1.理论基础
将普通的卷积过程推广到非规则数据领域一般是通过邻域聚合或者信息传递机制。 x i ( k − 1 ) ∈ R F x^{(k-1)}_i∈R^F xi(k−1)∈RF表示在第k-1层节点i的节点特征, e j , i ∈ R D e_{j,i}∈R^D ej,i∈RD表示从节点j到节点i的边的特征(可选参数),那么图神经网络中的信息传递机制就可以表示为:
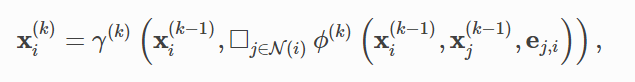
其中□ 表示一种可微的、置换不变的函数(也就是后面的聚合模式),比如求和、取均值或者最大值, γ \gamma γ和 ϕ \phi ϕ均为可微的函数,比如MLP多层感知机。上述公式相当于就是把一个节点的邻域节点的特征聚合到当前节点上面,最外层的 γ \gamma γ函数就类似于我们常见的非线性激活函数,聚合的信息分为两部分,第一部分是上一层中该节点自身的特征信息,第二部分是上一层中,该节点和邻域节点边上的传递信息。
2.“信息传递”基类
Pytorch-Geometric中提供了一个基类torch_geometric.nn.MessagePassing,它自身已经实现了信息传递机制来更有效的创建信息传递机制的图神经网络,只要将其作为一个基类继承创建自己的类即可。使用的时候只需要定义函数 ϕ \phi ϕ
比如message(),和函数 γ \gamma γ比如update();同时需要指定聚合方式比如aggr='add',aggr='mean'或者aggr='max'。在这个基类中比较重要的几个地方如下:
(1)torch_geometric.nn.MessagePassing(aggr="add", flow="source_to_target")
定义三种聚合模式中的一种以及信息传递的方向,默认是从源节点到目标节点,比如一个有向边1->2,源节点是1,目标节点是2。
(2)torch_geometric.nn.MessagePassing.propagate(edge_index, size=None, dim=0, **kwargs)
调用该函数会进行信息的传播计算过程,参数为边的数据以及其他在构建信息传递过程和更新节点嵌入向量的数据参数(这里的额外的数据参数并不会在这该函数用到,而是传递到之后的函数中)。值得注意的是该方法不仅限于shape=[N, N]的邻接矩阵,也可以用于一些稀疏化的矩阵,对于稀疏化矩阵如果创建完整的邻接矩阵对于空间浪费比较大,所以只会存储其中非0元素(存储该元素的行坐标和列坐标),比如二分图;对于矩阵格式shape=[N, M]需要传递参数size=(N, M),如果该参数为None,就会默认为是规则的邻接矩阵。对于二分图而言,含有两个独立的节点索引,所以传递参数的方式可以类似于x=(x_N, x_M)的形式。
(3)torch_geometric.nn.MessagePassing.message()
对到达节点i的信息进行构建,相当于函数 ϕ \phi ϕ,也就是计算出所有邻居节点的应该传递过来的信息量为多少;根据信息传递方向的不同(详见(1)中的参数flow),节点对的选取方式也不同。值得注意的是,该函数所需的参数是来自于最初传递给propagate()函数的参数中的任何参数,换句话说,你要想在message中使用图的某些属性参数,必须在propagate()中先传递。另外,传递给propagate()的tensor会通过增加_i和_j的方式来创建新的变量名,该变量作为tensor分别映射到节点i和节点j的值。
(4)torch_geometric.nn.MessagePassing.update()
将聚合函数后的结果作为输入计算出更新值。接受聚合过程的输出结果作为第一个参数,和其他任意之前传递给propagate()的参数。
3.GCN层的实现
从数学角度看,GCN层即:
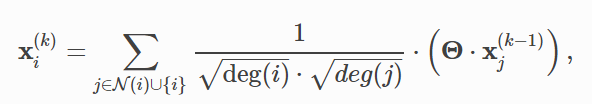
邻居节点的特征首先通过一个权重矩阵的转换,然后通过它们的度进行标准化,最后进行求和。具体步骤如下:
1.在邻接矩阵中增加自环
2.对节点特征进行一次线性转化(利用linear层实现)
3.计算标准化系数
4.对节点特征进行标准化(函数 ϕ \phi ϕ)
5.对相邻节点特征进行求和("add"聚合方式)
6.得到新的节点嵌入
import torch
from torch_geometric.nn import MessagePassing
from torch_geometric.utils import add_self_loops, degree
from torch_geometric.datasets import TUDatasetclass GCNConv(MessagePassing):def __init__(self, in_channels, out_channels):super(GCNConv, self).__init__(aggr='add')self.lin = torch.nn.Linear(in_channels, out_channels)def forward(self, x, edge_index):# X: [N, in_channels]# edge_index: [2, E]# 1.在邻接矩阵中增加自环edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0))# 2.对节点特征进行一个非线性转换# x的维度会由[N, in_channels]转换为[N, out_channels]x = self.lin(x)# 3.计算标准化系数# edge_index的第一个向量作为行坐标,第二个向量作为列坐标row, col = edge_indexdeg = degree(row, x.size(0), dtype=x.dtype)deg_inv_sqrt = deg.pow(-1/2)# norm的第一个元素就是edge_index中的第一列(第一条边)上的标准化系数# tensor的乘法为对应元素乘法,tensor1[tensor2]后的维度与tensor2一致norm = deg_inv_sqrt[row] * deg_inv_sqrt[col]# 4-6步的开始标志,内部实现了message-AGGREGATE-updatereturn self.propagate(edge_index, size=(x.size(0), x.size(1)), x=x, norm=norm)def message(self, x_j, norm):# x_j的维度为[E, out_channels]# 4.进行传递消息的构造,将标准化系数乘以邻域节点的特征信息得到传递信息return norm.view(-1, 1) * x_jdef update(self, aggr_out):# aggr_out的维度为[N, out_channels]# 6.更新新的节点嵌入,这里没有做任何多余的映射过程return aggr_out# 实例化对象
conv = GCNConv(16, 32)
# 默认为调用对象的forward函数
x = conv(x, edge_index)
对于上面的代码,GCNConv全部的计算流程都在forward()函数中,在该函数中,前三步是明确计算出来,但是第4-6步是隐含在propagate()函数中进行调用,propagate()函数会调用重载后message()函数和update()函数,并且自身实现了聚合过程。下面测试一下x_j的取值:
(1)取消linear过程
(2)在message函数中输出x_j
初始化信息为:
# 构建数据
edge_index = torch.tensor([[0, 1, 1, 2],[1, 0, 2, 1]
], dtype=torch.long)
x = torch.tensor([[0, 0, 0],[1, 1, 1],[2, 2, 2]
], dtype=torch.float)
输出的x_j为:
tensor([[0., 0., 0.],[1., 1., 1.],[1., 1., 1.],[2., 2., 2.],[0., 0., 0.],[1., 1., 1.],[2., 2., 2.]])
所以x_j对应的节点序列为[0,1,1,2,0,1,2],而egde_index增加自环之后,是:
tensor([[0, 1, 1, 2, 0, 1, 2],[1, 0, 2, 1, 0, 1, 2]])
所以x_j对应第一行节点的特征信息。
【注】后面将会对PyG自带的例子进行分析以及相关API。
![[易飞]录入信息传递设置信息](https://img-blog.csdnimg.cn/2022010623523218517.png)