java-题库 一、hashMap的底层实现 1.1、hashMap概述 1.2、JDK1.7-扩容源码 1.3、JDK1.7链表迁移过程 1.4、JDK1.8下的扩容机制 二、java面向对象的三大特征 三、JVM相关 四、集合相关 五、JDK1.8新特性 5.1、接口内可以添加非抽象的方法实现 5.2、Lambda表达式 5.3、函数式接口 5.4、Stream API 5.6、引入了ForkJoin框架 5.7、引入了新的日期API LocalDate | LocalTime | LocalDateTime 六、抽象类和接口的区别 七、==和eques区别
HashMap基于Map接口实现,键值对存储,允许使用null 建和null值。 HashMap无序的,HashMap线程不安全。 public class HashMap < K , V > extends AbstractMap < K , V > implements Map < K , V > , Cloneable , Serializable { void resize ( int newCapacity) { Entry [ ] oldTable = table; int oldCapacity = oldTable. length; if ( oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer . MAX_VALUE; return ; } Entry [ ] newTable = new Entry [ newCapacity] ; transfer ( newTable, initHashSeedAsNeeded ( newCapacity) ) ; table = newTable; threshold = ( int ) Math . min ( newCapacity * loadFactor, MAXIMUM_CAPACITY + 1 ) ; } void transfer ( Entry [ ] newTable, boolean rehash) { int newCapacity = newTable. length; for ( Entry < K , V > : table) { while ( null != e) { Entry < K , V > = e. next; if ( rehash) { e. hash = null == e. key ? 0 : hash ( e. key) ; } int i = indexFor ( e. hash, newCapacity) ; e. next = newTable[ i] ; newTable[ i] = e; e = next; } } } }
e. next = newTable[ i] ; newTable[ i] = e; e = next;
假设HashMap的存储状态如下 第一次处理e e. next = newTable[ i]
对oldTable进行遍历的过程中,取出元素e,假设先取出图中的元素e,
在执行这行代码时,相当于断开x位置e与e1的链表关系,并与newTable[ i] 建立链表关系,
此时newTable[ i] 位置为null newTable[ i] = e此时将oldTable中的e复制到newTable中的i位置,同时链表e指向null
while ( null != e) { Entry < K , V > = e. next; if ( rehash) { e. hash = null == e. key ? 0 : hash ( e. key) ; } . . . . . .
}
Entry < K , V > = e. next; e. next = newTable[ i] newTable[ i] = e
链表顺序:开始为e-- > e1-- > e2
完成扩容后:e2-- > e1-- > e
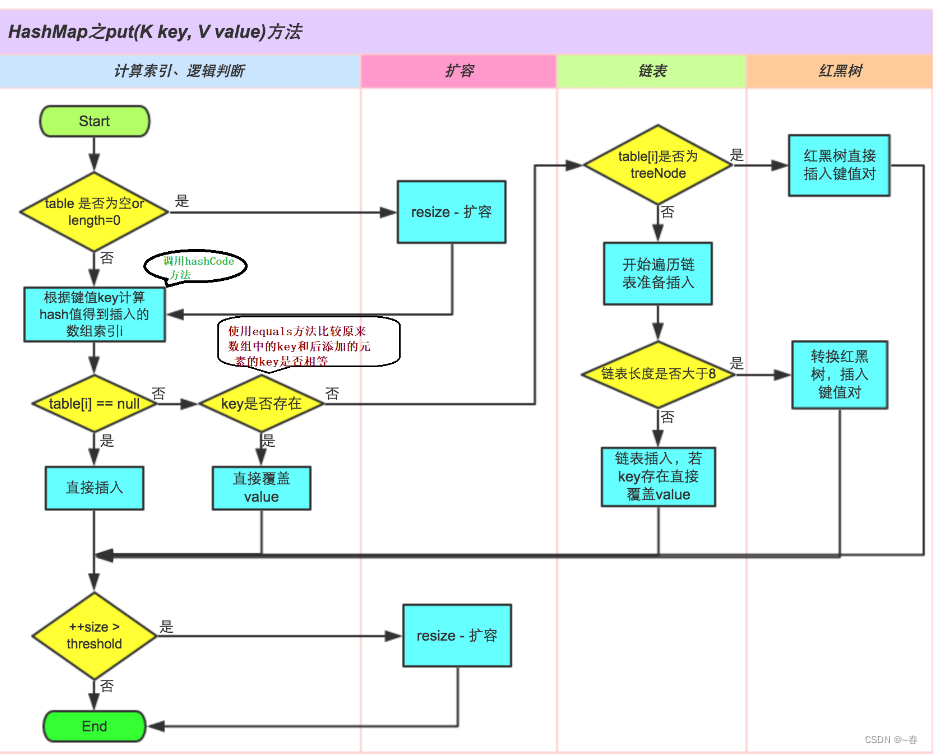
底层实现由之前的 “数组+链表” 改为 “数组+链表+红黑树”。 当链表节点较少时仍然是以链表存在,当链表节点较多时(大于8)且数组的长度大于64,时会转为红黑树 public V put ( K key, V value) { return putVal ( hash ( key) , key, value, false , true ) ; } final V putVal ( int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node < K , V > [ ] tab; Node < K , V > ; int n, i; if ( ( tab = table) == null || ( n = tab. length) == 0 ) n = ( tab = resize ( ) ) . length; if ( ( p = tab[ i = ( n - 1 ) & hash] ) == null ) tab[ i] = newNode ( hash, key, value, null ) ; else { Node < K , V > ; K k; if ( p. hash == hash && ( ( k = p. key) == key || ( key != null && key. equals ( k) ) ) ) e = p; else if ( p instanceof TreeNode ) e = ( ( TreeNode < K , V > ) p) . putTreeVal ( this , tab, hash, key, value) ; else { for ( int binCount = 0 ; ; ++ binCount) { if ( ( e = p. next) == null ) { p. next = newNode ( hash, key, value, null ) ; if ( binCount >= TREEIFY_THRESHOLD - 1 ) treeifyBin ( tab, hash) ; break ; } if ( e. hash == hash && ( ( k = e. key) == key || ( key != null && key. equals ( k) ) ) ) break ; p = e; } } if ( e != null ) { V oldValue = e. value; if ( ! onlyIfAbsent || oldValue == null ) e. value = value; afterNodeAccess ( e) ; return oldValue; } } ++ modCount; if ( ++ size > threshold) resize ( ) ; afterNodeInsertion ( evict) ; return null ; }
1 、封装:属性私有化,提供setter和getter方法
2 、继承:继承是指将多个相同的属性和方法提取出来,新建一个父类
3 、多态:分为两种:设计时多态、运行时多态
第一代线程安全集合类Vector. Hashtable 是怎么保证线程安排的:使用synchronized 修饰方法缺点:效率低下第二代线程非安全集合类ArrayList , HashMap 线程不安全,但是性能好,用来替代Vector 、Hashtable 使用ArrayList 、HashMap , 需要线程安全怎么办呢?使用 Collections . synchronizedList ( list) ; Collections . synchronizedMap ( m) ; 第三代线程安全集合类在大量并发情况下如何提高集合的效率和安全呢?java. utll. concurrent. *ConcurrentHashMap : CopyOnWriteArrayList : CopyOnWriteArraySet : 注意不是 CopyOnWriteHashSet * 底层大都采用Lock 锁( 1.8 的ConcurrentHashMap 不使用LocktW , 保证安全的同时,性能也很高.
java 8 允许我们给接口添加一个非抽象的方法实现,只需要使用ddefault关键字即
可,这个特征又叫做犷展方法, 代码如下:interface Formula { double calculatefint a) ; default double sqrt ( int a) { return Math . sqrt ( a) ; } } Formula 接口在拥有calculate方法之外同时还定义了sqrt方法, 实现了Formula 接口的子类
只需要实现calculate方法,默认方法sqrl将在子类上可以直接使用.
Lambda 规定接口中只能有一个需要被实现的方法。
函数式接口的提出是为了给Lambda表达式的使用提供更好的支持。 简单来说就是只定义了一个抽象方法的接口(Object类的public方法除外),就是函数式接口,并且还提供了注解@FunctionalInterface Stream操作的三个步骤:创建stream,中间操作,终止操作 创建stream List < String > = new ArrayList < > ( ) ; Strean < String > = list. stream ( ) ; String [ ] str = new String [ 10 ] ; Stream < String > = Arrays . stream ( str) ; Stream < String > = Stream . of ( "aa" , "bb" , "cc" ) ; Stream < Integer > = Stream . iterate ( 0 , ( x) -> x+ 2 ) ; Stream . generate ( ( ) -> Math . random ( ) ) ;
emps. stream ( ) . filter ( e -> e. getAge ( ) > 10 ) . limit ( 4 ) . skip ( 4 ) . distinct ( ) . forEach ( System . out:: println ) ; emps. stream ( ) . map ( ( e) -> e. getAge ( ) ) . forEach ( System . out:: println ) ; emps. stream ( ) . sorted ( ( e1 , e2) -> { if ( e1. getAge ( ) . equals ( e2. getAge ( ) ) ) { return e1. getName ( ) . compareTo ( e2. getName ( ) ) ; } else { return e1. getAge ( ) . compareTo ( e2. getAge ( ) ) ; } } ) . forEach ( System . out:: println ) ; boolean b1 = emps. stream ( ) . allMatch ( ( e) -> e. getStatus ( ) . equals ( Employee. Status . BUSY) ) ; System . out. println ( b1) ; boolean b2 = emps. stream ( ) . anyMatch ( ( e) -> e. getStatus ( ) . equals ( Employee. Status . BUSY) ) ; System . out. println ( b2) ; boolean b3 = emps. stream ( ) . noneMatch ( ( e) -> e. getStatus ( ) . equals ( Employee. Status . BUSY) ) ; System . out. println ( b3) ; Optional < Employee > = emps. stream ( ) . findFirst ( ) ; System . out. println ( opt. get ( ) ) ; Optional < Employee > = emps. parallelStream ( ) . findAny ( ) ; System . out. println ( opt2. get ( ) ) ; long count = emps. stream ( ) . count ( ) ; System . out. println ( count) ; Optional < Employee > = emps. stream ( ) . max ( ( e1, e2) -> Double . compare ( e1. getSalary ( ) , e2. getSalary ( ) ) ) ; System . out. println ( max. get ( ) ) ; Optional < Employee > = emps. stream ( ) . min ( ( e1, e2) -> Double . compare ( e1. getSalary ( ) , e2. getSalary ( ) ) ) ; System . out. println ( min. get ( ) ) ;
就是在必要的情况下,将一个大任务,进行拆分(fork)成若干个小任务(拆到不可再拆时),再将一个个的小任务运算的结果进行 join 汇总
public class ForkJoin extends RecursiveTask < Long > { private static final long serialVersionUID = 23423422L ; private long start; private long end; public ForkJoin ( ) { } public ForkJoin ( long start, long end) { this . start = start; this . end = end; } private static final long THRESHOLD = 10000L ; @Override protected Long compute ( ) { if ( end - start <= THRESHOLD) { long sum = 0 ; for ( long i = start; i < end; i++ ) { sum += i; } return sum; } else { long middle = ( end - start) / 2 ; ForkJoin left = new ForkJoin ( start, middle) ; left. fork ( ) ; ForkJoin right = new ForkJoin ( middle + 1 , end) ; right. fork ( ) ; return left. join ( ) + right. join ( ) ; } } @Test public void test1 ( ) { Instant start = Instant . now ( ) ; ForkJoinPool pool = new ForkJoinPool ( ) ; ForkJoinTask < Long > = new ForkJoin ( 0L , 10000000000L ) ; long sum = pool. invoke ( task) ; Instant end = Instant . now ( ) ; System . out. println ( Duration . between ( start, end) . getSeconds ( ) ) ; } @Test public void test2 ( ) { Instant start = Instant . now ( ) ; LongStream . rangeClosed ( 0 , 10000000000L ) . parallel ( ) . reduce ( 0 , Long :: sum ) ; Instant end = Instant . now ( ) ; System . out. println ( Duration . between ( start, end) . getSeconds ( ) ) ; } @Test public void test3 ( ) { List < Integer > = Arrays . asList ( 1 , 2 , 3 , 4 , 5 ) ; list. stream ( ) . forEach ( System . out:: print ) ; list. parallelStream ( ) . forEach ( System . out:: print ) ; }
@Test public void test ( ) { LocalDateTime date = LocalDateTime . now ( ) ; System . out. println ( date) ; System . out. println ( date. getYear ( ) ) ; System . out. println ( date. getMonthValue ( ) ) ; System . out. println ( date. getDayOfMonth ( ) ) ; System . out. println ( date. getHour ( ) ) ; System . out. println ( date. getMinute ( ) ) ; System . out. println ( date. getSecond ( ) ) ; System . out. println ( date. getNano ( ) ) ; LocalDateTime date2 = LocalDateTime . of ( 2017 , 12 , 17 , 9 , 31 , 31 , 31 ) ; System . out. println ( date2) ; LocalDateTime date3 = date2. plusDays ( 12 ) ; System . out. println ( date3) ; LocalDateTime date4 = date3. minusYears ( 2 ) ; System . out. println ( date4) ; } LocalDate today = LocalDate . now ( ) ; LocalDate oldDate = LocalDate . of ( 2018 , 5 , 1 ) ; LocalDate yesteday = LocalDate . parse ( "2018-05-03" ) ; LocalDate . parse ( "2018-02-28" ) ; == 号在比较基本数据类型时比较的是值,而用== 号比较两个对象时比较的是两个对象的地址值。
equals()方法存在于Object类中,因为Object类是所有类的直接或间接父类,也就是说所有的类中的equals()方法都继承自Object类,而通过源码我们发现,Object类中equals()方法底层依赖的是== 号,那么,在所有没有重写equals()方法的类中,调用equals()方法其实和使用== 号的效果一样,也是比较的地址值,然而,Java提供的所有类中,绝大多数类都重写了equals()方法,重写后的equals()方法一般都是比较两个对象的值.