elasticsearch下载安装
本篇前述的ES版本是7.14.2,实现了与Mysql的数据同步,ES端的搜索与分词;后来由于和Springcloud(spring-data-elasticsearch:3.0.6)集成发现版本问题,换成ES5.5.0,所以完整的安装到线上运行采用的是ES5.5.0版本。
更全面的教程及docx文档下载请访问http://honglitech.cn/productDetail/8
官网下载后解压ES7.14.2,ES、Kibana、Logstash统一下载地址https://www.elastic.co/cn/downloads/past-releases#elasticsearch
直接在bin目录下执行命令运行:
./elasticsearch
通过docker安装
wanghong@192-200-232-116 ~ % docker pull elasticsearch:7.6.2
7.6.2: Pulling from library/elasticsearch
7.6.2: Pulling from library/elasticsearch
no matching manifest for linux/arm64/v8 in the manifest list entries
wanghong@192-200-232-116 ~ % docker pull elasticsearch:7.14.2
7.14.2: Pulling from library/elasticsearch
333cbcae3fb8: Downloading 39.9MB/75.61MB
7fa00907024c: Downloading 33.07MB/91.75MB
5d68e84eef78: Download complete
756ca6399aa1: Downloading 69.82MB/343MB
689d68c97e57: Waiting
43919fab8263: Waiting
1b2ce3a977ef: Waiting 在m1使用docker的镜像的时候,如果不支持linux/arm64/v8会提示上面内容。
解决方法:使用支持linux/arm64/v8架构的镜像。
启动命令:
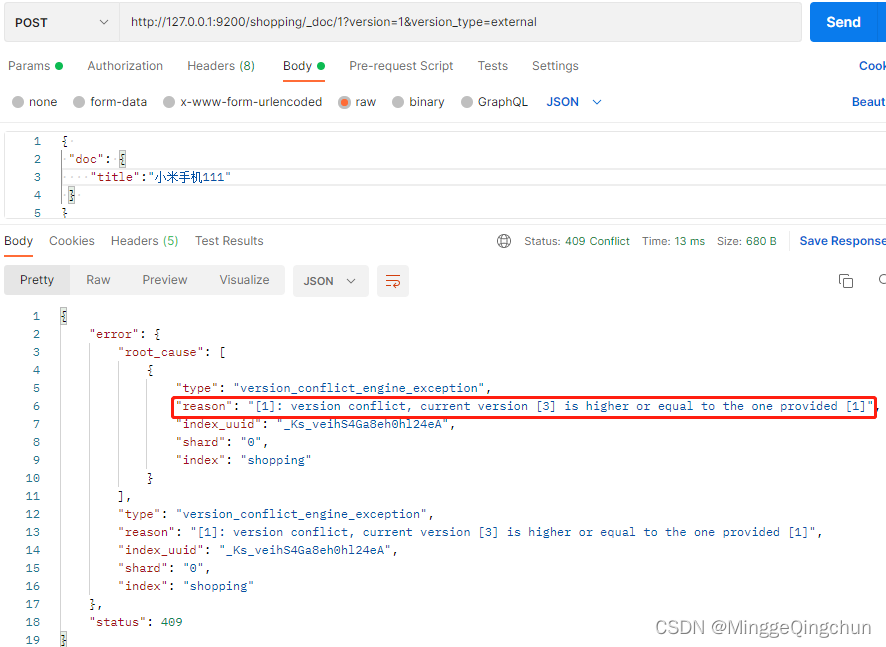
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -d elasticsearch:7.14.2解决跨域问题
进入容器修改配置文件:
docker exec -it elasticsearch /bin/bash
cd /usr/share/elasticsearch/config/
vi elasticsearch.yml末尾添加
cluster.name: "elasticsearch-cluster"
network.host: 0.0.0.0
http.cors.enabled: true
http.cors.allow-origin: "*"保存退出,重启
exit
docker restart elasticsearch解决找不到java问题

如有关于java建议将JAVA_HOME改为ES_JAVA_HOME的提示,按照提示在bin下的配置文件elasticsearch-env全部修改即可。
具体也可按照以下方式配置:
下载JDK1.8 随意放在任意目录 在环境变量中增加了一个 ES_JDK 指向了刚刚JDK1.8 的目录;
打开ES解压目录找到bin 目录 找到 elasticsearch-env 这个文件,大概在39 - 40 行 将JAVA_HOME换成刚刚配置的ES_JDK。
分析与可视化平台Kibana的下载安装
官网下载与ES版本一致的包,解压,bin下执行命令kibana即可运行。
docker安装Kibana
//拉取
docker pull kibana:7.14.2
//启动
docker run --name kibana --link=elasticsearch:7.14.2 -p 5601:5601 -d kibana:7.14.2浏览器输入地址访问Kibana:http://localhost:5601或者http://localhost:5601/app/kibana
Management里通过Dev tools打开命令终端。
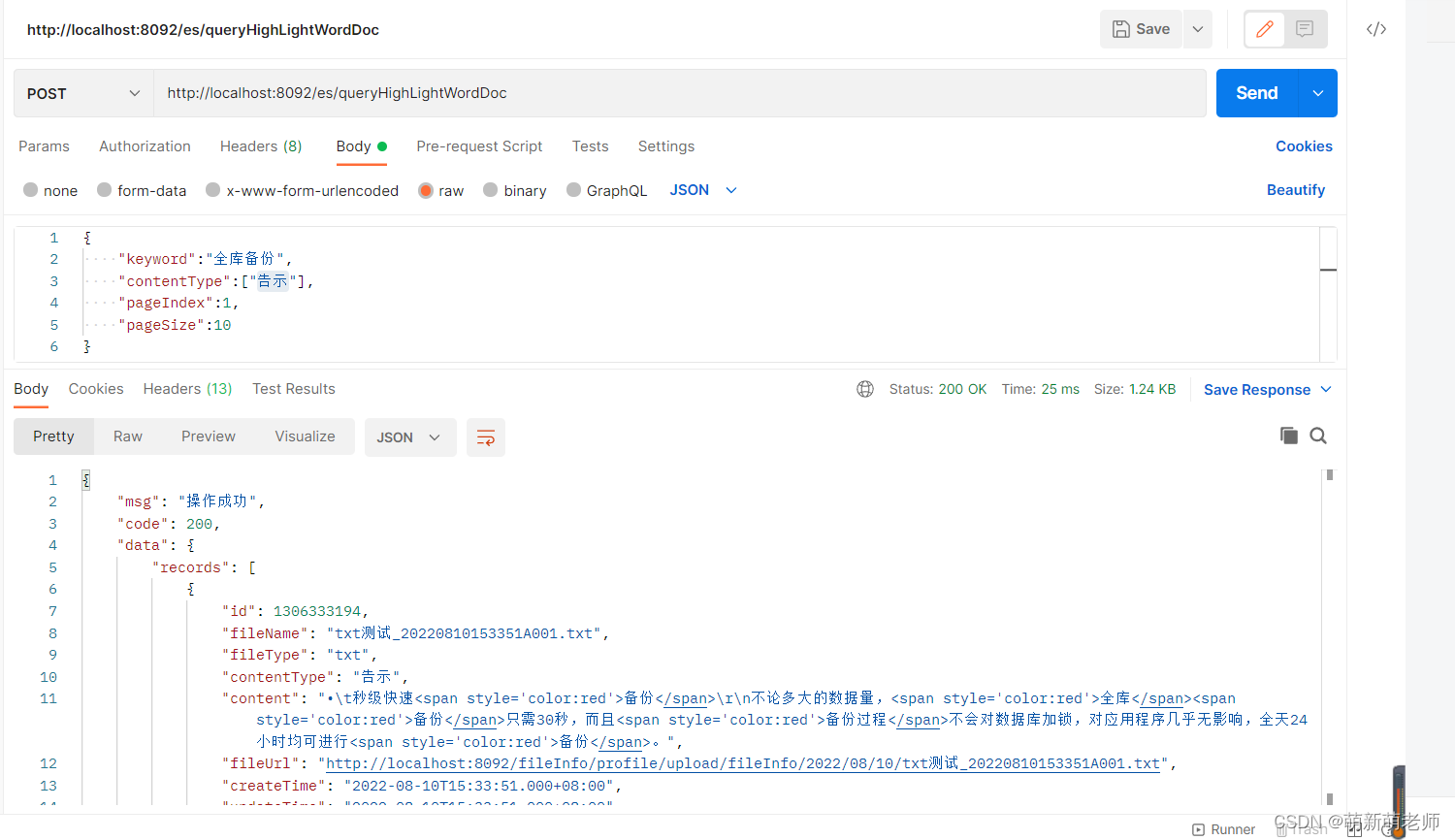
查询所有索引
通过Postman请求链接
get http://127.0.0.1:9200/_cat/indices?v
或者浏览器访问
Logstash使ES和Mysql数据同步
原理架构图:
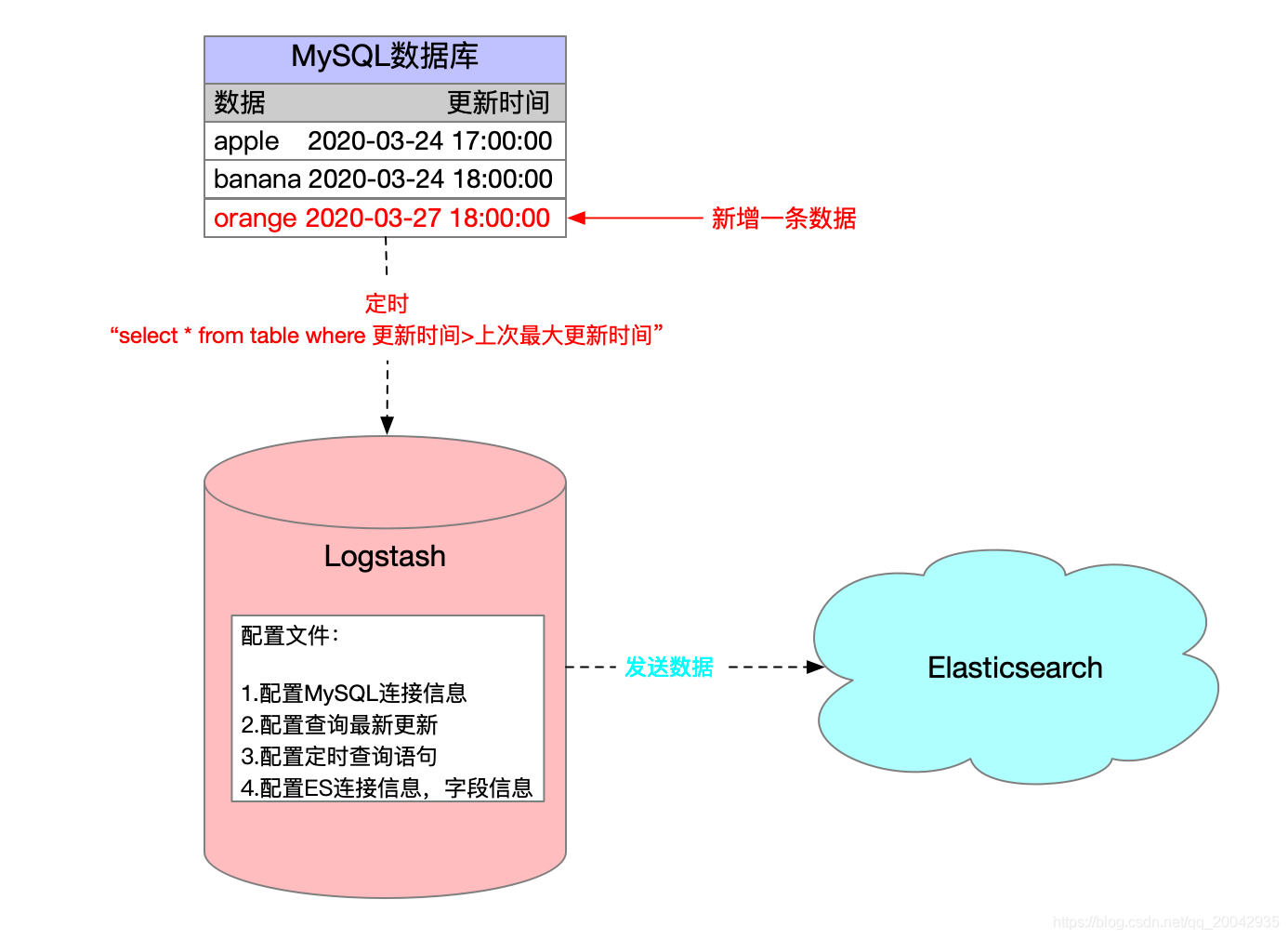
在集群环境下的Logstash的安装配置
下载与ES版本一致的Logstash,解压。
安装jdbc插件,bin目录下执行:
./logstash-plugin install logstash-input-jdbc
安装logstash-output-elasticsearch插件,bin目录下执行:
./logstash-plugin install logstash-output-elasticsearch
在安装程序lib目录下,放置连接mysql的jar,mysql-connector-java-5.1.46.jar,注意版本,不能过低。
配置文件夹conf下添加mysql.conf,其内容如下:
input {
stdin {}
jdbc {# 多表同步时,表类型区分,建议命名为“库名_表名”,每个jdbc模块需对应一个type;
type => "taodong-goods_product"# 数据库连接地址
jdbc_connection_string => "jdbc:mysql://localhost:3306/taodong-goods"# 数据库连接账号密码;
jdbc_user => "root"
jdbc_password => "123abc!*"# MySQL依赖包路径;
jdbc_driver_library => "/usr/local/logstash-8.6.2/lib/mysql-connector-java-5.1.46.jar"# the name of the driver class for mysql
jdbc_driver_class => "com.mysql.jdbc.Driver"# 数据库重连尝试次数
connection_retry_attempts => "3"# 判断数据库连接是否可用,默认false不开启
jdbc_validate_connection => "true"# 数据库连接可用校验超时时间,默认3600S
jdbc_validation_timeout => "3600"# 开启分页查询(默认false不开启);
jdbc_paging_enabled => "true"# 单次分页查询条数(默认100000,若字段较多且更新频率较高,建议调低此值);
jdbc_page_size => "500"# statement为查询数据sql,如果sql较复杂,建议配通过statement_filepath配置sql文件的存放路径;# sql_last_value为内置的变量,存放上次查询结果中最后一条数据tracking_column的值,此处即为ModifyTime;# statement_filepath => "mysql/jdbc.sql"
statement => "SELECT * FROM product WHERE UPDATED_TIME >= :sql_last_value"use_column_value => truetracking_column_type => "timestamp"tracking_column => "updated_time"last_run_metadata_path => "syncpoint_product_table"# 是否清除last_run_metadata_path的记录,需要增量同步时此字段必须为false;
clean_run => false## 同步频率(分 时 天 月 年),默认每分钟同步一次;
schedule => "* * * * *"
}
jdbc {# 多表同步时,表类型区分,建议命名为“库名_表名”,每个jdbc模块需对应一个type;
type => "taodong-goods_category"
# 数据库连接地址
jdbc_connection_string => "jdbc:mysql://localhost:3306/taodong-goods"# 数据库连接账号密码;
jdbc_user => "root"
jdbc_password => "123abc!*"# MySQL依赖包路径;
jdbc_driver_library => "/usr/local/logstash-8.6.2/lib/mysql-connector-java-5.1.46.jar"# the name of the driver class for mysql
jdbc_driver_class => "com.mysql.jdbc.Driver"# 数据库重连尝试次数
connection_retry_attempts => "3"# 判断数据库连接是否可用,默认false不开启
jdbc_validate_connection => "true"# 数据库连接可用校验超时时间,默认3600S
jdbc_validation_timeout => "3600"# 开启分页查询(默认false不开启);
jdbc_paging_enabled => "true"# 单次分页查询条数(默认100000,若字段较多且更新频率较高,建议调低此值);
jdbc_page_size => "500"# statement为查询数据sql,如果sql较复杂,建议配通过statement_filepath配置sql文件的存放路径;# sql_last_value为内置的变量,存放上次查询结果中最后一条数据tracking_column的值,此处即为ModifyTime;# statement_filepath => "mysql/jdbc.sql"
statement => "SELECT * FROM category WHERE UPDATED_TIME >= :sql_last_value"use_column_value => truetracking_column_type => "timestamp"tracking_column => "updated_time"last_run_metadata_path => "syncpoint_category_table"# 是否清除last_run_metadata_path的记录,需要增量同步时此字段必须为false;
clean_run => false## 同步频率(分 时 天 月 年),默认每分钟同步一次;
schedule => "* * * * *"
}
}filter {
json {
source => "message"
remove_field => ["message"]
}
}output {
# output模块的type需和jdbc模块的type一致
if [type] == "taodong-goods_product" {x
elasticsearch {# host => "0.0.0.0"# port => "9200"# 配置ES集群地址
hosts => ["ip:9201", "ip:9202", "ip:9203"]# 索引名字,必须小写
index => "product"# 数据唯一索引(建议使用数据库KeyID)
document_id => "%{id}"document_type => "product"
}更全面的教程及docx文档下载请访问http://honglitech.cn/productDetail/8