文章目录
- 一.SQL的环境搭载
- 单机离线环境
- 在线环境
- 二.SQL的单表操作
- 1.sql基础三步
- 2.sql四则运算
- 3.limit (限制查询结果个数)
- 4.order by(排序)
- 5.where 综合条件筛选
- 6.SQL常量
- 7.distinct (把结果中重复的行删除)
- 8.函数
- (1) 聚合函数:
- `sum()` ——求和函数
- `count()`——计数函数
- `avg()`——平均值函数
- `min()| max()`——最小最大值函数
- `group by `——分组函数
- (2) 显示方式控制函数:
- `round`——控制保留位小数的结果
- `concat`——把分开的两列合成在一个结果中
- 三.SQL的多表操作
- 1.嵌套子循环
- (1).where子查询
- (2).from子查询
- (3).from与where子查询互换
- (4).select子查询
- 2.JOIN——连接多个数据库(或多表)
- 3.null与内连接与外连接
一.SQL的环境搭载
单机离线环境
安装:下载Beekeeper-studio
运行:可导入一个简单数据库进行实验
在线环境
- (这是在python基础下创造的sql环境,在线可用的python:希冀平台中的在线实验)
在希冀平台实验输入sql的方法:
- 第一步:把sql拖入
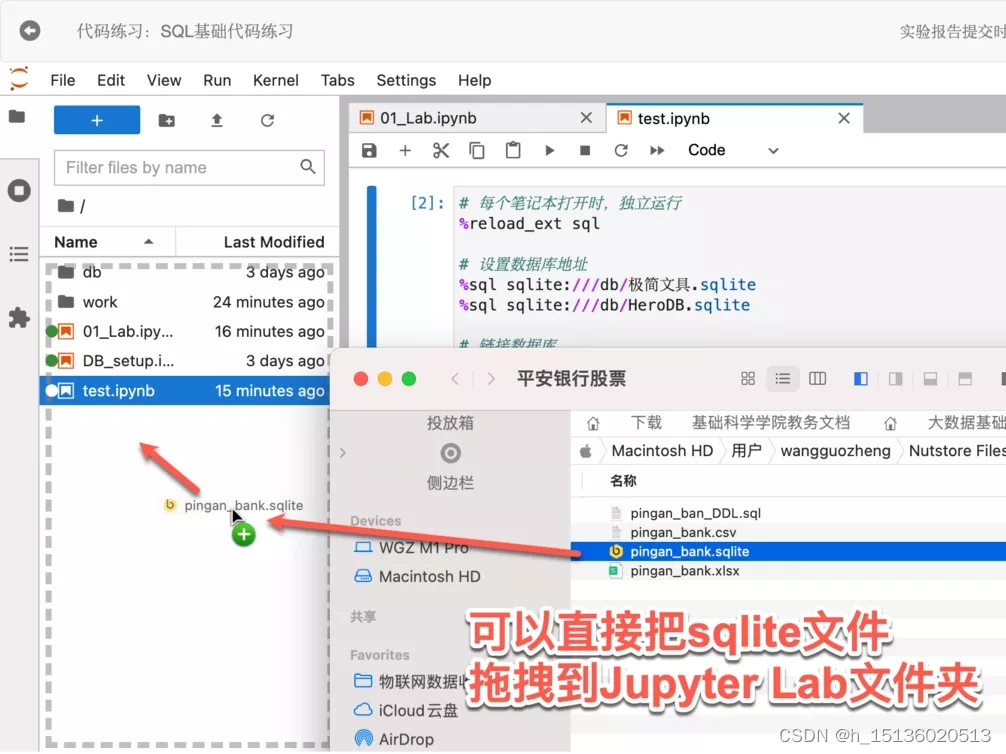
- 第二步:将以下代码输入运行框并修改一下,点击Code,点击运行,如果运行结尾后有done出现,则说明运行成功。
%reload_ext sql%sql sqlite:///需要你输入sql的文件名.sqlite%sql ATTACH '需要你输入sql的文件名.sqlite' AS e_store_db;
如图所示: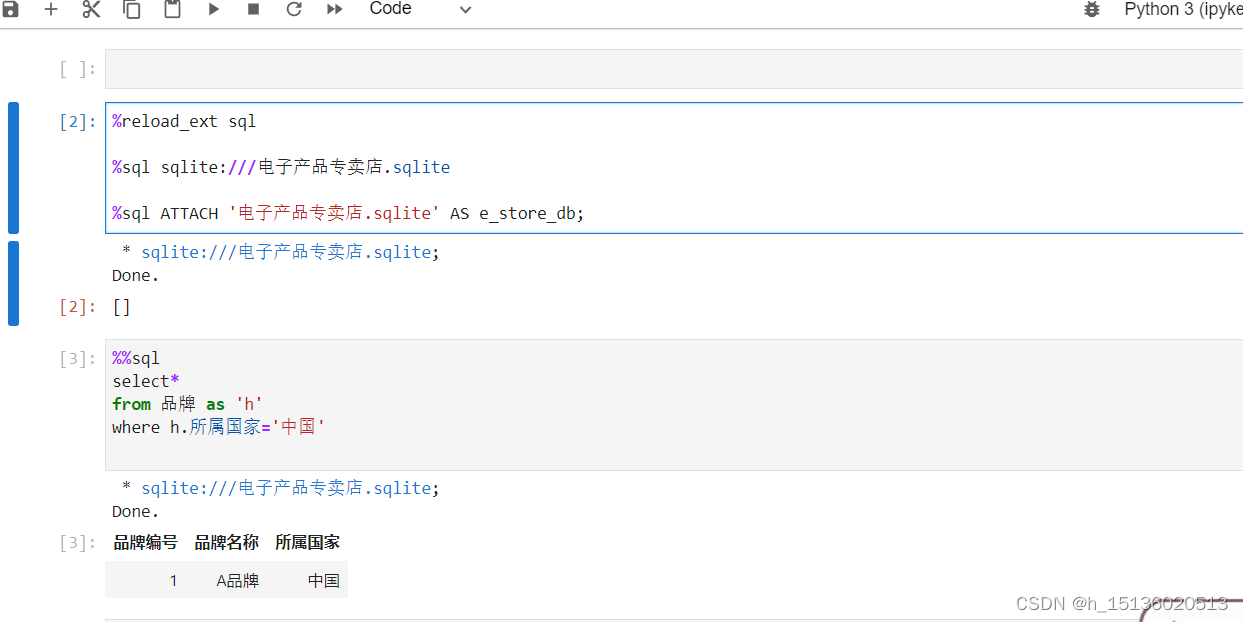
- 第三步:对sql数据库进行操作时前提要输入%%sql,之后再写你需要编辑的代码,否则运行不了
二.SQL的单表操作
1.sql基础三步
-
书写顺序:select…from…where…
-
from:定位要载入的表 → 定位hero_data_table数据表(hero_data_table为被剪辑的数据名称)
-
select:显示出想要出现的数据,一行一行的按条件筛选出目标行,*代表选中所有的行,运行出的结果是sql的所有数据
-
拓展:
1.对数据库名称简单重命名为h:from 数据库名称 as h
2.选中数据库中hero一行(可以同时选中多行中间用,隔开):select h.hero
3.在select中将自己编辑的新的数据命名 eg:h.life + h.speed + h.attack as'显示数字的总和')
如图:
-
where:输入筛选目标的代码,显示出来目标行中的指定列

以上显示的是所有speed>350的英雄数据 -
注意事项:大前提是输入的代码应全为英文,标点符号也是,在select中不想显示所有行,可以h.想要选中某一行的名称,用英文逗号隔开,数据库命名为h之后,h后面的内容必须是数据库每一列名称的内容

2.sql四则运算
sql可以单独经行运算
| 含义 | 运算符 |
|---|---|
| 加法运算 | + |
| 减法运算 | _ |
| 乘法运算 | * |
| 除法运算 | / |
| 求余运算 | % |
就好像select语句不需要from就可以独立成句显示常量一样,select语句也可以独立成句进行简单四则运算。
| 代码 | 代码结果 |
|---|---|
| select 3+2 | 3+2=5 |
| select 3/2 | select 3/2=1 |
| select 3/2.0 | select 3/2.0=1.5 |
| select (3*(2+3))/5-6 as ‘复合运算’ | 复合运算 = -3 |
既然独立成句语境下支持,那么在更加复杂的使用环境下也同样支持,比如:
产品档位划分如下
| 范围 | 档位 |
|---|---|
| [0,10) | 1 |
| [10, 20) | 2 |
| [20, 30) | 3 |
使用select和where四则运算得到极简文具公司数据库处在2,3档位的文具
代码如下:
select p.产品_描述,p.产品_售价, p.产品_售价/10+1 as '价格档位'
from 产品 as p
where (p.产品_售价/10+1) in (2,3)
代码结果如下:
| 产品_描述 | 产品_售价 | 价格档位 |
|---|---|---|
| 自动铅笔 | 15 | 2 |
| 16开笔记本 | 22 | 3 |
| 中性笔 | 18 | 2 |
| 马克笔 | 10 | 2 |
| 文件夹 | 20 | 3 |
3.limit (限制查询结果个数)
- 比如对于以下代码
select s.销售_订单_ID, s.销售数量
from 销售 as s
其运行的结果就有213行
- 如果我们指向显示,比如10行,就可以用以下的代码实现
select s.销售_订单_ID, s.销售数量
from 销售 as s
**limit 10 -- 限制只显示10行结果
代码结果如下:有十行内容
| 销售_订单_ID | 销售数量 |
|---|---|
| 80001 | 19456 |
| 80016 | 19037 |
| 80037 | 39582 |
| 80040 | 15012 |
| 80047 | 19621 |
| 80048 | 26637 |
| 80064 | 17921 |
| 80075 | 23015 |
| 80086 | 11860 |
| 80106 | 16212 |
- limit 之后一般是数字
4.order by(排序)
- order by XXX desc 降序
- order by XXX asc 升序
- 应用举例:在产品表中,价格档位,售价降序排列

5.where 综合条件筛选
where主要为筛选功能,对数据库进行一定规则的限制,从而达到我们需要得到的数据 (除筛选外还具有连接多表的功能,目前先不展开)
- 比较运算符:
| 条件 | 意义 | 表达式举例1 | |
|---|---|---|---|
= | 判断相等 | score = 80 | 你现在学的SQL不是编程语言→ = 在编程语言中是赋值的意思 |
> | 判断大于 | score > 80 | |
>= | 判断大于或相等 | score >= 80 | |
< | 判断小于 | score < 80 | |
<= | 判断小于或相等 | score <= 80 | |
<> | 判断不相等 | score <> 80 | 有些数据库 != |
LIKE | 判断字符串相似 | name LIKE 'ab%' | %表示任意字符,例如’ab%‘将匹配’ab’,‘abc’,‘abcd’注意有些数据库大小写敏感,有些不敏感 |
is NULL | 判断是否是NULL | score is NULL | 用来检测空值 |
-
LIKE的灵活使用-
以
X开头like 'X%' -
以
X结尾like '%X' -
包含
Xlike '%X%' -
eg:使用SQL的条件表达式搜索那个叫做
ca...的游戏英雄的全部属性
-
select *
from hero_data_table as 'h'
where h.Hero like 'ca%'
代码结果:

- 逻辑运算符
| 意义 | 公式 | 举例 |
|---|---|---|
| 两个条件都满足 | <条件1> and <条件2> | where (h.attack>60) and (h.Hero like 'L%')攻击力大于60且名字以 L开头的游戏英雄 |
在闭区间[X , Y]之内 | between X and Y | where h.life between 445 and 580生命值大于等于445且小于等于580 |
| 两个条件至少满足一个 | <条件1> or <条件2> | where (h.life > 600) or (h.armor = 20)生命值大于600 或者 护甲等于20 |
| 在X, Y, Z 中存在 | IN (X, Y, Z) | where h.Hero in ('Lo', 'Zoe', 'Tariq')游戏英雄名称是 Lo或者Zoe或者Tariqwhere h.life in (445,580)生命值是445或者580 |
| 条件不满足 | NOT <条件> | where not h.attack_speed = 1攻击速度不是1 where h.Hero not in ('Lo', 'Zoe', 'Tariq')游戏英雄名称不是 Lo或者Zoe或者Tariq |
| 指定多复合运算的关系 | ( ) | where (h.life > 500) and (not h.attack_speed = 1) and (not (h.Hero like 'A%'))生命值大于500且攻击速度不是1且名称不以A开头 |
6.SQL常量
- select语句不需要from就可以独立成句显示常量,而且也能进行四则运算
- 只使用select语句显示常量
select 1000
代码结果
| 1000 |
|---|
| 1000 |
select 1000 , '你好' , '2021-03-18'
代码结果
| 1000 | ‘你好’ | ‘2021-03-18’ |
|---|---|---|
| 1000 | 你好 | 2021-03-18 |
select1000 as '数字','你好' as '字符串','2020-10-28' as '日期';
代码结果
| 数字 | 字符串 | 日期 |
|---|---|---|
| 1000 | 你好 | 2020-10-28 |
- 例子:希望在极简文具数据库中找到价格<20的产品,并注明商品特征是便宜商品
select'便宜产品' as '产品特征',p.产品_描述 as '产品名称',p.产品_售价 as '产品价格'
from产品 as p
wherep.产品_售价 < 20
结果:
| 产品特征 | 产品名称 | 产品价格 |
|---|---|---|
| 便宜产品 | 自动铅笔 | 15 |
| 便宜产品 | 32开笔记本 | 8 |
| 便宜产品 | 中性笔 | 18 |
| 便宜产品 | 橡皮 | 5 |
| 便宜产品 | 马克笔 | 10 |
7.distinct (把结果中重复的行删除)
如果要得到极简文具公司数据库的所有收入超过一百万的订单的SQL代码如下:
selects.销售订单_日期_月 as '有超过百万订单月'
from销售 as s
wheres.销售数量 * s.产品_价格 > 1000000
order by有超过百万订单月
代码结果:
| 有超过百万订单月 |
|---|
| 1 |
| 2 |
| 2 |
| 2 |
| 3 |
| 4 |
| 5 |
| 5 |
| 6 |
| 11 |
| 12 |
以上我们发现2月和5月的订单都有重复超过一万的,而我们想要的是月份,不让它有重复,我们只需要在select后加个distinct便可实现
select distincts.销售订单_日期_月 as '有超过百万订单月'
from销售 as s
wheres.销售数量 * s.产品_价格 > 1000000
order by有超过百万订单月
代码结果:
| 有超过百万订单月 |
|---|
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
| 6 |
| 11 |
| 12 |
注意:如果放在多个列之前,则会只删除所有列内容都同时重复的行,比如以下代码:
select distincts.销售订单_日期_月 as '有百万单月',s.销售数量 * s.产品_价格 as '销售额'
from销售 as s
wheres.销售数量 * s.产品_价格 > 1000000
order bys.销售订单_日期_月, 销售额
结果:

8.函数
(函数大致含义:f(x)=y)
- 聚合函数
- 显示方式控制函数
(1) 聚合函数:
sum() ——求和函数
很多时候我们需要计算搜索出来的数据的综合,就需要用到sum()函数,比如:

意思是:在销售表中销售数量一列的总和
count()——计数函数
如果我们想要知道第十一月份有多少笔订单
代码如下:
select
count(s.销售_订单_ID) as '11月订单数'
from
销售 as s
where
s.销售订单_日期_月 = 11
结果:

avg()——平均值函数
sum()/count()这种表示运算出的结果不带小数
eg:求极简文具库11月份的产品单位订单平均销量
avg直接表示:
select
avg(s.销售数量) as '11月平均每笔订单销量'
from
销售 as s
where
s.销售订单_日期_月 = 11
结果:
sum()/count()的两种表示:
1.
select
sum(s.销售数量)/count(s.销售数量) as '11月平均每笔订单销量'
from
销售 as s
where
s.销售订单_日期_月 = 11
select sum(s.销售数量)/count(客户_ID) as '11月平均每笔订单销量'
from 销售 as s
where s.销售订单_日期_月 = 11
结果:

min()| max()——最小最大值函数
在select中筛选出最大最小的数,用where也可以实现,但比直接用最大最小麻烦一些
eg:使用min()和max()获得极简文具公司数据库中最贵和最便宜的产品售价
1.min()max()直接实现:
selectmax(p.产品_售价) as '最高售价',min(p.产品_售价) as '最低售价'
from产品 as p
结果:

2.where语句实现:
最高售价:
select distinct p.产品_价格
from 销售 as p
order by p.产品_价格 desc
limit 1
最低售价:
select distinct p.产品_价格
from 销售 as p
order by p.产品_价格 asc
limit 1
区别:where语句中主要通过distinct,order by,limit来实现的
group by ——分组函数
eg:我们想要得到每个月份的销量总和(这就需要以月份为对象进行分组,然后再求出每个月份的销售总和)
未分组前的数据:

分组后:代码如下
select p.销售订单_日期_月,sum(p.销售数量) as '每月销售总额'
from 销售 as p
group by p.销售订单_日期_月
结果如下:

(2) 显示方式控制函数:
round——控制保留位小数的结果
由avg()函数中的结果得知,小数点后面有很多位,如果我们想要保留两位小数可以用round函数实现

代码如下:
selectround(avg(s.销售数量),2) as '11月平均每笔订单销量'
from销售 as s
wheres.销售订单_日期_月 = 11
代码结果:

concat——把分开的两列合成在一个结果中
理解说明:
在英雄数据库中Hero和life是独立的两个属性

而concat的作用是把两列合并到一起

concat在sqlite与mysql的表达方法不一样
希冀与beekeeper中是sqlite形式
sqlite中:代码如下:
selecth.Hero || ' 的生命值是 ' || h.life as '生命值>580的英雄描述'
fromhero_data_table as h
whereh.life > 580
mysql中:代码如下:
selectconcat(h.Hero,' 的生命值是 ',h.life) as '生命值>580的英雄描述'
fromhero_data_table as h
whereh.life > 580
两种方式的代码结果都是一样的:

三.SQL的多表操作
1.嵌套子循环
(1).where子查询
(简单来说就是在where里面嵌套一个或者加一个sql的语句)
举个栗子:在英雄数据库中找到比Nesus更快的游戏英雄
思路:首先,要找到Nesus这个英雄的速度,再以它为筛选条件输入在where中找到比它更快的英雄
找到Nesus的速度代码如下:
select h1.speed
from hero_data_table as h1
where h1.Hero = 'Nesus'
结果:
所以以它为条件找到速度比350更快的英雄代码如下:
select *
from hero_data_table as h2
where h2.speed > ( -- 以下子查询语句得到Nesus的速度select h1.speedfrom hero_data_table as h1where h1.Hero='Nesus');
代码结果:

(2).from子查询
(与where子查询类似,这次是在from中嵌套一个sql语句)
举个栗子:在英雄数据库中找到比Nesus快的英雄中魔法值大于200的游戏英雄
大致思路:我们是要在嵌套中再加一个嵌套,我们已经有了比Nesus更快的游戏英雄的代码了(里面已经包含了一个嵌套了),只需要把它嵌套在from中
首先,已知比Nesus快的代码了,只需要写出魔法值>200的代码
代码如下:
select *
from --比Nesus快的所有的游戏英雄--
where magic>200
所以将两个代码结合:如下
select *
from ( -- 以下子查询得到比Nesus速度快的所有游戏英雄数据select *from hero_data_table as h2where h2.speed > ( -- 以下子查询语句得到Nesus的速度select h1.speedfrom hero_data_table as h1where h1.Hero='Nesus')
) as h3
where h3.magic > 200;
代码结果:

(3).from与where子查询互换
其实from子查询是可以直接转化为where子查询的,比如针对找到比Nesus快的所有的游戏英雄中魔法值大于200的游戏英雄的例子
我们可以进行如下转换:
select *
from hero_data_table as h3
where h3.magic > 200 and h3.Hero in(select h2.Herofrom hero_data_table as h2where h2.speed > ( -- 以下子查询语句得到Nesus的速度select h1.speedfrom hero_data_table as h1where h1.Hero='Nesus')
)
不管那种方式,代码最后运行的结果都是一样的:

(4).select子查询
(与where和from子循环一样与,是在select中嵌套sql语句)
大致思路:
eg:统计极简文具公司数据库_升级版中无产品_售价1的产品有多少个?
(需用到null的语法,建议在后续学过null再回过头看更清楚一些)
代码如下:
select (select count(h.产品_售价 is null) as '无价格产品个数'
from 产品 as h
where h.产品_售价 is null) as '无价格产品个数',(select count(h.产品_售价) as '有价格产品个数'
from 产品 as h) as '有价格产品个数'
代码结果:
2.JOIN——连接多个数据库(或多表)
(简单来说就是通过表中的相同的部分把表连接起来)

如上图,可以把客户表可以跟销售表通过客户_ID连接,产品表跟销售表可以通过产品_代码连接,于是最终结果客户和产品表通过销售表连接在一起。
- 两表连接的代码如下:
使用把极简文具公司数据库中的客户表格和产品表格通过关联列客户_ID关联起来
select c.客户_名称, s.销售订单_日期,s.销售数量 * s.产品_价格 as '订单金额'
from客户 as c JOIN 销售 as sONc.客户_ID = s.客户_ID
wherec.客户_ID = 101
代码结果
| 客户_名称 | 销售订单_日期 | 订单金额 |
|---|---|---|
| 图龙信息信息有限公司 | 1/10/2020 | 352632 |
| 图龙信息信息有限公司 | 1/26/2020 | 78112 |
| 图龙信息信息有限公司 | 1/31/2020 | 771584 |
| 图龙信息信息有限公司 | 1/7/2020 | 50224 |
| 图龙信息信息有限公司 | 4/17/2020 | 505960 |
| 图龙信息信息有限公司 | 6/18/2020 | 516990 |
| 图龙信息信息有限公司 | 6/2/2020 | 809116 |
| 图龙信息信息有限公司 | 6/29/2020 | 840366 |
- 多表连接代码如下:
select ...
from A JOIN B on A.id1 = B.id1C on A.id2 = C.id2
应用:通过电子专卖店数据库,对比2018年6,7,8月份的销售额,要求保留小数后两位,总销售额以亿为单位。
实现结果:
代码如下:
select c.年度,c.月,round(sum(h.销售单价*s.销售数量)/100000000,2) as '销售总额_亿元'
from 产品明细 as h join 销售明细 as s on h.产品编号=s.产品编号 join 日期 as c on s.订单日期=c.日期
where c.月 in (6,7,8) and c.年度=2018
group by c.月,c.年度
3.null与内连接与外连接
-null(在有些环境下none与null表达一样)(null的意思是空值,表示未知)
应用实例:判断极简文具公司数据库_升级版中是否有产品未定产品_售价,或者缺少产品_代码
代码如下:
select *
from产品 as p
wherep.产品_代码 is NULL or p.产品_售价 is NULL
代码结果:
日常生活中我们可以用null检测出没有标价的商品
inner join内连接
理解:通常的内连接表示两个表中的交集部分

- 内连接表示的关系最严格,即,只返回满足条件的两个表格的
交集 - 即:只显示A和B中
A.Key=B.Key的那些行,如果在A中有些A.Key在B中没有,无法进行匹配,则不显示,例如空值,A中某一部分如果有空值与B无法匹配,则那一行数据就不会有显示。 - 举个栗子:在极简文具库升级版中显示出,产品_代码,产品_描述,销售_订单_ID所有的信息
代码:
selectp.产品_代码,p.产品_描述,s.销售_订单_ID
from产品 as pJOIN 销售 as s ON p.产品_代码 = s.产品_代码
order bys.销售_订单_ID
结果:
但是,我们发现,它并没有显示出有空值的数据
原因就是inner join 连接的是两个表中的交集,并不会显示一个表中的空值部分,如果想要显示出空值就需要使用外连接。
outter join外连接
理解:
紧接上一个栗子,显示出没有订单的产品(就是显示出空值)
代码如下:
select p.产品_代码,p.产品_描述,s.销售_订单_ID
from 产品 as p left join 销售 as son p.产品_代码 = s.产品_代码
order by s.销售_订单_ID asc
代码结果:
其中里面最核心的地方是 left join (左连接),它显示出了相交的部分与没有相交的部分,显示没有相交的部分是产品表中的空值部分,同理也有右连接但sqlite不支持,那想要显示出销售表中的空值只需要把from中销售表与产品表中的位置互换就可以。