Test 1:
package test.wyh.wordcountimport org.apache.spark.rdd.RDD
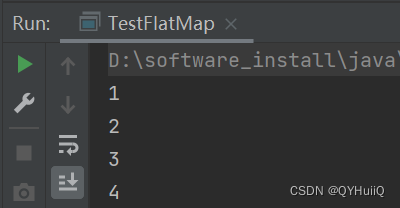
import org.apache.spark.{SparkConf, SparkContext}object TestFlatMap {def main(args: Array[String]): Unit = {//建立Spark连接val sparkConf = new SparkConf().setMaster("local").setAppName("TestWordCountApp")val sc = new SparkContext(sparkConf)//以List作为元素,组成的Listval rdd: RDD[List[Int]] = sc.makeRDD(List(List(1, 2), List(3, 4)))//将每个List元素中元素作为单独的元素形成一个迭代器val flatRDD: RDD[Int] = rdd.flatMap(element => {element})flatRDD.collect().foreach(println)//关闭连接sc.stop()}}
运行结果:
Test 2:
package test.wyh.wordcountimport org.apache.spark.rdd.RDD
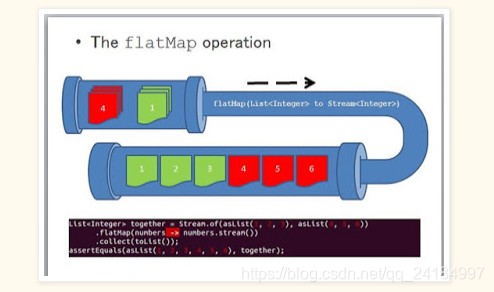
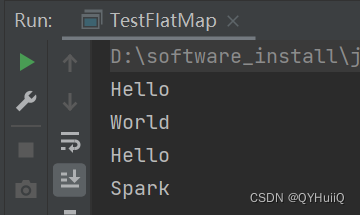
import org.apache.spark.{SparkConf, SparkContext}object TestFlatMap {def main(args: Array[String]): Unit = {//建立Spark连接val sparkConf = new SparkConf().setMaster("local").setAppName("TestWordCountApp")val sc = new SparkContext(sparkConf)//以字符串作为元素,组成的Listval rdd: RDD[String] = sc.makeRDD(List("Hello World", "Hello Spark"))//将字符串分割后的元素作为迭代器元素val flatRDD: RDD[String] = rdd.flatMap(element => {element.split(" ")})flatRDD.collect().foreach(println)//关闭连接sc.stop()}}
运行结果:
Test 3:
package test.wyh.wordcountimport org.apache.spark.rdd.RDD
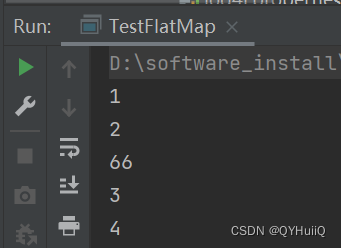
import org.apache.spark.{SparkConf, SparkContext}object TestFlatMap {def main(args: Array[String]): Unit = {//建立Spark连接val sparkConf = new SparkConf().setMaster("local").setAppName("TestWordCountApp")val sc = new SparkContext(sparkConf)//元素类型不统一val rdd = sc.makeRDD(List(List(1,2),66,List(3,4)))//模式匹配,如果元素本身是List,就原样返回,如果元素是不确定类型的,就将其封装为Listval flatRDD = rdd.flatMap(element => {element match {case list:List[_] => listcase value => List(value)}})flatRDD.collect().foreach(println)//关闭连接sc.stop()}}
运行结果: