startTime = currentTime();try {long timeout = hardTimeout;PoolEntry poolEntry = null;try {do {// 从connectionBag中借已经存在的PoolEntrypoolEntry = connectionBag.borrow(timeout, MILLISECONDS);if (poolEntry == null) {break; // We timed out... break and throw exception}final long now = currentTime();// 如果被除掉或长时间空闲,则关闭连接if (poolEntry.isMarkedEvicted() || (elapsedMillis(poolEntry.lastAccessed, now) > ALIVE_BYPASS_WINDOW_MS && !isConnectionAlive(poolEntry.connection))) {closeConnection(poolEntry, "(connection is evicted or dead)"); // Throw away the dead connection (passed max age or failed alive test)timeout = hardTimeout - elapsedMillis(startTime);}else {// 从poolEntry中获取代理连接metricsTracker.recordBorrowStats(poolEntry, startTime);return poolEntry.createProxyConnection(leakTask.schedule(poolEntry), now);}} while (timeout > 0L);metricsTracker.recordBorrowTimeoutStats(startTime);}catch (InterruptedException e) {// 借poolEntry时报错,将它回收到池中if (poolEntry != null) {poolEntry.recycle(startTime);}Thread.currentThread().interrupt();throw new SQLException(poolName + " - Interrupted during connection acquisition", e);}}finally {// 释放semophoresuspendResumeLock.release();}throw createTimeoutException(startTime);}
ConcurrentBag提供borrow()方法从并发集合中获取PoolEntry元素,先尝试从threadList中获取,再尝试从sharedList中获取,如果还没有获取到,则尝试从handoffQueue中获取:
public T borrow(long timeout, final TimeUnit timeUnit) throws InterruptedException{// Try the thread-local list first// 先从thread-local里尝试获取final List<Object> list = threadList.get();for (int i = list.size() - 1; i >= 0; i--) {final Object entry = list.remove(i);@SuppressWarnings("unchecked")final T bagEntry = weakThreadLocals ? ((WeakReference<T>) entry).get() : (T) entry;if (bagEntry != null && bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {return bagEntry;}}// 否则,查看 shared list ... 然后从handoff队列中获取final int waiting = waiters.incrementAndGet();try {for (T bagEntry : sharedList) {if (bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {// 可能拿了别的等待者的连接,需要添加一个bagif (waiting > 1) {// listener是HikariPool实例listener.addBagItem(waiting - 1);}return bagEntry;}}listener.addBagItem(waiting);timeout = timeUnit.toNanos(timeout);do {final long start = currentTime();// 从队列中获取bagEntry, 最长等待timtout时间final T bagEntry = handoffQueue.poll(timeout, NANOSECONDS);if (bagEntry == null || bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {return bagEntry;}timeout -= elapsedNanos(start);} while (timeout > 10_000);return null;}finally {waiters.decrementAndGet();}}
HikariPool通过connectionBag将poolEntry回收到连接池中:
void recycle(final PoolEntry poolEntry){metricsTracker.recordConnectionUsage(poolEntry);connectionBag.requite(poolEntry);}
ConcurrentBag提供requite()方法将借来的poolEntry返回到集合中,如果有等待获取连接则直接将bagEntry放到handoffQueue中,否则把bagEntry放到threadLocalList中:
public void requite(final T bagEntry){bagEntry.setState(STATE_NOT_IN_USE);for (int i = 0; waiters.get() > 0; i++) {// 有等待连接的,直接把bagEntry放到handoffQueue中用于borrowif (bagEntry.getState() != STATE_NOT_IN_USE || handoffQueue.offer(bagEntry)) {return;}else if ((i & 0x100) == 0x100) {parkNanos(MICROSECONDS.toNanos(10));}else {yield();}}// 没有等待着,将poolEntry返回到threadLocalListfinal List<Object> threadLocalList = threadList.get();threadLocalList.add(weakThreadLocals ? new WeakReference<>(bagEntry) : bagEntry);}
2.2.2 添加连接
HikariPool通过addBagItem()方法添加PoolEntry实例,它会提交一个POOL_ENTRY_CREATOR任务:
public Future<Boolean> addBagItem(final int waiting){final boolean shouldAdd = waiting - addConnectionQueue.size() >= 0; // Yes, >= is intentional.if (shouldAdd) {return addConnectionExecutor.submit(POOL_ENTRY_CREATOR);}return CompletableFuture.completedFuture(Boolean.TRUE);}
POOL_ENTRY_CREATOR是一个Callable<Boolean>实例,call()方法用于向connectionBag添加PoolEntry实例:
public Boolean call() throws Exception{long sleepBackoff = 250L;while (poolState == POOL_NORMAL && shouldCreateAnotherConnection()) {// 创建新的PoolEntry实例final PoolEntry poolEntry = createPoolEntry();if (poolEntry != null) {connectionBag.add(poolEntry);LOGGER.debug("{} - Added connection {}", poolName, poolEntry.connection);if (loggingPrefix != null) {logPoolState(loggingPrefix);}return Boolean.TRUE;}// 不能从数据库中获取连接,重试quietlySleep(sleepBackoff);sleepBackoff = Math.min(SECONDS.toMillis(10), Math.min(connectionTimeout, (long) (sleepBackoff * 1.5)));}// 连接池 suspend 或者关闭或者到了最大连接数return Boolean.FALSE;}
HikariPool使用createPoolEntry()方法创建PoolEntry, 它会创建新的连接来构造PoolEntry,如果设置了连接的maxLifetime,还会配置任务来移除该连接:
private PoolEntry createPoolEntry(){try {// 用新的连接创建新的poolEntryfinal PoolEntry poolEntry = newPoolEntry();final long maxLifetime = config.getMaxLifetime();if (maxLifetime > 0) {// 方差最大为maxlifetime的2.5%final long variance = maxLifetime > 10_000 ? ThreadLocalRandom.current().nextLong( maxLifetime / 40 ) : 0;final long lifetime = maxLifetime - variance;// 调度任务再lifetime之后执行移除连接poolEntry.setFutureEol(houseKeepingExecutorService.schedule(() -> {if (softEvictConnection(poolEntry, "(connection has passed maxLifetime)", false /* not owner */)) {// 尝试添加PoolEntry因为当前连接被移除了addBagItem(connectionBag.getWaitingThreadCount());}},lifetime, MILLISECONDS));}return poolEntry;}catch (Exception e) {if (poolState == POOL_NORMAL) {LOGGER.debug("{} - Cannot acquire connection from data source", poolName, (e instanceof ConnectionSetupException ? e.getCause() : e));}return null;}}
ConcurrentBag用add()方法把新建的PoolEntry加到bag里给其他人borrow, 它先把bagEntry加到sharedList中,如果现在有waiters则将bagEntry放到handoffQueue以供borrow:
public void add(final T bagEntry){if (closed) {LOGGER.info("ConcurrentBag has been closed, ignoring add()");throw new IllegalStateException("ConcurrentBag has been closed, ignoring add()");}// 将bagEntry加到sharedList中sharedList.add(bagEntry);// 如果有等待连接的,自旋直到有一个线程需要bagEntrywhile (waiters.get() > 0 && !handoffQueue.offer(bagEntry)) {yield();}}
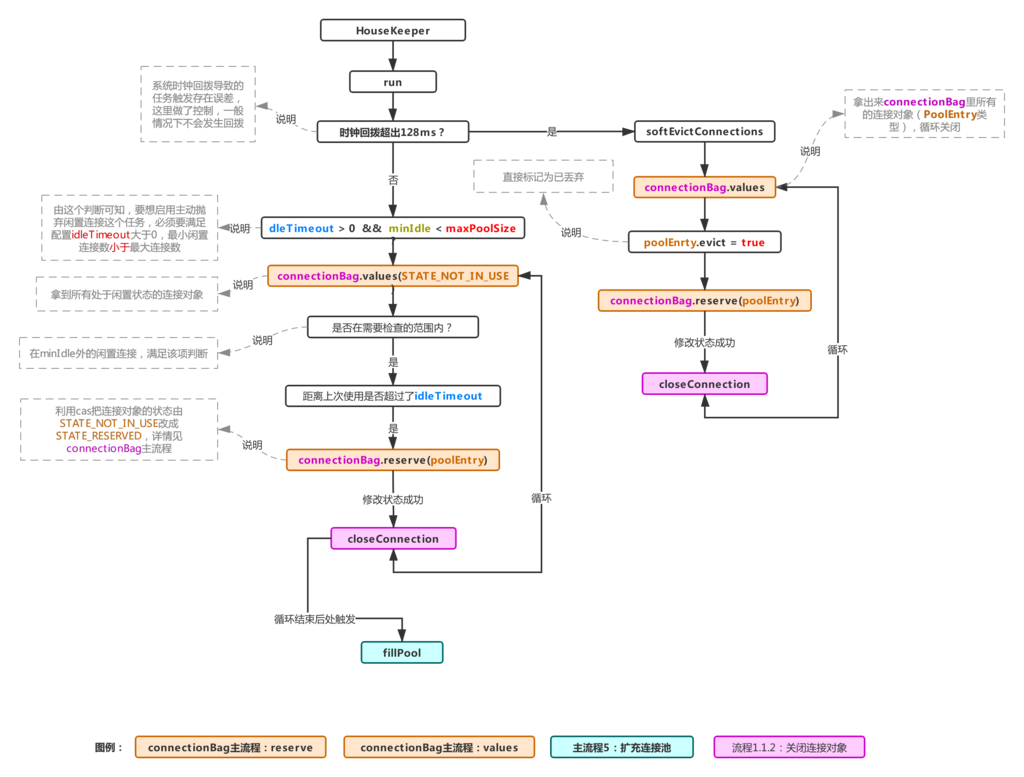
2.2.3 维护连接
HikariPool用HouseKeeper关闭和维护最小空闲连接,它实现了Runnable()方法,如果设置了idleTimeout并且minimumIdle数量比maximunPoolSize小,则限制空闲超时的连接,为了避免改行为,可以不设置minimumIdle和idleTimeout。
// 上次执行house keeping的时间戳private volatile long previous = plusMillis(currentTime(), -HOUSEKEEPING_PERIOD_MS);public void run(){try {// 更新超时时间以防其被改变connectionTimeout = config.getConnectionTimeout();validationTimeout = config.getValidationTimeout();leakTask.updateLeakDetectionThreshold(config.getLeakDetectionThreshold());final long idleTimeout = config.getIdleTimeout();final long now = currentTime();// 检查逆向时间,根据NTP规范允许+128msif (plusMillis(now, 128) < plusMillis(previous, HOUSEKEEPING_PERIOD_MS)) {// 当前时间戳比预期小LOGGER.warn("{} - Retrograde clock change detected (housekeeper delta={}), soft-evicting connections from pool.",poolName, elapsedDisplayString(previous, now));previous = now;softEvictConnections();fillPool();return;}else if (now > plusMillis(previous, (3 * HOUSEKEEPING_PERIOD_MS) / 2)) {// 前向的时钟不需要移除连接,这只是加速了连接退出的时间LOGGER.warn("{} - Thread starvation or clock leap detected (housekeeper delta={}).", poolName, elapsedDisplayString(previous, now));}previous = now;String afterPrefix = "Pool ";if (idleTimeout > 0L && config.getMinimumIdle() < config.getMaximumPoolSize()) {// 关闭空闲超时的连接,如果空闲超时被设置// 且minimumIdle比maximumPoolSize小logPoolState("Before cleanup ");afterPrefix = "After cleanup ";connectionBag.values(STATE_NOT_IN_USE).stream().sorted(LASTACCESS_REVERSE_COMPARABLE).skip(config.getMinimumIdle()).filter(p -> elapsedMillis(p.lastAccessed, now) > idleTimeout).filter(connectionBag::reserve).forEachOrdered(p -> closeConnection(p, "(connection has passed idleTimeout)"));}logPoolState(afterPrefix);fillPool(); // 尝试维护最小连接数量}catch (Exception e) {LOGGER.error("Unexpected exception in housekeeping task", e);}}
HikariPool提供fillPool()方法维护最小空闲连接数量,它会计算需要添加的连接数并且提交POOL_ENTRY_CREATOR的任务:
private synchronized void fillPool(){final int connectionsToAdd = Math.min(config.getMaximumPoolSize() - getTotalConnections(), config.getMinimumIdle() - getIdleConnections())- addConnectionQueue.size();for (int i = 0; i < connectionsToAdd; i++) {addConnectionExecutor.submit((i < connectionsToAdd - 1) ? POOL_ENTRY_CREATOR : POST_FILL_POOL_ENTRY_CREATOR);}}
2.3 metrics
HikariCP提供dropwizard和prometheus两种metrics, 顶层接口MetricsTrackerFactory 用于创建IMetricsTracker, 后者用于记录连接的创建,获取,使用和超时情况。
2.3.1 dropwizard
CodahaleMetricsTrackerFactory创建CodaHaleMetricsTracker实例,它保存了以下metrics:
private final String poolName;// 相关的metricsprivate final Timer connectionObtainTimer;private final Histogram connectionUsage;private final Histogram connectionCreation;private final Meter connectionTimeoutMeter;// registry用于注册metricsprivate final MetricRegistry registry;// 其他metrics的名称private static final String METRIC_CATEGORY = "pool";private static final String METRIC_NAME_WAIT = "Wait";private static final String METRIC_NAME_USAGE = "Usage";private static final String METRIC_NAME_CONNECT = "ConnectionCreation";private static final String METRIC_NAME_TIMEOUT_RATE = "ConnectionTimeoutRate";private static final String METRIC_NAME_TOTAL_CONNECTIONS = "TotalConnections";private static final String METRIC_NAME_IDLE_CONNECTIONS = "IdleConnections";private static final String METRIC_NAME_ACTIVE_CONNECTIONS = "ActiveConnections";private static final String METRIC_NAME_PENDING_CONNECTIONS = "PendingConnections";
2.3.2 prometheus
PrometheusMetricsTrackerFactory创建PrometheusMetricsTracker实例,它保存了以下metrics:
// hikaricp_connection_timeout_count{poolName}private final Counter.Child connectionTimeoutCounter;// hikaricp_connection_acquired_nanos{poolName}private final Summary.Child elapsedAcquiredSummary;// hikaricp_connection_usage_millis{poolName}private final Summary.Child elapsedBorrowedSummary;// hikaricp_connection_creation_millis{poolName}private final Summary.Child elapsedCreationSummary;// hikaricp_connection_timeout_countprivate final Counter ctCounter;// hikaricp_connection_acquired_nanosprivate final Summary eaSummary;// hikaricp_connection_usage_millisprivate final Summary ebSummary;// hikaricp_connection_creation_millisprivate final Summary ecSummary;private final Collector collector;
3. 最佳实践
有一些HikariCP的最佳实践:
- 通过
HikariDataSource(HikariConfig config)构造器创建HikariDataSource
它会检查配置并且提前初始化连接池,且fastPathPool可以被缓存获得更好的性能。 - 以固定大小的池运行
不设置minimumIdle和idleTimeout,然后连接池不需要关闭长时间空闲的连接。 - 配置合理的
maximumPoolSize
主要取决于处理请求的QPS,每条请求的处理时间以及数据库服务器的CPU核心数。







![[数据仓库]分层概念,ODS,DM,DWD,DWS,DIM的概念](https://img-blog.csdnimg.cn/img_convert/523af9b199c957a94f22907cc0df07b1.png)
