本文下面所有的Python基础都有详细的配套教程以及源码,都已经打包好上传到百度云了,链接在文章结尾处!
扫码此处领取大家自行获取即可~~~

1.爬虫的过程分析
当人类去访问一个网页时,是如何进行的?
①打开浏览器,输入要访问的网址,发起请求。
②等待服务器返回数据,通过浏览器加载网页。
③从网页中找到自己需要的数据(文本、图片、文件等等)。
④保存自己需要的数据。
对于爬虫,也是类似的。它模仿人类请求网页的过程,但是又稍有不同。
首先,对应于上面的①和②步骤,我们要利用python实现请求一个网页的功能。
其次,对应于上面的③步骤,我们要利用python实现解析请求到的网页的功能。最后,对于上面的④步骤,我们要利用python实现保存数据的功能。
因为是讲一个简单的爬虫嘛,所以一些其他的复杂操作这里就不说了。下面,针对上面几个功能,逐一进行分析。
2.如何用python请求一个网页
作为一门拥有丰富类库的编程语言,利用python请求网页完全不在话下。这里推荐一个非常好用的第三方类库requests。
2.1 requests
2.1.1 安装方式
打开终端或者cmd,在里面输入以下指令并回车
pip3 install requests
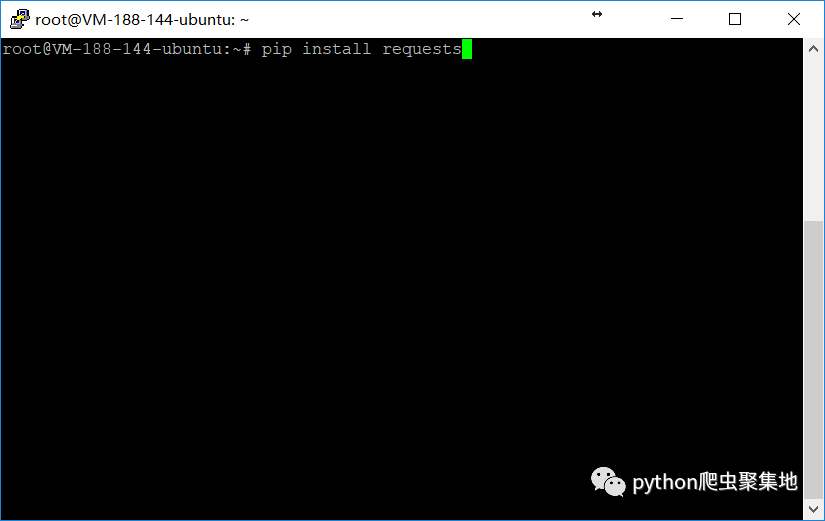
一般不会出什么问题,如果下载太慢,是因为pip使用的源服务器在国外,可以设置pip使用国内镜像源,设置方法可以参考PyPI使用国内源。
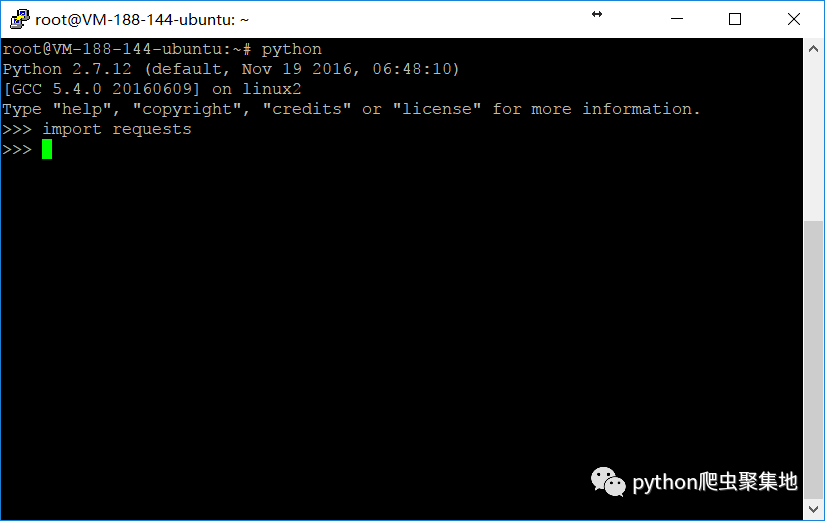
2.1.2 测试是否安装成功
在命令行中输入python,敲击回车,进入python交互环境。在里面输入以下代码并回车:
import requests
如果不报错,就安装成功了,如下图:
2.2 使用requests请求网页
打开pycharm,创建一个项目,嗯,随便取个名字吧。
创建成功后,再创建一个py文件,用来写代码。嗯,再随便取个名字= =教程(二)的2.2,那就spider_2_2_2吧。
在里面输入以下代码:
#coding=utf-8import requestsresp=requests.get('https://www.baidu.com') #请求百度首页print(resp) #打印请求结果的状态码print(resp.content) #打印请求到的网页源码
对上面的代码进行以下简单的分析:
我是用的是python2.7,第1行到第4行,都是为了将字符编码设置为utf8。
第2行:引入requests包。
第4行:使用requests类库,以get的方式请求网址https://www.baidu.com,并将服务器返回的结果封装成一个对象,用变量resp来接收它。第5行:一般可以根据状态码来判断是否请求成功,正常的状态码是200,异常状态码就很多了,比如404(找不到网页)、301(重定向)等。
第6行:打印网页的源码。注意,只是源码。不像是浏览器,在获取到源码之后,还会进一步地取请求源码中引用的图片等信息,如果有JS,浏览器还会执行JS,对页面显示的内容进行修改。使用requests进行请求,我们能够直接获取到的,只有最初始的网页源码。也正是因为这样,不加载图片、不执行JS等等,爬虫请求的速度会非常快。
代码很短吧?一行就完成了请求,可以,这很python。
现在,运行一下代码看看吧。

箭头指向的是状态码,可以看到,200,请求正常。
被圈起来是网页的源码。
3.如何用python解析网页源码
网页源码我们拿到了,接下来就是要解析了。python解析网页源码有很多种方法,比如BeautifulSoup、正则、pyquery、xpath等。这里我简单介绍一下。
3.1 网页源码解析器
3.1.1 BeautifulSoup
这是我比较推荐的一款解析器,简单易用,容易理解。
但是使用bs4还需要安装另一个类库lxml,用来代替bs4默认的解析器。之所以这样做,是因为默认的那个实在太慢了,换用了lxml后,可以大幅度提升解析速度。
3.1.1.1 安装
命令行中输入以下指令并回车,安装bs4:
pip3 install beautifulsoup4
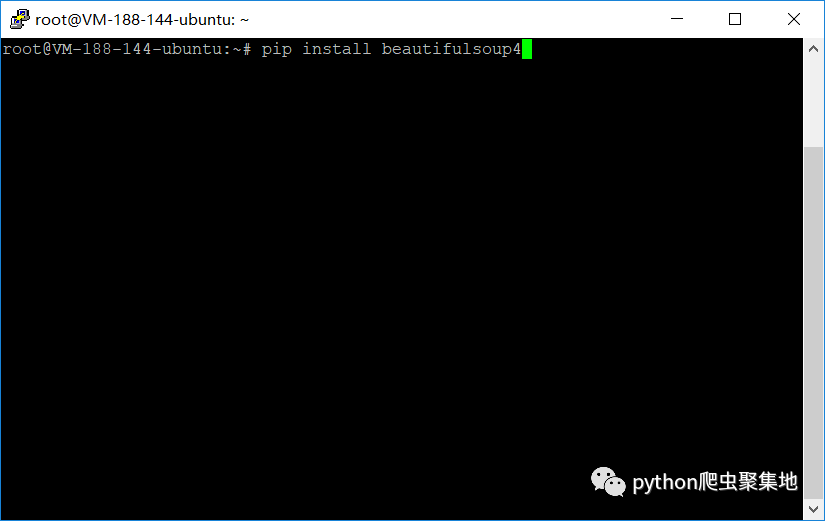
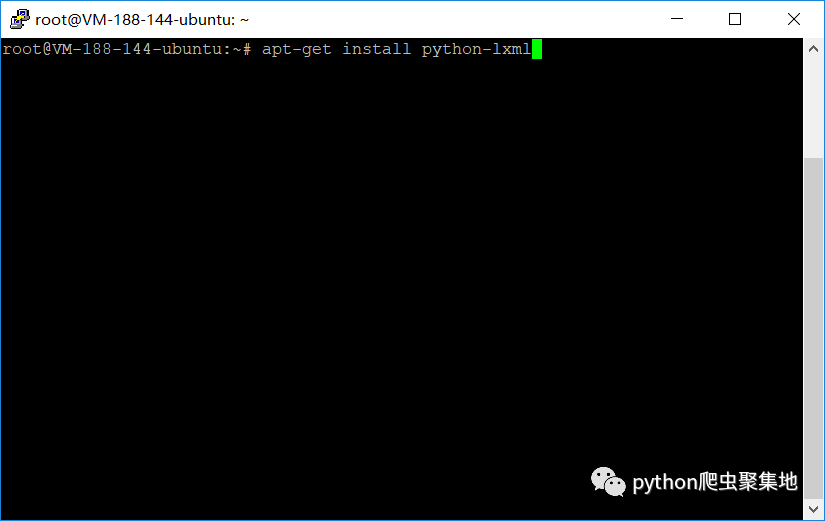
使用pip直接安装lxml会出错,所以要用些特别的方法。Windows用户的话,去百度搜一下lxml在Windows环境下的安装方法,网上有很多,我就不多说了(主要是嫌麻烦= =)。Ubuntu用户就很方便了,在终端里面输入以下指令并回车就行了:
apt-get install python-lxml
3.1.1.2 测试是否安装成功
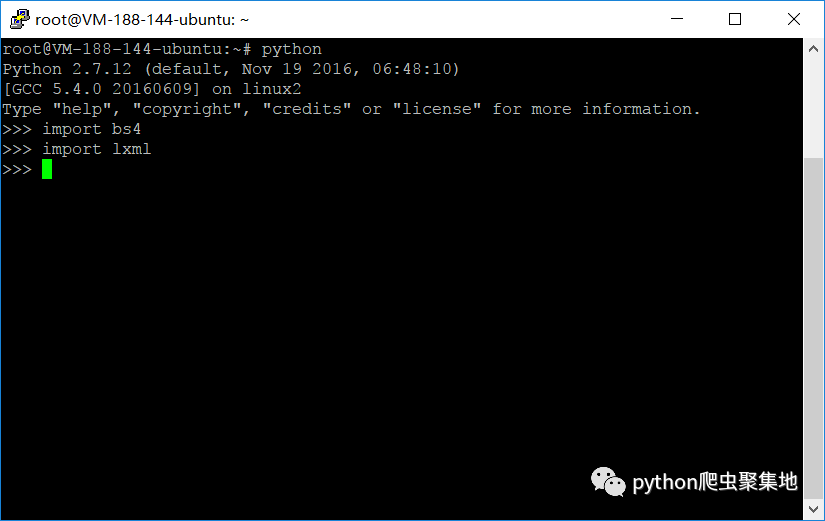
进入python交互环境,引用bs4和lxml类库,不报错即安装成功。
import bs4import lxml
3.1.2 正则
这个不用安装,标准库里带的就有。
正则的优点:①速度快 ②能够提取有些解析器提取不到的数据
正则的缺点:①不够直观,很难从面向对象的角度来考虑数据的提取 ②你得会写正则表达式
教程就不放了,善用百度嘛。正则一般用来满足特殊需求、以及提取其他解析器提取不到的数据,正常情况下我会用bs4,bs4无法满足就用正则。
当然了,如果你喜欢,全部用正则解析也是没问题的,你喜欢就好= =。
3.1.3 pyquery
这个解析器的语法和jQuery很相似,所以写过jQuery的同学用起来可能比较容易上手。国内有个dalao写的爬虫框架pyspider用的就是这个解析器。
如果没用过jQuery,那就在bs4和pyquery两个里面选一个学吧,一般情况下会一个就够了。
3.1.3.1 安装
pip3 install pyquery
3.1.3.2 测试
import pyquery
3.2 使用BeautifulSoup+lxml解析网页源码
接着上面的代码来,我们使用BeautifulSoup+lxml解析请求到的网页源码。
从百度的首页,可以通过点击跳转到很多其他页面,比如说下面圈起来的,点击都会跳转到新的页面:
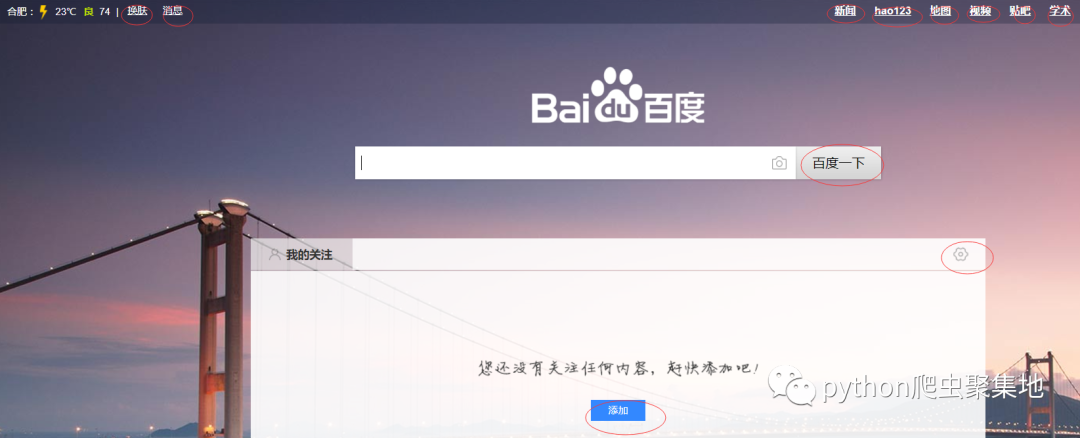
现在,我们想要用python获得从百度能够跳转到的页面的链接,该怎么做?
代码很简单,接着上面的写:
#coding=utf-8import requestsfrom bs4 import BeautifulSoupresp=requests.get('https://www.baidu.com') #请求百度首页print(resp) #打印请求结果的状态码print(resp.content) #打印请求到的网页源码bsobj=BeautifulSoup(resp.content,'lxml') #将网页源码构造成BeautifulSoup对象,方便操作a_list=bsobj.find_all('a') #获取网页中的所有a标签对象for a in a_list: print(a.get('href')) #打印a标签对象的href属性,即这个对象指向的链接地址首先,第3行,引入我们解析时要使用的类库,beautifulsoup4。
第9行,将网页的源码转化成了BeautifulSoup的对象,这样我们可以向操作DOM模型类似地去操作它。
第10行,从这个BeautifulSoup对象中,获取所有的a标签对象(大家应该知道a标签对象是什么吧,网页中的链接绝大多数都是a对象实现的),将他们组成一个列表,也就是a_list。
第11、12行,遍历这个列表,对于列表中的每一个a标签对象,获取它的属性href的值(href属性记录一个a标签指向的链接地址)。获取一个标签对象的属性,可以使用get(‘xx’)方法,比如a_tag是一个a标签对象,获取它的href的值,就是a_tag.get('href'),获取它的class信息可以用a_tag.get('class'),这将返回一个修饰该标签的class列表。
运行一下,可以看到,打印出了很多链接。

这是个简单的例子,介绍如何开始一个简单爬虫,不涉及复杂操作(复杂的后面会上小项目,会介绍)。关于beautifulsoup的详细用法,请自行百度。
3.3 简单的保存数据的方法
保存数据的方法大概可以分为几类:保存文本、保存二进制文件(包括图片)、保存到数据库。保存二进制文件和保存到数据库后面会具体说,这里简单讲一下怎么保存到文本。
python里面操作文本相当的简单。现在,我将刚才提取出来的链接保存到一个名称为url.txt的文本里面去,将上面的代码稍作修改。
#coding=utf-8import requestsfrom bs4 import BeautifulSoupresp=requests.get('https://www.baidu.com') #请求百度首页print(resp) #打印请求结果的状态码print(resp.content) #打印请求到的网页源码bsobj=BeautifulSoup(resp.content,'lxml') #将网页源码构造成BeautifulSoup对象,方便操作a_list=bsobj.find_all('a') #获取网页中的所有a标签对象text='' # 创建一个空字符串for a in a_list: href=a.get('href') #获取a标签对象的href属性,即这个对象指向的链接地址 text+=href+'\n' #加入到字符串中,并换行with open('url.txt','w') as f: #在当前路径下,以写的方式打开一个名为'url.txt',如果不存在则创建 f.write(text) #将text里的数据写入到文本中代码中注释写得很清楚了,就不多做解释了。值得一提的是,使用with…as…来打开文件,在操作完成后,会自动关闭文件,不用担心忘记关闭文件了,超级好用啊!
运行一下代码,可以发现,当前路径下多了个名为url.txt的文件。
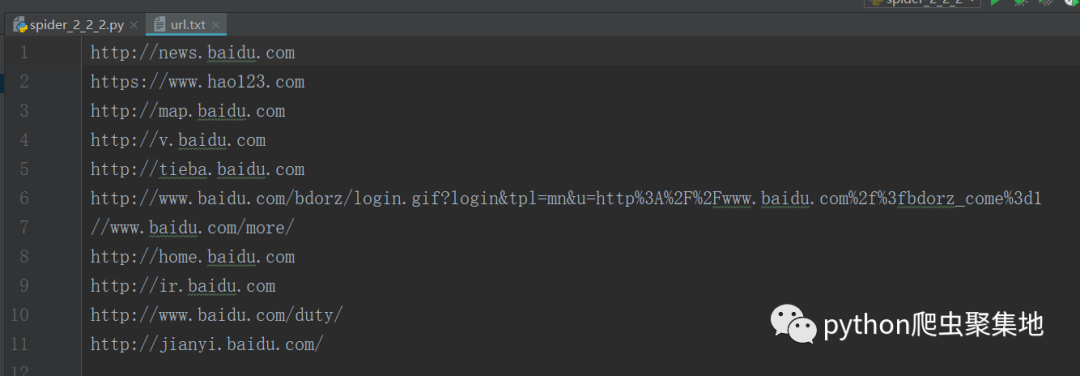
打开后,能够看到我们刚才提取出来的url。
4.更多
虽然东西不多,但是写了挺长时间的。因为平时在一边上课,一边实习,时间真的不多,抽着时间一点点写的。后面我尽量加快速度写吧,当然了,尽量嘛,写得慢了的话……你顺着网线过来打我呀~
本文上面所有的爬虫项目都有详细的配套教程以及源码,都已经打包好上传到百度云了,链接在文章结尾处!
扫码此处领取大家自行获取即可~~~