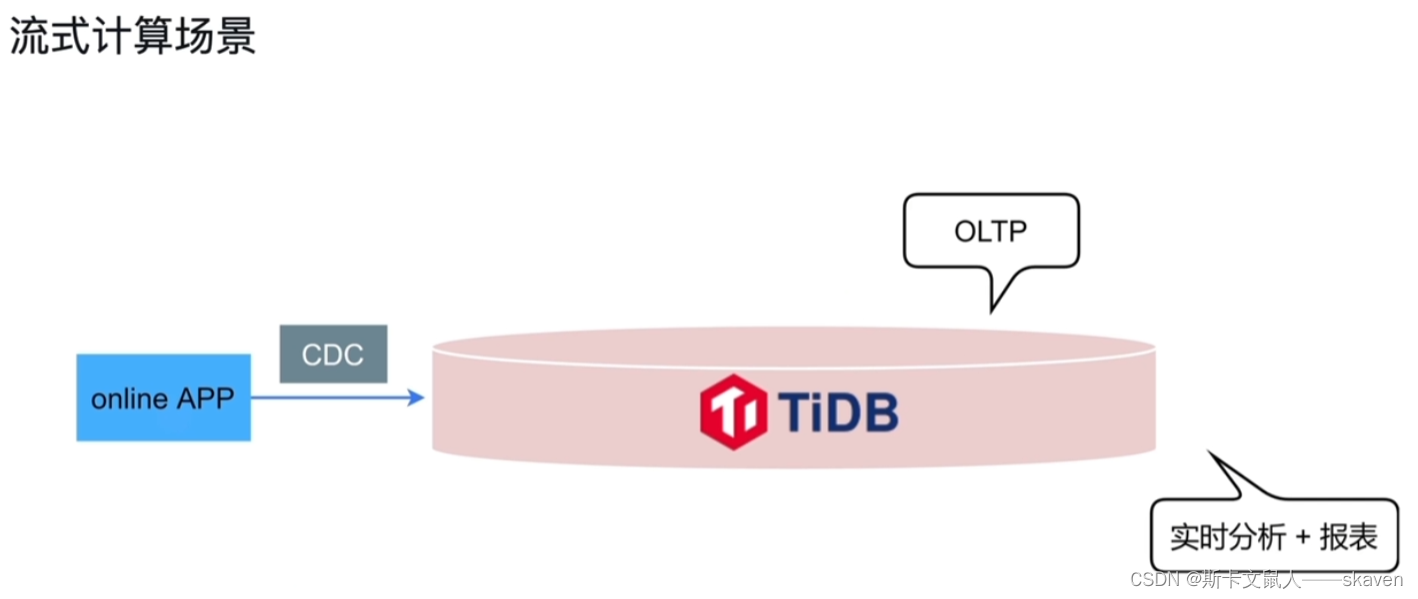
内存碎片的产生:
内存分配有静态分配和动态分配两种
静态分配在程序编译链接时分配的大小和使用寿命就已经确定,而应用上要求操作系统可以提供给进程运行时申请和释放任意大小内存的功能,这就是内存的动态分配。
因此动态分配将不可避免会产生内存碎片的问题,那么什么是内存碎片?内存碎片即“碎片的内存”描述一个系统中所有不可用的空闲内存,这些碎片之所以不能被使用,是因为负责动态分配内存的分配算法使得这些空闲的内存无法使用,这一问题的发生,原因在于这些空闲内存以小且不连续方式出现在不同的位置。因此这个问题的或大或小取决于内存管理算法的实现上。
为什么会产生这些小且不连续的空闲内存碎片呢?
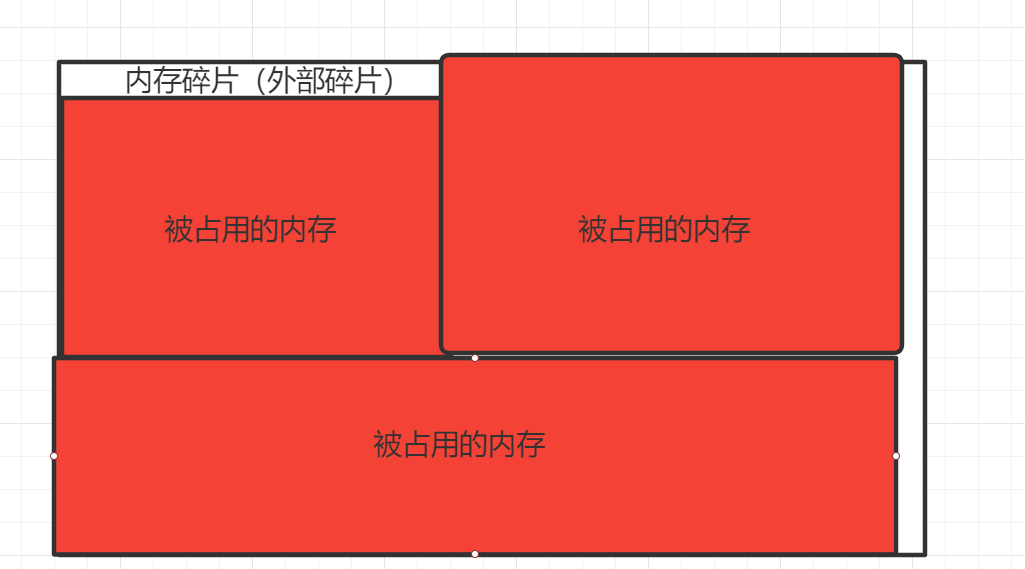
实际上这些空闲内存碎片存在的方式有两种:a.内部碎片 b.外部碎片 。
内部碎片的产生:因为所有的内存分配必须起始于可被 4、8 或 16 整除(视处理器体系结构而定)的地址或者因为MMU的分页机制的限制,决定内存分配算法仅能把预定大小的内存块分配给客户。假设当某个客户请求一个 43 字节的内存块时,因为没有适合大小的内存,所以它可能会获得 44字节、48字节等稍大一点的字节,因此由所需大小四舍五入而产生的多余空间就叫内部碎片。
外部碎片的产生: 频繁的分配与回收物理页面会导致大量的、连续且小的页面块夹杂在已分配的页面中间,就会产生外部碎片。假设有一块一共有100个单位的连续空闲内存空间,范围是0~99。如果你从中申请一块内存,如10个单位,那么申请出来的内存块就为0~9区间。这时候你继续申请一块内存,比如说5个单位大,第二块得到的内存块就应该为10~14区间。如果你把第一块内存块释放,然后再申请一块大于10个单位的内存块,比如说20个单位。因为刚被释放的内存块不能满足新的请求,所以只能从15开始分配出20个单位的内存块。现在整个内存空间的状态是0~9空闲,10~14被占用,15~24被占用,25~99空闲。其中0~9就是一个内存碎片了。如果10~14一直被占用,而以后申请的空间都大于10个单位,那么0~9就永远用不上了,变成外部碎片。
如何解决内存碎片:
采用Slab Allocation机制:整理内存以便重复使用
最近的memcached默认情况下采用了名为Slab Allocator的机制分配、管理内存。在该机制出现以前,内存的分配是通过对所有记录简单地进行malloc和free来进行的。但是,这种方式会导致内存碎片,加重操作系统内存管理器的负担,最坏的情况下,会导致操作系统比memcached进程本身还慢。Slab Allocator就是为解决该问题而诞生的。
下面来看看Slab Allocator的原理。下面是memcached文档中的slab allocator的目标:he primary goal of the slabs subsystem in memcached was to eliminate memory fragmentation issuestotally by using fixedsizememory chunks coming from a few predetermined size classes.
也就是说,Slab Allocator的基本原理是按照预先规定的大小,将分配的内存分割成特定长度的块,以完全解决内存碎片问题。Slab Allocation的原理相当简单。将分配的内存分割成各种尺寸的块(chunk),并把尺寸相同的块分成组(chunk的集合)(图2.1)。

slab allocator还有重复使用已分配的内存的目的。也就是说,分配到的内存不会释放,而是重复利用
Slab Allocation的主要术语
Page
分配给Slab的内存空间,默认是1MB。分配给Slab之后根据slab的大小切分成chunk。
Chunk
用于缓存记录的内存空间。
Slab Class
特定大小的chunk的组。
在Slab中缓存记录的原理
下面说明memcached如何针对客户端发送的数据选择slab并缓存到chunk中。memcached根据收到的数据的大小,选择最适合数据大小的slab(图2.2)。memcached中保存着slab内空闲chunk的列表,根据该列表选择chunk,然后将数据缓存于其中。
图2.2:选择存储记录的组的方法
实际上,Slab Allocator也是有利也有弊。下面介绍一下它的缺点。
Slab Allocator的缺点
Slab Allocator解决了当初的内存碎片问题,但新的机制也给memcached带来了新的问题。这个问题就是,由于分配的是特定长度的内存,因此无法有效利用分配的内存。例如,将100字节的数据缓存到128字节的chunk中,剩余的28字节就浪费了

对于该问题目前还没有完美的解决方案,但在文档中记载了比较有效的解决方案。
The most efficient way to reduce the waste is to use a list of size classes that closely matches (if that's at all
possible) common sizes of objects that the clients of this particular installation of memcached are likely to
store.
就是说,如果预先知道客户端发送的数据的公用大小,或者仅缓存大小相同的数据的情况下,只要使用适合数据大小的组的列表,就可以减少浪费。但是很遗憾,现在还不能进行任何调优,只能期待以后的版本了。但是,我们可以调节slab class的大小的差别
最佳适合与最差适合分配程序
最佳适合算法在功能上与最先适合算法类似,不同之处是,系统在分配一个内存块时,要搜索整个自由表,寻找最接近请求存储量的内存块。这种搜索所花的时间要比最先适合算法长得多,但不存在分配大小内存块所需时间的差异。最佳适合算法产生的内存碎片要比最先适合算法多,因为将小而不能使用的碎片放在自由表开头部分的排序趋势更为强烈。由于这一消极因素,最佳适合算法几乎从来没有人采用过。
最差适合算法也很少采用。最差适合算法的功能与最佳适合算法相同,不同之处是,当分配一个内存块时,系统在整个自由表中搜索与请求存储量不匹配的内存快。这种方法比最佳适合算法速度快,因为它产生微小而又不能使用的内存碎片的倾向较弱。始终选择最大空闲内存块,再将其分为小内存块,这样就能提高剩余部分大得足以供系统使用的概率。
伙伴(buddy)分配程序与本文描述的其它分配程序不同,它不能根据需要从被管理内存的开头部分创建新内存。它有明确的共性,就是各个内存块可分可合,但不是任意的分与合。每个块都有个朋友,或叫“伙伴”,既可与之分开,又可与之结合。伙伴分配程序把内存块存放在比链接表更先进的数据结构中。这些结构常常是桶型、树型和堆型的组合或变种。一般来说,伙伴分配程序的工作方式是难以描述的,因为这种技术随所选数据结构的不同而各异。由于有各种各样的具有已知特性的数据结构可供使用,所以伙伴分配程序得到广泛应用。有些伙伴分配程序甚至用在源码中。伙伴分配程序编写起来常常很复杂,其性能可能各不相同。伙伴分配程序通常在某种程度上限制内存碎片。
固定存储量分配程序有点像最先空闲算法。通常有一个以上的自由表,而且更重要的是,同一自由表中的所有内存块的存储量都相同。至少有四个指针:MSTART指向被管理内存的起点,MEND 指向被管理内存的末端,MBREAK 指向 MSTART 与 MEND 之间已用内存的末端,而 PFREE[n]则是指向任何空闲内存块的一排指针。在开始时,PFREE 为 NULL,MBREAK 指针为MSTART。当一个分配请求到来时,系统将请求的存储量增加到可用存储量之一。然后,系统检查 PFREE[ 增大后的存储量 ] 空闲内存块。因为PFREE[ 增大后的存储量 ] 为 NULL,一个具有该存储量加上一个管理标题的内存块就脱离 MBREAK,MBREAK 被更新。
这些步骤反复进行,直至系统使一个内存块空闲为止,此时管理标题包含有该内存块的存储量。当有一内存块空闲时,PFREE[ 相应存储量 ]通过标题的链接表插入项更新为指向该内存块,而该内存块本身则用一个指向 PFREE[ 相应存储量 ]以前内容的指针来更新,以建立一个链接表。下一次分配请求到来时,系统将 PFREE[ 增大的请求存储量 ]链接表的第一个内存块送给系统。没有理由搜索链接表,因为所有链接的内存块的存储量都是相同的。
固定存储量分配程序很容易实现,而且便于计算内存碎片,至少在块存储量的数量较少时是这样。但这种分配程序的局限性在于要有一个它可以分配的最大存储量。固定存储量分配程序速度快,并可在任何状况下保持速度。这些分配程序可能会产生大量的内部内存碎片,但对某些系统而言,它们的优点会超过缺点。
减少内存碎片
内存碎片是因为在分配一个内存块后,使之空闲,但不将空闲内存归还给最大内存块而产生的。最后这一步很关键。如果内存分配程序是有效的,就不能阻止系统分配内存块并使之空闲。即使一个内存分配程序不能保证返回的内存能与最大内存块相连接(这种方法可以彻底避免内存碎片问题),但你可以设法控制并限制内存碎片。所有这些作法涉及到内存块的分割。每当系统减少被分割内存块的数量,确保被分割内存块尽可能大时,你就会有所改进。
这样做的目的是尽可能多次反复使用内存块,而不要每次都对内存块进行分割,以正好符合请求的存储量。分割内存块会产生大量的小内存碎片,犹如一堆散沙。以后很难把这些散沙与其余内存结合起来。比较好的办法是让每个内存块中都留有一些未用的字节。留有多少字节应看系统要在多大
程度上避免内存碎片。对小型系统来说,增加几个字节的内部碎片是朝正确方向迈出的一步。当系统请求1字节内存时,你分配的存储量取决于系统的工作状态。
如果系统分配的内存存储量的主要部分是 1 ~ 16 字节,则为小内存也分配 16字节是明智的。只要限制可以分配的最大内存块,你就能够获得较大的节约效果。但是,这种方法的缺点是,系统会不断地尝试分配大于极限的内存块,这使系统可能会停止工作。减少最大和最小内存块存储量之间内存存储量的数量也是有用的。采用按对数增大的内存块存储量可以避免大量的碎片。例如,每个存储量可能都比前一个存储量大20%。在嵌入式系统中采用“一种存储量符合所有需要”对于嵌入式系统中的内存分配程序来说可能是不切实际的。这种方法从内部碎片来看是代价极高的,但系统可以彻底避免外部碎片,达到支持的最大存储量。
将相邻空闲内存块连接起来是一种可以显著减少内存碎片的技术。如果没有这一方法,某些分配算法(如最先适合算法)将根本无法工作。然而,效果是有限的,将邻近内存块连接起来只能缓解由于分配算法引起的问题,而无法解决根本问题。而且,当内存块存储量有限时,相邻内存块连接可能很难实现。
有些内存分配器很先进,可以在运行时收集有关某个系统的分配习惯的统计数据,然后,按存储量将所有的内存分配进行分类,例如分为小、中和大三类。系统将每次分配指向被管理内存的一个区域,因为该区域包括这样的内存块存储量。较小存储量是根据较大存储量分配的。这种方案是最先适合算法和一组有限的固定存储量算法的一种有趣的混合,但不是实时的。
有效地利用暂时的局限性通常是很困难的,但值得一提的是,在内存中暂时扩展共处一地的分配程序更容易产生内存碎片。尽管其它技术可以减轻这一问题,但限制不同存储量内存块的数目仍是减少内存碎片的主要方法。
现代软件环境业已实现各种避免内存碎片的工具。例如,专为分布式高可用性容错系统开发的 OSE 实时操作系统可提供三种运行时内存分配程序:内核alloc(),它根据系统或内存块池来分配;堆 malloc(),根据程序堆来分配; OSE 内存管理程序alloc_region,它根据内存管理程序内存来分配。
从许多方面来看,Alloc就是终极内存分配程序。它产生的内存碎片很少,速度很快,并有判定功能。你可以调整甚至去掉内存碎片。只是在分配一个存储量后,使之空闲,但不再分配时,才会产生外部碎片。内部碎片会不断产生,但对某个给定的系统和八种存储量来说是恒定不变的。
Alloc是一种有八个自由表的固定存储量内存分配程序的实现方法。系统程序员可以对每一种存储量进行配置,并可决定采用更少的存储量来进一步减少碎片。除开始时以外,分配内存块和使内存块空闲都是恒定时间操作。首先,系统必须对请求的存储量四舍五入到下一个可用存储量。就八种存储量而言,这一目标可用三个 如果语句来实现。其次,系统总是在八个自由表的表头插入或删除内存块。开始时,分配未使用的内存要多花几个周期的时间,但速度仍然极快,而且所花时间恒定不变。
堆 malloc() 的内存开销(8 ~ 16 字节/分配)比 alloc小,所以你可以停用内存的专用权。malloc()分配程序平均来讲是相当快的。它的内部碎片比alloc()少,但外部碎片则比alloc()多。它有一个最大分配存储量,但对大多数系统来说,这一极限值足够大。可选的共享所有权与低开销使 malloc() 适用于有许多小型对象和共享对象的 C++应用程序。堆是一种具有内部堆数据结构的伙伴系统的实现方法。在 OSE 中,有 28 个不同的存储量可供使用,每种存储量都是前两种存储量之和,于是形成一个斐波那契(Fibonacci)序列。实际内存块存储量为序列数乘以 16 字节,其中包括分配程序开销或者 8 字节/分配(在文件和行信息启用的情况下为 16 字节)。
当你很少需要大块内存时,则OSE内存管理程序最适用。典型的系统要把存储空间分配给整个系统、堆或库。在有 MMU 的系统中,有些实现方法使用 MMU 的转换功能来显著降低甚至消除内存碎片。在其他情况下,OSE 内存管理程序会产生非常多的碎片。它没有最大分配存储量,而且是一种最先适合内存分配程序的实现方法。内存分配被四舍五入到页面的偶数——典型值是 4 k 字节。
本文来自:我爱研发网(52RD.com) - R&D大本营