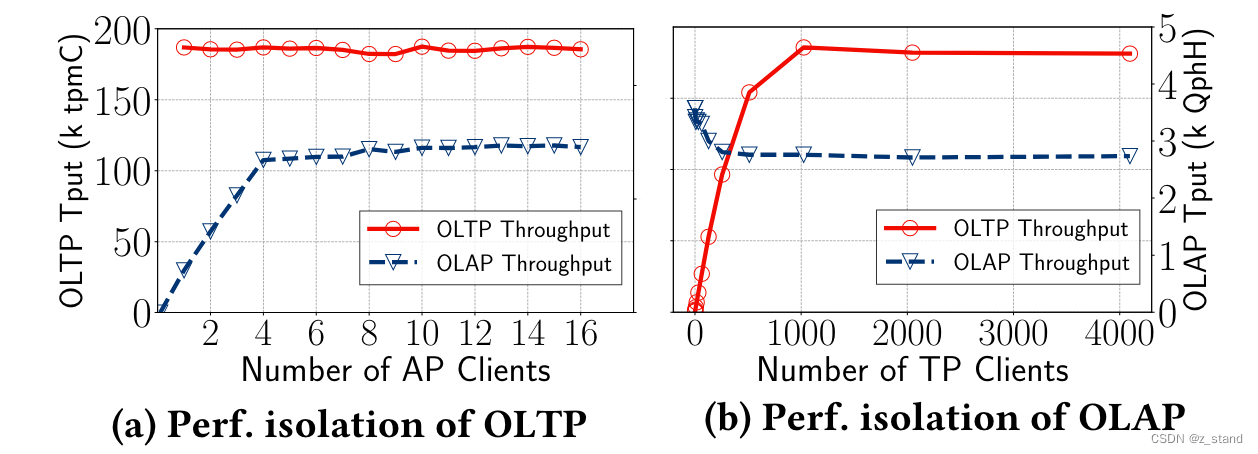
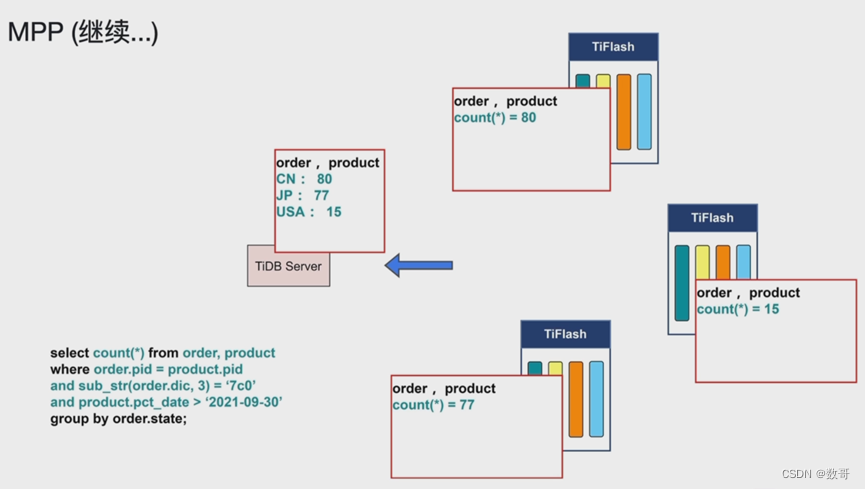
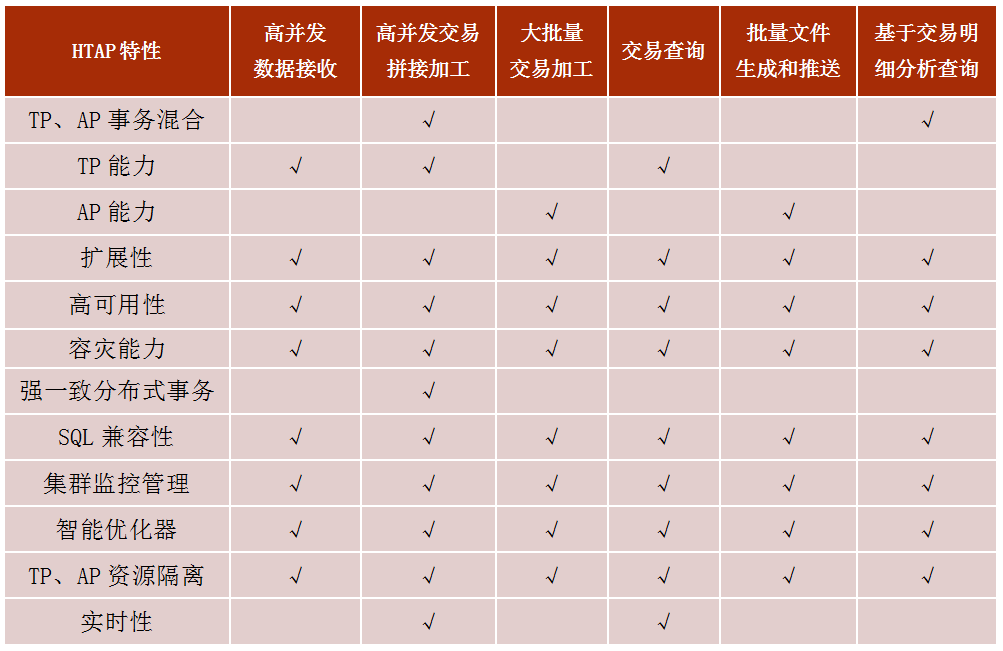
📢📢📢📣📣📣
哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10年DBA工作经验
一位上进心十足的【大数据领域博主】!😜😜😜
中国DBA联盟(ACDU)成员,目前从事DBA及程序编程
擅长主流数据Oracle、MySQL、PG 运维开发,备份恢复,安装迁移,性能优化、故障应急处理等。
✨ 如果有对【数据库】感兴趣的【小可爱】,欢迎关注【IT邦德】💞💞💞
❤️❤️❤️感谢各位大可爱小可爱!❤️❤️❤️
文章目录
- 前言
- 📣 1.集群管理
- ✨1.1 启动与关闭
- ✨1.2 集群状态
- 📣 2.连接到 TiDB
- ✨2.1 MySQL客戶端
- ✨ 2.2 JDBC
- ✨ 2.3 navicat客戶端
- 📣 3.数据库应用
- ✨ 3.1 创建数据库
- ✨3.2 创建表
- ✨3.3 数据写入
- ✨ 3.4 数据查询
前言
快速上手TiDB,体验全新的一栈式实时HTAP数据库📣 1.集群管理
✨1.1 启动与关闭
1.启动集群
集群部署成功后,可以执行以下命令启动该集群
[root@jeames ~]# su - tidb
[tidb@jeames ~]$ tiup cluster start tidb-test2.关闭集群
可以执行以下命令关闭该集群
[root@jeames ~]# su - tidb
[tidb@jeames ~]$ tiup cluster stop tidb-test
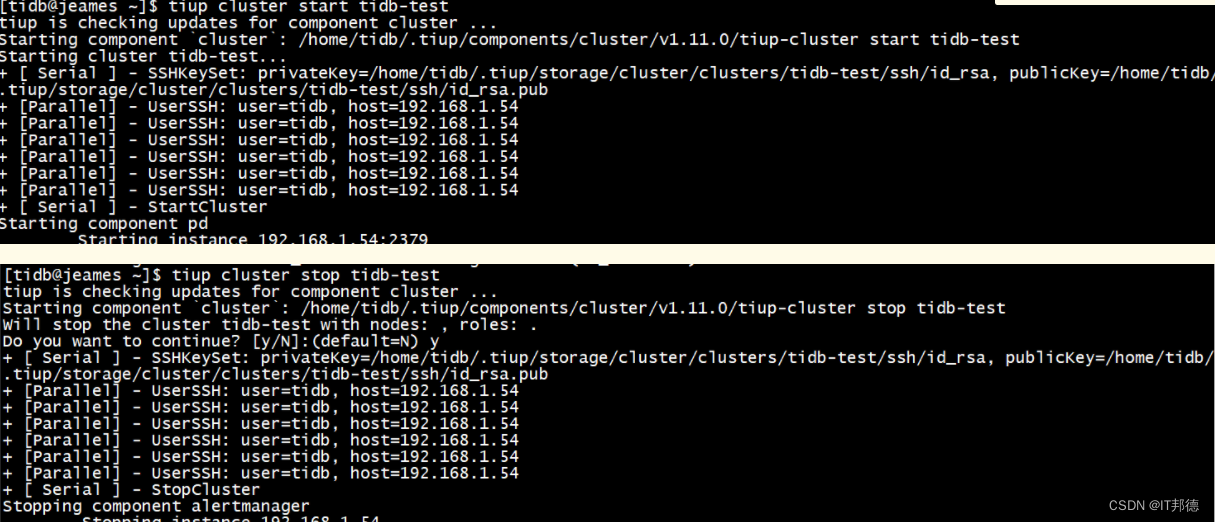
✨1.2 集群状态
1.检查集群状态
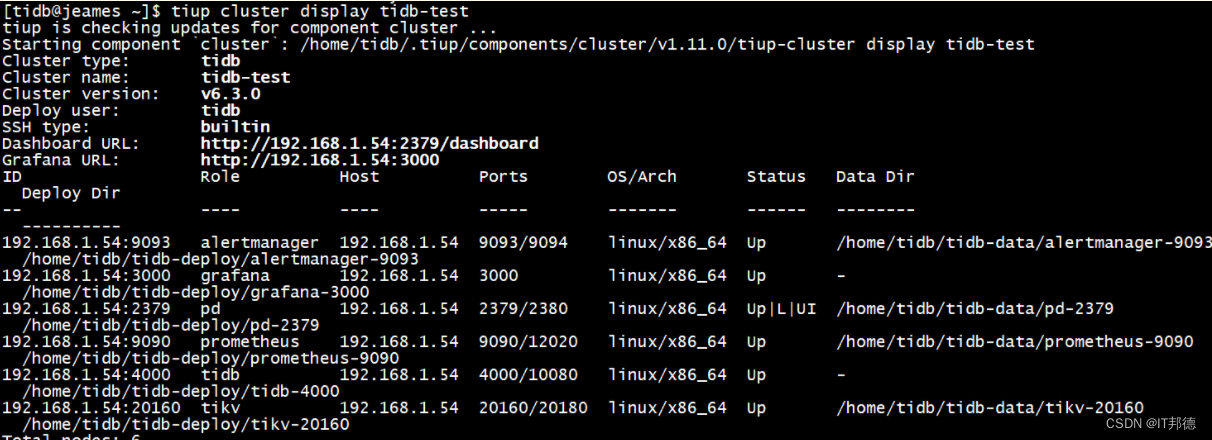
[tidb@jeames ~]$ tiup cluster display tidb-test2.集群部署成功后,可以通过 tiup cluster list 命令在集群列表中查看该集群
[tidb@jeames ~]$ tiup cluster list
tiup is checking updates for component cluster ...
Starting component `cluster`: /home/tidb/.tiup/components/cluster/v1.11.0/tiup-cluster list
Name User Version Path PrivateKey
---- ---- ------- ---- ----------
tidb-test tidb v6.3.0 /home/tidb/.tiup/storage/cluster/clusters/tidb-test /home/tidb/.tiup/storage/cluster/clusters/tidb-test/ssh/id_rsa
📣 2.连接到 TiDB
✨2.1 MySQL客戶端
TiDB 高度兼容 MySQL 协议,全量的客户端连接参数列表,请参阅 MySQL Client Options。
TiDB 支持 MySQL 客户端/服务器协议。这使得大多数客户端驱动程序和 ORM 框架可以像连接到 MySQL 一样地连接到 TiDB。MySQL Client
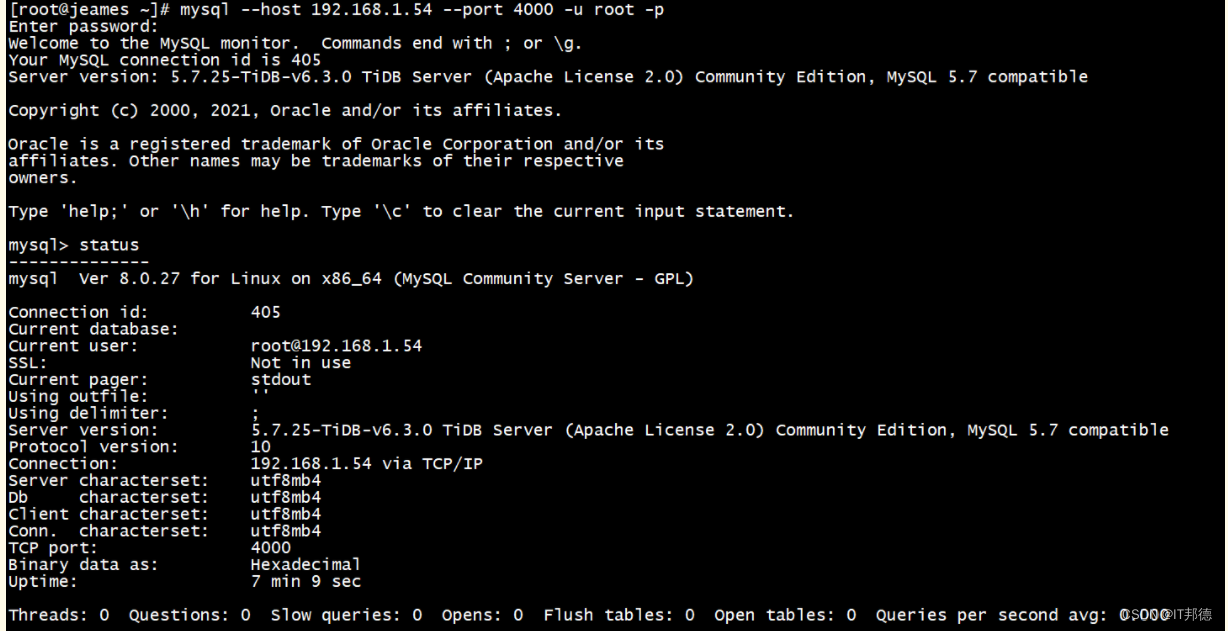
可以使用 MySQL Client 作为 TiDB 的命令行工具,安装完后你可以使用如下命令行连接到 TiDB:
mysql --host <tidb_server_host> --port 4000 -u root -p --comments注意:MySQL 命令行客户端在 5.7.7 版本之前默认清除了 Optimizer Hints。
如果需要在这些早期版本的客户端中使用 Hint 语法,需要在启动客户端时加上 --comments 选项[root@jeames ~]# mysql --host 192.168.1.54 --port 4000 -u root -p
注:The new password is: ‘Z2h^q6tBV7058bn&=%’
✨ 2.2 JDBC
使用 JDBC 驱动连接到 TiDB,这需要创建一个 MysqlDataSource 或 MysqlConnectionPoolDataSource 对象(它们都实现了 DataSource 接口),
并使用 setURL 函数设置连接字符串MysqlDataSource mysqlDataSource = new MysqlDataSource();
mysqlDataSource.setURL("jdbc:mysql://{host}:{port}/{database}?user={username}&password={password}");有关 JDBC 连接的更多信息,可参考 JDBC 官方文档
https://dev.mysql.com/doc/connector-j/8.0/en/连接参数如下:参数名 描述
{username} 需要连接到 TiDB 集群的 SQL 用户
{password} 需要连接到 TiDB 集群的 SQL 用户的密码
{host} TiDB 节点运行的 Host
{port} TiDB 节点正在监听的端口
{database} (已经存在的)数据库的名称
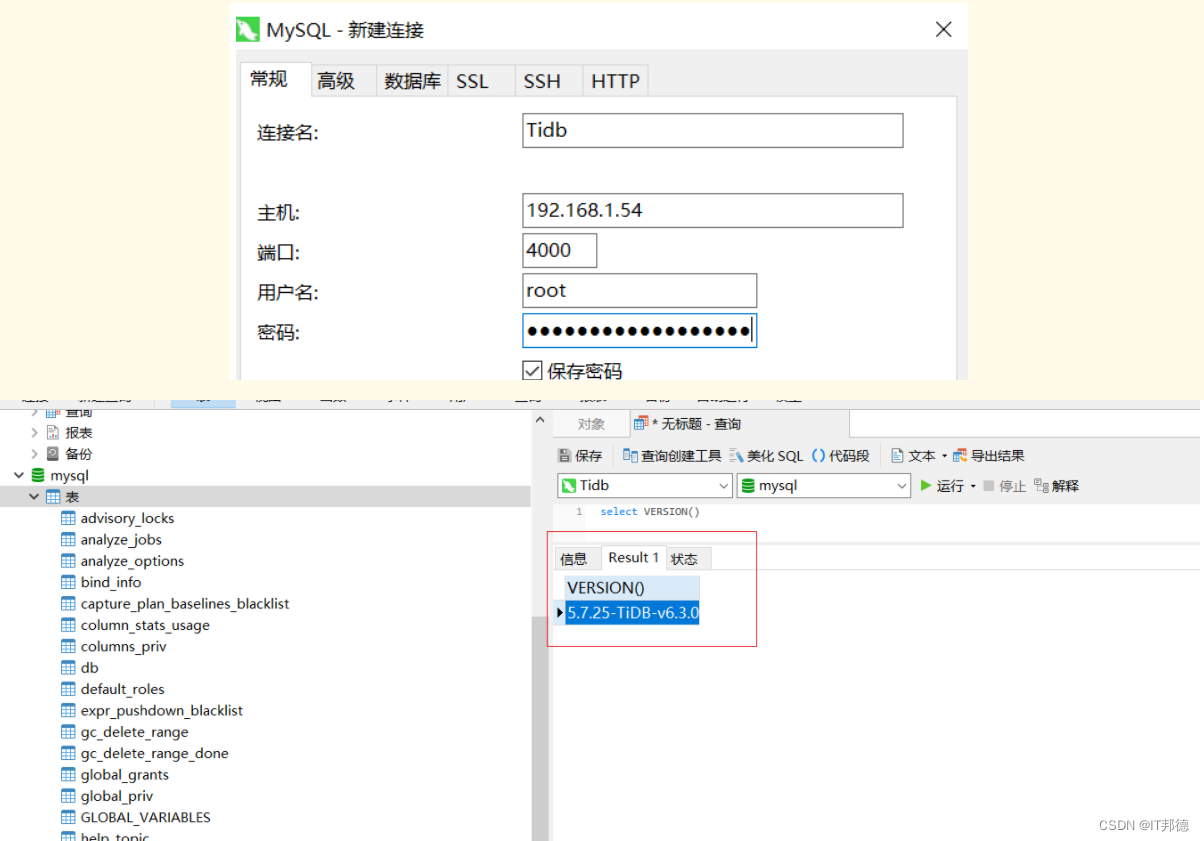
✨ 2.3 navicat客戶端
因为TiDB内核是MySQL,所以直接用Navicat工具选择连接MySQL就行:
使用Navicat登录进去后,可以看到目前最新版本的TiDB的MySQL内核是:5.7.25
📣 3.数据库应用
✨ 3.1 创建数据库
在 TiDB 中数据库对象可以包含表、视图、序列等对象1.创建数据库
使用 CREATE DATABASE 语句来创建数据库:
mysql> CREATE DATABASE IF NOT EXISTS `jeames`;
Query OK, 0 rows affected (0.23 sec)2.要查看集群中的数据库,可在命令行执行一条 SHOW DATABASES 语句
mysql> SHOW DATABASES-> ;
+--------------------+
| Database |
+--------------------+
| INFORMATION_SCHEMA |
| METRICS_SCHEMA |
| PERFORMANCE_SCHEMA |
| jeames |
| mysql |
| test |
+--------------------+
6 rows in set (0.00 sec)注意:test 数据库是 TiDB 提供的一个默认数据库。如果没有必要,尽量不要在生产环境使用它。你可以自行使用 CREATE DATABASE 语句来创建数据库
✨3.2 创建表
表是集Tidb群中的一种逻辑对象,它从属于数据库,用于保存从 SQL 中发送的数据。表以行和列的形式组织数据记录,一张表至少有一列。
若在表中定义了 n 个列,那么每一行数据都将拥有与这 n 个列中完全一致的字段.1.CREATE TABLE 语句通常采用以下形式:
CREATE TABLE {table_name} ( {elements} );{table_name}: 表名。
{elements}: 以逗号分隔的表元素列表,比如列定义,主键定义等2.定义列
列从属于表,每张表都至少有一列,列定义通常使用以下形式:
{column_name} {data_type} {column_qualification}参数描述
{column_name}: 列名。
{data_type}: 列的数据类型。
{column_qualification}: 列的限定条件,如列级约束案例:
mysql> use jeames
Database changedCREATE TABLE `jeames`.`users` (`id` bigint,`nickname` varchar(100),`balance` decimal(15,2)
);3.表中创建主键
主键是一个或一组列,这个由所有主键列组合起来的值是数据行的唯一标识。需遵循选择主键时应遵守的规则,举一个 student 表中定义 AUTO_RANDOM 主键的例子:CREATE TABLE `jeames`.`student` (`id` bigint AUTO_RANDOM,`balance` decimal(15,2),`nickname` varchar(100),PRIMARY KEY (`id`)
);3.列约束
除主键约束外,TiDB 还支持其他的列约束,如:非空约束 NOT NULL、唯一约束 UNIQUE KEY、默认值 DEFAULT 等例如,你需要确保用户的昵称唯一,可以这样改写 student 表的创建 SQL
CREATE TABLE `jeames`.`student` (`id` bigint AUTO_RANDOM,`balance` decimal(15,2),`nickname` varchar(100) UNIQUE,PRIMARY KEY (`id`)
);如果你在 users 表中尝试插入相同的 nickname,将返回错误。
✨3.3 数据写入
1.插入行
假设你需要插入多行数据,那么会有两种插入的办法,假设需要插入 3 个玩家数据:一个多行插入语句
INSERT INTO `player` (`id`, `coins`, `goods`) VALUES (1, 1000, 1), (2, 230, 2), (3, 300, 5);多个单行插入语句
INSERT INTO `player` (`id`, `coins`, `goods`) VALUES (1, 1000, 1);
INSERT INTO `player` (`id`, `coins`, `goods`) VALUES (2, 230, 2);
INSERT INTO `player` (`id`, `coins`, `goods`) VALUES (3, 300, 5);2.更新数据
在 SQL 中,UPDATE 语句一般为以下形式:
UPDATE {table} SET {update_column} = {update_value} WHERE {filter_column} = {filter_value}在 SQL 中更改作者姓名的示例为:
UPDATE `authors` SET `name` = "Helen Haruki" WHERE `id` = 1;3.删除数据
在 SQL 中,DELETE 语句一般为以下形式:
DELETE FROM {table} WHERE {filter}在SQL中,删除数据的示例如下:
DELETE FROM `ratings` WHERE `rated_at` >= "2022-04-15 00:00:00" AND `rated_at` <= "2022-04-15 00:15:00";
✨ 3.4 数据查询
1.单表查询
在 MySQL Client 等客户端输入并执行如下 SQL 语句:
SELECT id, name FROM authors;在 SQL 中,可以使用 WHERE 子句添加筛选的条件:
SELECT * FROM authors WHERE birth_year = 1998;使用 ORDER BY 语句可以让查询结果按照期望的方式进行排序
SELECT id, name, birth_year
FROM authors
ORDER BY birth_year DESC;希望 TiDB 只返回部分结果,可以使用 LIMIT 语句限制查询结果返回的记录数。
SELECT id, name, birth_year
FROM authors
ORDER BY birth_year DESC
LIMIT 10;你想要关注数据整体的情况,而不是部分数据,你可以通过使用 GROUP BY 语句配合聚合函数
mysql> SELECT birth_year, COUNT(DISTINCT id) AS author_count
FROM authors
GROUP BY birth_year
ORDER BY author_count DESC;+------------+--------------+
| birth_year | author_count |
+------------+--------------+
| 1932 | 317 |
| 1947 | 290 |
| 1939 | 282 |
| 1935 | 289 |
| 1968 | 291 |
| 1962 | 261 |
| 1961 | 283 |
| 1986 | 289 |
| 1994 | 280 |
...
| 1972 | 306 |
+------------+--------------+
71 rows in set (0.00 sec)2.多表连接查询1)内连接 INNER JOIN
内连接的连接结果只返回匹配连接条件的行。2)左外连接 LEFT OUTER JOIN
左外连接会返回左表中的所有数据行,以及右表当中能够匹配连接条件的值,如果在右表当中没有找到能够匹配的行,则使用 NULL 填充。3)右外连接 RIGHT OUTER JOIN
右外连接返回右表中的所有记录,以及左表当中能够匹配连接条件的值,没有匹配的值则使用 NULL 填充。4)交叉连接 CROSS JOIN
当连接条件恒成立时,两表之间的内连接称为交叉连接(又被称为“笛卡尔连接”)。
交叉连接会把左表的每一条记录和右表的所有记录相连接,如果左表的记录数为 m, 右表的记录数为 n,则结果集中会产生 m * n 条记录。3.子查询
子查询是嵌套在另一个查询中的 SQL 表达式,借助子查询,可以在一个查询当中使用另外一个查询的查询结果。例如,想要查找 authors 表当中年龄大于总体平均年龄的作家,可以通过将子查询作为比较操作符的操作数来实现:
SELECT * FROM authors a1 WHERE (IFNULL(a1.death_year, YEAR(NOW())) - a1.birth_year) > (SELECTAVG(IFNULL(a2.death_year, YEAR(NOW())) - a2.birth_year) AS average_ageFROMauthors a2
)