一、维特比算法(Viterbi Algorithm)讲解方式01:篱笆网络(Lattice)的最短路径问题
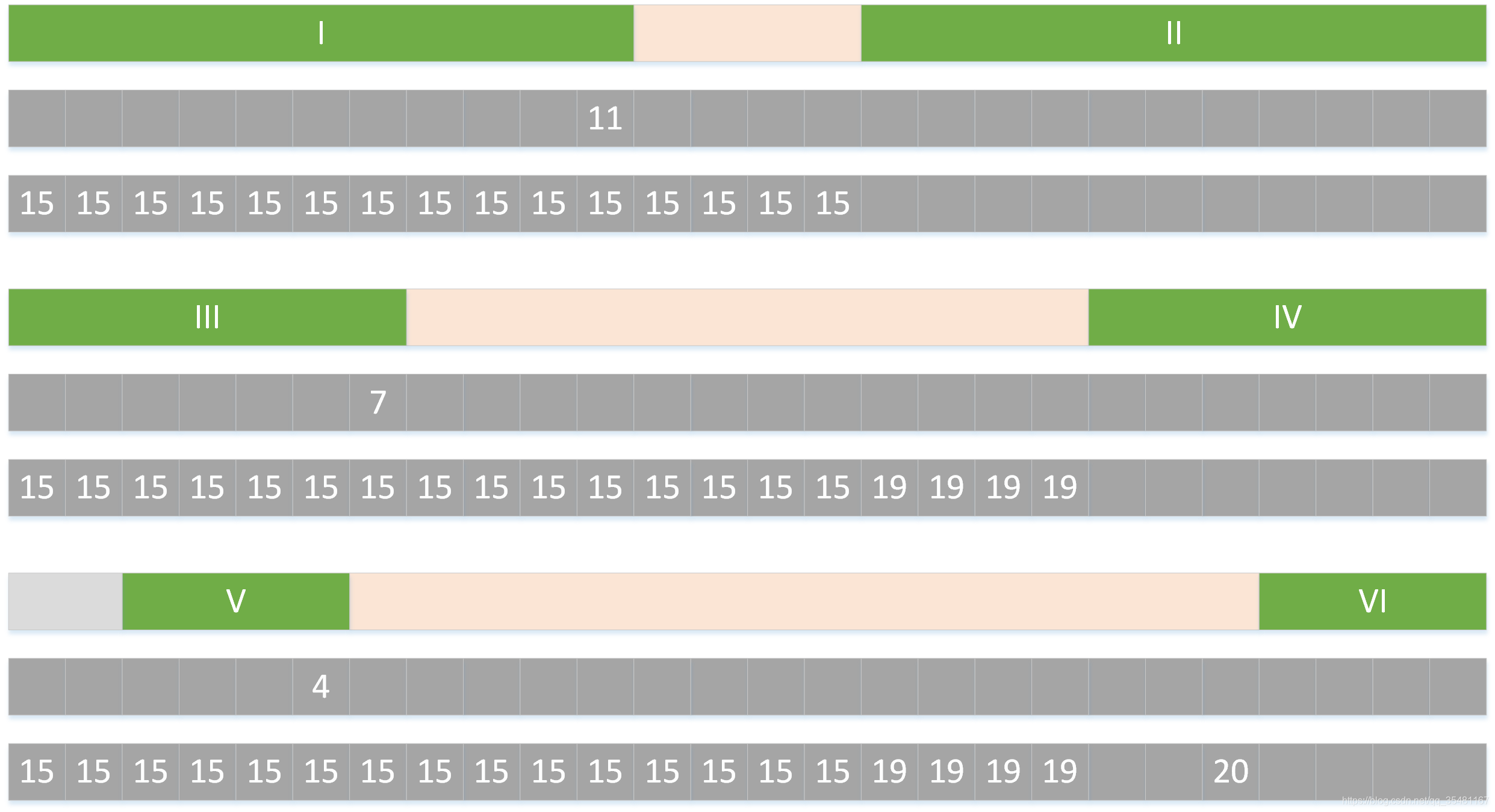
已知下图的篱笆网络,每个节点之间的数字表示相邻节点之间的距离,举个例子来说,如果我走,这个距离是。那么如果让你从A走到E,最短路径是哪一条呢?

显然大家都知道,通过穷举的方法是很容易得到最短路径,可是问题就在于如果穷举的话,需要的加法次数不用算你也知道实在是太多啦(每条路径需要计算次加法,一共条路径共次计算)!像这种没几层的篱笆网络也就罢了,如果每层13个节点,一共12层(然而这个规模对于标注问题来说也依然根本不算什么),可想而知那个线有多乱,如果仅仅穷举的话,这个计算量(大致是每条次计算,一共条路径共大约次计算)怕是超级计算机也吃不消。
如下图,假如你从S和E之间找一条最短的路径,除了遍历完所有路径,还有什么更好的方法?答案:viterbi (维特比)算法。

viterbi维特比算法解决的是篱笆型的图的最短路径问题,图的节点按列组织,每列的节点数量可以不一样,每一列的节点只能和相邻列的节点相连,不能跨列相连,节点之间有着不同的距离,距离的值就不在图上一一标注出来了,大家自行脑补。
为了找出S到E之间的最短路径,我们先从S开始从左到右一列一列地来看。
首先起点是S,从S到A列的路径有三种可能:S-A1、S-A2、S-A3,如下图:

我们不能武断地说S-A1、S-A2、S-A3中的哪一段必定是全局最短路径中的一部分,目前为止任何一段都有可能是全局最短路径的备选项。
我们继续往右看,到了B列。按B列的B1、B2、B3逐个分析。
先看B1:


如上图,经过B1的所有路径只有3条:
S-A1-B1
S-A2-B1
S-A3-B1
以上这三条路径,各节点距离加起来对比一下,我们就可以知道其中哪一条是最短的。假设S-A3-B1是最短的,那么我们就知道了经过B1的所有路径当中S-A3-B1是最短的,其它两条路径路径S-A1-B1和S-A2-B1都比S-A3-B1长,绝对不是目标答案,可以大胆地删掉了。删掉了不可能是答案的路径,就是viterbi算法(维特比算法)的重点,因为后面我们再也不用考虑这些被删掉的路径了。现在经过B1的所有路径只剩一条路径了,如下图:

接下来,我们继续看B2:

同理,如上图,经过B2的路径有3条:
S-A1-B2
S-A2-B2
S-A3-B2
这三条路径中,各节点距离加起来对比一下,我们肯定也可以知道其中哪一条是最短的,假设S-A1-B2是最短的,那么我们就知道了经过B2的所有路径当中S-A1-B2是最短的,其它两条路径路径S-A2-B2和S-A3-B1也可以删掉了。经过B2所有路径只剩一条,如下图:

接下来我们继续看B3:

同理,如上图,经过B3的路径也有3条:
S-A1-B3
S-A2-B3
S-A3-B3
这三条路径中我们也肯定可以算出其中哪一条是最短的,假设S-A2-B3是最短的,那么我们就知道了经过B3的所有路径当中S-A2-B3是最短的,其它两条路径路径S-A1-B3和S-A3-B3也可以删掉了。经过B3的所有路径只剩一条,如下图:

现在对于B列的所有节点我们都过了一遍,B列的每个节点我们都删除了一些不可能是答案的路径,看看我们剩下哪些备选的最短路径,如下图:

上图是我们删掉了其它不可能是最短路径的情况,留下了三个有可能是最短的路径:S-A3-B1、S-A1-B2、S-A2-B3。现在我们将这三条备选的路径放在一起汇总到下图:

S-A3-B1、S-A1-B2、S-A2-B3都有可能是全局的最短路径的备选路径,我们还没有足够的信息判断哪一条一定是全局最短路径的子路径。
如果我们你认为没毛病就继续往下看C列,如果不理解,回头再看一遍,前面的步骤决定你是否能看懂viterbi算法(维特比算法)。
接下来讲到C列了,类似上面说的B列,我们从C1、C2、C3一个个节点分析。
经过C1节点的路径有:
S-A3-B1-C1、
S-A1-B2-C1、
S-A2-B3-C1

和B列的做法一样,从这三条路径中找到最短的那条(假定是S-A3-B1-C1),其它两条路径同样道理可以删掉了。那么经过C1的所有路径只剩一条,如下图:

同理,我们可以找到经过C2和C3节点的最短路径,汇总一下:

到达C列时最终也只剩3条备选的最短路径,我们仍然没有足够信息断定哪条才是全局最短。
最后,我们继续看E节点,才能得出最后的结论。
到E的路径也只有3种可能性:

E点已经是终点了,我们稍微对比一下这三条路径的总长度就能知道哪条是最短路径了。

在效率方面相对于粗暴地遍历所有路径,viterbi 维特比算法到达每一列的时候都会删除不符合最短路径要求的路径,大大降低时间复杂度。
二、维特比算法(Viterbi Algorithm)讲解方式02:分词算法
维特比算法(Viterbi Algorithm)本质上还是动态规划(Dynamic Programming)
例子:“经常有意见分歧”
我们仍然是有以下几个数据:
词典:["经常","有","意见","意","见","有意见","分歧","分","歧"]
概率P(x):{"经常":0.08,"有":0.04,"意见":0.08,"意":0.01,"见":0.005,"有意见":0.002,"分歧":0.04,"分":0.02, "歧":0.005}
-ln(P(x)):{"经常":2.52,"有":3.21,"意见":2.52,"意":4.6,"见":5.29,"有意见":6.21,"分歧":3.21,"分":3.9, "歧":5.29}
如果某个词不在字典中,我们将认为其 − l n [ P ( x ) ] −ln[P(x)] −ln[P(x)] 值为20。
我们构建以下的DAG(有向图),每一个边代表一个词,我们将 − l n [ P ( x ) ] -ln[P(x)] −ln[P(x)]的值标到边上,

求 − l n [ P ( x ) ] −ln[P(x)] −ln[P(x)] 的最小值问题,就转变为求最短路径的问题。
由图可以看出,路径 0—>②—>③—>⑤—>⑦ 所求的值最小,所以其就是最优结果:经常 / 有 / 意见 / 分歧
那么我们应该怎样快速计算出来这个结果呢?
我们设 f ( n ) f(n) f(n) 代表从起点 0 0 0 到结点 n n n 的最短路径的值,所以我们想求的就是 f ( 7 ) f(7) f(7),从DAG图中可以看到,到结点⑦有2条路径:
- 从结点⑤—>结点⑦: f ( 7 ) = f ( 5 ) + 3.21 f(7)=f(5)+3.21 f(7)=f(5)+3.21
- 从结点⑥—>结点⑦: f ( 7 ) = f ( 6 ) + 5.29 f(7)=f(6)+5.29 f(7)=f(6)+5.29
我们应该从2条路径中选择路径短的。
在上面的第1条路径中, f ( 5 ) f(5) f(5) 还是未知的,我们要 f ( 5 ) f(5) f(5),同理我们发现到结点⑤的路径有3条路径:
- 从结点②—>结点⑤: f ( 5 ) = f ( 2 ) + 6.21 f(5)=f(2)+6.21 f(5)=f(2)+6.21
- 从结点③—>结点⑤: f ( 5 ) = f ( 3 ) + 2.52 f(5)=f(3)+2.52 f(5)=f(3)+2.52
- 从结点④—>结点⑤: f ( 5 ) = f ( 4 ) + 20 f(5)=f(4)+20 f(5)=f(4)+20
我们同样从3条路径中选择路径短的。以此类推,直到结点0,所有的路径值都可以算出来。我们维护一个列表来表示 f ( n ) f(n) f(n) 的各值:
| 结点 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| f(n) | 20 | 2.52 | 5.73 | 25.73 | 8.25 | 12.5 | 11.46 |
| 结点的上一个结点 | 0 | 0 | ② | ③ | ③ | ⑤ | ⑤ |
第2行代表从起点0到该结点的最短路径的值,第3行代表在最短路径中的该节点的上一个结点。
通过表,我们可以找到结点⑦的上一个结点⑤,结点⑤的上一个结点③,结点③的上一个结点②,结点②的上一个结点0,即路径:0—>②—>③—>⑤—>⑦
# -*- coding: utf-8 -*-
import math
import collections# 维特比算法(viterbi)
def word_segmentation(text):####################################################################################################################################################################word_dictionaries = ["经常", "有", "意见", "意", "见", "有意见", "分歧", "分", "歧"]probability = {"经常": 0.08, "有": 0.04, "意见": 0.08, "意": 0.01, "见": 0.005, "有意见": 0.002, "分歧": 0.04, "分": 0.02, "歧": 0.005}probability_ln = {key: -math.log(probability[key]) for key in probability}# probability_ln = {'经常': 2.5257286443082556, '有': 3.2188758248682006, '意见': 2.5257286443082556, '意': 4.605170185988091, '见': 5.298317366548036, '有意见': 6.214608098422191, '分歧': 3.2188758248682006, '分': 3.912023005428146, '歧': 5.298317366548036}print("probability_ln = {0}".format(probability_ln))# 构造图的代码并没有实现,以下只是手工建立的图【如果某个词不在字典中,我们将认为其 −ln[P(x)] 值为20。】,为了说明 维特比算法##################################################################################################################################################################### 有向五环图,存储的格式:key是结点名,value是一个结点的所有上一个结点(以及边上的权重)graph = {0: {0: (0, "")},1: {0: (20, "经")},2: {0: (2.52, "经常"), 1: (20, "常")},3: {2: (3.21, "有")},4: {3: (20, "意")},5: {2: (6.21, "有意见"), 3: (2.52, "意见"), 4: (5.30, "见")},6: {5: (3.9, "分")},7: {5: (3.21, "分歧"), 6: (5.29, "歧")}}# =====================================================================利用“维特比算法”构建各个节点的最优路径:开始=====================================================================print("#"*50, "利用“维特比算法”构建各个节点的最优路径:开始", "#"*50)f = collections.OrderedDict() # 保存结点n的f(n)以及实现f(n)的上一个结点【f(n):代表从起点 0 到结点 n 的最短路径的值】for key, value in graph.items(): # 遍历有向图graph中的所有节点print("\nkey = {0}----value = {1}".format(key, value))tuple_temp_list = []for pre_node_key, pre_node_value in value.items(): # 遍历当前节点的所有上一个节点【pre_node_key:上一个节点的节点号,pre_node_value:本节点距离上一个节点的距离】# print("本节点的节点号:key = {0}----上一个节点的节点号:pre_node_key = {1}----本节点距离上一个节点的距离:pre_node_value = {2}".format(key, pre_node_key, pre_node_value))distance_from_0 = 0if pre_node_key not in f: # 当遍历到0节点时,该节点的上一个结点还没有计算f(n);distance_from_0 = pre_node_value[0] # 0节点的上一节点(依旧时0节点)的距离else: # 当遍历到0节点之后的节点distance_from_0 = pre_node_value[0] + f[pre_node_key][0] # pre_node_value[0]:当前节点距离上一节点的距离;f[pre_node_key][0]:当前节点的上一节点“pre_node_key”距离0节点的最短距离print("本节点的节点号:key = {0}----本节点可触及的上一节点号:pre_node_key = {1}----本节点距离上一个节点“节点{1}”的距离:pre_node_value = {2}----上一节点“节点{1}”距离0节点的最短距离:f[pre_node_key][0] = {3}----本节点路径上一节点“节点{1}”距离0节点的距离:distance_from_0 = {4}".format(key, pre_node_key, pre_node_value, f[pre_node_key][0], distance_from_0))tuple_temp = (distance_from_0, pre_node_key) # 【pre_node_value[0]:本节点距离0节点的最短距离;pre_node_key:本节点实现距离0节点距离最短时的上一个节点的节点号】tuple_temp_list.append(tuple_temp)min_temp = min(tuple_temp_list) # 比较比较当前节点路径所触及的所有上一节点到达0节点的距离,得出当前节点 key 距离0节点的最短距离# min_temp = min((pre_node_value[0], pre_node_key) if pre_node_key not in f else (pre_node_value[0] + f[pre_node_key][0], pre_node_key) for pre_node_key, pre_node_value in value.items()) # 高阶写法print("本节点的节点号:key = {0}----当前节点路径所触及的所有上一节点到达0节点的距离:tuple_temp_list = {1}----当前节点 key 距离0节点的最短距离:min_temp = {2}".format(key, tuple_temp_list, min_temp))f[key] = min_tempprint("将当前节点{0}距离0节点的(最短距离,路径的节点号)= ({0},{1}) 加入f---->f = {2}".format(key, min_temp, f)) # f = OrderedDict([(0, (0, 0)), (1, (20, 0)), (2, (2.52, 0)), (3, (5.73, 2)), (4, (25.73, 3)), (5, (8.25, 3)), (6, (12.15, 5)), (7, (11.46, 5))])print("#" * 50, "利用“维特比算法”构建各个节点的最优路径:结束", "#" * 50)# =====================================================================利用“维特比算法”构建各个节点的最优路径:结束=====================================================================# =====================================================================提取最优最优路径:开始=====================================================================print("\n", "#" * 50, "提取最优路径:开始", "#" * 50)last = next(reversed(f)) # 最后一个结点7first = next(iter(f)) # 第一个结点0path_result = [last, ] # 保存路径,最后一个结点先添入pre_last = f[last] # 最后一个结点的所有前一个结点print("最后一个结点7:last = {0}----第一个结点0:first = {1}----初始化最优路径:path_result = {2}----最后一个结点的所有前一个结点:pre_last = {3}".format(last, first, path_result, pre_last))while pre_last[1] is not first: # 没到达第一个结点就一直循环,查找上一个节点的上一个节点号path_result.append(pre_last[1]) # 加入一个路径结点Xpre_last = f[pre_last[1]] # 定位到路径结点X的上一个结点path_result.append(first) # 第一个结点添入print("最优路径:path_result = {0}".format(path_result)) # 结果:[7, 5, 3, 2, 0]print("#" * 50, "提取最优路径:结束", "#" * 50)# =====================================================================提取最优最优路径:结束=====================================================================# =====================================================================通过最优路径得到分词结果:开始=====================================================================print("\n", "#" * 50, "通过最优路径得到分词结果:开始", "#" * 50)text_result = []for index, num in enumerate(path_result): # 找到路径上边的词if index + 1 == len(path_result):breakword = graph[num][path_result[index + 1]][1]print("最优路径:path_result = {0}----index = {1}----当前节点号:num = {2}----在最优路径里,当前节点号的上一个节点号:path_result[index + 1] = {3}----当前节点号{2}与上一节点号{3}之间的词汇:{4}".format(path_result, index, num, path_result[index + 1], word))text_result.append(word)print("text_result = {0}".format(text_result))text_result.reverse() # 翻转一下print("翻转后:text_result = {0}".format(text_result))print("#" * 50, "通过最优路径得到分词结果:结束", "#" * 50)return "".join(word + "/" for word in text_result)# =====================================================================通过最优路径得到分词结果:结束=====================================================================if __name__ == '__main__':content = "经常有意见分歧"word_segmentation_result = word_segmentation(content)print("word_segmentation_result:", word_segmentation_result)
打印结果:
probability_ln = {'经常': 2.5257286443082556, '有': 3.2188758248682006, '意见': 2.5257286443082556, '意': 4.605170185988091, '见': 5.298317366548036, '有意见': 6.214608098422191, '分歧': 3.2188758248682006, '分': 3.912023005428146, '歧': 5.298317366548036}
################################################## 利用“维特比算法”构建各个节点的最优路径:开始 ##################################################
key = 0----value = {0: (0, '')}
本节点的节点号:key = 0----当前节点路径所触及的所有上一节点到达0节点的距离:tuple_temp_list = [(0, 0)]----当前节点 key 距离0节点的最短距离:min_temp = (0, 0)
将当前节点0距离0节点的(最短距离,路径的节点号)= (0,(0, 0)) 加入f---->f = OrderedDict([(0, (0, 0))])key = 1----value = {0: (20, '经')}
本节点的节点号:key = 1----本节点可触及的上一节点号:pre_node_key = 0----本节点距离上一个节点“节点0”的距离:pre_node_value = (20, '经')----上一节点“节点0”距离0节点的最短距离:f[pre_node_key][0] = 0----本节点路径上一节点“节点0”距离0节点的距离:distance_from_0 = 20
本节点的节点号:key = 1----当前节点路径所触及的所有上一节点到达0节点的距离:tuple_temp_list = [(20, 0)]----当前节点 key 距离0节点的最短距离:min_temp = (20, 0)
将当前节点1距离0节点的(最短距离,路径的节点号)= (1,(20, 0)) 加入f---->f = OrderedDict([(0, (0, 0)), (1, (20, 0))])key = 2----value = {0: (2.52, '经常'), 1: (20, '常')}
本节点的节点号:key = 2----本节点可触及的上一节点号:pre_node_key = 0----本节点距离上一个节点“节点0”的距离:pre_node_value = (2.52, '经常')----上一节点“节点0”距离0节点的最短距离:f[pre_node_key][0] = 0----本节点路径上一节点“节点0”距离0节点的距离:distance_from_0 = 2.52
本节点的节点号:key = 2----本节点可触及的上一节点号:pre_node_key = 1----本节点距离上一个节点“节点1”的距离:pre_node_value = (20, '常')----上一节点“节点1”距离0节点的最短距离:f[pre_node_key][0] = 20----本节点路径上一节点“节点1”距离0节点的距离:distance_from_0 = 40
本节点的节点号:key = 2----当前节点路径所触及的所有上一节点到达0节点的距离:tuple_temp_list = [(2.52, 0), (40, 1)]----当前节点 key 距离0节点的最短距离:min_temp = (2.52, 0)
将当前节点2距离0节点的(最短距离,路径的节点号)= (2,(2.52, 0)) 加入f---->f = OrderedDict([(0, (0, 0)), (1, (20, 0)), (2, (2.52, 0))])key = 3----value = {2: (3.21, '有')}
本节点的节点号:key = 3----本节点可触及的上一节点号:pre_node_key = 2----本节点距离上一个节点“节点2”的距离:pre_node_value = (3.21, '有')----上一节点“节点2”距离0节点的最短距离:f[pre_node_key][0] = 2.52----本节点路径上一节点“节点2”距离0节点的距离:distance_from_0 = 5.73
本节点的节点号:key = 3----当前节点路径所触及的所有上一节点到达0节点的距离:tuple_temp_list = [(5.73, 2)]----当前节点 key 距离0节点的最短距离:min_temp = (5.73, 2)
将当前节点3距离0节点的(最短距离,路径的节点号)= (3,(5.73, 2)) 加入f---->f = OrderedDict([(0, (0, 0)), (1, (20, 0)), (2, (2.52, 0)), (3, (5.73, 2))])key = 4----value = {3: (20, '意')}
本节点的节点号:key = 4----本节点可触及的上一节点号:pre_node_key = 3----本节点距离上一个节点“节点3”的距离:pre_node_value = (20, '意')----上一节点“节点3”距离0节点的最短距离:f[pre_node_key][0] = 5.73----本节点路径上一节点“节点3”距离0节点的距离:distance_from_0 = 25.73
本节点的节点号:key = 4----当前节点路径所触及的所有上一节点到达0节点的距离:tuple_temp_list = [(25.73, 3)]----当前节点 key 距离0节点的最短距离:min_temp = (25.73, 3)
将当前节点4距离0节点的(最短距离,路径的节点号)= (4,(25.73, 3)) 加入f---->f = OrderedDict([(0, (0, 0)), (1, (20, 0)), (2, (2.52, 0)), (3, (5.73, 2)), (4, (25.73, 3))])key = 5----value = {2: (6.21, '有意见'), 3: (2.52, '意见'), 4: (5.3, '见')}
本节点的节点号:key = 5----本节点可触及的上一节点号:pre_node_key = 2----本节点距离上一个节点“节点2”的距离:pre_node_value = (6.21, '有意见')----上一节点“节点2”距离0节点的最短距离:f[pre_node_key][0] = 2.52----本节点路径上一节点“节点2”距离0节点的距离:distance_from_0 = 8.73
本节点的节点号:key = 5----本节点可触及的上一节点号:pre_node_key = 3----本节点距离上一个节点“节点3”的距离:pre_node_value = (2.52, '意见')----上一节点“节点3”距离0节点的最短距离:f[pre_node_key][0] = 5.73----本节点路径上一节点“节点3”距离0节点的距离:distance_from_0 = 8.25
本节点的节点号:key = 5----本节点可触及的上一节点号:pre_node_key = 4----本节点距离上一个节点“节点4”的距离:pre_node_value = (5.3, '见')----上一节点“节点4”距离0节点的最短距离:f[pre_node_key][0] = 25.73----本节点路径上一节点“节点4”距离0节点的距离:distance_from_0 = 31.03
本节点的节点号:key = 5----当前节点路径所触及的所有上一节点到达0节点的距离:tuple_temp_list = [(8.73, 2), (8.25, 3), (31.03, 4)]----当前节点 key 距离0节点的最短距离:min_temp = (8.25, 3)
将当前节点5距离0节点的(最短距离,路径的节点号)= (5,(8.25, 3)) 加入f---->f = OrderedDict([(0, (0, 0)), (1, (20, 0)), (2, (2.52, 0)), (3, (5.73, 2)), (4, (25.73, 3)), (5, (8.25, 3))])key = 6----value = {5: (3.9, '分')}
本节点的节点号:key = 6----本节点可触及的上一节点号:pre_node_key = 5----本节点距离上一个节点“节点5”的距离:pre_node_value = (3.9, '分')----上一节点“节点5”距离0节点的最短距离:f[pre_node_key][0] = 8.25----本节点路径上一节点“节点5”距离0节点的距离:distance_from_0 = 12.15
本节点的节点号:key = 6----当前节点路径所触及的所有上一节点到达0节点的距离:tuple_temp_list = [(12.15, 5)]----当前节点 key 距离0节点的最短距离:min_temp = (12.15, 5)
将当前节点6距离0节点的(最短距离,路径的节点号)= (6,(12.15, 5)) 加入f---->f = OrderedDict([(0, (0, 0)), (1, (20, 0)), (2, (2.52, 0)), (3, (5.73, 2)), (4, (25.73, 3)), (5, (8.25, 3)), (6, (12.15, 5))])key = 7----value = {5: (3.21, '分歧'), 6: (5.29, '歧')}
本节点的节点号:key = 7----本节点可触及的上一节点号:pre_node_key = 5----本节点距离上一个节点“节点5”的距离:pre_node_value = (3.21, '分歧')----上一节点“节点5”距离0节点的最短距离:f[pre_node_key][0] = 8.25----本节点路径上一节点“节点5”距离0节点的距离:distance_from_0 = 11.46
本节点的节点号:key = 7----本节点可触及的上一节点号:pre_node_key = 6----本节点距离上一个节点“节点6”的距离:pre_node_value = (5.29, '歧')----上一节点“节点6”距离0节点的最短距离:f[pre_node_key][0] = 12.15----本节点路径上一节点“节点6”距离0节点的距离:distance_from_0 = 17.44
本节点的节点号:key = 7----当前节点路径所触及的所有上一节点到达0节点的距离:tuple_temp_list = [(11.46, 5), (17.44, 6)]----当前节点 key 距离0节点的最短距离:min_temp = (11.46, 5)
将当前节点7距离0节点的(最短距离,路径的节点号)= (7,(11.46, 5)) 加入f---->f = OrderedDict([(0, (0, 0)), (1, (20, 0)), (2, (2.52, 0)), (3, (5.73, 2)), (4, (25.73, 3)), (5, (8.25, 3)), (6, (12.15, 5)), (7, (11.46, 5))])
################################################## 利用“维特比算法”构建各个节点的最优路径:结束 #################################################################################################### 提取最优路径:开始 ##################################################
最后一个结点7:last = 7----第一个结点0:first = 0----初始化最优路径:path_result = [7]----最后一个结点的所有前一个结点:pre_last = (11.46, 5)
最优路径:path_result = [7, 5, 3, 2, 0]
################################################## 提取最优路径:结束 #################################################################################################### 通过最优路径得到分词结果:开始 ##################################################
最优路径:path_result = [7, 5, 3, 2, 0]----index = 0----当前节点号:num = 7----在最优路径里,当前节点号的上一个节点号:path_result[index + 1] = 5----当前节点号7与上一节点号5之间的词汇:分歧
最优路径:path_result = [7, 5, 3, 2, 0]----index = 1----当前节点号:num = 5----在最优路径里,当前节点号的上一个节点号:path_result[index + 1] = 3----当前节点号5与上一节点号3之间的词汇:意见
最优路径:path_result = [7, 5, 3, 2, 0]----index = 2----当前节点号:num = 3----在最优路径里,当前节点号的上一个节点号:path_result[index + 1] = 2----当前节点号3与上一节点号2之间的词汇:有
最优路径:path_result = [7, 5, 3, 2, 0]----index = 3----当前节点号:num = 2----在最优路径里,当前节点号的上一个节点号:path_result[index + 1] = 0----当前节点号2与上一节点号0之间的词汇:经常
text_result = ['分歧', '意见', '有', '经常']
翻转后:text_result = ['经常', '有', '意见', '分歧']
################################################## 通过最优路径得到分词结果:结束 ##################################################
word_segmentation_result: 经常/有/意见/分歧/Process finished with exit code 0