首先列明参考博文地址:
使用中文维基百科语料库训练一个word2vec模型并使用说明
windows使用opencc中文简体和繁体互转
使用中文维基百科训练word2vec模型
一、下载维基百科中文语料库
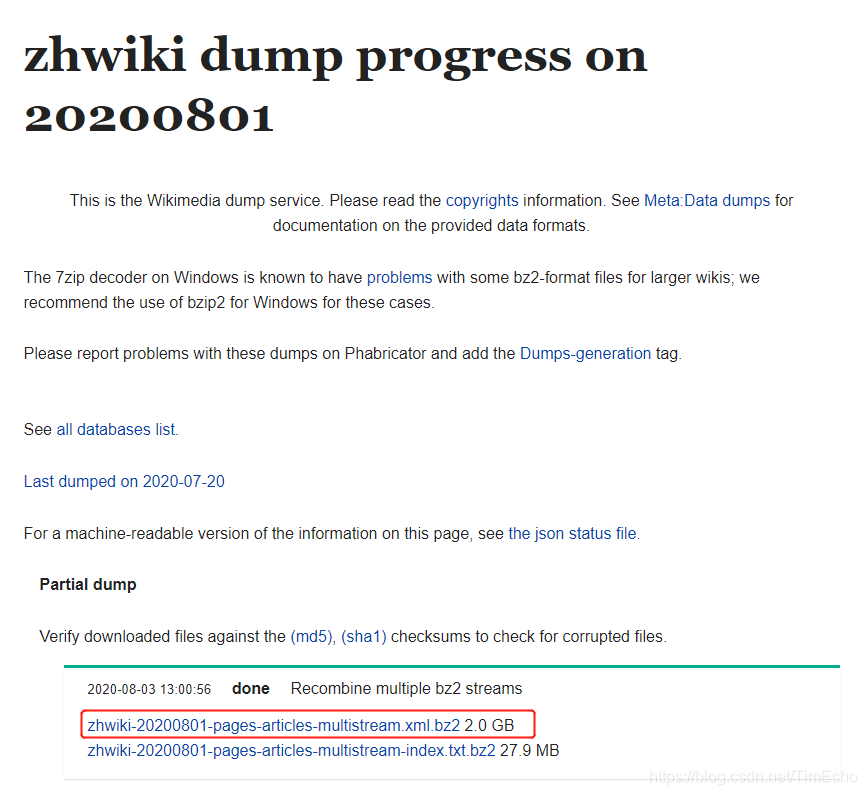
下载地址:https://dumps.wikimedia.org/zhwiki/
这里我选择的是20200801,下载第一个即可
二、语料库处理
1、使用WikiExtractor提取语料库文章
WikiExtractor项目git地址
直接根据说明安装,这里我直接pip

WikiExtractor是一个意大利人写的一个Python脚本专门用来提取维基百科语料库中的文章,将每个文件分割的大小为500M,它是一个通过cmd命令来设置一些参数提取文章。
先找出这个脚本,这个脚本是独立的,放于与语料库同一目录
然后cmd执行以下命令
python WikiExtractor.py -b 500M -o zhwiki zhwiki-20200801-pages-articles-multistream.xml.bz2
提取会产生一个AA文件夹,可以打开查看里边是一些文章
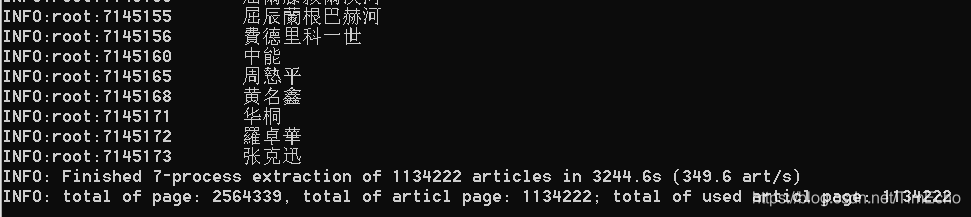
包含714万词条,113万文章
2、繁体转简体
上图发现提取的文章是简体繁体混杂,使用opencc统一转换为简体中文
从文章开头的博文中下载windows下可用的opencc并解压
其中share文件夹下的json文件就是opencc的配置文件,用于简繁体转换
接着在bin目录下cmd
命令格式:
opencc -i 需要转换的文件路径 -o 转换后的文件路径 -c 配置文件路径
这里我将转换后文件保存到BB目录下,t2s.json就是繁体转简体的文件
F:\opencc-1.0.4-win32\opencc-1.0.4\bin>opencc -i F:\wikibaike\zhwiki\AA\wiki_00 -o F:\wikibaike\zhwiki\BB\zh_wiki_00 -c F:\opencc-1.0.4-win32\opencc-1.0.4\share\opencc\t2s.json
三个文件都需要转换

3、提取文章并分词
将多余字符使用正则表达式去除并分词,3个文件都要执行一次
import logging,jieba,os,re
from gensim.models import word2vecdef get_stopwords():logging.basicConfig(format='%(asctime)s:%(levelname)s:%(message)s',level=logging.INFO)#加载停用词表stopword_set = set()with open("./data/stop_words.txt",'r',encoding="utf-8") as stopwords:for stopword in stopwords:stopword_set.add(stopword.strip("\n"))return stopword_set'''
使用正则表达式解析文本
'''
def parse_zhwiki(read_file_path,save_file_path):#过滤掉<doc>regex_str = "[^<doc.*>$]|[^</doc>$]"file = open(read_file_path,"r",encoding="utf-8")#写文件output = open(save_file_path,"w+",encoding="utf-8")content_line = file.readline()#获取停用词表stopwords = get_stopwords()#定义一个字符串变量,表示一篇文章的分词结果article_contents = ""while content_line:match_obj = re.match(regex_str,content_line)content_line = content_line.strip("\n")if len(content_line) > 0:if match_obj:#使用jieba进行分词words = jieba.cut(content_line,cut_all=False)for word in words:if word not in stopwords:article_contents += word+" "else:if len(article_contents) > 0:output.write(article_contents+"\n")article_contents = ""content_line = file.readline()output.close()if __name__ == '__main__':parse_zhwiki('F:\wikibaike\zhwiki\BB\zh_wiki_00', 'F:\wikibaike\zhwiki\CC\wiki_corpus00')
4、合并上边三个文件
'''
合并分词后的文件
'''
def merge_corpus():output = open("F:\wikibaike\zhwiki\CC\wiki_corpus","w",encoding="utf-8")input = "F:\wikibaike\zhwiki\CC"for i in range(3):file_path = os.path.join(input,str("wiki_corpus0%s"%str(i)))file = open(file_path,"r",encoding="utf-8")line = file.readline()while line:output.writelines(line)line = file.readline()file.close()output.close()
三、word2vec模型训练
我的训练过程需要40分钟,迭代了5次
# 训练模型
def main():logging.basicConfig(format="%(asctime)s:%(levelname)s:%(message)s",level=logging.INFO)sentences = word2vec.LineSentence("F:\wikibaike\zhwiki\CC\wiki_corpus")# size:单词向量的维度。model = word2vec.Word2Vec(sentences,size=250)#保存模型model.save("F:\wikibaike\model\wiki_corpus.bin")

训练好的模型包含3个文件
四、模型使用
import logging
from gensim import models# 使用word2vec模型
# 打印日志
logging.basicConfig(format="%(asctime)s:%(levelname)s:%(message)s",level=logging.INFO)
# 加载模型
model = models.Word2Vec.load("./model/wiki_corpus.bin")# 找出 与指定词相似的词
#输入一个词找出相似的前10个词
def top10():one_corpus = ["人工智能"]# ''' 词库中与one_corpus最相似的10个词'''result = model.most_similar(one_corpus[0],topn=10)for i, res in enumerate(result):print(i, ':', res)# 计算两个词的相似度
def similar():# #输入两个词计算相似度two_corpus = ["腾讯", "阿里巴巴"]res = model.similarity(two_corpus[0], two_corpus[1])print("similarity:%.4f" % res)if __name__ == '__main__':similar()
参考博文