文章目录
- 前言
- 一、学习爬虫前所需掌握的内容
- 二、爬取数据
- 2.1 如何存储数据
- 2.2 获取html网络数据
- 2.3 获取json网络数据
- 2.4 获取图片数据
- 三、提取数据
- 3.1 提取百度热搜信息
- 3.2 提取豆瓣同城近期活动信息
前言
第一次接触爬虫,这篇博客用于记录学习的过程,将持续进行更新与修正,希望大家指正错误。本文所学习的案例为:爬取豆瓣电影的评分、评价等信息,进行数据分析。
一、学习爬虫前所需掌握的内容
我们进入豆瓣官网,我现在们想要爬取电影的评分、评价等信息。
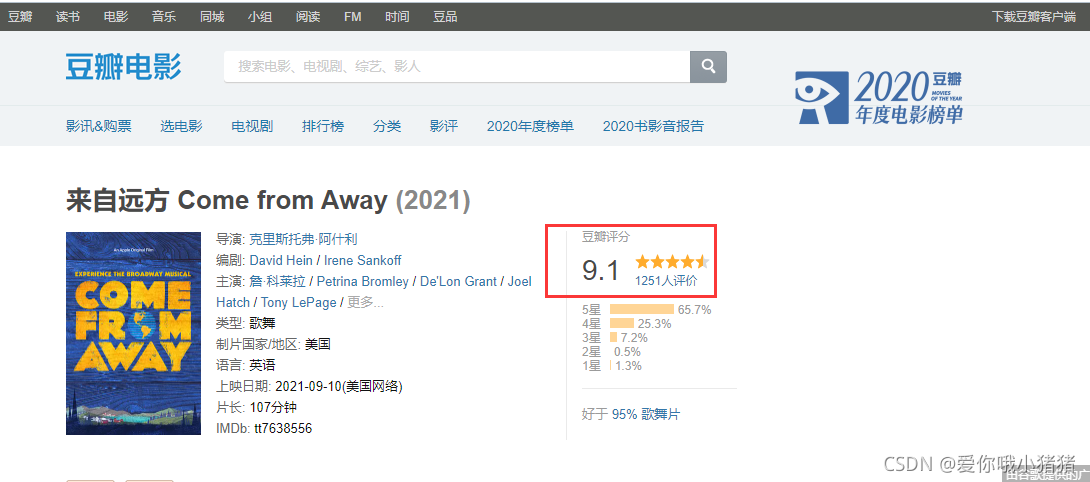
提取这些信息用处很大,例如对于评价信息,可以提取里面的关键词等信息,并进行分析做一个词云图。
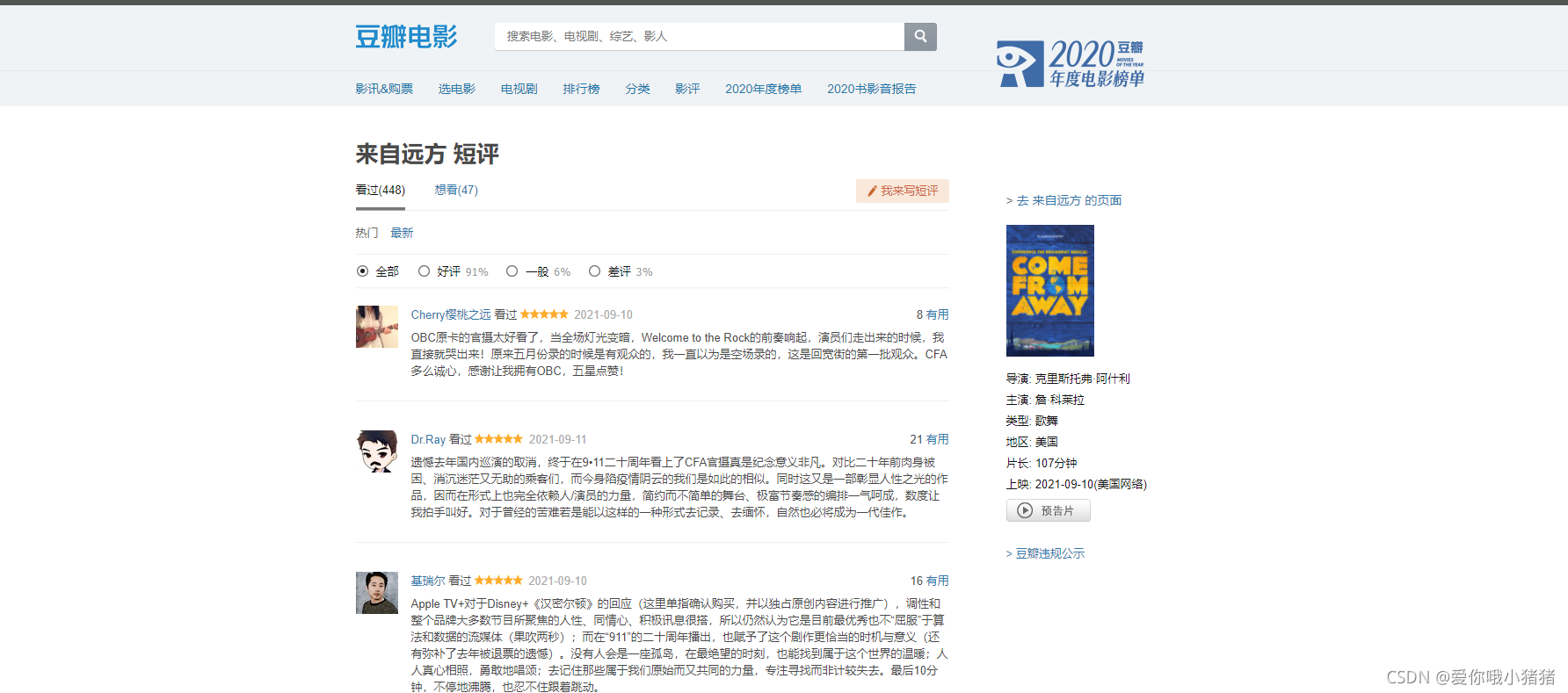
如果我们需要爬取这些信息,则需要以下基础:
①会使用Python完成相关代码
②会分析html
③会使用csv文件、sql存储数据
二、爬取数据
2.1 如何存储数据
由于是入门,我们使用csv文件存储数据,csv又叫逗号分隔符。使用csv文件存储文件的相关代码如下所示:
import csv # 利用csv模块完成数据读取与存储的相关操作# 新建一个list,存储一些信息
goods = [[1, 'jack', 18],[2, 'Lucy', 19],[3, 'Lily', 18],[4, 'Tom', 20]]# 正常使用open步骤如下:即首先创建文件流,然后进行操作,最后关闭文件流。
# f = open('persons.csv')
# ......
# f.close()
# 但是有时候会忘记关闭文件流,导致资源浪费,所以可以使用with。
# 在with的缩进里面执行文件相关操作,当超出with的缩进时,资源自动释放。# 默认的文件读写模式为 文本模式 t
# 写入所有图片、音乐、视频 mode='wb'
# 写入普通文本 mode='wt'# Windows系统写入内容时,具有内容的各行之间会出现空白行,所以需要加上newline=''。具体原因参见博客中的链接# 写内容到文件中
with open('persons.csv', mode='wt', newline='') as f:w_file = csv.writer(f) # 将f管道升级为csv管道w_file.writerows(goods) # 写入内容print('写入完毕')# 读取文件中的内容
with open('persons.csv', mode='r') as f:r_file = csv.reader(f)for row in r_file:print(row)
Windows系统的用户有一些需要注意的地方,即写入数据到csv文件里时会出现空行,具体原因参见:关于python中csv模块writerows()功能写入二维列表数据时会出现空行的一点思考
2.2 获取html网络数据
获取网络数据需要使用request模块,官方文档链接:request官方文档
现在我们需要了解浏览器的开发者工具,因为通过开发者工具可以查看请求和响应的详细信息。我们在浏览器页面右键点击,选择检查元素。
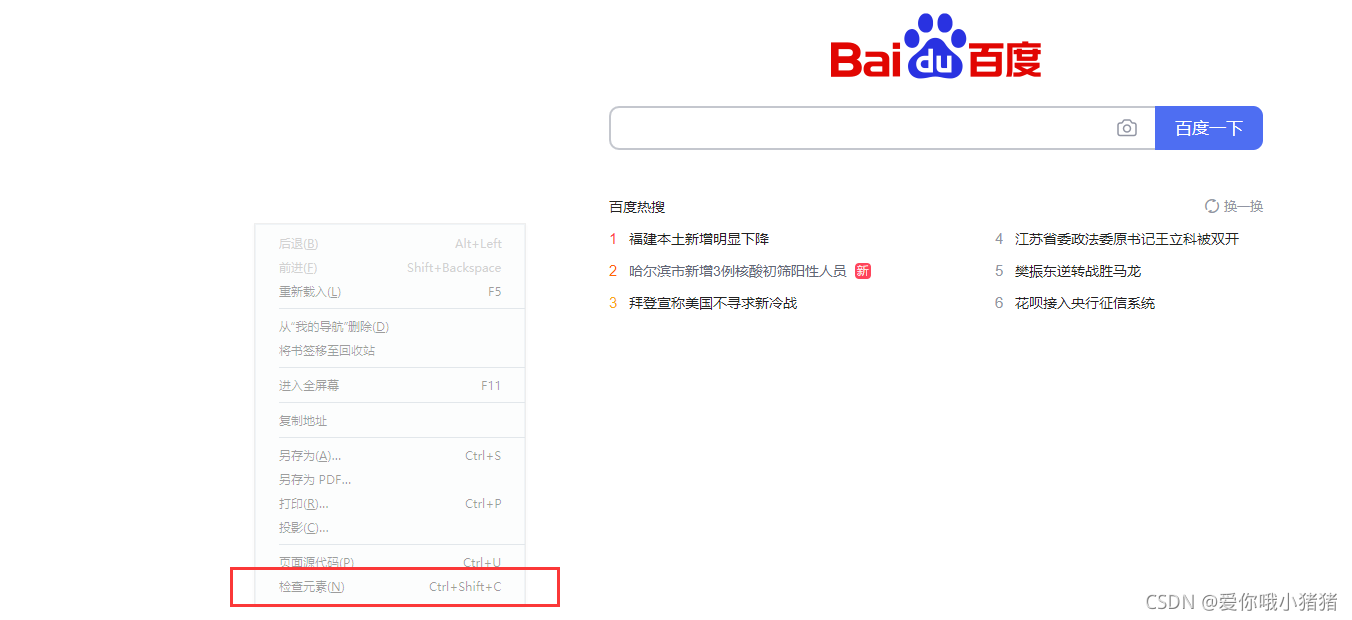
接着便会弹出以下界面,其中Element便是html代码。
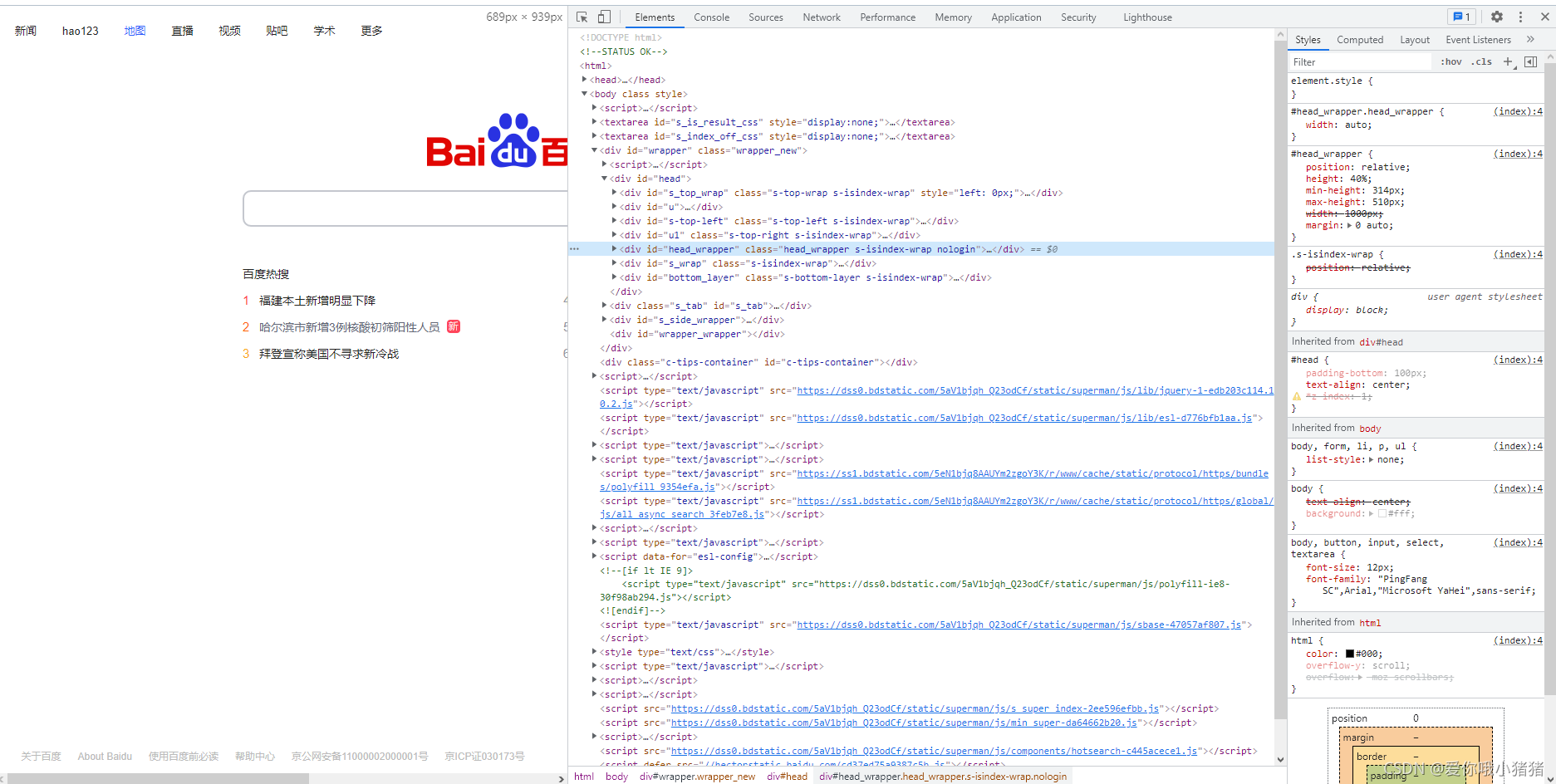
我们选择Network,查看响应的相关信息。
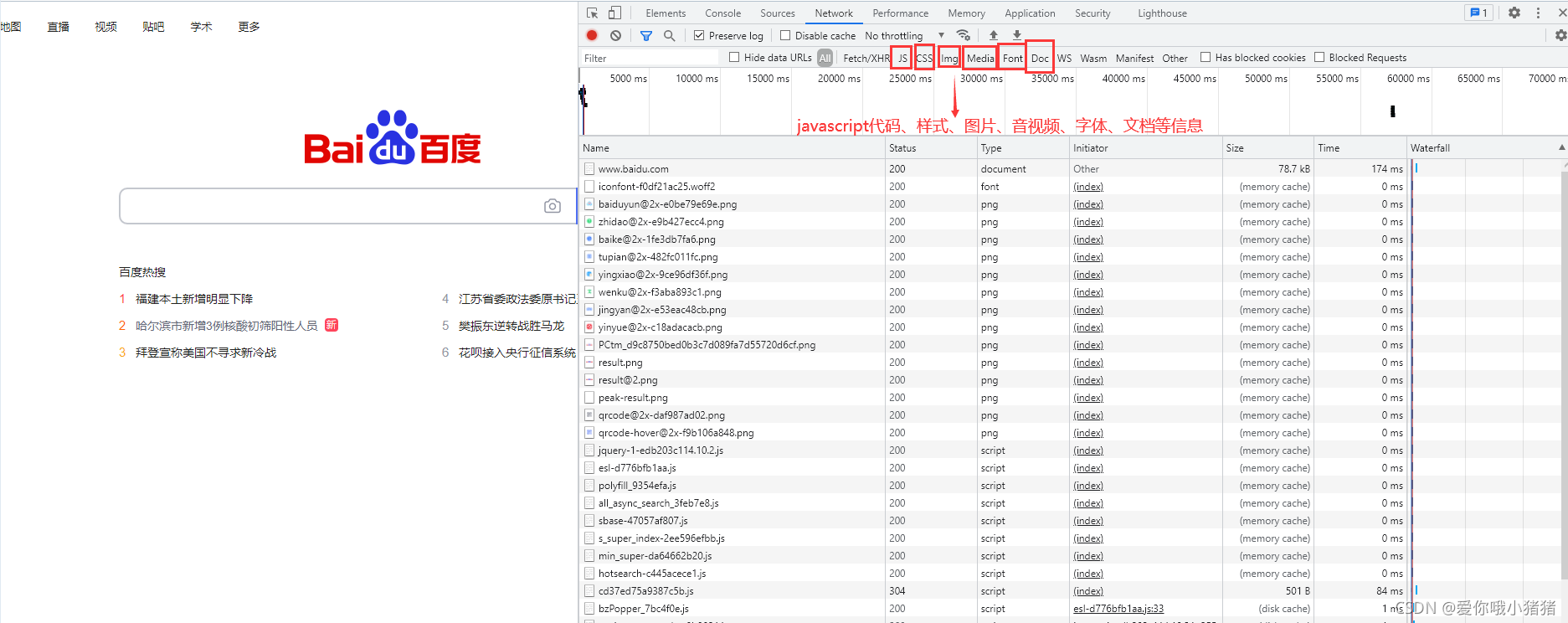
其中Doc文件里面信息重要,界面如下。在General一栏中,Request URL代表我们要访问的地址。Request Method代表请求的方法,有GET和POST两种。
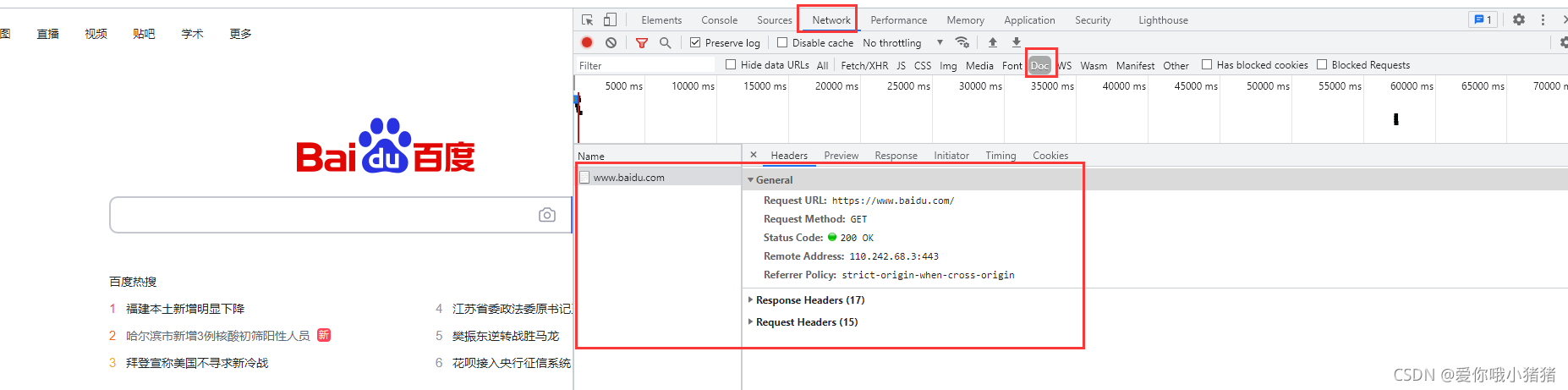
我们可以分析里面Request Headers的内容,看看我们是发送了一个什么东西让服务器给了我们response并允许我们访问。Request Headers中User Agent最为重要,它表示了当前是谁在访问。服务器通过User Agent认为是浏览器在进行访问。

我们开始进行访问,需要保存的是响应的返回内容。
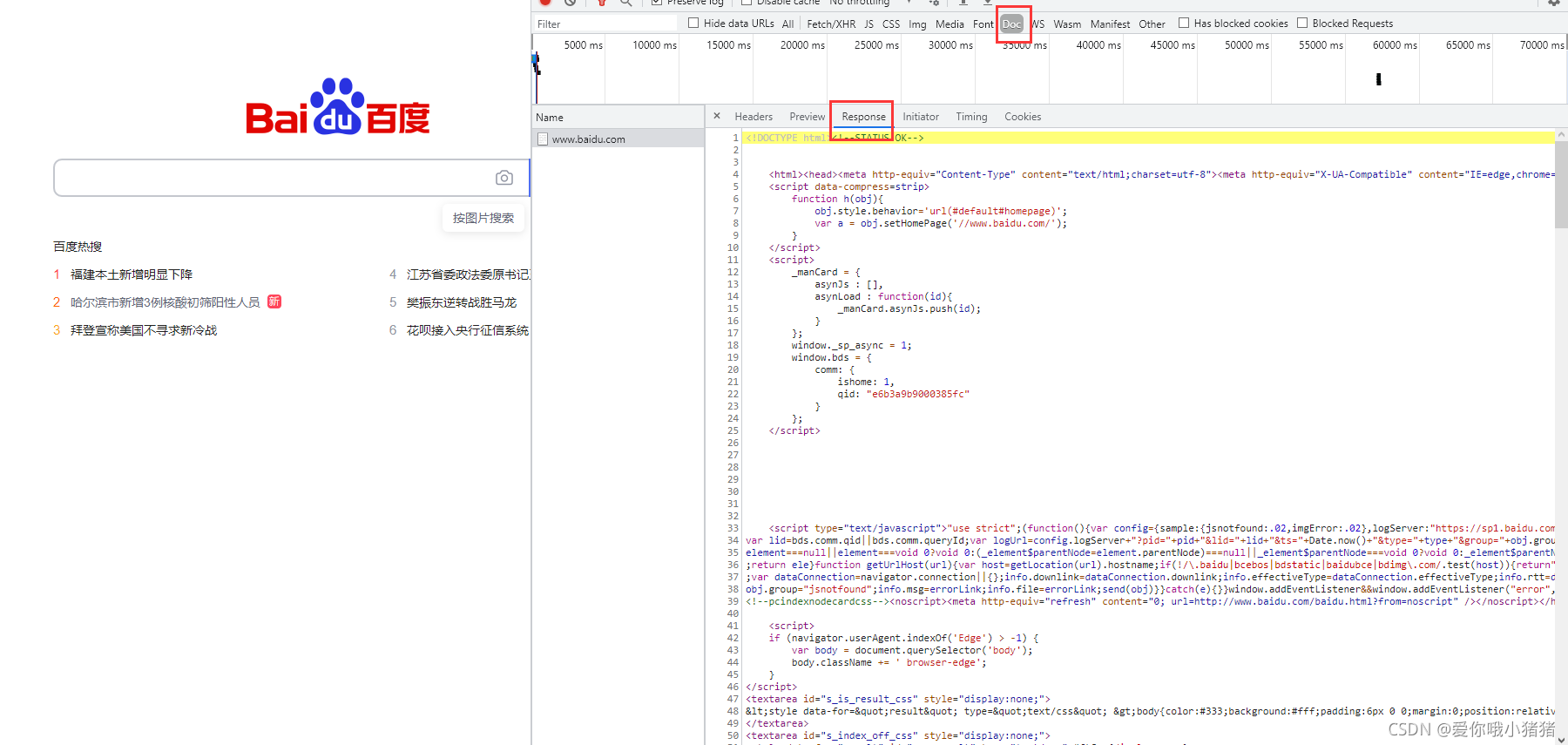
代码如下:
import locale # 查看系统的编码方式
import requests# 一个字典,保存User-Agent信息
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36 OPR/78.0.4093.231"
}# 使用requests发送get类型的请求,同时将requests伪装成由浏览器发起
url = 'https://movie.douban.com/explore#!type=movie&tag=热门&sort=recommend&page_limit=20&page_start=0'
response = requests.get(url, headers=headers) # headers参数需要输入一个子字典类型的参数
code = response.status_code # 返回码,正确时为200# 看一下系统的编码方式,Windows默认是GBK。
# print(locale.getpreferredencoding(False))if code == 200:# 获取的响应数据data = response.text# 将相应数据保存到douban.html文件中# open函数采用的编码方式依赖于系统,而我们在pycharm中打开html文件是使用UTF-8。因此,使用open函数时将编码方式更改为UTF-8with open('douban.html', mode='w', encoding="utf-8") as f:f.write(data)
else:print('请求有误!')
得到返回的html原始数据后,我们看一看,并在浏览器中打开。
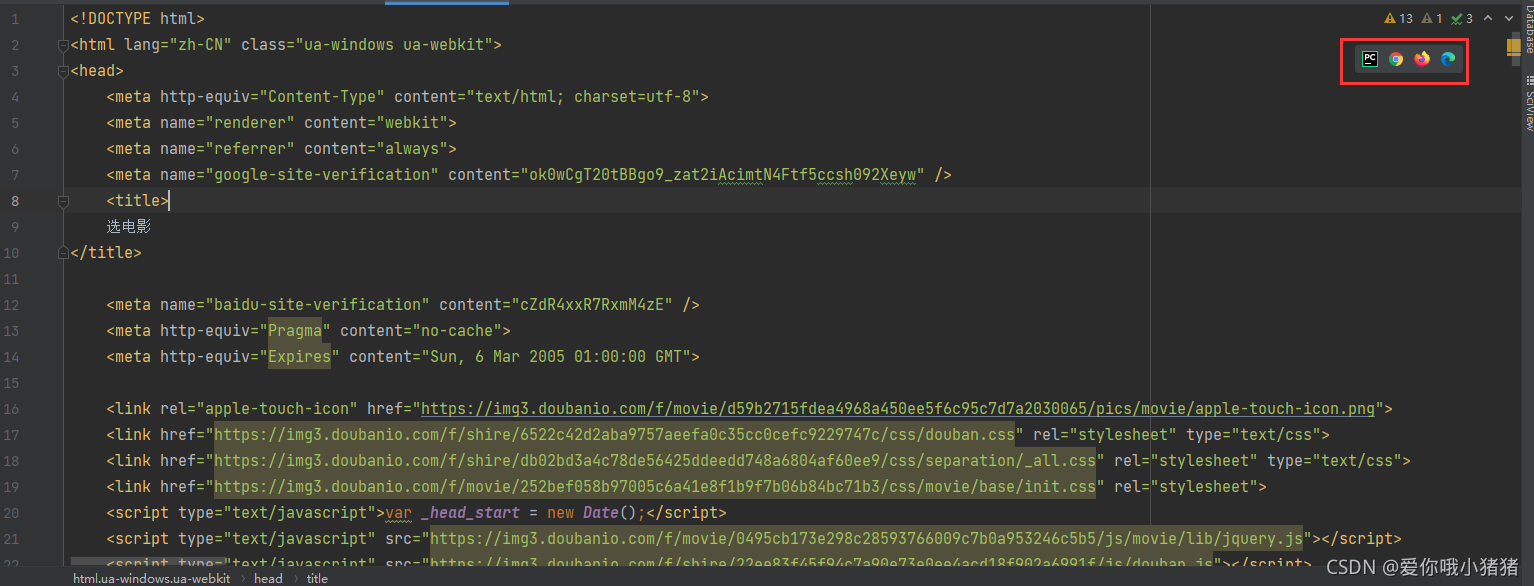
我们发现效果如下,电影的信息都不显示,说明我们想要的信息不在这个链接。
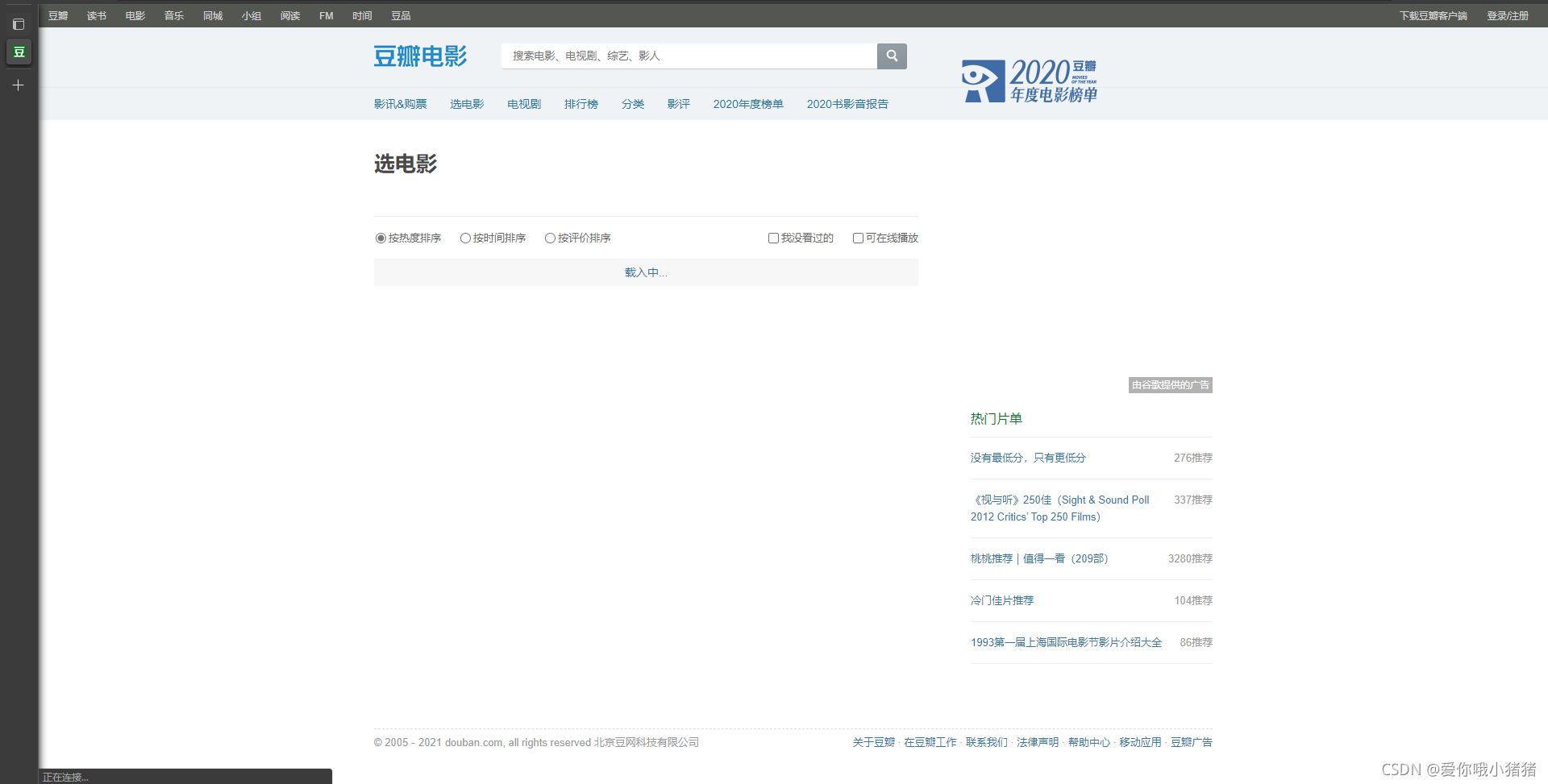
2.3 获取json网络数据
因此,我们得继续回去分析。只要我们的数据没在Doc里面,那么加载方式可能是异步加载。如何验证是否是异步加载的呢?操作步骤如下:
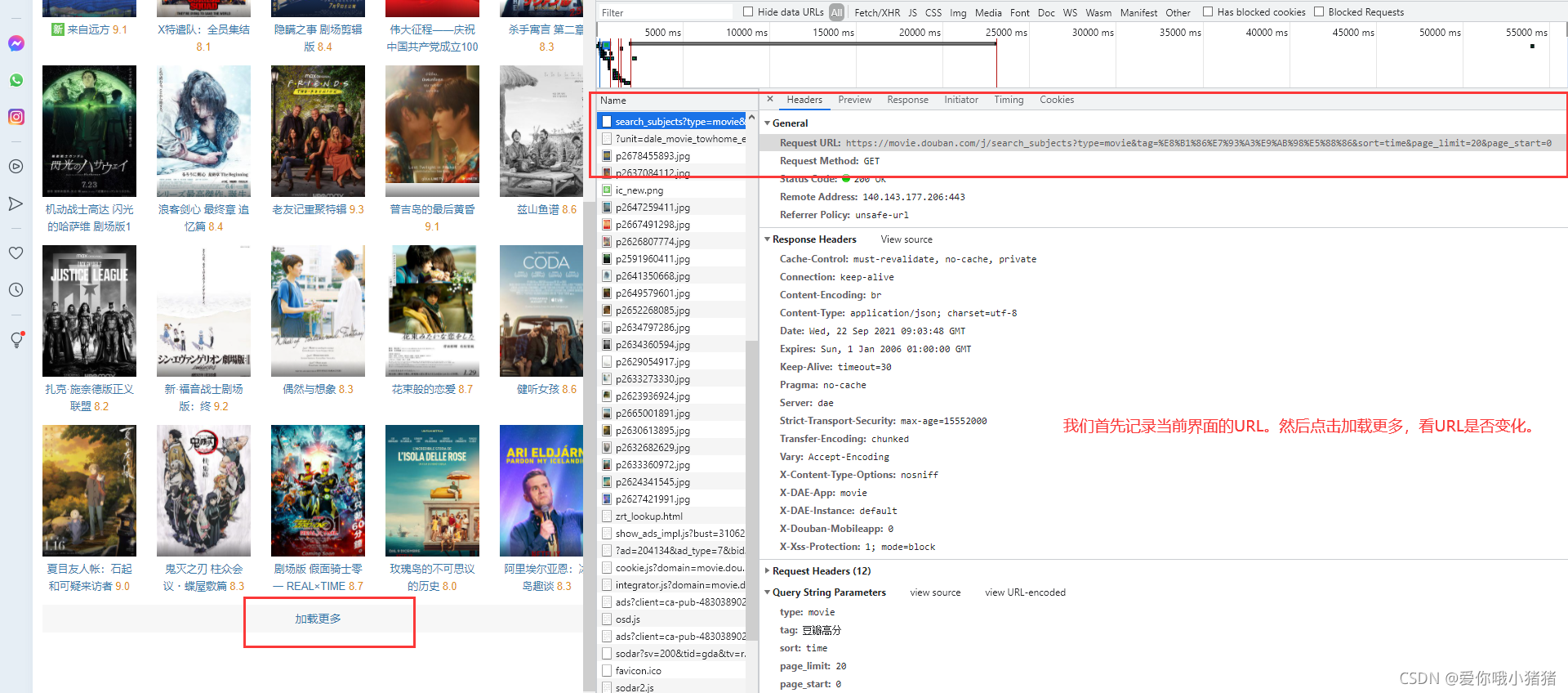
我们对比几次的URL如下:
Request URL: https://movie.douban.com/j/search_subjects?type=movie&tag=%E8%B1%86%E7%93%A3%E9%AB%98%E5%88%86&sort=time&page_limit=20&page_start=0
Request URL: https://movie.douban.com/j/search_subjects?type=movie&tag=%E8%B1%86%E7%93%A3%E9%AB%98%E5%88%86&sort=time&page_limit=20&page_start=20
Request URL: https://movie.douban.com/j/search_subjects?type=movie&tag=%E8%B1%86%E7%93%A3%E9%AB%98%E5%88%86&sort=time&page_limit=20&page_start=40
我们可以发现只是最后的page_start不一样。我使用浏览器打开page_start=20对应的URL,界面如下,返回了json信息。

我们可以得到:
Document返回html格式数据,格式如下:
<html>
......
<html>
XHR(ajax)返回json格式数据,格式如下:
{
data:["",""]
}
如果觉得json格式较乱,可以使用bejson进行格式化校验,让格式更清晰。
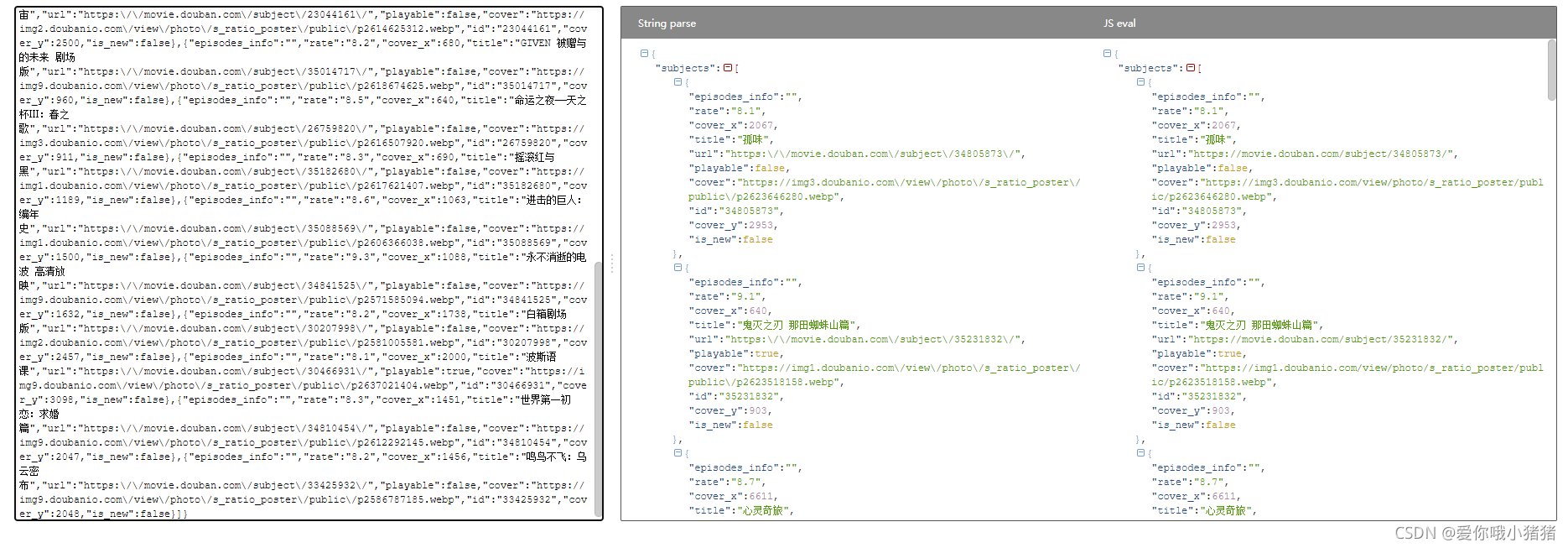
获取json数据代码如下:
import requestsheaders = {"User-Agent": "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36 OPR/78.0.4093.231"
}url = 'https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0'
response = requests.get(url, headers=headers)
code = response.status_codeif code == 200:data = response.json() # 获取的响应数据是json类型print(type(data)) # data的类型是stringdata = str(data) # 将字典类型转成str类型with open('movies.txt', mode='w', encoding="utf-8") as f:f.write(data)
else:print('请求有误!')
2.4 获取图片数据
如果我们想提取电影的海报图片,首先查看bejson格式化后的json信息。
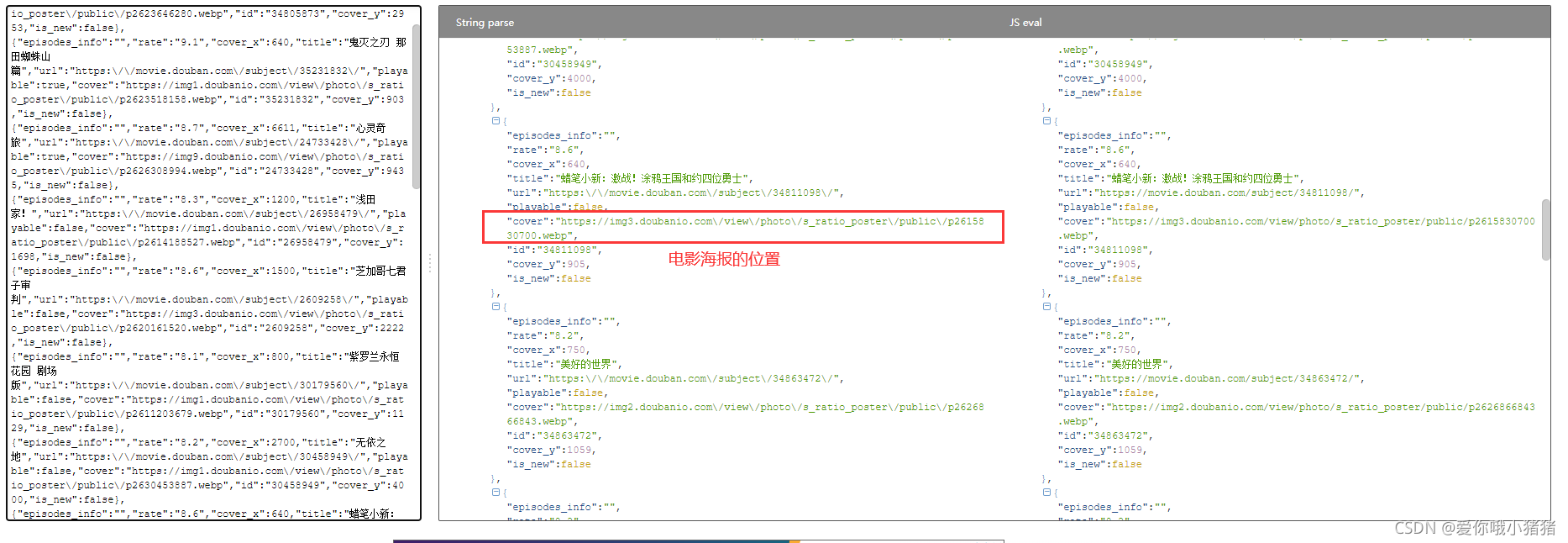
可以看出cover项对应的应该就是电影海报所在位置,我们复制网址并检查,发现正是存储电影海报的位置。
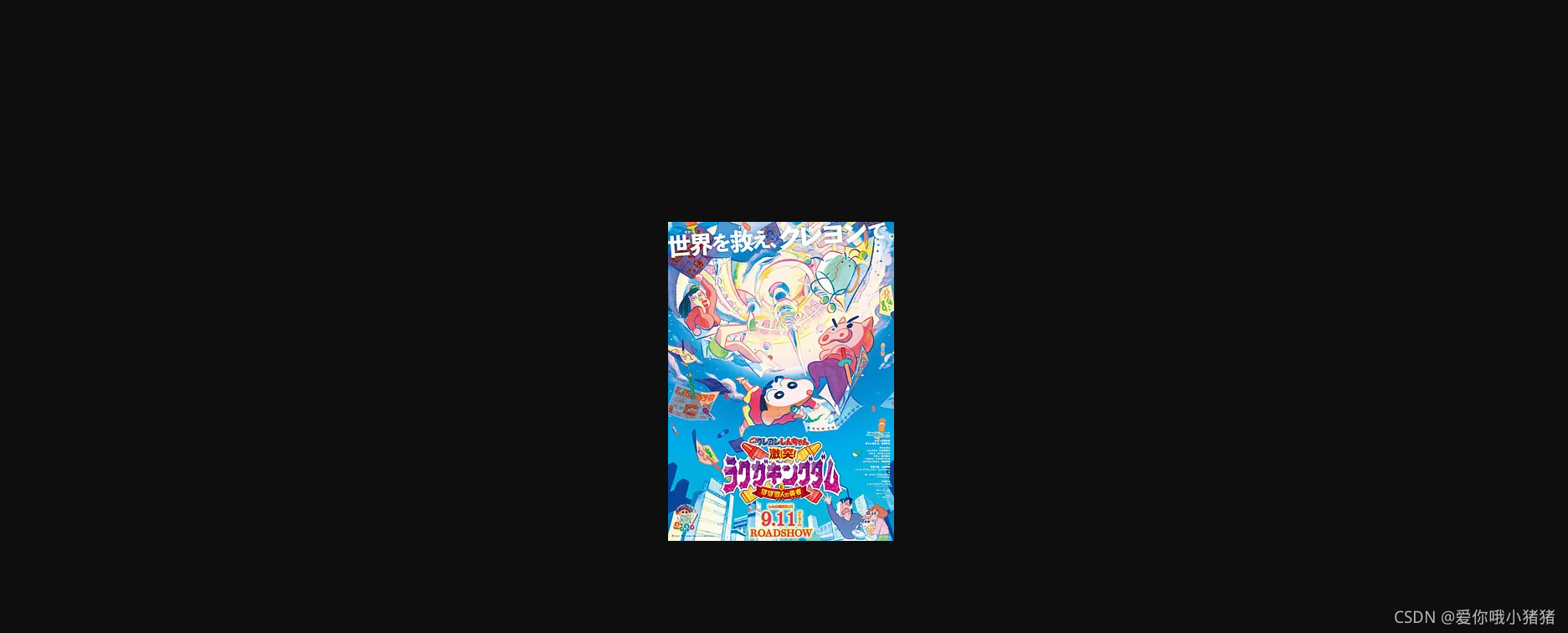
我们将该网址设置为需要爬取的URL,代码如下:
import requestsheaders = {"User-Agent": "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36 OPR/78.0.4093.231"
}url = "https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2615830700.webp"
response = requests.get(url, headers=headers)
code = response.status_codeif code == 200:# 获取的响应数据是二进制data = response.contentwith open('picture.jpg', mode='wb') as f:f.write(data)
else:print('请求有误!')爬取图片如下:

三、提取数据
将各类数据爬取后,我们开始从中提取出数据。我们可以使用XPATH,它能够解析html,也能解析xml。XPATH的详细语法可参照:XPATH语法
3.1 提取百度热搜信息
我们从最开始爬取的百度html文件如下:
浏览器中打开后界面如下,我们如何从中提取出热搜信息呢?
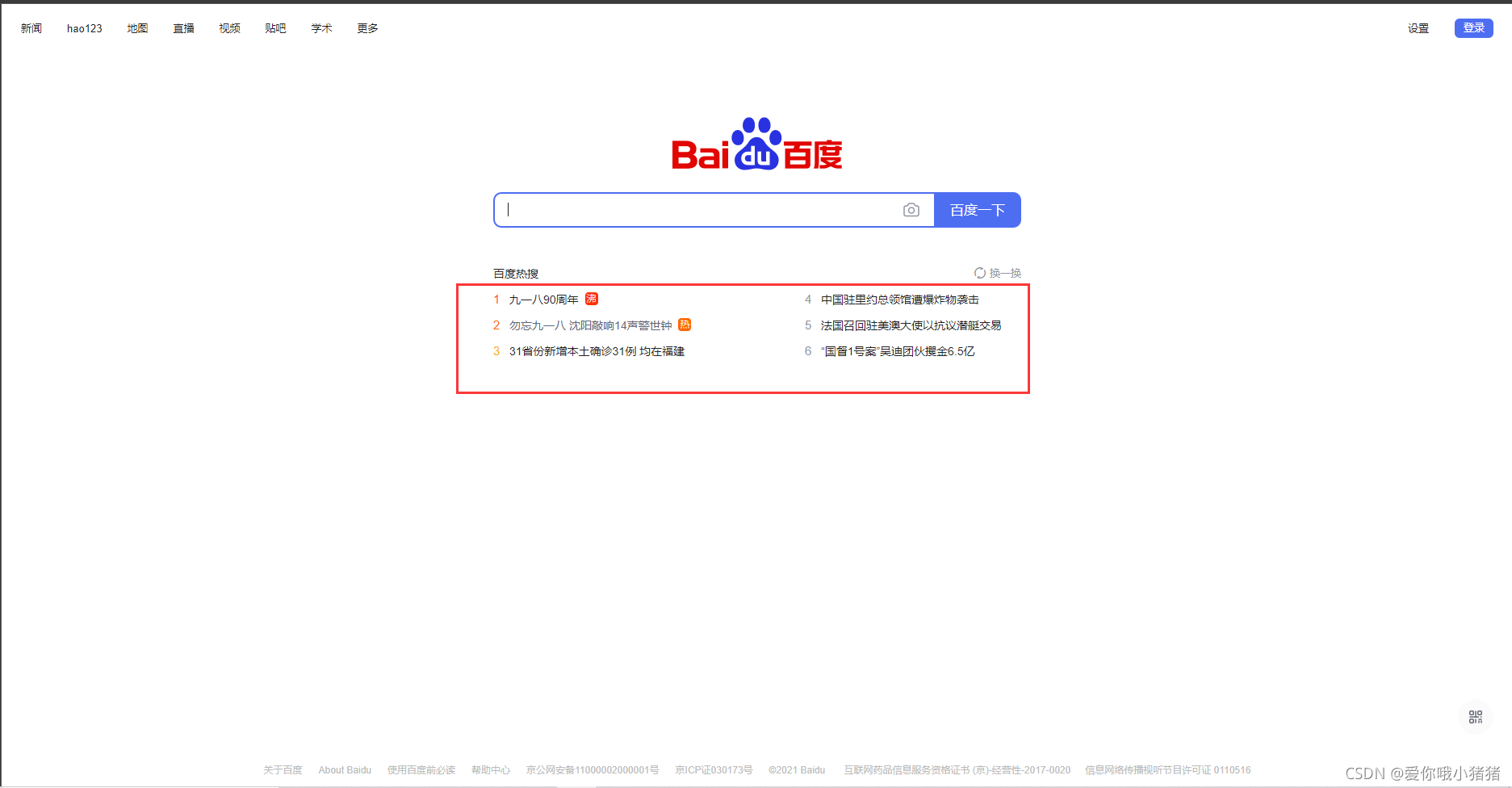
我们可以看出,热搜信息位置如下:
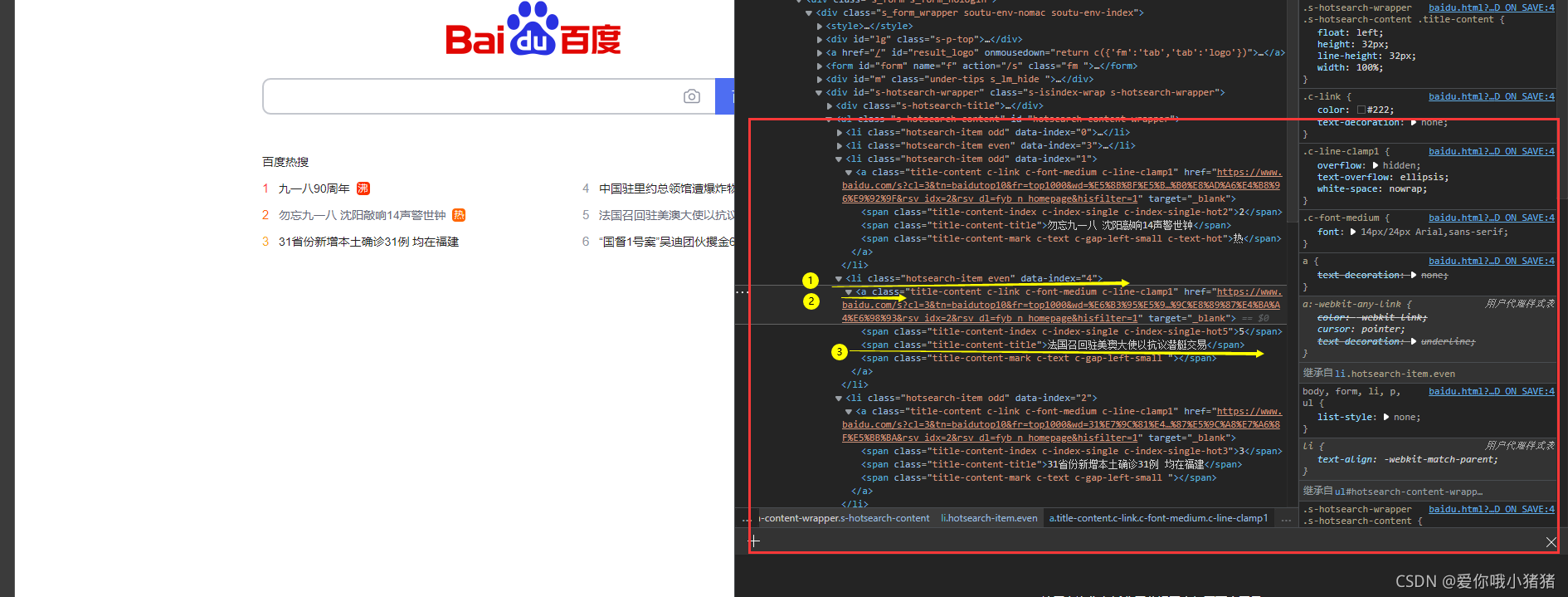
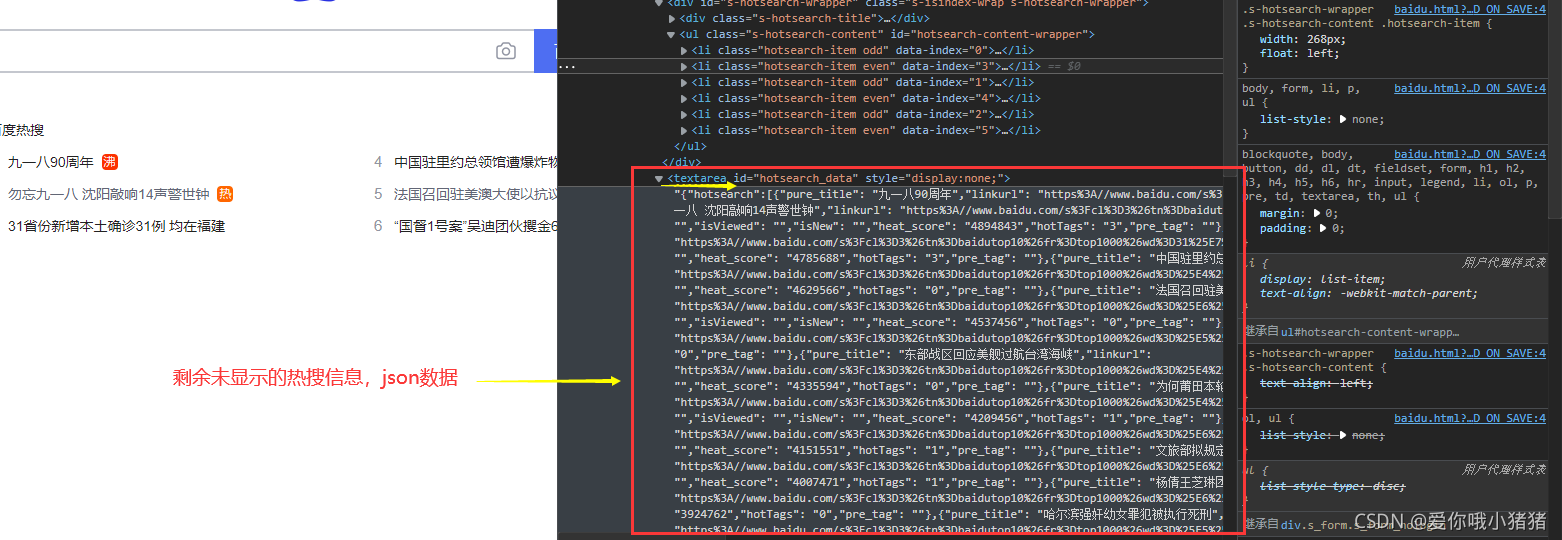
剩余的热搜信息(点击换一批可以看到)则在这里:
提取热搜信息代码如下:
import requests
from lxml import etreeheaders = {"User-Agent": "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36 OPR/78.0.4093.231"
}
url = 'https://www.baidu.com'response = requests.get(url, headers=headers)
code = response.status_codeif code == 200:data = response.text# 将获取的网络数据交给etree进行解析html = etree.HTML(data)hotsearchs = html.xpath('//ul[@class="s-hotsearch-content"]/li/a/span[2]/text()')print(hotsearchs)
else:print('请求有误!')
效果如下:

3.2 提取豆瓣同城近期活动信息
希望提取的豆瓣同城近期活动信息如下图所示:
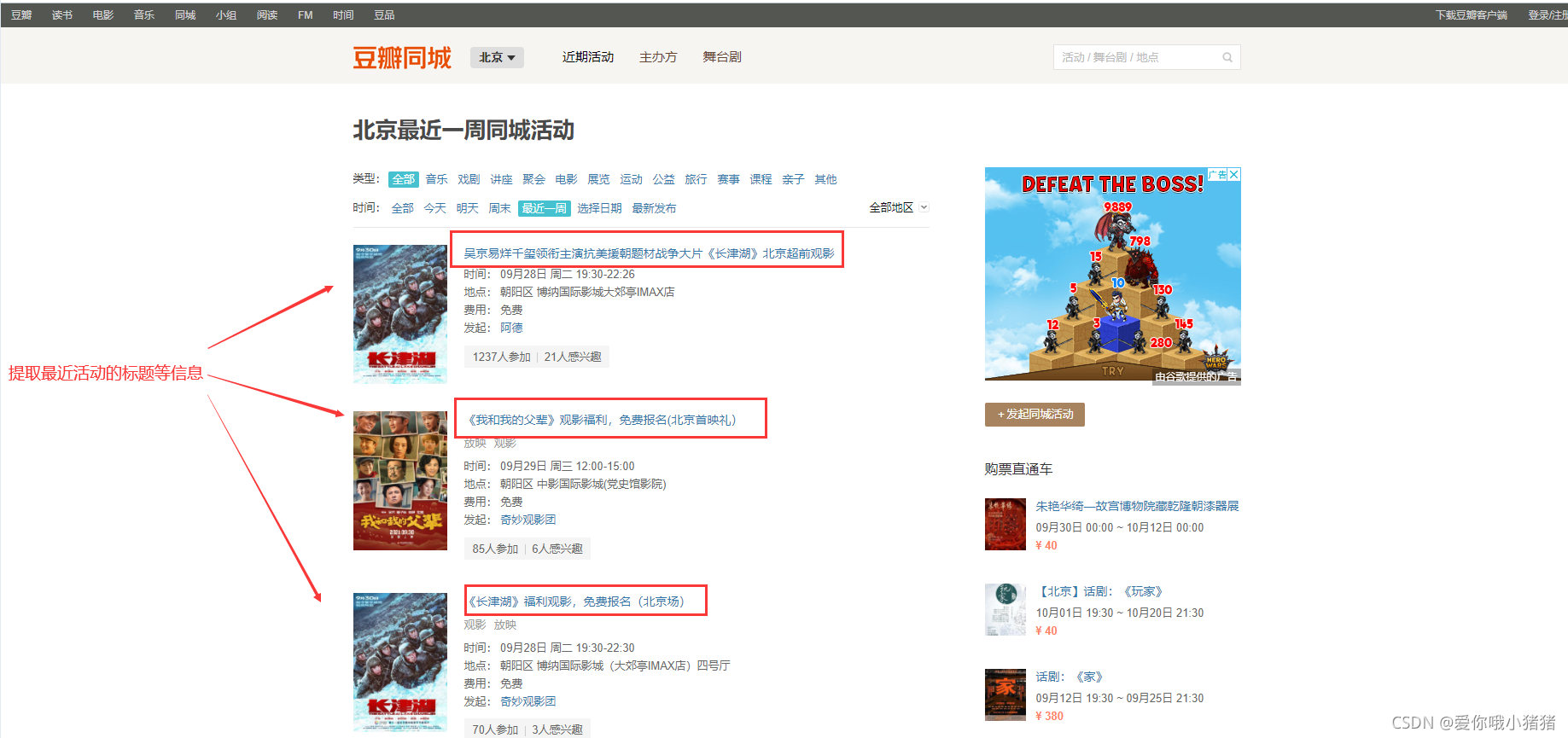
我们希望提取活动标题和时间信息。其中,活动标题所处位置如下:
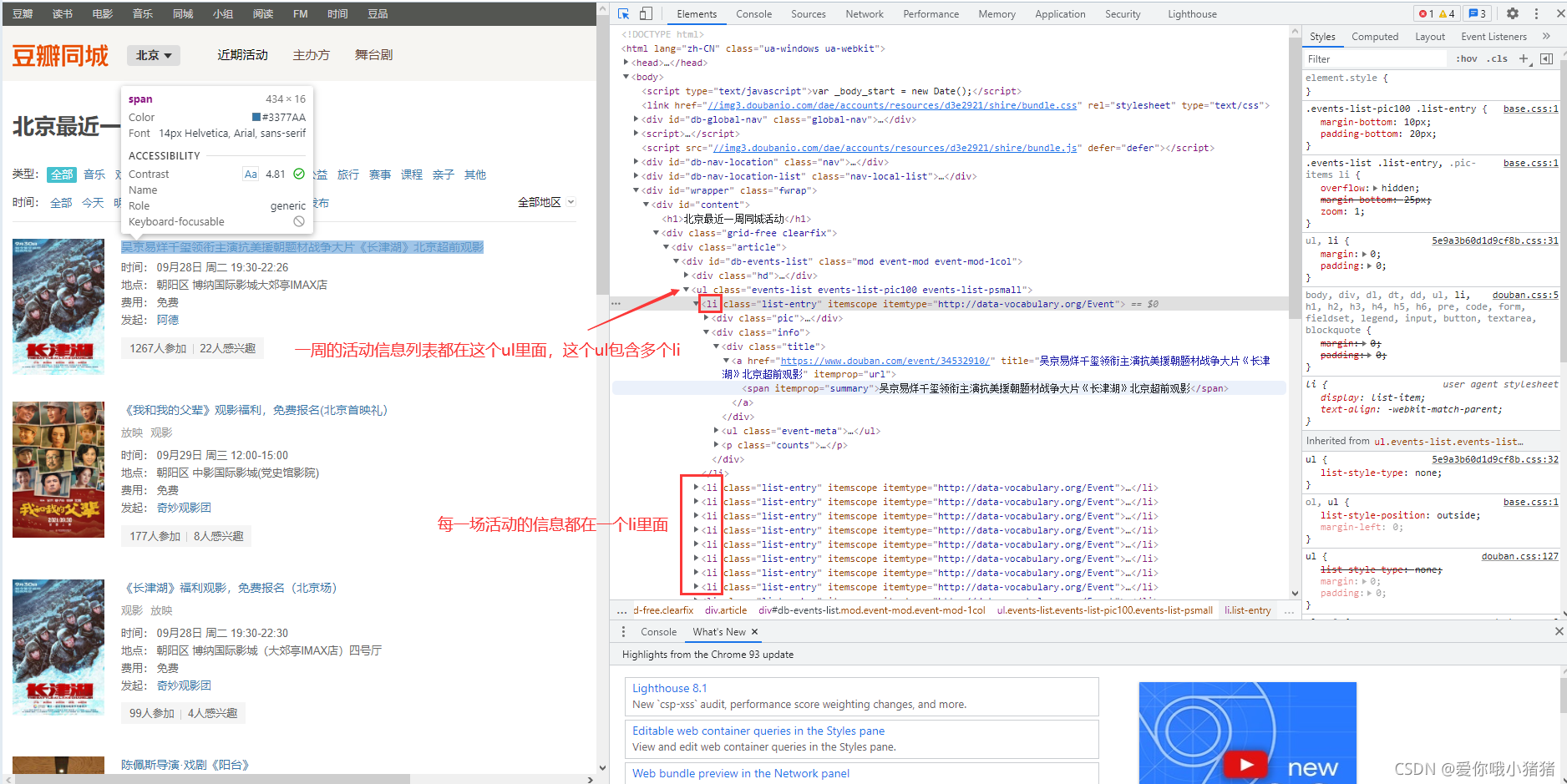
活动时间所处位置如下:
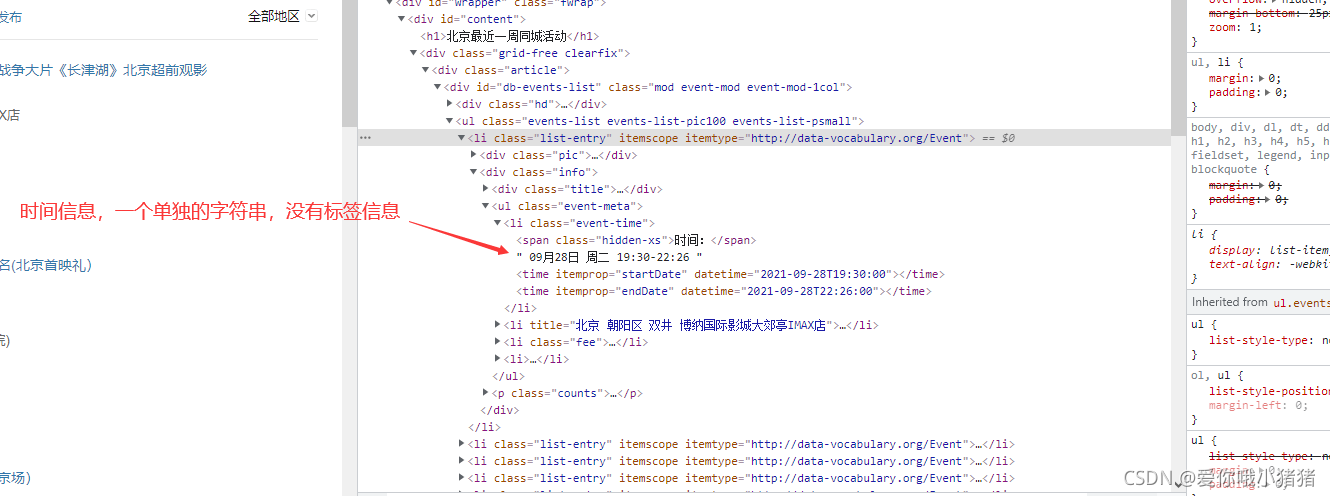
提取标题和时间信息代码如下:
import requests
from lxml import etree
import re
import csv# 1. 发出请求,获取响应数据
headers = {"User-Agent": "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36 OPR/78.0.4093.231"
}
url = 'https://beijing.douban.com/events/week-all'
response = requests.get(url, headers=headers)if response.status_code == 200:data = response.text# 2. 解析数据html = etree.HTML(data)titles = html.xpath('//ul[@class="events-list events-list-pic100 events-list-psmall"]/li/div[2]/div/a/span/text()')print(titles)times = html.xpath('//ul[@class="events-list events-list-pic100 events-list-psmall"]/li/div[2]/ul/li[1]/text()')print(times)# 处理times中的\n和空格# 准备一个列表times1存放处理好的数据times1 = []for t in range(1,len(times),4):ti = re.sub(r'\s+','',times[t])times1.append(ti)print(ti)# 3. 存储数据titles = zip(titles, times1)with open('tongcheng.csv', mode='w', newline='', encoding='utf-8') as f:w_file = csv.writer(f)w_file.writerows(titles)
else:print('error')