文章目录
- 2022华为软挑(初赛笔记)
- 1. 赛题要求
- 2. 解决方案
- 2.1 挑选适合的边缘节点
- 2.2 第一轮:最大分配
- 2.3 第二轮:均值分配
- 总结
本文仓库地址:
Github-CodeCraft-2022
2022华为软挑(初赛笔记)
1. 赛题要求
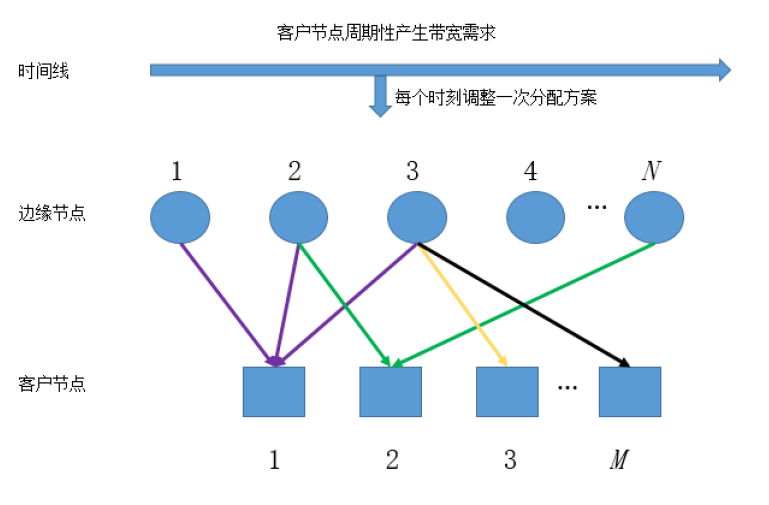
任务核心:解决流量的调度问题,以最优分配满足客户的流量请求
- 共有M个客户节点和N个边缘节点。
- 在每个时刻,要决策如何把每个客户节点的带宽需求分配到边缘节点。
- 为了确保调度质量,每个客户节点的需求只能分配到满足QoS约束的边缘节点上。即:当客户节点和边缘节点之间的QoS小于“QoS上限”时,才会进行流量分配。
- 在每个时刻,每个边缘节点接收的带宽需求总和不能超过其带宽上限。
- 合理分配所有时刻的客户节点带宽需求,使得最终的带宽总成本尽量小。
计分标准:所有使用的边缘服务器95百分位流量值总和
优化目标:找到一组满足约束的流量分配方案 𝑋 使其在时间集合 𝑇 内的总带宽成本尽可能小 。
2. 解决方案
题目的核心是使得各边缘服务器95百分位流量值求和最小。首先要选择所有满足QoS上限的边缘服务器,然后核心目的使得计分位以上的点时刻该边缘节点流量跑分尽可能满,计分点以下的时刻应该尽可能均且靠近95百分位点。考虑无论是从纵向时间分配的角度,还是横向各用户需求分配的角度,都突出“削峰”思想,避免出现带宽分配集中的情况,使得分配尽量平均。
2.1 挑选适合的边缘节点
解题的第一步是要找出各个用户满足QoS限制的合适的边缘服务节点,按照各点QoS计算出用户的对应边缘节点表,并加以记录。代码如下:
# 计算有效用户节点
def find_useful_server():# 挑选出满足每个客户带宽需求的边缘节点def limit_server_qos(axis_input):index_temp = np.where(qos[:, axis_input] < qos_constraint)qos_temp = np.array((index_temp[0], qos[index_temp][:, axis_input])).Tqos_temp = qos_temp[np.argsort(qos_temp[:, 1], axis=0)]return qos_temp# 每个用户满足的节点列表# 每个用户满足的节点数量排序_client_limit_res, _client_limit_num_sequence, _client_limit_band_sequence = [], [], []for i in range(len(demand[0])):_server_res = limit_server_qos(i)_client_limit_res.append(_server_res)_client_limit_num_sequence.append(len(_server_res))_client_limit_band_sequence.append(sum([int(apply[qos_keys[x]][0]) for x in _server_res[:, 0]]))# 所有可用边缘节点集合_server_all = []# 构建所有可用边缘节点列表for x in _client_limit_res:_server_all += list(x[:, 0])_server_set = set(_server_all)# 每个客户所有满足的边缘节点的列表# 增加排序,(由于边缘节点时延目前无需考虑,直接按照序号排列),保证满足边缘节点搜索优先度_server_list = [sorted(list(_client_limit_res[i][:, 0])) for i in range(len(_client_limit_num_sequence))]# 每个客户拥有的满足边缘节点升序排序,首要排序指标数量,次要排序指标可提供带宽_server_num_sequence = np.argsort(np.array((_client_limit_num_sequence, _client_limit_band_sequence)).T, axis=0)# _server_num_sequence = [j[0] if j[0]==j[1] else j[1] for j in _server_num_sequence]_server_num_sequence = [j[0] for j in _server_num_sequence]# 排除完全没有边缘可以满足的用户while not len(_server_list[_server_num_sequence[0]]):_server_num_sequence = np.delete(_server_num_sequence, 0)# 对客户表进行排序temp_dict = {j: i for i, j in enumerate(_server_num_sequence)}_client_list = {j: [] for j in _server_set}for client, s_list in enumerate(_server_list):for s in s_list:_client_list[s].append(client)for k, cc in zip(_client_list.keys(), _client_list.values()):x = np.array([[c, temp_dict[c]] for c in cc])x = x[np.argsort(x[:, 1])][:, 0]_client_list[k] = x.tolist()# 对边缘节点按照可以被使用用户数量调整排序temp = []_client_num_sequence = []for y in _client_list.values():temp.append(len(y))temp_list = list(_server_set)for i, j in enumerate(np.argsort(temp)):_client_num_sequence.append(temp_list[j])_server_set = _client_num_sequencereturn _server_list, _server_num_sequence, _server_set, _client_list
2.2 第一轮:最大分配
刚开始使用的策略是一轮即完成分配。在一轮里按时刻遍历,先找到时刻内还有前5%值的边缘,再依次找边缘拥有的请求用户,将需求分配到该边缘,直到边缘满了或者用户需求解决。然后所有剩下的用户需求再均分。
但这种思路没有很好的解决最大需求的完美分配问题。因为各个边缘节点供给的用户最大需求来临时刻不一样,如果直接按照时间顺序会造成很多百分之五节点的浪费。经过考虑,我们决定针对总需求进行排序然后送入的方式解决这个问题。虽然最终的确可以在一定程度上解决问题,但依然存在一部分百分之五的点无法完全分配的问题。结果如图:
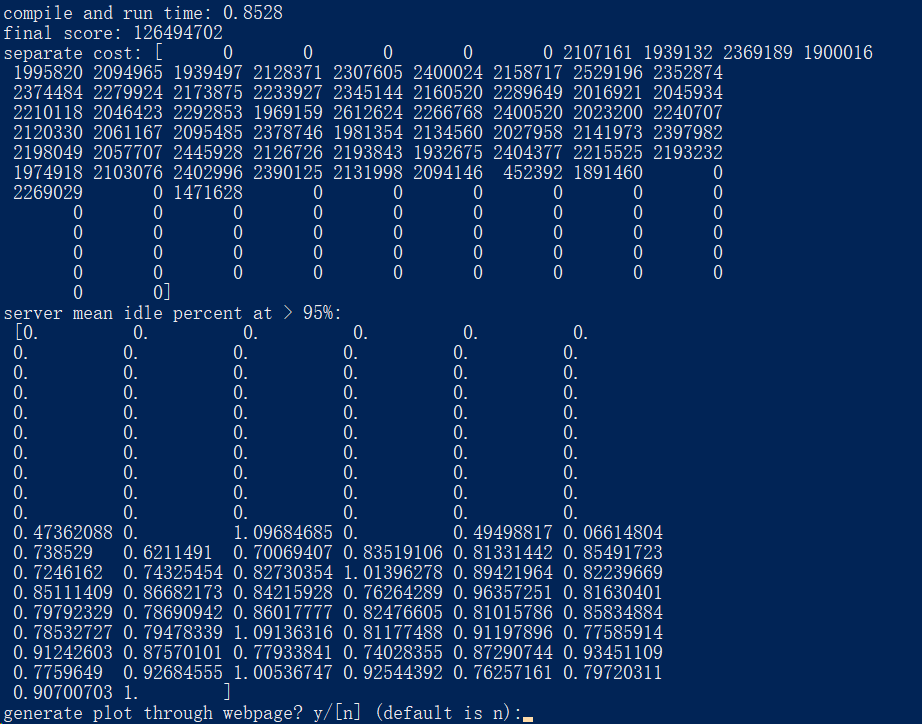
最终,通过交流,我们明白了问题的原因:由于各个用户峰值来临时刻的不同,且这种不同很难通过整体流量的变化进行判断。所以应该对流量的分配进行调整,从各个边缘节点出发,让其挑选出其所属用户流量最高的1个时刻,然后进行分配。待到分配完成之后,再继续从下一个边缘节点出发,对其覆盖用户目前流量继续排序。直到五轮迭代,满足所有的边缘节点。这样的操作方法可以尽可能跑满边缘的用户流量,使其达到最大。
最终改进的代码如下:
for roll_time in range(demand_limit):for server_index in server_set:client_index_list = client_wait_pool_max[server_index]# user_demand_list 表示用户的需求数组, 第1列表示排序后的需求次序映射到原始次序的顺序, 第二列往后表示该边缘拥有的各用户按顺序的需求量user_demand_list = np.array([demand[:, index] for index in client_index_list]).Tuser_demand_list_sum = np.sum(user_demand_list, axis=1)user_sort_sequence = np.argsort(np.sum(user_demand_list, axis=0))user_demand_list = np.c_[np.arange(len(user_demand_list)), user_demand_list_sum, user_demand_list]user_demand_list = user_demand_list[np.argsort(user_demand_list[:,1], axis=0)[::-1]]for i, u_demand in enumerate(user_demand_list):if u_demand[0] not in record_time[server_index]:user_demand_list = user_demand_list[i]breakuser_demand = np.delete(user_demand_list, 1)time = user_demand[0]record_time[server_index].append(user_demand[0])# 单个时间用户的需求user_list_temp = {}server_bandwidth = int(apply[qos_keys[server_index]][0])# 遍历各个用户for index, user in enumerate(client_index_list):# query: 该用户的请求query = user_demand[index + 1]# 如果这个用户的需求超过了当前服务器闲置带宽if query >= server_bandwidth:# 分配所有闲置带宽total_res[user_demand[0]][user].append([server_index, server_bandwidth])# 如果user_list_temp有东西,说明不是一个节点填满的,写进去for u, q in zip(user_list_temp.keys(), user_list_temp.values()):# 保存分配total_res[user_demand[0]][u].append([server_index, q])# 用户请求量更新demand[user_demand[0], u] = 0# 用户请求量更新demand[user_demand[0], user] -= server_bandwidth# 边缘服务量更新server_bandwidth = 0breakelse:# 服务器待分配带宽更新server_bandwidth -= query# 用户记录队列保存user_list_temp.update({user: query})if server_bandwidth != 0:for u, q in zip(user_list_temp.keys(), user_list_temp.values()):# 保存分配total_res[user_demand[0]][u].append([server_index, q])# 用户请求量更新demand[user_demand[0], u] = 0# 使用过的时间记数max_used_time[time] += 12.3 第二轮:均值分配
第一轮动态分配完成之后,第二轮对于剩下的各个时刻总流量来说,已经是削峰过后的结果。考虑对剩下的待分配流量,使用可以使用的边缘结点进行动态均分。
我们尝试使用了很多办法,最终选择了基于动态分配以及最大上限的平均算法:
首先,按照总请求量从小到大进行排列,按照排序时间序列进行处理。
然后,按照可用边缘节点数量对用户进行排序,按照升序顺序逐个处理用户剩余请求。
再者,对于每个用户的请求,分为两种情况:
- 若该边缘节点未发生过排序,按照动态平均的思想,将动态分配期望作为所属节点的带宽期望,最终追求各个节点分配量的平均。
- 若该边缘节点在平均轮已经有某个时间产生过流量服务,剩下的时间以不超过前面轮次该节点产生流量的最大值作为初始期望。
最终实现的代码如下:
# 开始进行匹配
for num, demand_index in enumerate(demand_sequence):# 从时间序列上按用户需求总量降序匹配client_query_bandwidth = demand[demand_index]# 等待分配用户节点池client_wait_pool = list(server_num_sequence)# 等待分配边缘节点池server_wait_pool = server_wait_pool_max.copy()# # 单次分配结果字典# single_res = {i: [] for i in range(len(client_wait_pool))}# 全局边缘节点带宽大小server_bandwidth = {node: int(apply[qos_keys[node]][0]) for node in server_set}# 从用户角度迭代,满足用户未满足的需求# 挑选出此时刻不允许使用的边缘节点(已经被最大分配)server_useless = []for user_index, res_list in zip(total_res[demand_index].keys(), total_res[demand_index].values()):for server_list2 in res_list:server_useless.append(server_list2[0])for client in client_wait_pool:# 除了不能用的,剩下的加入列表use_server_index_list = []for s in server_list[client]:if s not in server_useless:use_server_index_list.append(s)# print(use_server_index_list)# print(use_server_index_list)query = client_query_bandwidth[client]server_temp = use_server_index_list.copy()# 迭代满足需求while query != 0:# # 计算均值策略可用各边缘节点使用率# use_rate = {node: (int(apply[qos_keys[node]][0]) - server_bandwidth[node]) / int(apply[qos_keys[node]][0])# for node in use_server_index_list}# # 按照最大使用率差值计算各节点富余分配量# deliver_dict = {node: int((max(use_rate.values()) - use_rate[node]) * int(apply[qos_keys[node]][0]))# for node in use_server_index_list}deliver_dict = {}for node in use_server_index_list:if server_max_avg[node]:deliver_dict.update({node: server_max_avg[node]})else:# 计算均值策略可用各边缘节点使用率use_rate = {node: (int(apply[qos_keys[node]][0]) - server_bandwidth[node]) / int(apply[qos_keys[node]][0])for node in use_server_index_list}# 按照最大使用率差值计算各节点富余分配量deliver_dict = {node: int((max(use_rate.values()) - use_rate[node]) * int(apply[qos_keys[node]][0]))for node in use_server_index_list}# 如果请求超过了当前动态分配的结果if query >= sum(deliver_dict.values()):res_query = query - sum(deliver_dict.values())# 平均分担当前待分配带宽mean_deliver = res_query // len(use_server_index_list)left_deliver = res_query % len(use_server_index_list)for node in use_server_index_list:deliver_dict[node] += mean_deliver# 如果请求不超过当前动态分配的结果else:temp = sum(deliver_dict.values())for node in use_server_index_list:deliver_dict[node] = int(query * (deliver_dict[node] / temp))left_deliver = query - sum(deliver_dict.values())# print(deliver_dict)# print(sum(deliver_dict.values()), query-sum(deliver_dict.values())-left_deliver)tempp = []for i in use_server_index_list:tempp.append(server_bandwidth[i])tempp = np.c_[use_server_index_list, tempp]tempp = tempp[np.argsort(tempp[:,1])][:,0][::-1]for use_server_index in tempp:free = server_bandwidth[use_server_index]if left_deliver > 0:need = deliver_dict[use_server_index] + left_deliverleft_deliver = 0else:need = deliver_dict[use_server_index]# # 如果待分配带宽为0# if free == 0:# continue# 如果分配请求超过该节点可提供带宽上限if need > free:# 存储单个分配节点信息total_res[demand_index][client].append([use_server_index, free])# 请求总量减小query -= free# 均值策略该节点待分配量归0server_bandwidth[use_server_index] = 0use_server_index_list.remove(use_server_index)else:# 分配量为均值total_res[demand_index][client].append([use_server_index, need])# 请求总量减小query -= need# 均值策略该节点待分配量减小server_bandwidth[use_server_index] -= need# print(server_bandwidth)for index, value in zip(server_bandwidth.keys(), server_bandwidth.values()):if index in server_temp:server_max_avg[index] = max(server_max_avg[index], int(apply[qos_keys[index]][0]) - value)总结
我们参赛历时大概十天,对处理的方法也经过不断的讨论调整。虽然最终的代码依然还有很大的改进空间,例如最大轮的分配不以简单吃完用户需求为策略,而是追求去均匀吃下用户的需求;最大轮里边缘的使用时间不要过于集中,避免“过削峰”;平均策略里应该尝试进行多次分配寻找最佳均值等。
但是,作为第一次参加的算法比赛,还是有很大的收获的。认识到理论的想法到实际的工程化实现之间依然有很远的距离,想要实现idea不是那么容易的。吸取教训,希望下次能够有更好的成绩!