前言
我毕业论文要写文本大数据情绪分析,没有现成的数据。淘宝要价600块我又舍不得,只能自学爬虫。我一点计算机网络的基础都没有,光是入门就花了一周(不知道从何下手),所幸爬虫不难,只要见过就能会用。
所以写个文章把这个爬虫分享出来。
我的需求
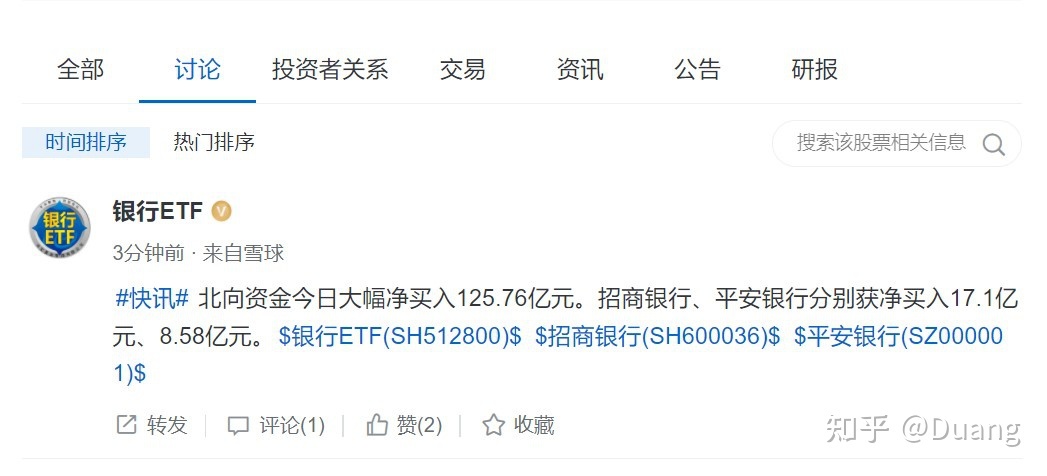
我要爬取[雪球网]的股票评论信息(如图),看起来很简单。
基础知识
URL
开发人员工具DevTools
你还需要知道浏览器中 F12 或 右键菜单-检查 是开发人员工具DevTools,现在就可以试试。在Edge DevTools的欢迎页面中有一个好心的链接“DevTools为初学者”,里面也可以学习html,但是中文翻译有点问题。
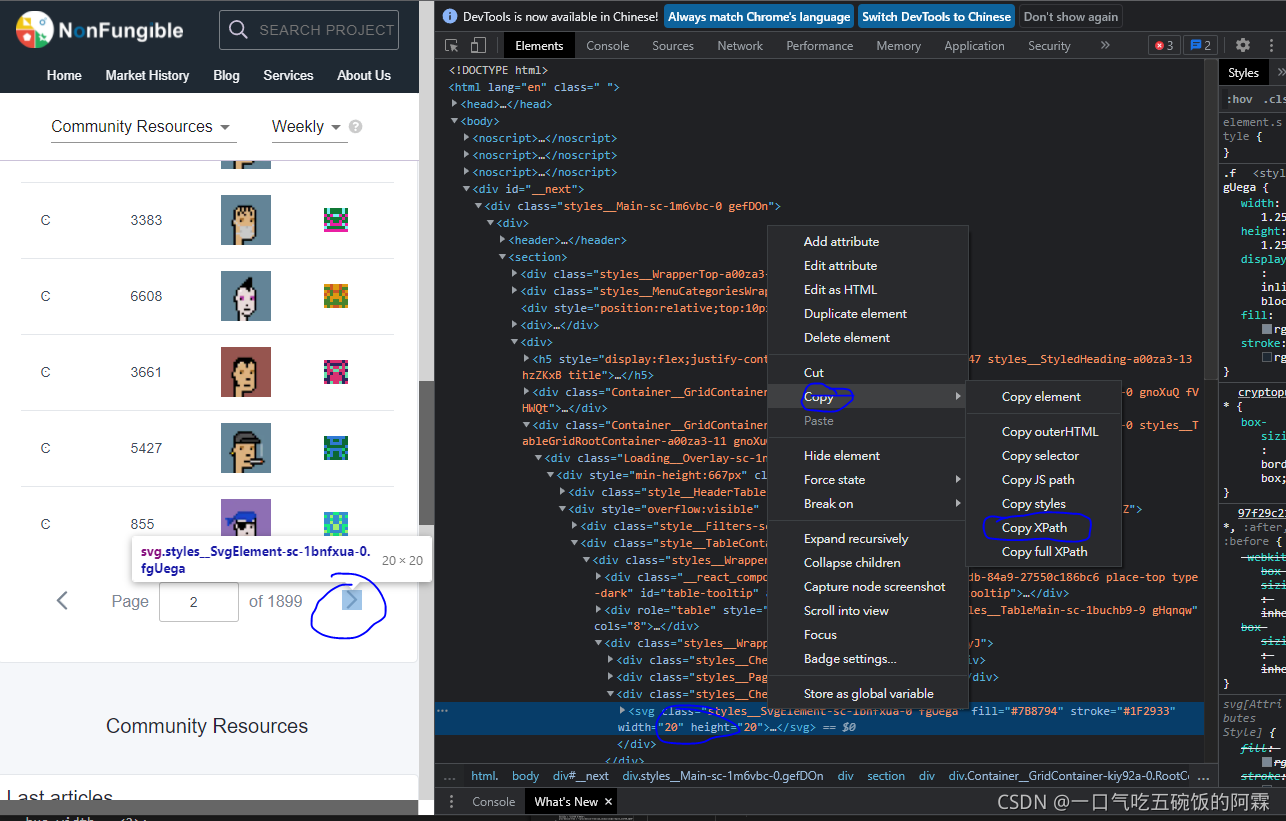
打开DevTools的"元素"面板可以看到当前网页的html代码(这个说法其实不准确)。打开DevTools的"网络"面板可以看到有哪些网络请求。这两个面板后面会用到。
HTTP请求过程
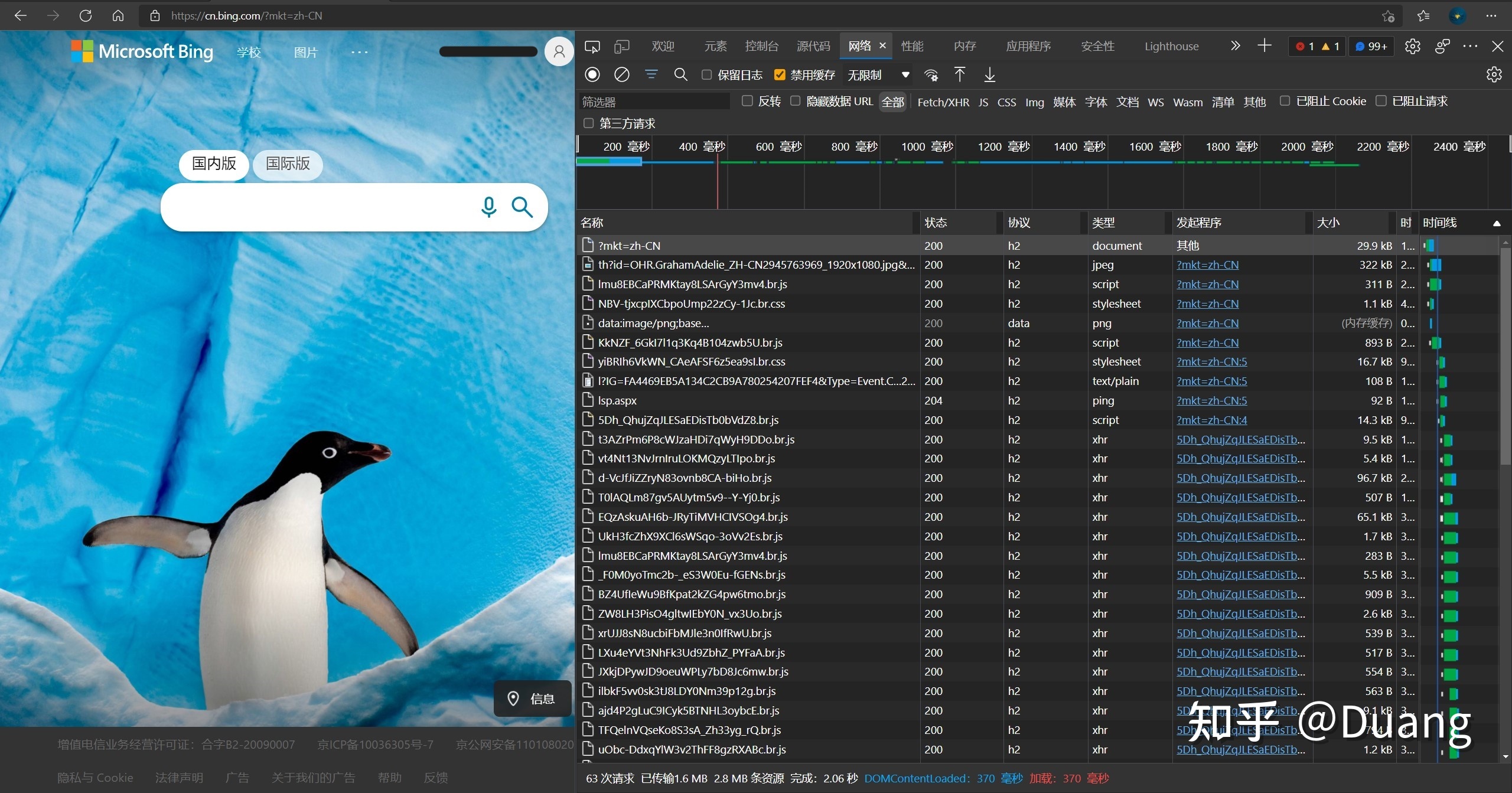
打开[必应 (bing.com)]网页,打开DevTools"网络"面板,刷新页面,你会看到许多请求。
第一个是“?mkt=zh-CN”,如果你看了URL介绍,可能会记得问号后面是“提供给网络服务器的额外参数”(知道是参数就行)。状态码是200 (ok),一切正常。常用的还有 403 forbidden 和 404 not found。
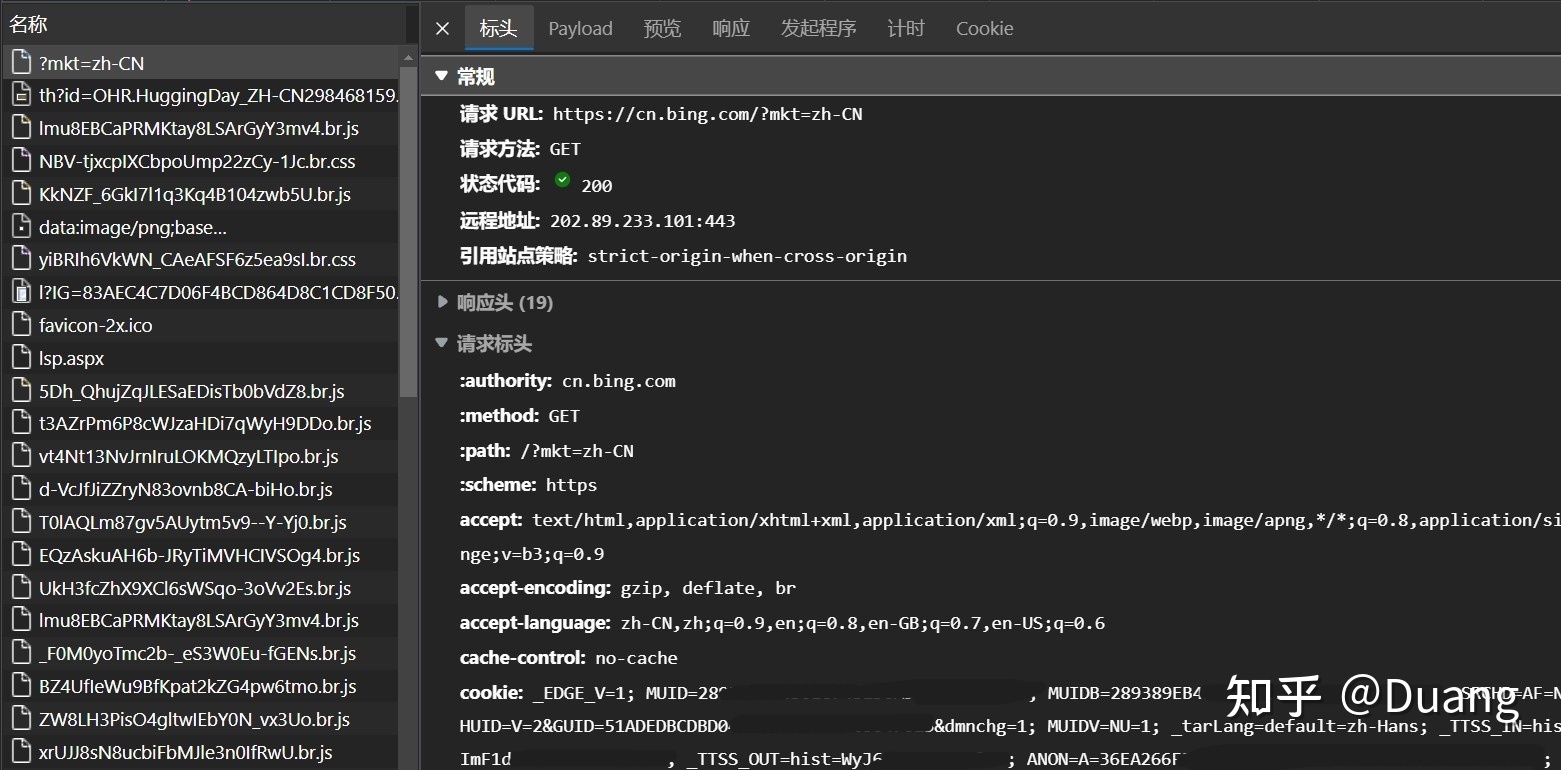
点击“?mkt=zh-CN”可以看到请求(标)头和响应头。HTTP请求是由客户端发出的消息,用来使服务器执行动作。做爬虫也是给服务器发请求(头)。
HTTP消息只看请求头和响应头部分:
请求头中的每一行含义见下链接(可以不看):
HTTP 请求方法有8种,我们只要用到 GET 方法:
Cookie
HTTP Cookie 是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器下次向同一服务器再发起请求时被携带并发送到服务器上。通常,它用于告知服务端两个请求是否来自同一浏览器,如保持用户的登录状态。
有些网站需要登录才能完整访问,而cookie可以保持登录状态。后面写爬虫需要把 cookie 复制保存在本地。
HTML, CSS, Javascript
[HTML](HyperText Markup Language) 不是一门编程语言,而是一种用来告知浏览器如何组织页面的标记语言。HTML 可复杂、可简单,一切取决于开发者。它由一系列的**元素([elements])**组成,这些元素可以用来包围不同部分的内容,使其以某种方式呈现或者工作。 一对标签([tags])可以为一段文字或者一张图片添加超链接,将文字设置为斜体,改变字号,等等。
层叠样式表 [CSS]:HTML用于定义内容的结构和语义,CSS用于设计风格和布局。比如,您可以使用CSS来更改内容的字体、颜色、大小、间距,将内容分为多列,或者添加动画及其他的装饰效果。
[JavaScript] 编程语言允许你在 Web 页面上实现复杂的功能。如果你看到一个网页不仅仅显示静态的信息,而是显示依时间更新的内容,或者交互式地图,或者 2D/3D 动画图像,或者滚动的视频播放器,等等——你基本可以确定,这需要 JavaScript 的参与。
Requests
这是个python包,我会把需要用到的用法写出来。
实现GET请求
> import requests
> url = 'https://www.httpbin.org/get'
> response = requests.get(url)
> print(response.status_code)
> print(response.text)200
{"args": {}, "headers": {"Accept": "*/*", "Accept-Encoding": "gzip, deflate, br", "Host": "www.httpbin.org", "User-Agent": "python-requests/2.26.0", "X-Amzn-Trace-Id": "Root=1-61ea5106-6a65650b1eff1121063b27ac"}, "origin": "110.255.126.198", "url": "https://www.httpbin.org/get"
}可以看到返回结果中包含请求头、URL、IP等信息
用Cookie维持登录状态
打开[Scrape | Movie],这个网站需要登录才能访问,用户名和密码都是admin。如果我们直接发送get请求,只能得到登录界面,你可以试试。
> url = 'https://login2.scrape.center/'
> response = requests.get(url)
> print(response.text)
需要使用cookie才行。我们先手动登录,打开DevTools的"网络"面板,点击第一个出现的请求"login2.scrape.center",在请求头中找到cookie并手动复制。
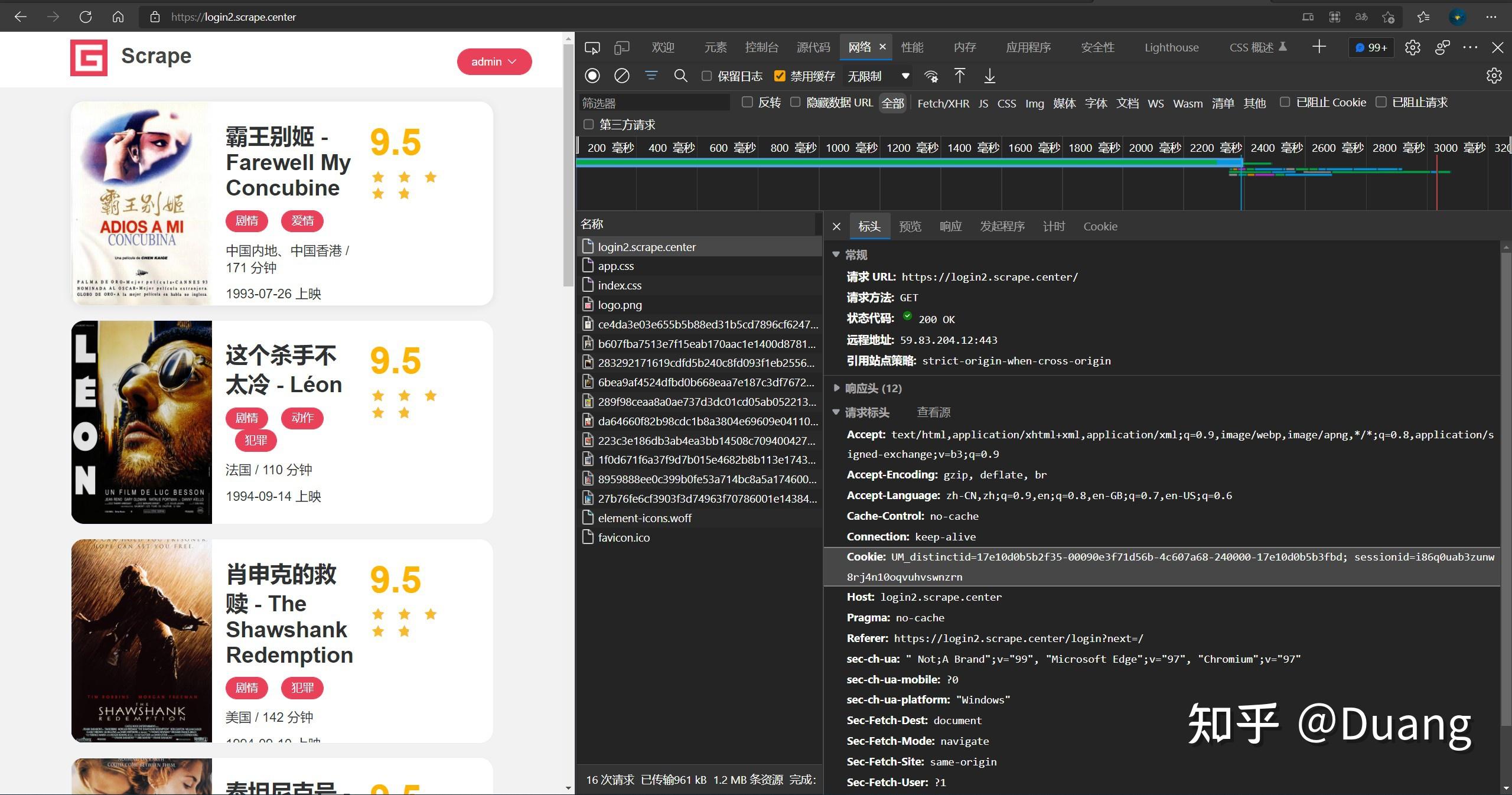
> url = 'https://login2.scrape.center/'
> headers = {'cookie':'UM_distinctid=17e10d0b5b2f35-00090e3f71d56b-4c607a68-240000-17e10d0b5b3fbd; sessionid=i86q0uab3zunw8rj4n10oqvuhvswnzrn'}
> response = requests.get(url,headers=headers)
> print(response.text)
fake_useragent
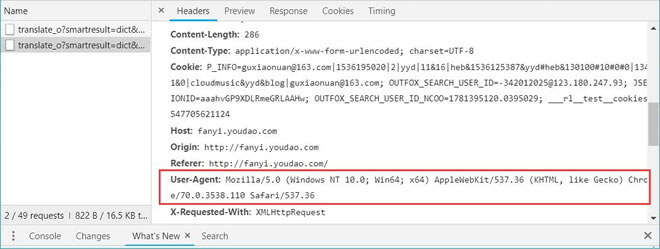
UserAgent 用户代理,相当于浏览器的身份证号,是请求头中的一行。在利用爬虫爬取网站数据时,频繁更换它可以避免触发相应的反爬机制。
fake_useragent 包可以用来生成UserAgent,用法很简单。
> from fake_useragent import UserAgent
> ua = UserAgent()
> headers = {
> 'user-Agent':ua.random,
> 'cookie':'your cookie'
> }
> response = requests.get(url,headers=headers)
时间戳 timestamp
时间戳,一串数字,代表从格林威治时间1970年01月01日00时00分00秒起至现在的总秒数(有时精确到毫秒或微秒)
> import time
> time.time()
1642747138.7392855
tqdm
tqdm是用来生成进度条的包,我看的是这个教程:
其实只需要这个示例
> from tqdm import tqdm
> dic = ['a', 'b', 'c', 'd', 'e']
> pbar = tqdm(dic)
> for i in pbar:
> pbar.set_description('Processing '+i)
> time.sleep(0.2)Processing e: 100%|██████████| 5/5 [00:01<00:00, 4.69it/s]存储数据的一种方式:JSON文件
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。易于人阅读和编写,同时也易于机器解析和生成。示例如下:
{"employees": [{ "firstName":"John" , "lastName":"Doe" },{ "firstName":"Anna" , "lastName":"Smith" },{ "firstName":"Peter" , "lastName":"Jones" }]
}存储数据的另一种方式:MongoDb数据库
NoSQL,非关系型的数据库,有时也称作Not Only SQL的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称。Mongodb是其中一种。
在官网选择合适的版本
打开安装程序,选择 complete 完全安装,在 Service Configuration 界面选择 Run Service as Network Service user。其他不管。
在浏览器地址栏输入 localhost:27017,安装成功应该出现 “It looks like you are trying to access MongoDB over HTTP on the native driver port.”
通过pymongo包使用数据库,
> import pymongo
> client = pymongo.MongoClient(host='localhost',port=27017) # 连接数据库
> client.list_database_names() #查看已有的数据库
> db = client.test # 创建名为 text 的数据库
> db.list_collection_names() #查看已有的集合,MongoDB 中的集合类似 SQL 的表。
> collection = db.comments # 创建名为 comments 的集合
> # 在 MongoDB 中,集合只有在内容插入后才会创建! 就是说,创建集合(数据表)后要再插入一个文档(记录),集合才会真正创建。> data = { "name": "Duang", "university": "SWUFE"}
> collection.insert_one(data) # 插入数据> result = collection.find_one({ "name": "Duang"}) # 查询数据
> print(result)
{'_id': ObjectId('61ea7d5b92328b1dc5121a0f'), 'name': 'Duang', 'university': 'SWUFE'}> collection.delete_one({ "name": "Duang"}) # 删除数据
<pymongo.results.DeleteResult at 0x17ec7f263c0>爬虫代码
我已经发在 github,自取
导入包
没什么好说的。
import requests
import logging
from fake_useragent import UserAgent
from datetime import datetime
from datetime import timedelta
#from tqdm.notebook import tqdm #如果用jupyter则从这里导入
from tqdm import tqdm
import pymongo不可更改部分
logging.basicConfig(level=logging.INFO,format='%(asctime)s - %(levelname)s: %(message)s')
INDEX_URL = 'https://xueqiu.com/query/v1/symbol/search/status.json?count=10&comment=0&symbol={symbol}&hl=0&source=user&sort={sort}&page={page}&q=&type=11'
client = pymongo.MongoClient(host='localhost',port=27017)
#client.list_database_names() #查看已有的数据库
db = client.test
#db.list_collection_names() #查看已有的集合
collection = db.comments实际上 db = client.test 也可以改成别的名字。
可更改部分
sort = 'time' # 时间排序
#sort = 'alpha'# 热度排序
eduSHcode=['SH600880','SZ002261','SZ300282',
'SZ300359','SZ300010','SZ300192','SZ002659',
'SH600636','SZ300688','SZ300338','SH603377',
'SZ002621','SH605098','SZ003032','SZ002841',
'SH600661','SH600730','SZ002638','SZ002607',
'SZ300089','SZ000526'] # 股票代码
keys = {'fav_count','hot','id','like_count',
'text','timeBefore','view_count','user_id'} # 需要的数据类型
maxPage=10 # 最大为100eduSHcode 是股票代码,我直接手动复制粘贴了。
maxPage 是爬取评论的页数,每页十条,最大为100页(雪球规定的)。
生成HTML请求头
def make_headers(cookie_path='cookie.txt'):# 生成HTML请求头ua = UserAgent()headers = {'user-Agent':ua.random,'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9','accept-encoding': 'gzip, deflate, br','accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6','cache-control': 'no-cache','pragma': 'no-cache','sec-ch-ua': '" Not;A Brand";v="99", "Microsoft Edge";v="97", "Chromium";v="97"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"','sec-fetch-dest': 'document','sec-fetch-mode': 'navigate','sec-fetch-site': 'none','sec-fetch-user': '?1','upgrade-insecure-requests': '1'}with open(cookie_path,"r") as f:cookie = f.read()headers['cookie'] = cookiereturn(headers)headers = make_headers()请求头里的内容都可以去DevTools"网络"面板看,如果不一样可以自己改。
在文件夹里新建个 cookie.txt,把 cookie 值复制进去。
几个主要的函数
但是没啥可讲的
def scrape_api(url):# 根据url爬取网页,是最基础的函数try:response = requests.get(url,headers=headers)if response.status_code == 200:return response.json()except requests.RequestException:logging.error('error occurred while scraping %s', url, exc_info=True)def scrape_symbol(symbol):# 爬取股票信息for page in tqdm(range(1, maxPage + 1), desc='Page',leave=False):url = INDEX_URL.format(symbol=symbol, page=page, sort=sort) # 将url中空缺的信息填上index_data = scrape_api(url)save_data_mongodb(index_data)def save_data_mongodb(index_data):# 输入为一页十条评论,分别保存about = index_data.get('about')for comment_data in index_data.get('list'):# 先处理时间格式if 'timeBefore' in comment_data.keys():thetime = str(comment_data['timeBefore'])comment_data['timeBefore'] = parse_time(thetime)# 好像bool值不能直接保存if 'hot' in comment_data.keys():comment_data['hot'] = str(comment_data['hot'])# 提取需要的信息result_data = {key:value for key,value in comment_data.items() if key in keys }result_data['symbol'] = about#保存collection.insert_one(result_data)def parse_time(thetime):# 此函数抄自: https://github.com/py-bin/xueqiu_spider# 稍有修改# 处理爬取时间格式异常问题,如“今天 08:30”、“20分钟前”date_now = datetime.now()if '今天' in thetime:rst = thetime.replace('今天',date_now.strftime('%Y-%m-%d'))elif '昨天' in thetime:the_time = date_now - timedelta(days=1)rst = thetime.replace('昨天',the_time.strftime('%Y-%m-%d'))elif '分钟前' in thetime:the_min = int(thetime[:-3])the_time = date_now - timedelta(minutes=the_min)rst = the_time.strftime('%Y-%m-%d %H:%M')elif '秒前' in thetime:rst = date_now.strftime('%Y-%m-%d %H:%M')elif len(thetime)== 11:rst = str(date_now.year) + '-' + thetimeelse:rst = thetimereturn rst最后是 main 函数
def main():pbar = tqdm(eduSHcode) # 进度条for symbol in pbar:pbar.set_description('Processing '+symbol)scrape_symbol(symbol)print('OK')if __name__ == '__main__':main()追加的需求
我还需要获取股票的历史数据(虽然很容易下载到),在网页上选择区间统计,近三年,得到请求URL
https://stock.xueqiu.com/v5/stock/chart/kline.json?symbol=SZ002607&begin=1548166870391&end=1642774867690&period=day&type=before&indicator=kline
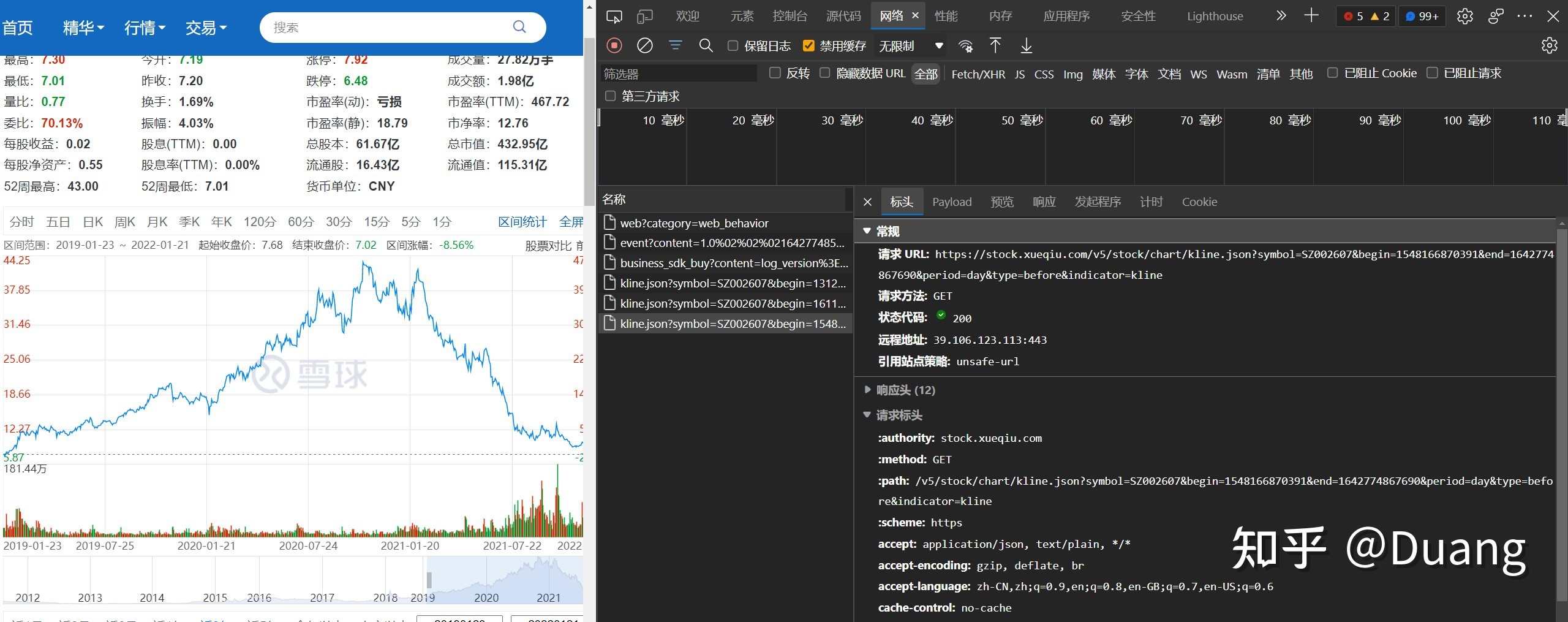
可以看到一次请求就获得所有三年的数据
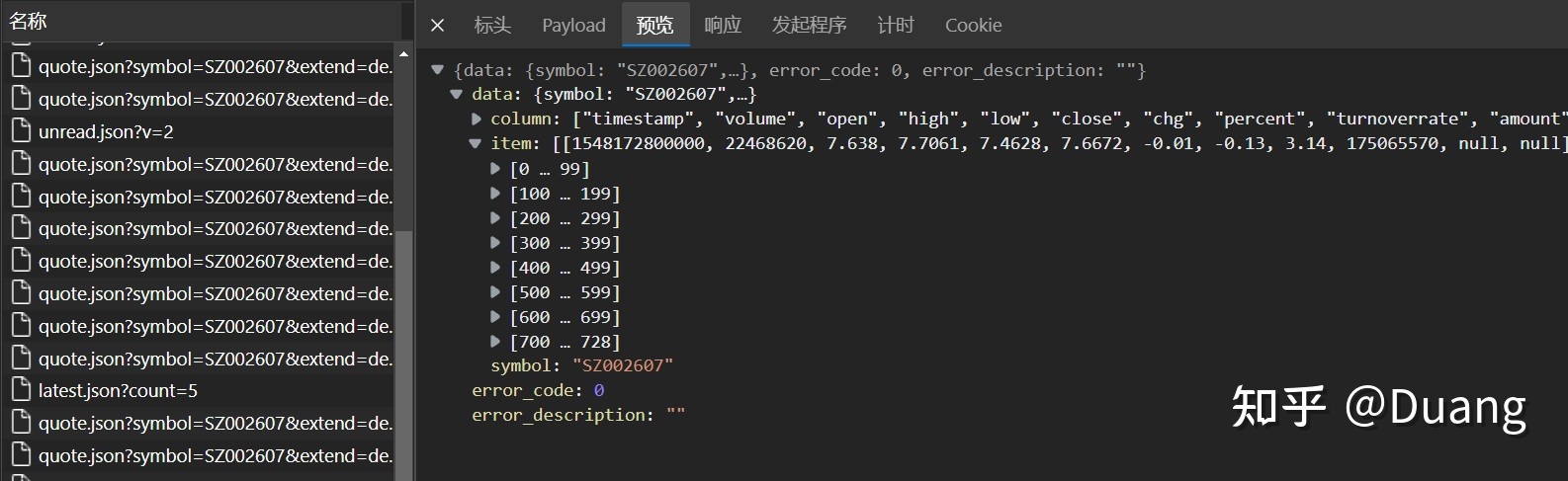
URL 中有三项需要我们自己该,分别是:
- symbol=SZ002607
- begin=1548166870391
- end=1642774867690
symbol 是股票代码,begin 和 end 是起止时间,观察规律+上网搜索得知,这个时间就是 Unix 时间戳,精确到毫秒。尝试发现其后四位(秒)不影响请求结果。
在之前爬虫的基础上改动如下:
更换URL
DATA_URL = 'https://stock.xueqiu.com/v5/stock/chart/kline.json?symbol={symbol}&begin={begin}&end={end}&period=day&type=before&indicator=kline'
生成时间戳
now = datetime.now()
end = int(time.mktime(now.timetuple()))*1000 # *1000 是从秒变毫秒
three_years_ago = now - timedelta(days=365*years)
begin = int(time.mktime(three_years_ago.timetuple()))*1000
两个函数(因为只要一次请求所以不用反复循环)
def scrape_num_symbol(symbol):# 爬取股票数据url = DATA_URL.format(symbol=symbol,begin=begin,end=end) # 将url中空缺的信息填上index_data = scrape_api(url)return index_datadef save_numdata_mongodb(index_data):about = index_data['data']['symbol']keys = index_data['data']['column']pbar = tqdm(index_data['data']['item'],leave=False)for data in pbar:pbar.set_description('saving timestamp '+str(data[0]))result_data = dict(zip(keys,data))result_data['symbol'] = aboutcollection.insert_one(result_data)
至此结束
如果你也想学习Python爬虫的话,这里给大家分享一份Python爬虫学习资料和公开课, 里面的内容都是适合零基础小白的笔记和资料,超多实战案例,不懂编程也能听懂、看懂。需要的话扫描下方二维码免费获得,让我们一起学习!
CSDN大礼包:全网最全《全套Python学习资料》免费分享🎁
😝朋友们如果有需要的话,可以扫描下方二维码免费领取🆓

1️⃣零基础入门
① 学习路线
对于从来没有接触过Python的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

② 路线对应学习视频
还有很多适合0基础入门的学习视频,有了这些视频,轻轻松松上手Python~
③练习题
每节视频课后,都有对应的练习题哦,可以检验学习成果哈哈!

因篇幅有限,仅展示部分资料
2️⃣国内外Python书籍、文档
① 文档和书籍资料

3️⃣Python工具包+项目源码合集
①Python工具包
学习Python常用的开发软件都在这里了!每个都有详细的安装教程,保证你可以安装成功哦!
②Python实战案例
光学理论是没用的,要学会跟着一起敲代码,动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。100+实战案例源码等你来拿!
③Python小游戏源码
如果觉得上面的实战案例有点枯燥,可以试试自己用Python编写小游戏,让你的学习过程中增添一点趣味!
4️⃣Python面试题
我们学会了Python之后,有了技能就可以出去找工作啦!下面这些面试题是都来自阿里、腾讯、字节等一线互联网大厂,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


5️⃣Python兼职渠道
而且学会Python以后,还可以在各大兼职平台接单赚钱,各种兼职渠道+兼职注意事项+如何和客户沟通,我都整理成文档了。


上述所有资料 ⚡️ ,朋友们如果有需要 📦《全套Python学习资料》的,可以扫描下方二维码免费领取 🆓