最近在公司做了一个构建卷积神经网络来识别字符的项目,编程环境为pycharm2019,使用的是OpenCv+Pytorch进行项目的实现,因此想总结和归纳一下方法。
本次的字符识别项目可以分为以下几个步骤:
一、图像处理和字符分割
二、创建自己的训练集和测试集,为训练集和验证集添加标签
三、重新定义Dataloader函数加载自己的数据集
四、构建卷积神经网络、训练神经网络并测试识别的正确率
五、简单图形界面的实现
一、图像处理和字符分割
要做字符图像的预处理和准确的字符分割,首先要我们要处理的图像是怎么样的,如图所示就是我这次要识别的工业上的字符图像。
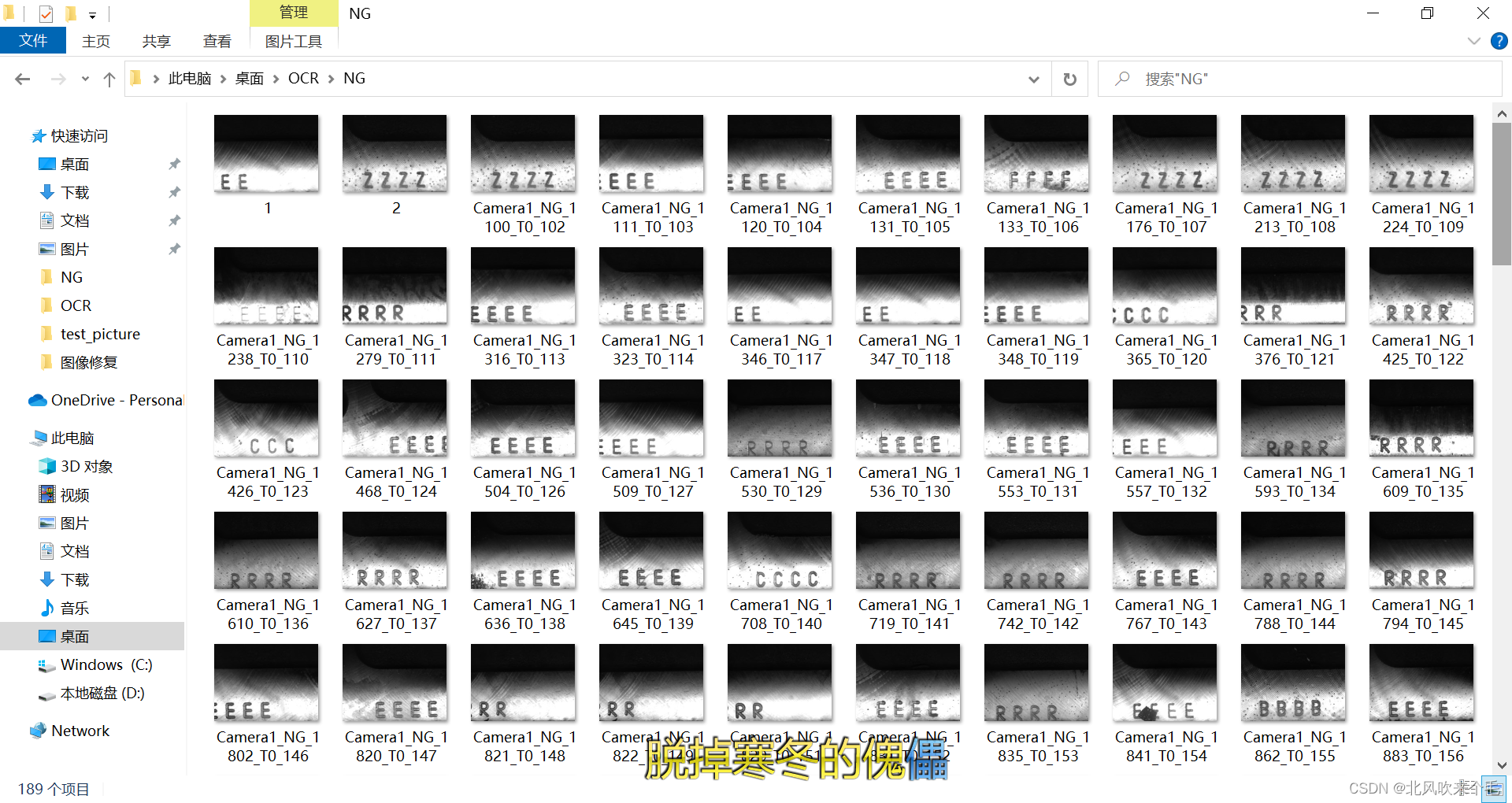




可以看到我们要去掉的噪声有两种,一种是图片中比较细小的噪声,一种是比较大的黑点,其中最难去掉的是这种比较大的黑点,它一般都是与字符黏在一起,如果处理不好则有可能会消除掉与其黏在一起的字符特征,从而影响识别出正确的字符。在这里我们使用OpenCv模块进行图像预处理,其中内容包括以下几个步骤:
1、图像融合
这里使用一张与要识别的字符图像大小一样的纯白色图像与字符图像进行融合,目的是让像素点差别更大,以便更容易地识别出字符。说白了就是让黑的地方更黑,让白的地方更白。


2、重置图像大小
使用cv2.resize()函数把图像重置为256x256大小的图像。
3、图像开运算
使用cv2.morphologyEx()函数对图像再进行开运算,卷积核为7x3大小,目的是去除较小的噪声。

4、图像滤波去噪声
使用cv2.blur()函数和cv2.GaussianBlur()函数(前者为均值滤波,后者为高斯滤波)去除噪声。ps:由于使用开运算以及滤波函数进行去除噪声之后的图像效果只能说是一般般,能够去除小噪声,目前试过最后的方法就是使用图像开运算和均值滤波及高斯滤波来去噪,此前有想过使用边缘检测、膨胀、侵蚀等来去除大黑点噪声,但是由于字符背景的像素变化不大,会影响到所有字符的特征因此只能作罢,采用这一般般的效果,如果后面处理图像的算法有极大的改进会更新。
本人也有考虑过使用图像的像素值和连通性来处理图像,去除大噪声,如遍历图像中所有的像素点,设置一个像素阈值,使小于阈值的像素点都为255,其余像素值不变,来处理字符图像,经过处理之后有大黑点噪声的图像都能完完整整分割出来,但没有大黑点噪声的图像其中的字符特征就会有一定程度的像素值缺失,导致识别率的下降,因此也只能作罢。

5、图像转化灰度图、图像二值化
使用cv2.cvtColor()函数把去除噪声后的图像转化为灰度图,之后使用自适应阈值二值化cv2.adaptiveThreshold()函数把图像转为二值图像,即大于阈值的像素值置为255,小于阈值的像素值置为0。

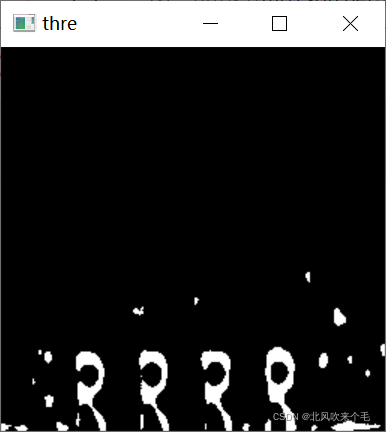
6、查找图像轮廓、绘制轮廓并显示
使用cv2.findContours()函数查找图像所有的轮廓,使用cv2.drawContours()函数绘制轮廓,并使用cv2.imshow()函数进行显示。

7、保存轮廓信息到列表,等待识别
使用cv2.boundingRect函数把各个找到的轮廓坐标、宽和高分别赋值给x、y、w、h,接着根据找到的轮廓的面积和坐标值等条件找到需要的字符图像,并使用cv2.rectangle()函数把字符图像信息保存到前面定义的空列表中,等待训练数据后识别。(x为矩形框的左上角坐标值,y为矩形框的左上角坐标值,w为矩形框的宽度,h为矩形框的高度)

至此,图像的预处理和字符分割完成。
二、创建自己的训练集和验证集,为训练集和验证集添加标签
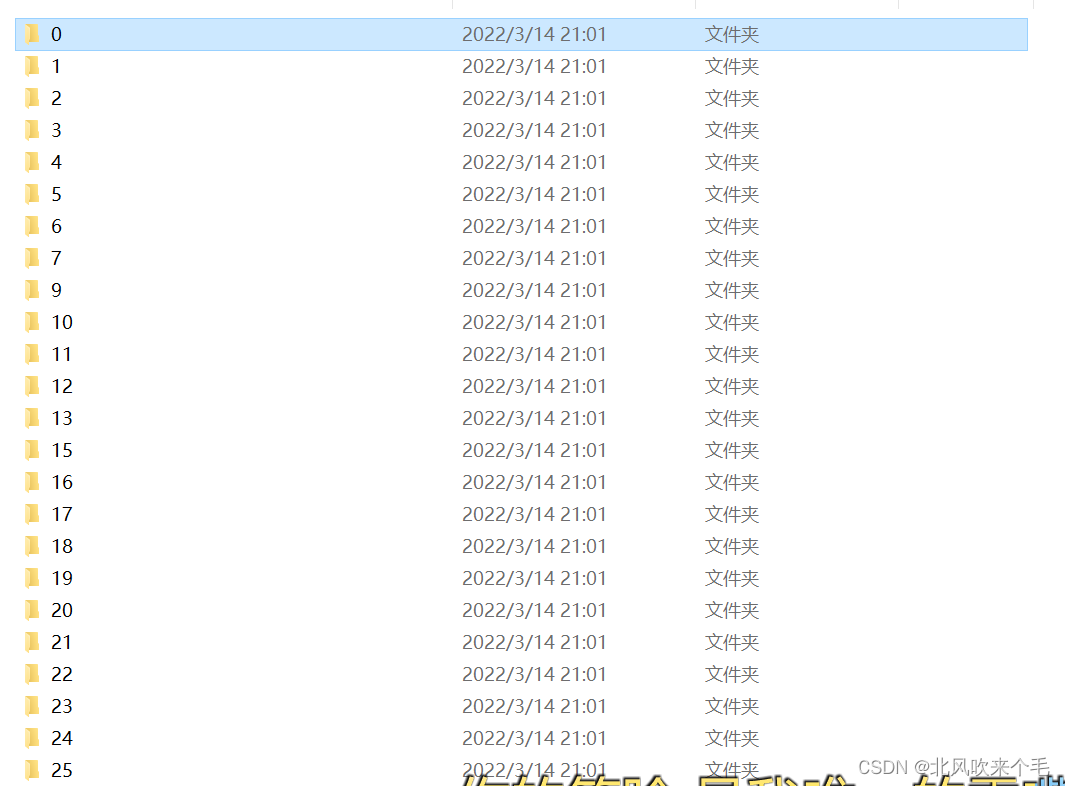
1、创建数据集、重新命名文件夹名称。
由于此处的项目只用识别26个字母,因此我选用的是车牌识别的英文字母数据集当作自己的数据集,从A字母文件夹到Z文件夹重新以数字0-25命名,并把文件夹名当作训练标签,验证集也是一样的道理。命名完成后如图:
2、制作自己的训练集标签和,验证集标签。
首先使用os模块遍历训练集中的各个文件夹下的训练图像,把进行训练的图像路径和标签(标签为训练的文件夹名,A为0,...,Z为25),存到label.txt文本里,其中图像路径和标签以“\\”符号隔开,每张图像信息存完进行换行处理。测试集同理,存为test_label.txt文本。存好的训练集和测试集如图:
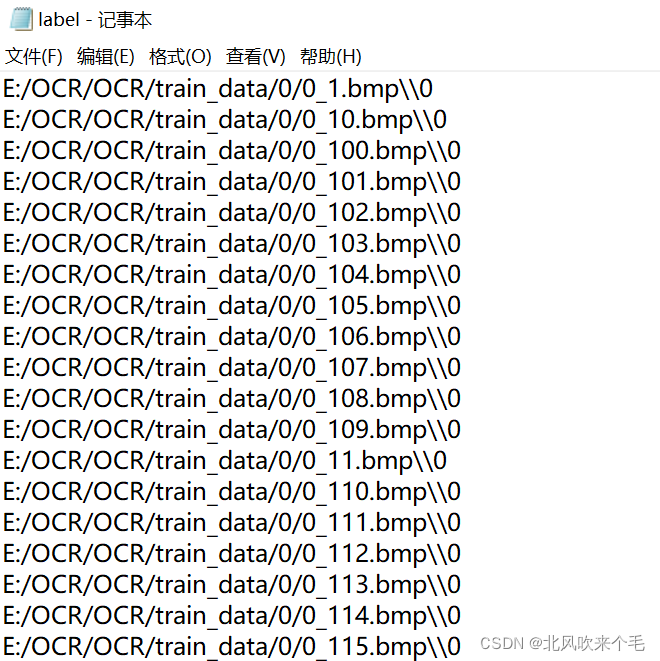
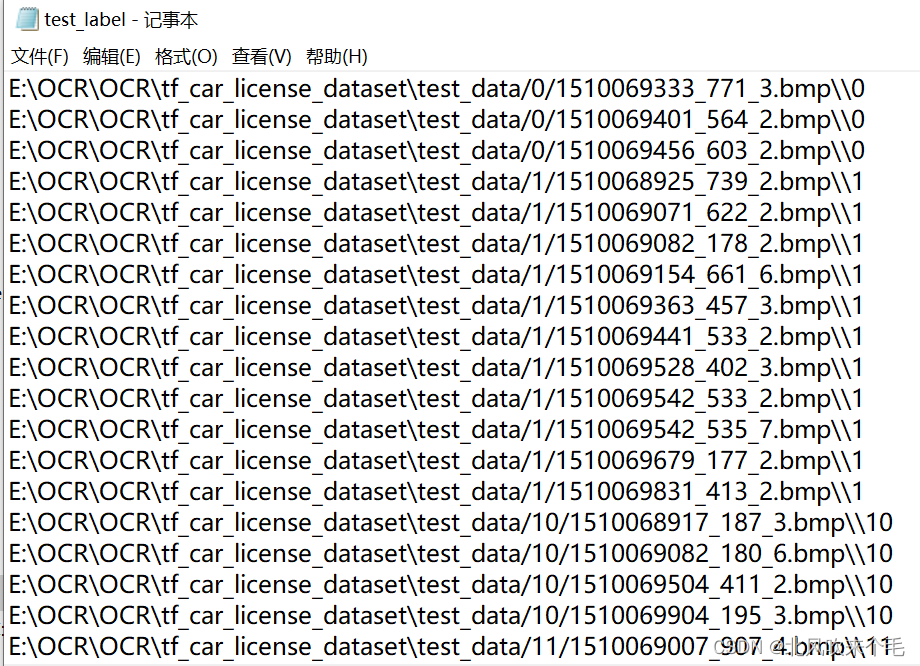
至此,训练集和验证集的标签制作完成。
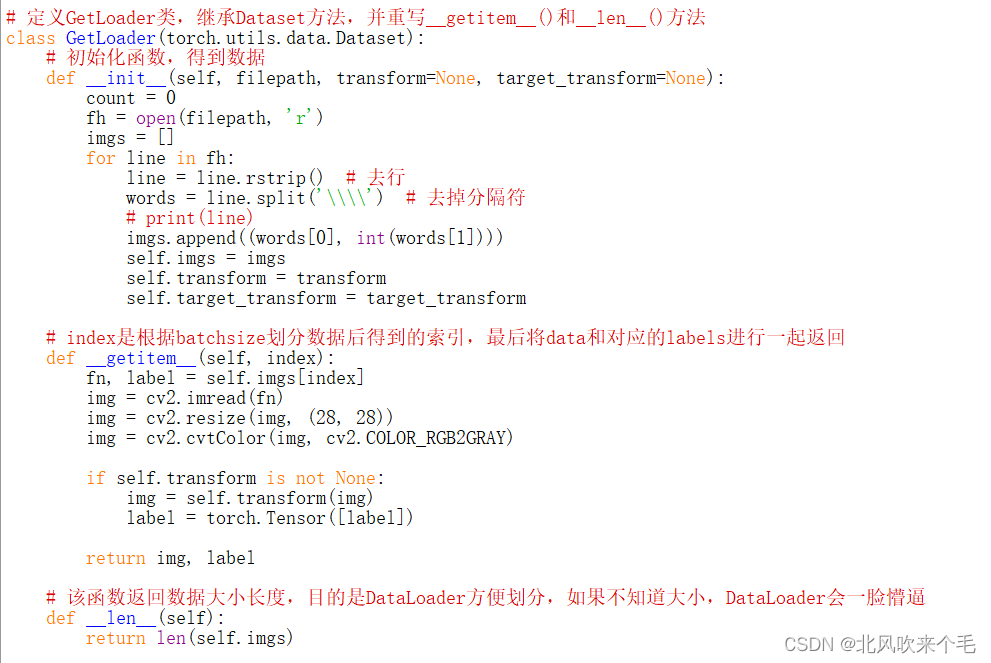
三、重新定义DataLoader函数加载自己的数据集
重新定义的DataLoader函数(继承至torch.utils.data.Dataset父类)包括三个需要重新定义的函数(这里参考的是大佬的文章,但具体是谁我忘了,因此就没有给出链接):
1、初始化函数__init__()函数:
我定义的函数的参数有三个:存有训练图像/测试图像路径和对应标签的txt文件路径filepath,把数值转化为张量的函数transform和target_transform,不过这里只使用了transform函数。
先根据输入的路径打开txt文件,并通过for循环遍历其中的数据,得到的是图像路径和标签混合在一起的一串数据,接着使用txt.strip()函数去掉其中的换行符,由于之前我们是用符号“\\\\”进行图像路径和标签分割的,因此这里我们使用split()函数把图像路径和对应的标签进行分隔,并以(图像路径,标签)的元组形式存入到空列表imgs里,方便后面的使用。
2、返回图像数据和标签的__getitem()__函数:
这里的index参数为根据batch_size划分得到的索引,根据索引index可以得到txt文件中的图像路径和标签。
由于初始化函数中列表imgs存入了图像路径和标签的元组,因此输出imgs的元组需要赋值给fn和label这两个变量,接着使用cv2.imread()函数读出每个路径的信息,并重置训练图像为28x28,设置为灰度图。这里的图像数据和标签数据都需要转化成张量,因此在这添加了一个条件,当transform不为空时,则使用外部定义的转化为张量的函数transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor()])把图像数据和标签数据都转化为张量形式,最后返回图像数据和标签数据。
3、返回图像的训练集/测试集大小的__len()__函数
重新定义DataLoader()函数之后就可以加载我们自己的数据集了,如图所示:

至此,自己数据集的加载完成。
四、构建卷积神经网络
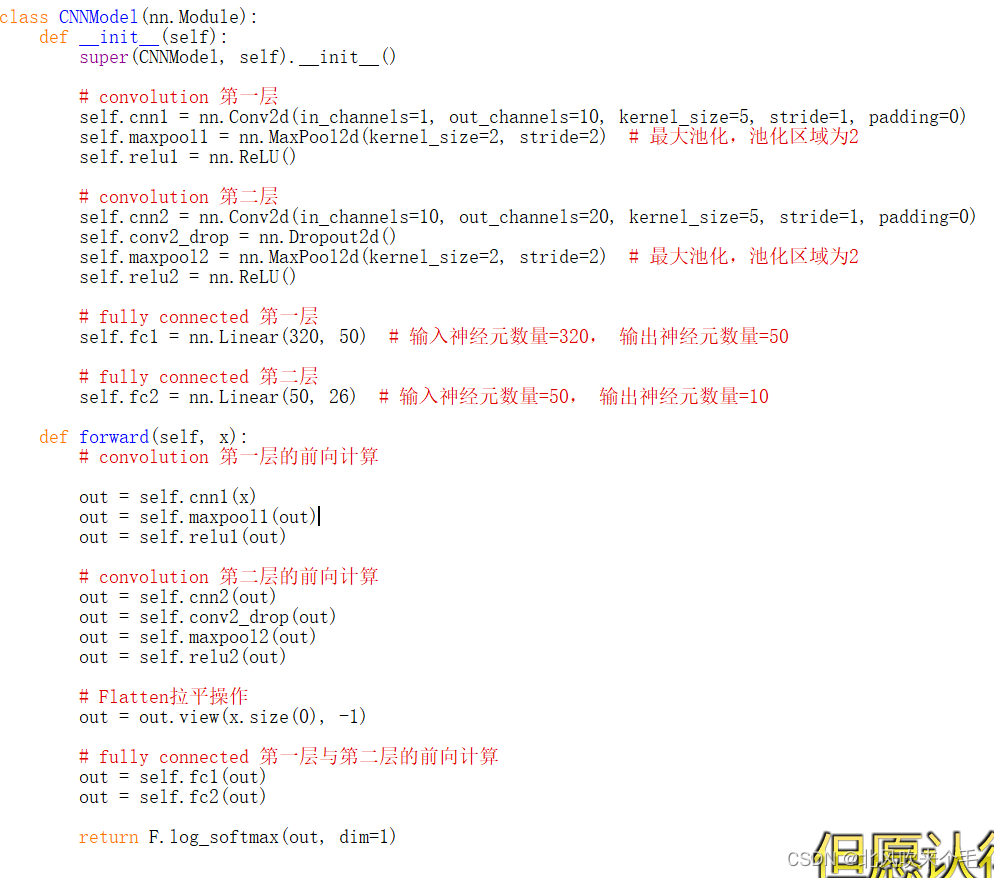
1、卷积神经网络构成:
(1)、第一层隐藏层包括卷积层(输入通道为1,输出通道为10,卷积核大小为5x5,步长为1,padding为0,作用是进行图像数据的主要数据特征的提取)、池化层(使用最大池化,kernel_size为2x2,步长为2,目的是进行数据的降维处理)、激活函数(使用ReLU激活函数)。
第二层隐藏层包括卷积层(输入通道为10,输出通道为20,卷积核大小为5x5,步长为1,padding为0,作用是进行图像数据的主要数据特征的提取)、Dropout函数的作用为防止数据的过拟合(在训练集上表现良好,在测试集里表现较差),池化层(使用最大池化,kernel_size为2x2,步长为2,目的是进行数据的降维处理)、激活函数(使用ReLU激活函数)。
(2)、拉平操作:将多维的输入变成一维的输入。
(3)、第一层全连接层输入神经元数量为320,输出神经元数量为50;
第二层全连接层输入神经元数量为50,输出神经元数量为26(全连接层的作用是分类器);
(4)、F.log_softmax()函数:对行进行归一化,返回样本的最大概率。
2、训练函数:
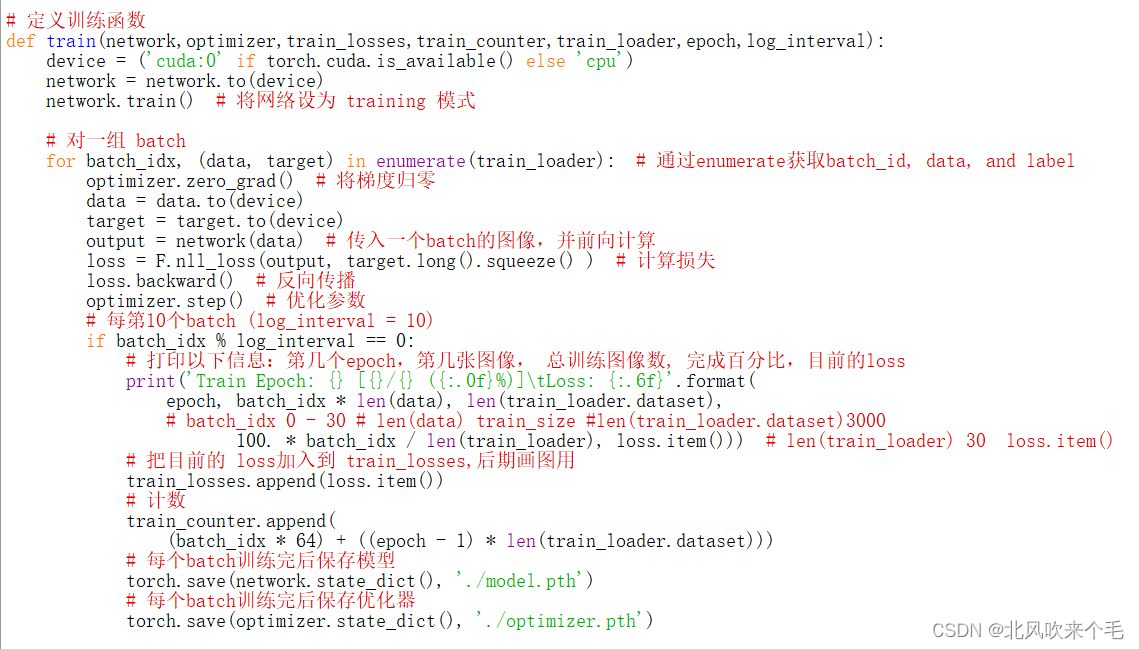
(1)使用network=CNNMoudle()将网络进行实例化,并使用optim.SGD()函数将优化器设置为随机梯度下降模式。
(2)首先检测设备是否有GPU,有就使用GPU进行训练,没有就使用CPU进行训练,并使用network.train()函数将网络设置为train模式,接着加载我们自己的训练集,将要训练的图像数据和标签分别赋值给data变量和target变量。
(3)将SGD优化器进行梯度归零操作,把data变量和target变量转化为GPU需要的张量(此次调用GPU训练因此需要进行转化,不调用就不转化),接着每次传入一个batch的图像并进行前向计算、计算损失、反向传播、优化参数等操作,打印出当前的epoch、当前图像、总训练图像、完成总训练的图像百分比、目前的损失值loss。
(4)调用torch.save(network.state_dict(), './model.pth')函数将当前训练好的模型保存到当前的文件夹目录下;调用torch.save(optimizer.state_dict(), './optimizer.pth')函数将当前训练好的优化器模型到当前的文件夹目录下。
3、测试函数:
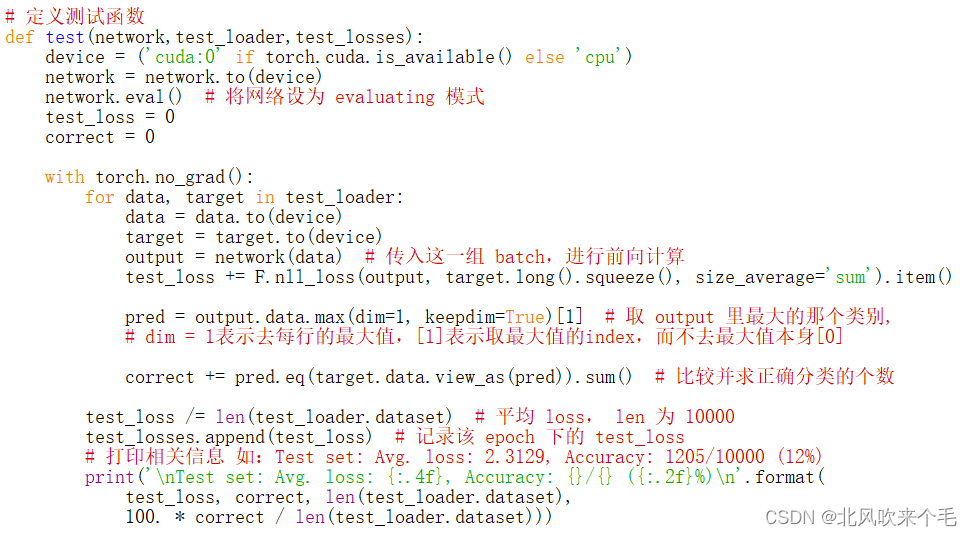
(1)使用network=CNNMoudle()将网络进行实例化,首先检测设备是否有GPU,有就使用GPU进行训练,没有就使用CPU进行训练,并使用network.eval()函数将网络设置为eval模式,接着加载我们自己的测试集,将要训练的图像数据和标签分别赋值给data变量和target变量。
(2)把data变量和target变量转化为GPU需要的张量(此次调用GPU训练因此需要进行转化,不调用就不转化),接着每次传入一个batch的图像并进行前向计算、计算损失,计算出output最大的类别并求出正确分类个数等操作,打印出损失值loss、正确识别的个数/总数、正确率等。
至此,卷积神经网络构建完成,开始进行训练,训练准确率如下图所示。
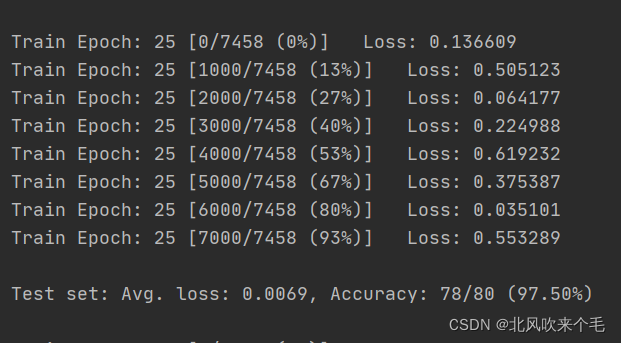
(ps: 此卷积神经网络的搭建大部分参考的是贵州理工学院计算机视觉霍雨佳老师搭建的手写数字手写体识别的卷积神经网络)
(4)调用模型测试
首先判断是否调用GPU,接着实例化自己的CNN模型,加载训练好的model.pth模型,将网络设置为eval模式,由于调用GPU需要将图像数据转化成GPU所需张量,因此需要使用torchvision.transforms.Compose()函数转化。

接着需要先将要识别的图像进行预处理、字符分割等操作,具体参考第一章。将要识别的图像进行字符分割所得的图像数据存入列表后,遍历列表中的每个图像数据,并进行以下步骤操作:先将图像重置大小为28x28,将图像转化为GPU所需要的张量,在data中的0位置添加一个维度,调用模型传入图像数据data,使用torch.max函数得到最大概率值的索引index,index.item()最后返回标签,为数字0-25。

由于最后得到的是标签而不是准确的字符输出,因此需要使用字典进行转换,关键字为标签,变量为标签所对应的字符。最后使用print('识别的图像为:{0}, 识别的结果是{1}'.format(img_label[i][0], label[index]))打印输出识别的图像和识别的结果。

五、简单图形界面的实现
1、此次项目为了更直观的看到实现的算法效果,于是我用tkinter模块做了一个简单的图形界面,其中的功能包括显示要识别的图形、识别的结果标签、识别字符的正确率标签、选择文件夹识别按钮、选择图片识别按钮、运行识别按钮、退出系统按钮。

2、选择图片识别函数:
使用tkinter模块中的filedialog.askopenfilename()函数访问图像路径,initaldir参数为初始的访问路径,返回选择图片的路径,若没有选择图片,则显示文件夹中的一张图片。

3、选择文件夹识别函数:
使用tkinter模块中的filedialog.askdirectory()函数访问图像路径,initaldir参数为初始的访问路径,返回选择文件夹的路径,若没有选择图片,则显示文件夹中的一张图片。

4、识别运行函数:
ocr()函数为识别选择图像或选择文件夹所有图像的函数,返回的值分别为图像识别结果集合、识别分割图片的正确率、运行时间。

5、选择图像识别结果显示:
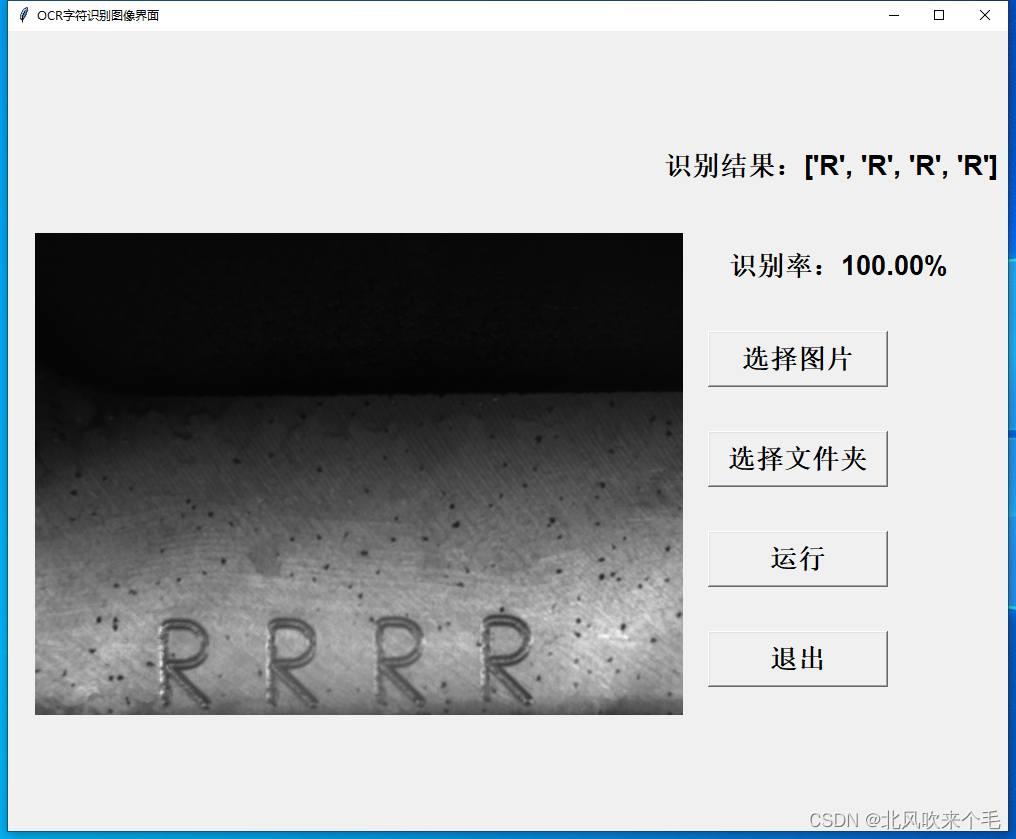
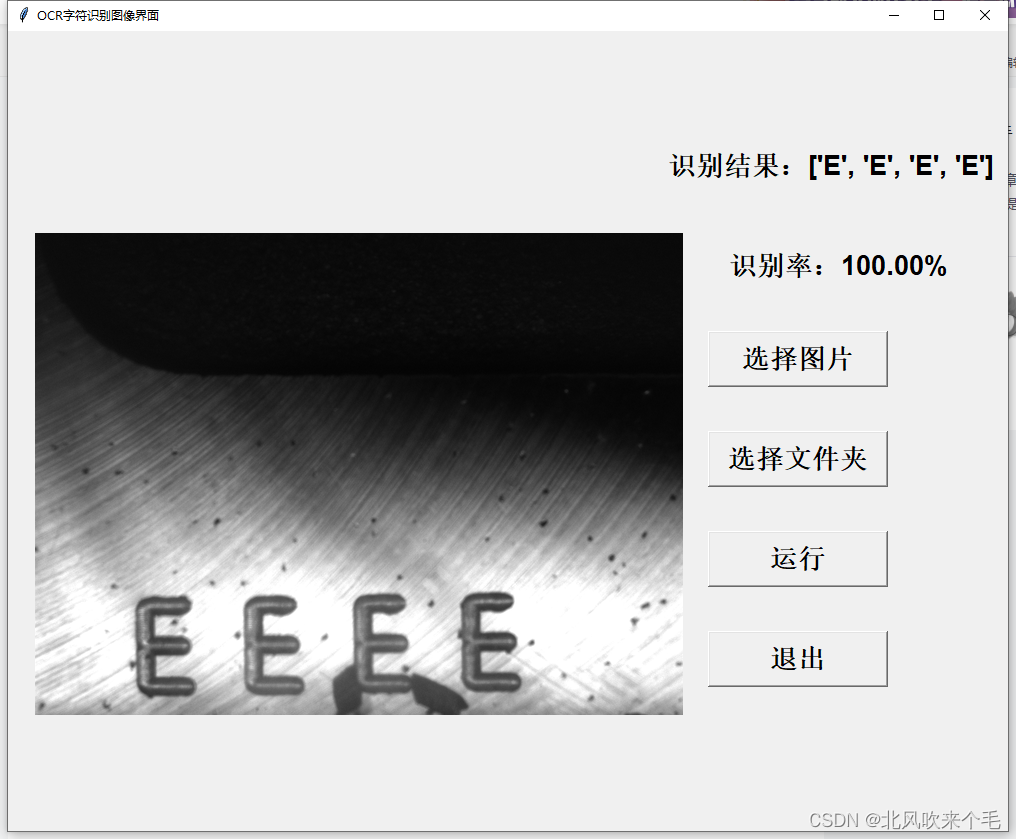
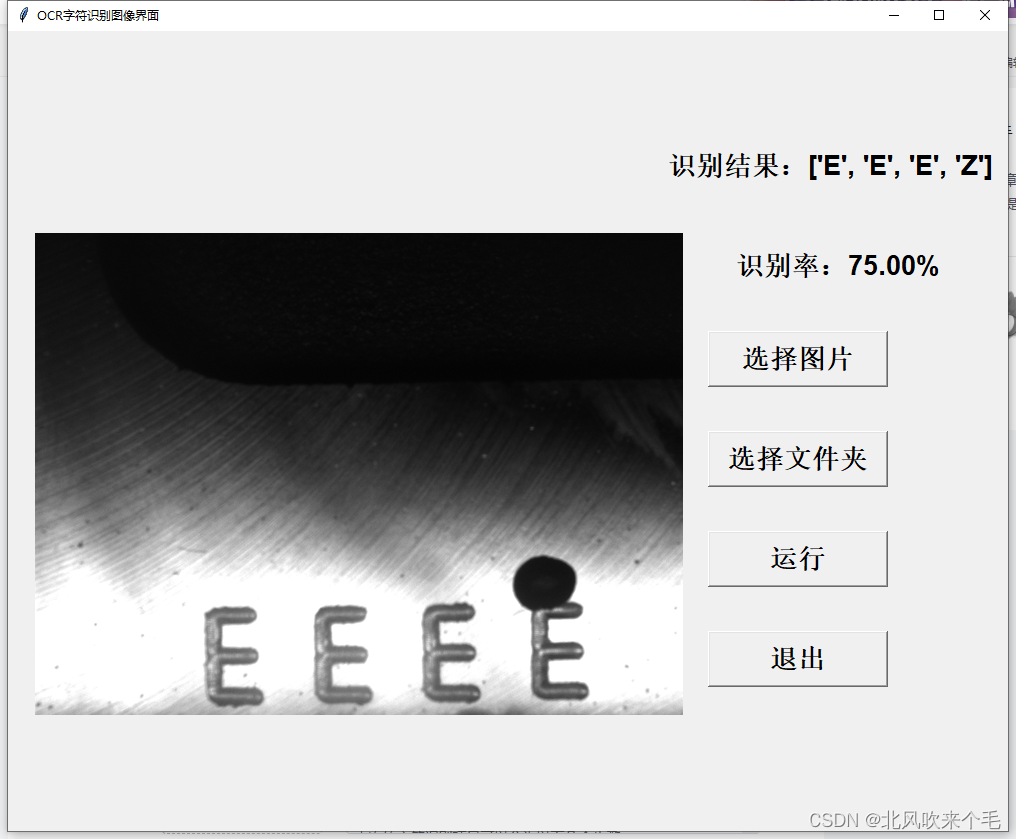
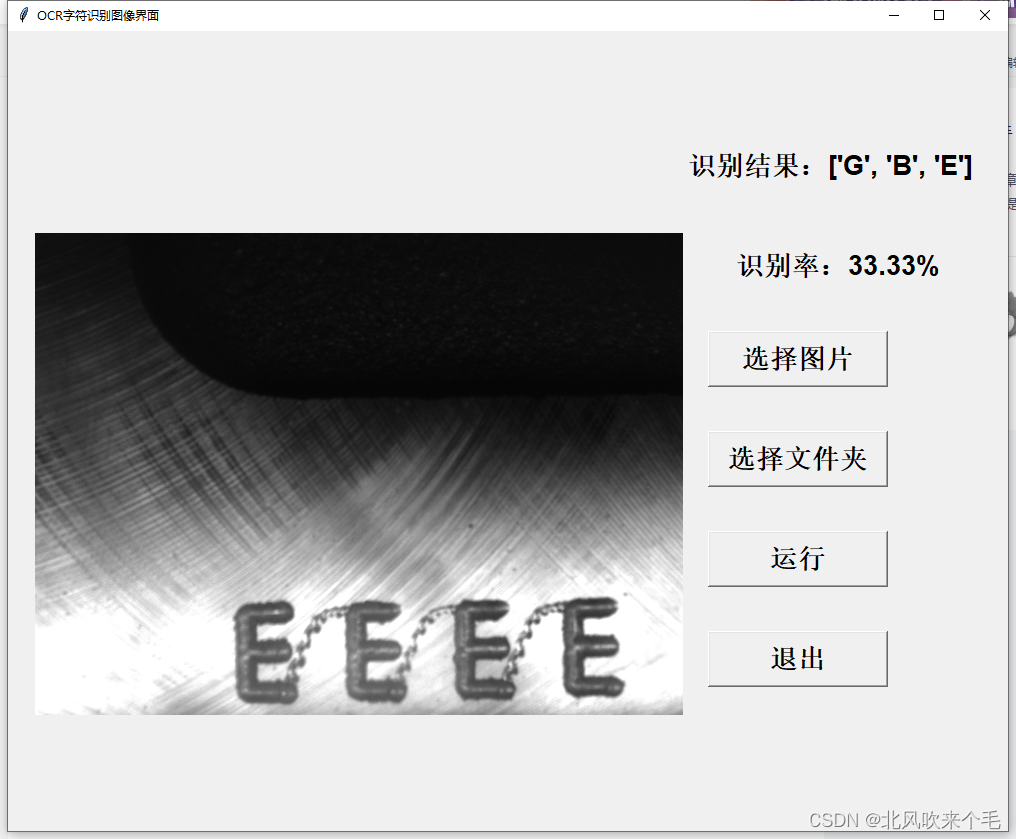
从识别结果看来,可以知道我们在图像预处理时处理的结果并不是太理想,对于字符有大黑点噪声或者字符之间有连接则不能分割出来。对于其他噪声还是能准确的识别出来,不过此次的项目我的任务是识别出来两个以上字符就行了,因此对于对于我此次的项目来说已经足够了。以后有时间会进行图像预处理的优化。
6、选择图像文件夹识别
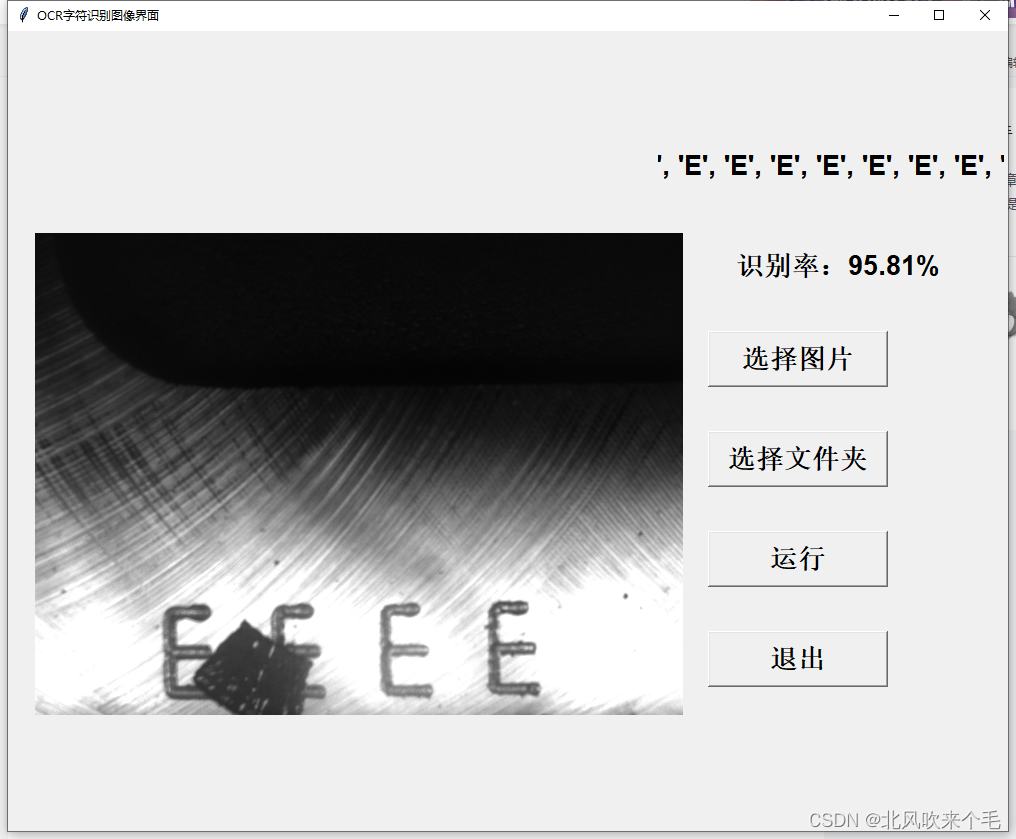

至此,整个字符识别项目完成。
六、项目经验总结
此次用卷积神经网络来实现工业上的字符识别项目需要改善的地方有以下几个:
1、做识别项目最主要的是图像的预处理,而此次项目的字符图像的预处理明显处理的不够好,对于有较大的黑点噪声去除不够完全,导致在分割字符图像的时候容易分割错误,这里是本次项目最需要优化的地方。
2、由于此次使用的是车牌识别的英文字符数据集来进行训练,而分割出来的字符图像并不像数据集的字体那么标准,因此在识别某些字符的时候或许会识别错误,如果使用的是由需要识别的字符图像分割而成的字符数据集进行训练,那准确率能提高许多。
3、在训练时使用的训练集图像数量已经足够,但是验证集的图像数量还是太少了,验证集总数只有80张,如果验证集的再多一点那么训练时的正确率应该会有所下降。
欢迎大家对此项目提出您最宝贵的建议,并在此处留言,与我一同探讨深度学习中的卷积神经网络。







![虚拟机系统iso镜像下载_[原版镜像]macOS Mojave 10.14.1 原版 iso 镜像- 虚拟机专用](https://img-blog.csdnimg.cn/img_convert/7b7ffd819f295264c80e1a50d5872e2e.png)