点击上方“大话coding”,选择“星标”公众号
重磅干货,第一时间送达
大家好,我是小轩
这两天整理了在数据分析中常见的5种存储格式
内容比较多,只是简要整理,仅供大家学习和选择
后面会对使用到的数据存储方式进行详细介绍
csv / txt / json
hdf
npy / npz / memmap
joblib
sequenceFile
Avro
Parquet
Orc
csv / txt / json
TXT文本储存:
方便,但不利于检索
CSV(逗号分隔值)是一种纯文本文件格式,用于存储表格数据(例如电子表格或数据库)
文件的每一行都称为记录。
JSON文件储存:
结构化程度非常高
对象和数组:
一切都是对象
对象:
使用{}包裹起来的内容,
{key1:value1, key2:value2, …}
类似于python中的字典数组:
使用[]包裹起来的内容[“java”, “javascript”, “vb”, …]hdf
HDF 是用于存储和分发科学数据的一种自我描述、多对象文件格式。
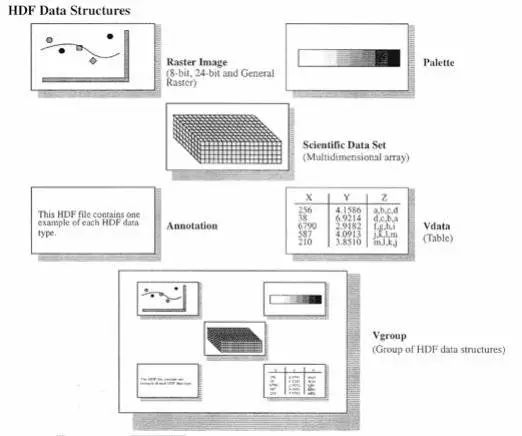
为什么创建HDF?
在不同的机器上生成和处理数据文件,各式各样的软件包被用来多种处理文件,同时也与其他使用不同机器和软件的人共享数据文件,这些文件也许包含不同类型的信息,这些文件也许概念上有关但在实质上却不同。HDF就是为了解决这些问题诞生的。
npy / npz / memmap
说到这三个,就必须了解NumPy
什么是NumPy呢?
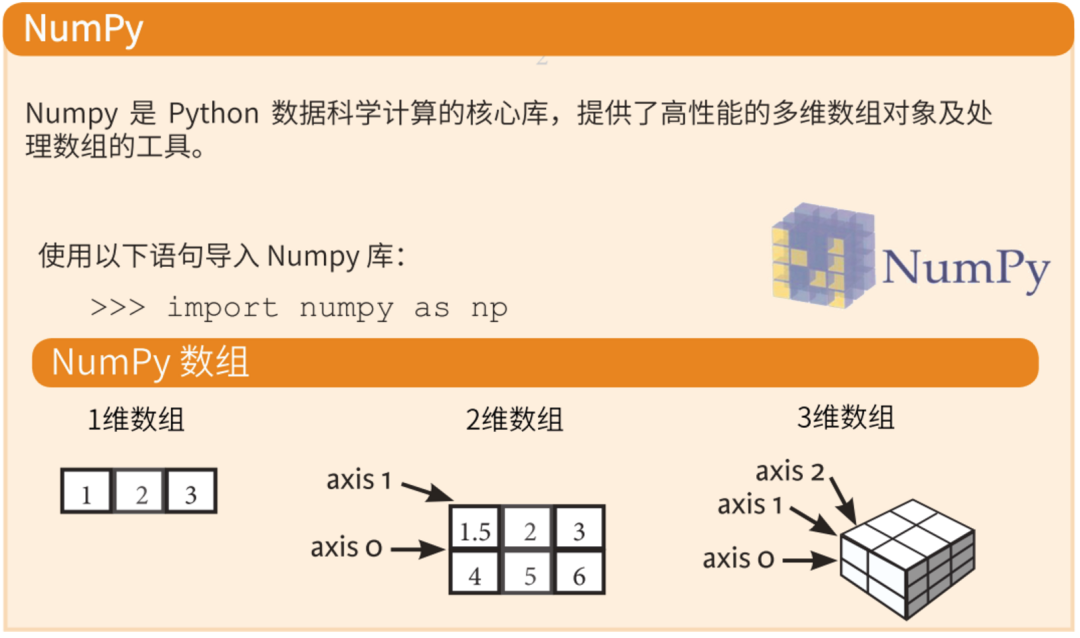
NumPy是一个功能强大的Python库,可以帮助程序员轻松地进行数值计算。
numpy专用的二进制类型:npy和npz
如果将特征和数据处理为Numpy格式,则可以考虑存储为Numpy中的npy或npz格式。
存储类型:矩阵
读取速度:较快
使用场景:文件存储
npy文件:
以二进制的方式存储文件,在二进制文件第一行以文本形式保存了数据的元信息(ndim,dtype,shape等),可以用二进制工具查看内容。
np.load()和np.save()是读写磁盘数组数据的两个重要函数。使用时数组会以未压缩的原始二进制格式保存在扩展名为.npy的文件中。
import numpy as nparr=np.arange(6)
np.save('wzx',arr)print(np.load('wzx.npy'))npz文件:
以压缩打包的方式存储文件,可以用压缩软件解压。
使用np.savez()函数可以将多个数组保存到同一个文件中。读取.npz文件时使用np.load()函数,返回的是一个类似于字典的对象,因此可以通过数组名作为关键字对多个数组进行访问。
import numpy as npa = np.arange(5)
b = np.arange(6)
c = np.arange(7)
np.savez('wzx', a, b, c_array=c) # c_array是数组c的命名data = np.load('wzx.npz')print('arr_0 : ', data['arr_0'])
print('arr_1 : ', data['arr_1'])
print('c_array : ', data['c_array'])memmap
NumPy实现了一个类似于ndarray的memmap对象,它允许将大文件分成小段进行读写,而不是一次性将整个数组读入内存。
memmap也拥有跟普通数组一样的方法,因此,基本上只要是能用于ndarray的算法就也能用于memmap。
存储类型:矩阵
读取速度:适中
使用场景:大文件存储
import numpy as np
a = np.random.randint(0, 10, (3, 4), dtype=np.int32)
print(a)
a.tofile("haha.bin")
b = np.memmap("haha.bin", dtype=np.int32, shape=(3, 4))
print(b)
b[0, 0] = 100
del b # 关闭文件,自动调用数组的finalize函数
b = np.memmap("haha.bin", dtype=np.int32, shape=(3, 4))
print(b)joblib
Joblib是一组用于在Python中提供轻量级流水线的工具。
在训练模型后将模型保存的方法,以免下次重复训练。可以使用sklearn内部的joblib
joblib更适合大数据量的模型,且只能往硬盘存储,不能往字符串存储
from sklearn.externals import joblib
joblib.dump(clf,'filename.pkl')
clf=joblib.load('filename.pkl')
补充,也可以使用pickle
import pickle
s=pickle.dumps(model)
f=open("model.pkl",'w')
f.write(s)
f.close()
f=open("model.pkl",'r')
model=pickle.loads(f.read())
model.predict(X)sequenceFile
什么是sequenceFile?
sequenceFile文件是Hadoop用来存储二进制形式的[Key,Value]对而设计的一种平面文件(Flat File)。
可以把SequenceFile当做是一个容器,把所有的文件打包到SequenceFile类中可以高效的对小文件进行存储和处理。
SequenceFile文件并不按照其存储的Key进行排序存储,SequenceFile的内部类Writer提供了append功能。
SequenceFile中的Key和Value可以是任意类型Writable或者是自定义Writable。
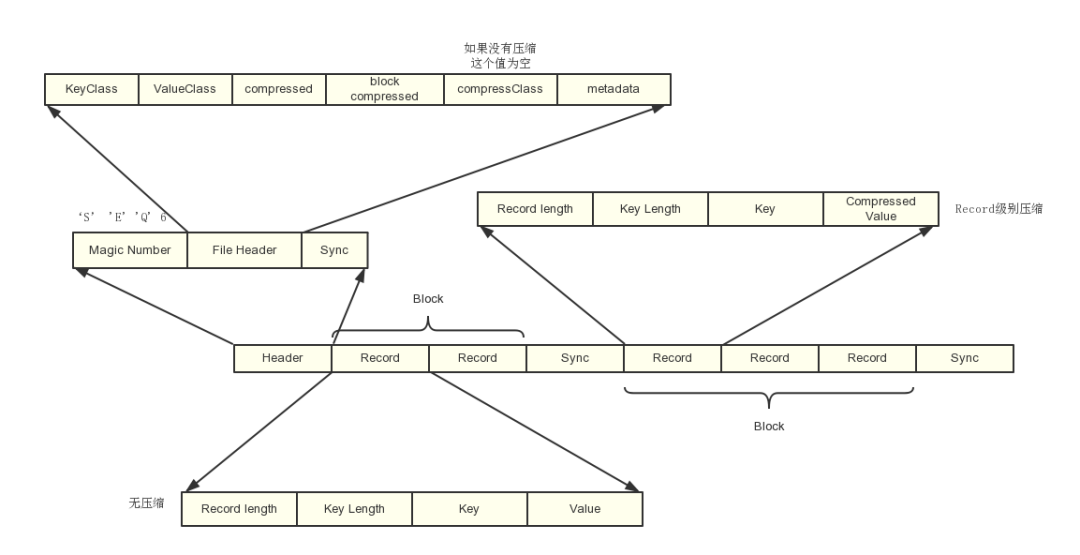
相比于text格式的文件,SequenceFile可以存储key-value格式的消息,方便mapreduce引擎处理数据
支持record级别的压缩和block级别的压缩
文件是分块的,因此是可分割的。支持mapreduce的split输入
Avro
Avro的模式主要由JSON对象来表示,它可能会有一些特定的属性,用来描述某种类型(Type)的不同形式。
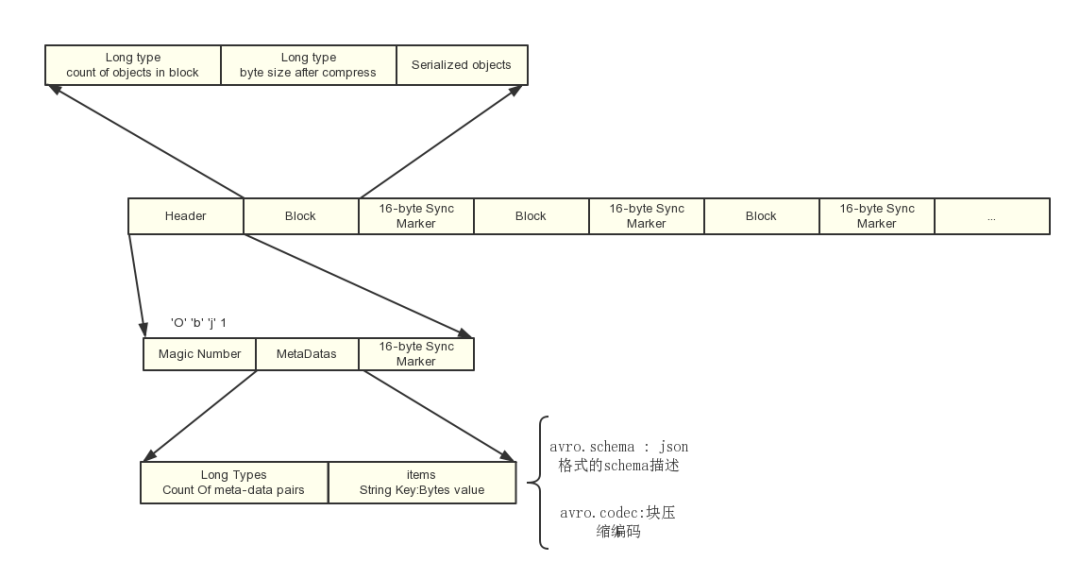
Avro支持八种基本类型(Primitive Type)和六种混合类型(Complex Type)。基本类型可以由JSON字符串来表示。每种不同的混合类型有不同的属性(Attribute)来定义,有些属性是必须的,有些是可选的,如果需要的话,可以用JSON数组来存放多个JSON对象定义。
Avro支持两种序列化编码方式:二进制编码和JSON编码。使用二进制编码会高效序列化,并且序列化后得到的结果会比较小;而JSON一般用于调试系统或是基于WEB的应用。
avro存储格式应用场景很多,比如hive、mongodb等
Parquet
Parquet是一个基于列式存储的文件格式,它将数据按列划分进行存储。Parquet官网上的文件格式介绍图:
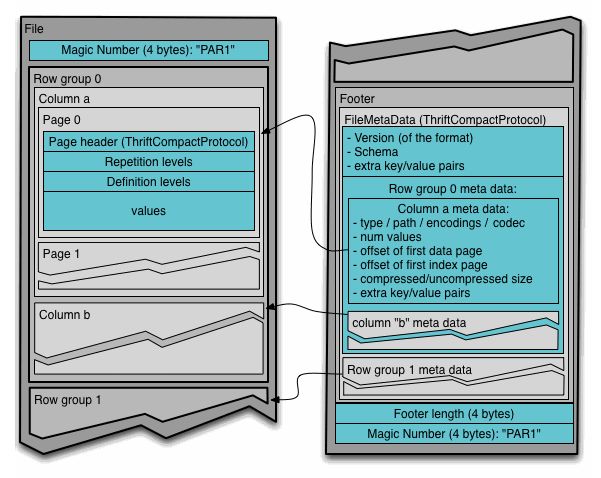
parquet应用场景也很多,比如hbase
Parquet 的存储模型主要由行组(Row Group)、列块(Column Chuck)、页(Page)组成。
行组,Row Group:Parquet 在水平方向上将数据划分为行组,默认行组大小与 HDFS Block 块大小对齐,Parquet 保证一个行组会被一个 Mapper 处理。
列块,Column Chunk:行组中每一列保存在一个列块中,一个列块具有相同的数据类型,不同的列块可以使用不同的压缩。
页,Page:Parquet 是页存储方式,每一个列块包含多个页,一个页是最小的编码的单位,同一列块的不同页可以使用不同的编码方式。
Orc
Orc也是一个列式存储格式,产生自Apache Hive,用于降低Hadoop数据存储空间和加速Hive查询速度。
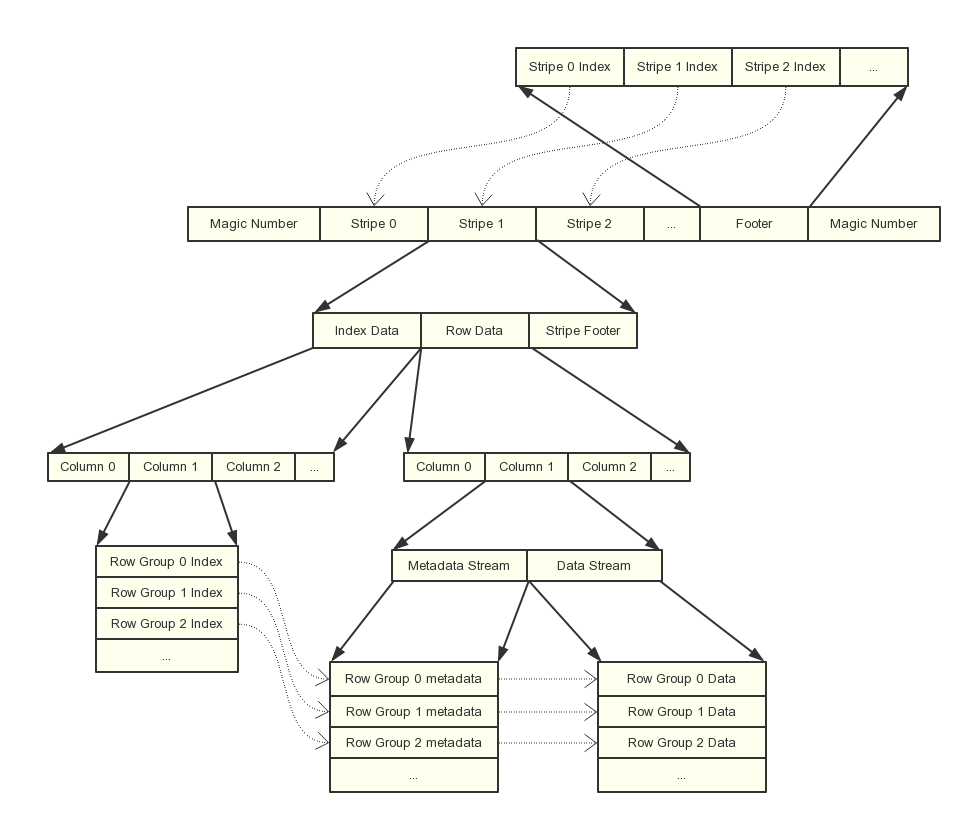
和Parquet的设计类似,也是将行分成多个组,然后组内按列存储,之后再对列进行分割。orc 的 Stripe 对应parquet的 Row Group,row Group 对应的是 parquet的 page
ORC文件是自描述的,它的元数据使用Protocol Buffers序列化
除了基本类型以外,还支持更复杂的数据结构,如LIST、STRUCT、MAP和UNION类型。
Parquet、Avro、ORC格式对比
相同点
1. 基于Hadoop文件系统优化出的存储结构
2. 提供高效的压缩
3. 二进制存储格式
4. 文件可分割,具有很强的伸缩性和并行处理能力
5. 使用schema进行自我描述
6. 属于线上格式,可以在Hadoop节点之间传递数据
不同点
1. 行式存储or列式存储:Parquet和ORC都以列的形式存储数据,而Avro以基于行的格式存储数据。就其本质而言,面向列的数据存储针对读取繁重的分析工作负载进行了优化,而基于行的数据库最适合于大量写入的事务性工作负载。
2. 压缩率:基于列的存储区Parquet和ORC提供的压缩率高于基于行的Avro格式。
3. 可兼容的平台:ORC常用于Hive、Presto;Parquet常用于Impala、Drill、Spark、Arrow;Avro常用于Kafka、Druid。
4. 不同的案例和应用场景选择合适的存储格式,可以提升存储和读取的效率。