基于高斯贝叶斯分类的C++优化器
摘要:2020华为软件挑战赛如期举行,本次挑战赛分为热身赛、初赛、复赛、总决赛4个部分,其中热身赛结合当前机器学习中分类问题以及鲲鹏服务器性能相关来出题。为了解决该问题,达到算法准确率和程序时间的平衡。本文基于高斯贝叶斯的分类算法思想,用C++程序来编写该算法,并在完成之后进行算法以及程序等层面优化策略。充分利用特征选择以及内存映射等特点。在赛题数据集上取得1.12分的成绩,为热身赛第180名左右(总约800名报名选手)。
目录
基于高斯贝叶斯分类的C++优化器
1 问题介绍
2 算法以及程序优化流程
3 流程详解
3.1 特征选择
3.2 使用什么分类算法
3.3 为什么使用C++?
3.4 如何优化C++程序?
3.4.1 算法层面
3.4.2 代码层面
4 结束语
1 问题介绍
机器学习是金融风控中使用到的核心技术之一。金融风控中,会结合各类特征,进行风险预估(常见的特征如:学历、性别、收入、负债情况、商品购买记录、历史逾期行为、人际社交等)。数据分析工程师会针对上述特征进行特征工程处理,再选用合适的机器学习模型进行数据建模工作。
在“大数据”的时代背景下,保证机器学习算法效果的同时,充分挖掘IT基础设施算力,提升算法计算性能,一方面有利于保护企业现有IT投资,另一方面能让数据分析师以更短的时间完成建模,从而可以选择出来更优化的业务模型。
在本次比赛中,我们准备了已经做好了特征工程处理的数据和对应的样例代码,您需要优化模型提升准确率和性能。
2 算法以及程序优化流程
由问题定义可知这是一个分类问题,华为官方要求在准确率和时间两个指标上来综合计分。为了能够达到两者的均衡。本文问题解决方案如下
问题解决流程
- 特征选择
- 使用高斯贝叶斯分类算法
- 使用C++编写程序
- 优化程序I/O部分,优化并发
3 流程详解
由于本篇为赛题博客,所涉及的知识点大多广而不深,所以在这里依据问题解决流程简单罗列下子问题以及本文解决的方法。
- 特征选择
- 使用什么分类算法?
- 为什么使用C++?
- 如何优化程序?
3.1 特征选择
因为本次热身赛的训练集在8w左右,测试集在2w左右。在分类算法达到一定准确率上如何让程序运行更快是一个亟待解决的问题。而特征选择的必要性体现出来,它可以缩短程序I/O读取数据集训练以及预测时间从而获得更好成绩。特征选择主要有3个派别的方法包括基于过滤的方法,其中有方差检验、相关性检验,这一派别方法通过去掉不符合阙值的特征以及优先选择与目标变量相关性高的特征来筛选特征集合。而基于嵌入的方法派别利用正则化和树模型,通过构建目标函数不断去除那些不太重要的特征。最后基于包裹的方法派别使用现成的分类算法为学习器,每次递归消除那些使得学习器性能提升最小的特征。
在本文中,由于并不知晓训练集多特征对于分类标签的共同影响,而且为了节省时间考虑。本文选择了基于皮尔逊系数的相关性检验方法来过滤特征。两个变量之间的皮尔逊相关系数定义为两个变量之间的协方差和标准差的商,其中协方差反应的是X和Y之间的总体误差,而标准差反应是X和Y各自作为一组数据的离散程度。公式如下
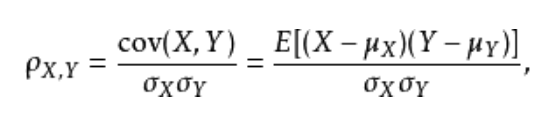
即

在该公式中,P为皮尔森相关系数,X为特征,Y为标签,分子为X和Y的方差。分母是X,Y的标准差乘积。该公式刻画X和Y之间的相关性,该公式能够反应每个特征和对应标签之间的关系,r值绝对值越大,表示X和Y相关性越高。但是这种过滤特征的方法有缺陷,皮尔逊系数是假设两个变量之间是线性相关而进行分析的,r值越大,相关性越高。而在本赛题中,并不知X和Y之间是否有线性关系,仅仅依赖现有条件去筛选特征,该缺陷可以靠画出X和Y的数据变化图来验证。本文不再赘述,暂且使用这种方法。本文使用皮尔逊相关系数方法从训练集中1000个特征中,取200列特征。之所以选择200列,是因为在后续实验中发现200列是保证贝叶斯预测准确率大于70的条件之一。
3.2 使用什么分类算法
在使用sklearn机器学习库来调研已有的分类算法中,本文基于各种分类算法在赛题发放的样例数据集表现,选择高斯贝叶斯分类器。该分类器在样例数据集中取全部特征可以达到约84%的准确率,用时仅为4.88s。关于高斯贝叶斯分类器的内容,本文不再赘述。只给出其分类思想以及前提假设。
假设:
特征分布符合正态分布,且各个特征之间独立。
分类思想公式:
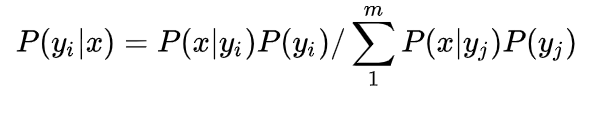
本公式为基本的贝叶斯公式,其中x为特征集合,yi表示标签。而样例数据集只有1和0两个类别。所以在该公式计算过程中,不需要计算分母。只需要计算分子即可。分子由两部分组成,包括P(x|yi)和P(yi),前者可以直接转化为P(x1|yi),P(x2|yi)...P(xn|yi)来计算(因为贝叶斯强烈的假设条件),而P(xi|yi)使用正态分布的概率密度计算即可,后者为训练集中每一种标签对应的先验概率。
3.3 为什么使用C++?
在挑选什么语言来实现贝叶斯算法问题上,目前大赛比较好的选手都是选择C++语言。其相对于其他编程语言的优点在于:
- C++是编译型语言
- C++更底层,程序员直接接触内存等底层资源,从而更快的运行
缺陷在于:
- 学习时间过长,不能关注于模型本身
3.4 如何优化C++程序?
3.4.1 算法层面
在算法层面,本文所做的是特征选择
3.4.2 代码层面
1.数据截取
在实验过程中,发现仅需要200列特征,1/10训练集即可在测试集上达到70准确率。
2. I/O的优化
在I/O层面,本文使用mmap内存映射机制。该机制过程如下
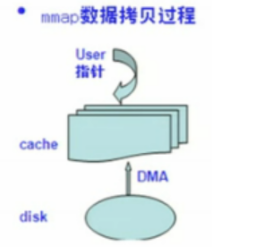
mmap通过将硬盘中的文件一部分内容映射到用户空间上,那么用户获取该空间指针就可以直接向内核缓存区读写这部分内容,相对于Fread读取方法,mmap没有硬盘拷贝到用户空间的过程,自然更快。本文首先获取需要读取训练集和测试集文件大小,再依据文件大小映射出整个文件到用户空间上,取文件映射头指针一个一个读取200列数据。
3 .并行优化
在并行层面,分别读取两个文件的操作很明显是可以并行的。数据隔离满足线程安全,本文采用两个线程分别读取数据到vector中。
4.代码优化
代码优化层面主要是语言特性以及计算机底层方面知识,本文在网络资源的帮助下,就以下几点做出改进
- 参数尽可能使用引用传递
- 不使用字符串的加法来转换字符串成数字,而是一个字符一个字符转成对应数字
- 预先分配二维数组空间存放训练数据,而不是使用vector
- 局部性原理
4 结束语
本文基于高斯贝叶斯分类器,结合特征选择,以及优化程序等流程,在大赛取得一定成绩,但仍有较大进步空间。分为以下几个方面阐述:
- 特征选择的理论解释,本文并未就特征选择方面提出可以让人信服的证明过程,所选择的200列仅仅是达到了一定准确率而已。
- 本文就贝叶斯计算过程没有采用neno技术来实现数据并行
- 没有针对现有方法提出改进,只是做了子问题的调研工作以及一些模糊的直觉来选择较好的方法,创新性低
- 在多线程方面,生产者-消费者模型可以使用。比如一个线程读取测试文件,一个线程消费所读取的数据。这样可以更快,而不是串行处理
5 拓展问题
本部分是笔者自己打比赛自己问自己的问题,可读可不读
问题的细致定义:
(C++性能优化代码+选择合适的算法(准确率和时间)+特征工程+服务器特性)4个方面的知识点 问题很简单,简单二分类问题,数据集为几w行1000列。但是要准确率以及够快。
- 1 学习特征工程,以及自己为什么选择这种特征?是单纯看出来的,还是经过实验所得?
- 2 读文件的优化?fread是怎么读的?怎么优化的?为什么更快?为什么不用mmap,那什么是mmap?可不可针对这两种方法优化? 3 为什么用朴素贝叶斯? 还有其他更快的分类算法吗?朴素贝叶斯的公式推演以及似然度的选择计算?
- 4 既然为了加速,那肯定有并行算法,在什么地方用了并行算法?为什么用这种并行算法?
- 5 为什么用neno加速,它是什么?为什么可以加速?
- 6 为什么选择C++,而不是Python或者java?
- 7 怎么对C++程序做性能优化?步骤?
- 8 针对某一问题的性能优化有没有理论最优值?
- 9 有无做出了解底层原理的方法或者创新操作。
- 10 积累了那些对于语言共同特性的优化?
- 11 看了那些书,包括C++性能优化指南,代码大全,编译原理等等。
- 12 为了编写合乎编译器和计算机底层(性能性)和可读性,维护性高,你知道了什么?
- * 从代码的编译过程来看,比如int a=-5;编译器如何解析它成为汇编? * 计算机时如何做的运算b-5的,涉及到原码,反码,补码等等。组成原理 * 代码大全为了可读性和维护性, * 语言本身特性。
- 13 当我编写一个hello world的时候,计算机里面发生了什么?