原标题:探讨Android全文检索技术
写在前面
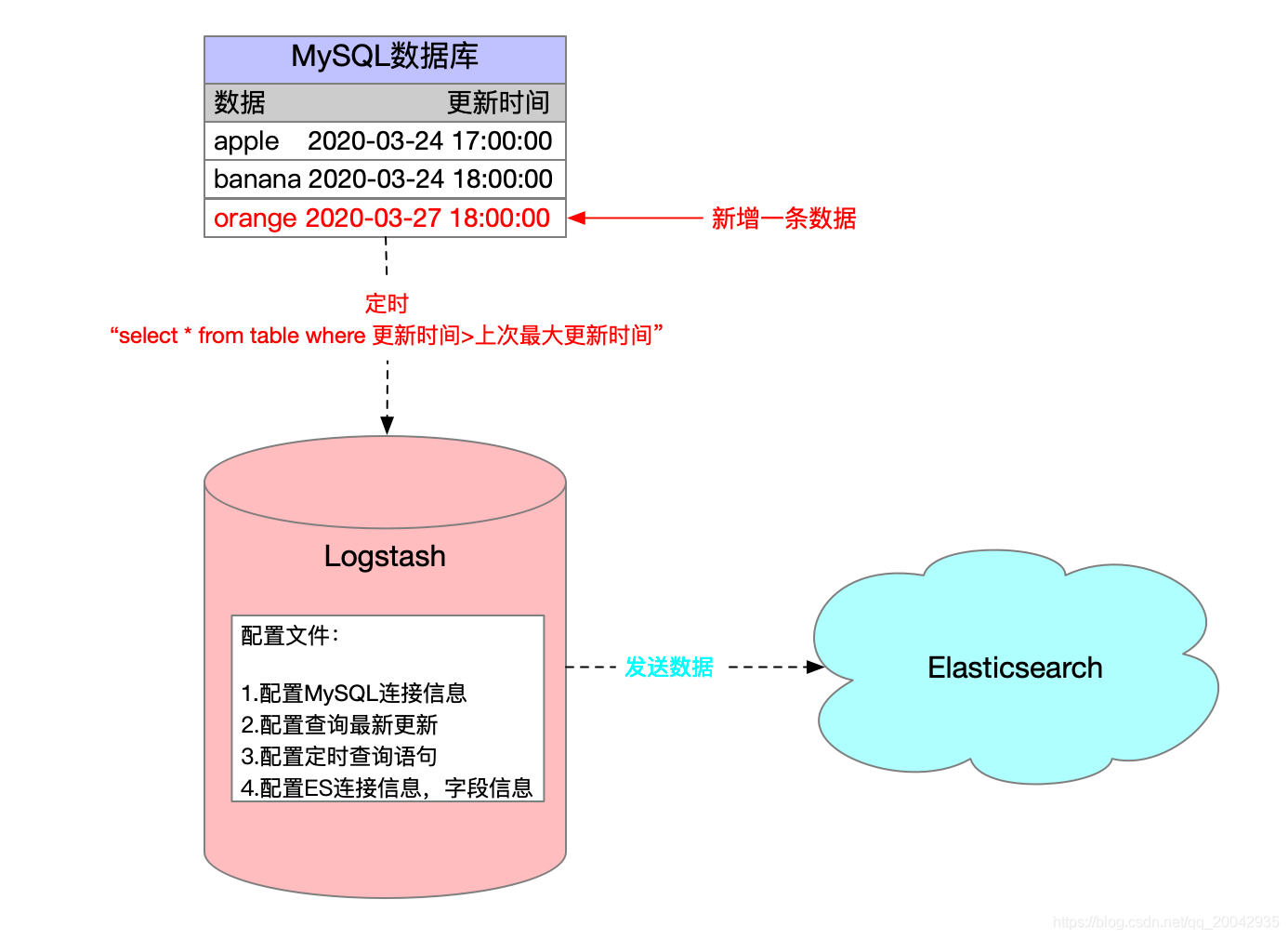
客户端本地存储数据一般使用的存储方式是:文件、SharedPreference、数据库(SQLite)
如果我们要做一些查询的操作,对于文件的方式,通过序列化和反序列化来进行数据的增删改查操作,表示效率低且繁琐到力不从心。
要实现高效的全文检索,必然需要使用到数据库,而对于手机客户端而言,SQLite支持FTS当然身先士卒
全文检索主要工作原理是:先建立索引,然后再对索引进行搜索
创建索引和搜索索引一般都是根据实际的业务进行相关设计的,没有全能的,只有相对和针对;至于优化,更是根据相关场景和数据量进行查询测试和分析的。
所以下面主要还是以介绍检索功能为出发点,来看看在实现全文检索的过程中,我们会遇到哪些知识分子,以及我们该如何吸收他们产出的能量。
通过这个篇文章你可以了解到:1. 全文检索是如何实现的
2. 全文检索涉及到的索引、倒排索引、B-树等等相关知识概念
3. 在Android端如何去使用全文检索功能
Sqlite FTS Extension
SQLite FTS Extension 是SQLite实现全文检索功能的插件。
目前一共有5个版本,其中FTS1、FTS2已经被废弃了,可用的版本为FTS3、FTS4、FTS5。
FTS3从SQLite 3.5.0版本开始支持
FTS4从SQLite 3.7.4版本开始支持
FTS5从SQLite 3.9.0版本开始支持
Sqlite在Android平台上对应的版本关系如下:
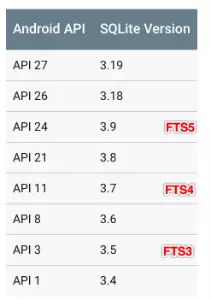
鉴于版本兼容,FTS5在Android 7.0及之后才开始支持,而目前市场上还有很大一部分机器是在7.0以下的,所以对于APP我们应该考虑使用FTS4。
那么下面我们主要以FTS4的身份,去分析和实现全文检索的功能
FTS 概要
FTS是SQLite数据库的虚拟表模块,提供全文检索的功能。
其基本增删改查操作方式如下:
//创建虚拟表fts_test
CREATEVIRTUALTABLEfts_test USING fts4(title, body, tokenize=unicode61);
//插入数据
INSERTINTOfts_test(title, body)VALUES('标题1','Java是全世界最好的编程语言');
//更新数据
UPDATEfts_testSETtitle ='标题1修正'WHERErowid = 1;
//根据rowid查询数据
SELECT*FROMfts_testWHERErowid = 1;
//全文检索数据
SELECT*FROMfts_testWHEREfts_test MATCH'java*';
//删除表数据
DELETEFROMfts_test;
//删除表结构
DROPTABLEfts_test;
FTS工作原理
其基本的工作原理如下:
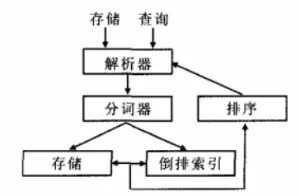
其中分词器和倒排索引是关键
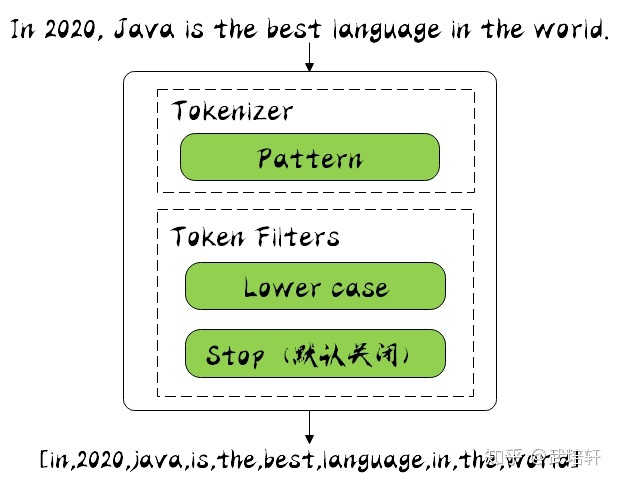
分词器
FTS4提供了四种系统分词器:simple、porter、icu、unicode61
类型
描述
simple根据单词进行分词,不区分大小写且不支持中文porter与simple一样,但是不区分单词语义(搜索do时,能搜索到do、did、does)icu将输入文本根据ICU规则寻找单词边界和丢弃任何标记,支持中文,可拓展unicode61根据空格和标点符号进行分词,依赖于Unicode Version 6.1标准,支持中文
使用方式:
CREATE VIRTUAL TABLE fts_test USING fts4(title, body, tokenize=unicode61);
当然也可以自定义分词器,这个需要在C层实现。
索引
是帮助MySQL高效获取数据的数据结构。提取句子主干,就可以得到索引的本质:索引是一种数据结构。
索引会增加表的体积,其实是在改变表的存储结构
主键是聚集索引,将表的存储结构变成了平衡树
创建其他索引会添加其他独立的索引结构,每次通过索引查询时,都会先去索引结构中查找到对应的主键,然后在通过主键去查找对应的内容
覆盖索引,即在多个字段上创建索引,这样可以通过索引直接查询到字段内容,加快了速度
索引虽然有效的提高的查询速度,但是也会影响数据的增删操作,所以需要根据具体情况做相关的决断
倒排索引
倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。
它是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。
倒排文件
用记录的非主属性值(也叫副键)来查找记录而组织的文件叫倒排文件,即次索引。倒排文件中包括了所有副键值,并列出了与之有关的所有记录主键值,主要用于复杂查询。
单词词典(难点)
是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。(常用的数据结构包含哈希加链表和树形词典结构)
倒排列表
记载了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,通过它可获知哪些文档包含某个单词
工作原理分析:
创建表的代码:
/*
** Create the backing store tables (%_content, %_segments and %_segdir)
** required by the FTS3 table passed as the only argument. This is done
** as part of the vtab xCreate() method.
**
** If the p->bHasDocsize boolean is true (indicating that this is an
** FTS4 table, not an FTS3 table) then also create the %_docsize and
** %_stat tables required by FTS4.
*/
staticintfts3CreateTables(Fts3Table *p){
intrc = SQLITE_OK; /* Return code */
inti; /* Iterator variable */
sqlite3 *db = p->db; /* The database connection */
if( p->zContentTbl==0 ){
constchar*zLanguageid = p->zLanguageid;
char*zContentCols; /* Columns of %_content table */
/* Create a list of user columns for the content table */
zContentCols = sqlite3_mprintf("docid INTEGER PRIMARY KEY");
for(i=0; zContentCols && inColumn; i++){
char*z = p->azColumn[i];
zContentCols = sqlite3_mprintf("%z, 'c%d%q'", zContentCols, i, z);
}
if( zLanguageid && zContentCols ){
zContentCols = sqlite3_mprintf("%z, langid", zContentCols, zLanguageid);
}
if( zContentCols==0 ) rc = SQLITE_NOMEM;
/* Create the content table */
fts3DbExec(&rc, db,
"CREATE TABLE %Q.'%q_content'(%s)",
p->zDb, p->zName, zContentCols
);
sqlite3_free(zContentCols);
}
/* Create other tables */
fts3DbExec(&rc, db,
"CREATE TABLE %Q.'%q_segments'(blockid INTEGER PRIMARY KEY, block BLOB);",
p->zDb, p->zName
);
fts3DbExec(&rc, db,
"CREATE TABLE %Q.'%q_segdir'("
"level INTEGER,"
"idx INTEGER,"
"start_block INTEGER,"
"leaves_end_block INTEGER,"
"end_block INTEGER,"
"root BLOB,"
"PRIMARY KEY(level, idx)"
");",
p->zDb, p->zName
);
if( p->bHasDocsize ){
fts3DbExec(&rc, db,
"CREATE TABLE %Q.'%q_docsize'(docid INTEGER PRIMARY KEY, size BLOB);",
p->zDb, p->zName
);
}
assert( p->bHasStat==p->bFts4 );
if( p->bHasStat ){
sqlite3Fts3CreateStatTable(&rc, p);
}
returnrc;
}
1. 创建虚拟表并插入数据
sqlite> CREATE VIRTUAL TABLE fts_test USING fts4(title, body, tokenize='unicode61');
sqlite> INSERT INTO fts_test(title, body) VALUES('标题1','Java是全世界最好的变成语言');
sqlite> INSERT INTO fts_test(title, body) VALUES('标题2','Android是最牛逼的手机系统');
sqlite> INSERT INTO fts_test(title, body) VALUES('标题3','Java是Android应用层的主要编程语言');
2. 通过sqlite3查看表结构和表数据插入过程
sqlite> .table
看到共创建了如下6个表:
fts_test、fts_test_content、fts_test_segments、fts_test_segdir、fts_test_stat、fts_test_docsize
sqlite> SELECT * FROM sqlite_master WHERE type = "table";
可以看到表结构如下:
table|fts_test|fts_test|0|CREATE VIRTUAL TABLE fts_test using fts4(title, body)
table|fts_test_content|fts_test_content|5|CREATE TABLE 'fts_test_content'(docid INTEGER PRIMARY KEY, 'c0title', 'c1body')
table|fts_test_segments|fts_test_segments|6|CREATE TABLE 'fts_test_segments'(blockid INTEGER PRIMARY KEY, block BLOB)
table|fts_test_segdir|fts_test_segdir|7|CREATE TABLE 'fts_test_segdir'(level INTEGER,idx INTEGER,start_block INTEGER,leaves_end_block INTEGER,end_block INTEGER,root BLOB,PRIMARY KEY(level, idx))
table|fts_test_docsize|fts_test_docsize|9|CREATE TABLE 'fts_test_docsize'(docid INTEGER PRIMARY KEY, size BLOB)
table|fts_test_stat|fts_test_stat|10|CREATE TABLE 'fts_test_stat'(id INTEGER PRIMARY KEY, value BLOB)
sqlite> .dump
看到其插入数据的过程:
PRAGMA foreign_keys=OFF;
BEGIN TRANSACTION;
CREATE TABLE android_metadata (locale TEXT);
INSERT INTO android_metadata VALUES('zh_CN');
PRAGMA writable_schema=ON;
INSERT INTO sqlite_master(type,name,tbl_name,rootpage,sql)VALUES('table','fts_test','fts_test',0,'CREATE VIRTUAL TABLE fts_test using fts4(title, body)');
CREATE TABLE IF NOT EXISTS 'fts_test_content'(docid INTEGER PRIMARY KEY, 'c0title', 'c1body');
INSERT INTO fts_test_content VALUES(1,'标题1','Java是全世界最好的编程语言');
INSERT INTO fts_test_content VALUES(2,'标题2','Android是最牛逼的手机系统');
INSERT INTO fts_test_content VALUES(3,'标题3','Java是Android应用层的主要编程语言');
CREATE TABLE IF NOT EXISTS 'fts_test_segments'(blockid INTEGER PRIMARY KEY, block BLOB);
CREATE TABLE IF NOT EXISTS 'fts_test_segdir'(level INTEGER,idx INTEGER,start_block INTEGER,leaves_end_block INTEGER,end_block INTEGER,root BLOB,PRIMARY KEY(level, idx));
INSERT INTO fts_test_segdir VALUES(0,0,0,0,'0 58',X’00256a617661e698afe585a8e4b896e7958ce69c80e5a5bde79a84e58f98e68890e8afade8a8800501010102000007e6a087e9a2983103010200');
INSERT INTO fts_test_segdir VALUES(0,1,0,0,'0 55',X’0022616e64726f6964e698afe69c80e7899be980bce79a84e6898be69cbae7b3bbe7bb9f0502010102000007e6a087e9a2983203020200');
INSERT INTO fts_test_segdir VALUES(0,2,0,0,'0 65',X’002c6a617661e698af616e64726f6964e5ba94e794a8e5b182e79a84e4b8bbe8a681e7bc96e7a88be8afade8a8800503010102000007e6a087e9a2983303030200');
CREATE TABLE IF NOT EXISTS 'fts_test_docsize'(docid INTEGER PRIMARY KEY, size BLOB);
INSERT INTO fts_test_docsize VALUES(1,X'0101');
INSERT INTO fts_test_docsize VALUES(2,X'0101');
INSERT INTO fts_test_docsize VALUES(3,X'0101');
CREATE TABLE IF NOT EXISTS 'fts_test_stat'(id INTEGER PRIMARY KEY, value BLOB);
INSERT INTO fts_test_stat VALUES(0,X'0303038801');
PRAGMA writable_schema=OFF;
COMMIT;
3. 表结构和内容分析
fts_test_content:存储的是完整的数据信息,默认会创建一个docid的主键
CREATE TABLE IF NOT EXISTS 'fts_test_content'(docid INTEGER PRIMARY KEY, 'c0title', 'c1body');
sqlite> select * from fts_test_content;
内容如下:
docid|c0title|c1body
1|标题1|Java是全世界最好的变成语言
2|标题2|Android是最牛逼的手机系统
3|标题3|Java是Android应用层的主要编程语言
fts_test_stat:存储的是FTS table的行数,以及表中所有行和列的符号总数
CREATE TABLE IF NOT EXISTS 'fts_test_stat'(id INTEGER PRIMARY KEY, value BLOB);
sqlite> select * from fts_test_stat;
内容如下:
id|value
0|0303038801
fts_test_docsize:存储的是docid以及每一行对列的tokens的数量(docid对应数据的所有符号数)
CREATE TABLE IF NOT EXISTS 'fts_test_docsize'(docid INTEGER PRIMARY KEY, size BLOB);
INSERT INTO fts_test_docsize VALUES(1,X'0101');
INSERT INTO fts_test_docsize VALUES(2,X'0101');
INSERT INTO fts_test_docsize VALUES(3,X'0101’);
sqlite> select * from fts_test_docsize;
内容如下:
docid|size
1|0101
2|0101
3|0101
fts_test_segments:保存B-树的非根节点(存储的是全文索引)
CREATE TABLE IF NOT EXISTS 'fts_test_segments'(blockid INTEGER PRIMARY KEY, block BLOB);
sqlite> select * from fts_test_segments;
内容无
fts_test_segdir:保存B-树的根节点(存储的是全文索引)
CREATE TABLE IF NOT EXISTS 'fts_test_segdir'(level INTEGER,idx INTEGER,start_block INTEGER,leaves_end_block INTEGER,end_block INTEGER,root BLOB,PRIMARY KEY(level, idx));
对应的字段含义如下:

插入数据的语句:
INSERT INTO fts_test_segdir VALUES(0,0,0,0,'0 58',X’00256a617661e698afe585a8e4b896e7 958ce69c80e5a5bde79a84e58f98e68890e8afade8a8800501010102000007e6a087e9a2983103010200');
INSERT INTO fts_test_segdir VALUES(0,1,0,0,'0 55',X’0022616e64726f6964e698afe69c80e7
899be980bce79a84e6898be69cbae7b3bbe7bb9f0502010102000007e6a087e9a2983203020200');
INSERT INTO fts_test_segdir VALUES(0,2,0,0,'0 65',X’002c6a617661e698af616e64726f6964e5ba94e7
94a8e5b182e79a84e4b8bbe8a681e7bc96e7a88be8afade8a8800503010102000007e6a087e9a2983303030200');
sqlite> select * from fts_test_segdir;
level|idx|start_block|leaves_end_block|end_block|root
0|0|0|0|0 58|00256a617661e698afe585a8e4b896e7
0|1|0|0|0 55|0022616e64726f6964e698afe69c80e7
0|2|0|0|0 65|002c6a617661e698af616e64726f6964
在Android中的使用姿势
DataDB
packagecom.mob.demo.ftsdb;
importandroid.content.ContentValues;
importandroid.content.Context;
importandroid.database.Cursor;
importandroid.database.DatabaseErrorHandler;
importandroid.database.sqlite.SQLiteDatabase;
importandroid.database.sqlite.SQLiteOpenHelper;
importandroid.text.TextUtils;
importjava.util.ArrayList;
importjava.util.List;
publicclassDataDBextendsSQLiteOpenHelper {
privateSQLiteDatabase db;
publicDataDB(Context context) {
super(context,"db_test_fts.db",null,1,newDatabaseErrorHandler() {
publicvoidonCorruption(SQLiteDatabase sqLiteDatabase) {
//TODO
}
});
db = getWritableDatabase();
}
publicvoidonCreate(SQLiteDatabase sqLiteDatabase) {
//创建虚拟表
sqLiteDatabase.execSQL("CREATE VIRTUAL TABLE fts_test USING fts4(title, body);");
db = sqLiteDatabase;
//插入数据
bulkInsert(newString[]{"标题1","标题2","标题3"},newString[]{"Java是全世界最好的变成语言","Android是最牛逼的手机系统","Java是Android应用层的主要编程语言"});
}
publicvoidonUpgrade(SQLiteDatabase sqLiteDatabase,inti,inti1) {
}
//插入单条数据
publicvoidinsert(String title, String body) {
ContentValues values =newContentValues();
values.put("title", title);
values.put("body", body);
db.insert("fts_test",null, values);
}
//批量插入数据
publicvoidbulkInsert(String[] titleArray, String[] bodyArray) {
if(titleArray ==null|| bodyArray ==null|| titleArray.length ==0|| titleArray.length != bodyArray.length) {
return;
}
db.beginTransaction();
for(inti =0; i < titleArray.length; i++) {
ContentValues values =newContentValues();
values.put("title", titleArray[i]);
values.put("body", bodyArray[i]);
db.insert("fts_test",null, values);
}
db.setTransactionSuccessful();
db.endTransaction();
}
//查询title字段包含text内容的数据
publicList queryTitle(String text) {
List resultList =null;
Cursor cursor = db.rawQuery("SELECT * FROM fts_test WHERE title MATCH '"+ text +"*';",null);
System.out.println("wenjun cursor title = "+ (cursor ==null?null: cursor.getCount()));
if(cursor !=null&& cursor.getCount() >0) {
resultList =newArrayList<>();
while(cursor.moveToNext()) {
resultList.add(cursor.getString(0));
}
}
returnresultList;
}
//查询body字段包含text内容的数据
publicList queryBody(String text) {
List resultList =null;
Cursor cursor = db.rawQuery("SELECT * FROM fts_test WHERE body MATCH '"+ text +"*';",null);
System.out.println("wenjun cursor body = "+ (cursor ==null?null: cursor.getCount()));
if(cursor !=null&& cursor.getCount() >0) {
resultList =newArrayList<>();
while(cursor.moveToNext()) {
resultList.add(cursor.getString(0));
}
}
returnresultList;
}
//查询全文包含text内容的数据
publicList queryAll(String text) {
List resultList =null;
Cursor cursor = db.rawQuery("SELECT docid, * FROM fts_test WHERE fts_test MATCH '"+ text +"*';",null);
if(cursor !=null&& cursor.getCount() >0) {
resultList =newArrayList<>();
while(cursor.moveToNext()) {
resultList.add(String.valueOf(cursor.getString(0)) +" | "+ cursor.getString(1) +" | "+ cursor.getString(2));
}
}
returnresultList;
}
//获取包含text内容的记录数
publiclonggetCount(String text) {
longresult =0;
String match =";";
if(!TextUtils.isEmpty(text)) {
match =" WHERE fts_test MATCH '"+ text +"*';";
}
Cursor cursor = db.rawQuery("SELECT count(*) FROM fts_test"+ match,null);
if(cursor !=null&& cursor.getCount() >0) {
cursor.moveToFirst();
result = cursor.getLong(0);
}
returnresult;
}
}
结语
全文检索技术的核心是分词算法以及存储的数据结构,目前Sqlite3 FTS主要使用的是B-树的存储方式,其最低搜索性能O[log2N]
在Android客户端中可根据实际的业务场景从分词算法方面来优化。
参考文献:
https://www.sqlite.org/fts3.html
https://www.sqlite.org/fileformat.html#varint_format
http://www.doc88.com/p-3337920383826.html
https://juejin.im/entry/59e6cd266fb9a0451968ab02
https://blog.csdn.net/andanlan/article/details/54237493
http://www.droidsec.cn/特性还是漏洞?滥用-sqlite-分词器/
https://blog.csdn.net/hguisu/article/details/7962350
https://www.cnblogs.com/binyue/archive/2013/10/21/3380750.html
https://raw.githubusercontent.com/wangwang4git/SQLite3-ICU/master/sqlite-amalgamation-3081002/sqlite3.c
https://tartarus.org/martin/PorterStemmer/返回搜狐,查看更多
责任编辑: