本发明涉及语音识别领域,具体涉及一种在线语音识别引擎及识别方法。
背景技术:
深度学习网络(Deep-Learning Neural Network,DNN)技术的发展,带来了语音识别领域的飞速发展。目前实际应用场景中语音识别的准确性,取决于DNN训练数据与真实数据特征的一致性,为了训练得到具有普适应用效果的在线识别引擎,需要获取具有广泛数据特征的海量标注数据。
为了增强语音识别系统的扩展性,普通的DNN语音识别引擎需要海量的标注数据,由于数据的庞大,要求网络层级复杂,导致所得到的声学模型和语音模型都很巨大,因此计算量会随着网络规模的增长而呈指数级增长,这导致普通的DNN语音识别系统随着用户语音特征的复杂化,无法有效控制自身对数据的增长需求以及对硬件设备计算能力的增长需求。由于无法控制自身规模,导致普通的DNN语音识别系统无法以极小代价做设备、系统间的移植,进而极大地限制了自身的应用适应范围。
技术实现要素:
鉴于上述技术问题,为了克服上述现有技术的不足,本发明提出了在线语音识别引擎及识别方法。
根据本发明的一个方面,提供了一种在线语音识别引擎包括:至少一个DNN网络,每一DNN网络基于与其对应的局部特征一致的经标注的语音数据来进行学习训练;以及RNN信息融合网络,用于接收需要识别的新语音数据和各个DNN语音识别子系统基于需要识别的新语音数据的输出,并不断提高RNN信息融合网络自身融合能力。
在一些实施例中,在线语音识别引擎还包括:语音识别评价模块,其基于所述DNN网络或所述DNN网络和RNN信息融合网络的语音识别输出给出评测结果。
在一些实施例中,在线语音识别引擎还包括:云端服务器,用于存储与每一DNN网络对应的局部特征一致的经标注的语音数据及采集到的需要识别的新语音数据。
在一些实施例中,所述云端服务器基于所述评测结果来决定RNN信息融合网络是否工作。
在一些实施例中,当DNN网络中的至少一个效能下降时,RNN信息融合网络开启工作。
根据本发明的另一个方面,提供了一种在线语音识别方法包括:至少一个DNN网络接收需要识别的新语音数据进行语音数据识别;判断至少一个DNN网络的效能是否下降;若是,则启动RNN信息融合网络,接收需要识别的新语音数据和各个DNN语音识别子系统基于需要识别的新语音数据的输出,并不断提高RNN信息融合网络自身融合能力;以及一个DNN网络或者和RNN信息融合网络共同实现语音数据识别。
在一些实施例中,在采用与其对应的局部特征一致的经标注的语音数据来对至少一个DNN网络进行学习训练之前好包括:采用与其对应的局部特征一致的经标注的语音数据来对至少一个DNN网络进行学习训练。
在一些实施例中,判断至少一个DNN网络的效能是否下降取决于由语音识别评价模块基于所述DNN网络和RNN信息融合网络的语音识别输出给出评测结果。
从上述技术方案可以看出,本发明具有以下有益效果:
利用至少一个DNN网络进行语音识别并结合RNN信息融合网络进行信息融合,增强在线语音识别引擎的扩展性和稳定性;
基于语音识别输出的评测结果绝定是都开启RNN信息融合网络,能够灵活进行在线语音识别引擎不同工作模式的切换,降低不必要开销,增强在线语音识别引擎整体效能。
附图说明
图1为本发明一实施例中在线语音识别引擎的结构框图;
图2为本发明另一实施例在线语音识别方法的流程图。
具体实施方式
本发明某些实施例于后方将参照所附附图做更全面性地描述,其中一些但并非全部的实施例将被示出。实际上,本发明的各种实施例可以许多不同形式实现,而不应被解释为限于此数所阐述的实施例;相对地,提供这些实施例使得本发明满足适用的法律要求。
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明进一步详细说明。
本发明一实施例提供一种在线语音识别引擎,包括:至少一个DNN网络和RNN信息融合网络,每一DNN网络基于与其对应的局部特征一致的经标注的语音数据来进行学习训练;RNN信息融合网络用于接收需要识别的新语音数据和各个DNN语音识别子系统基于需要识别的新语音数据的输出,并不断提高RNN信息融合网络自身融合能力。
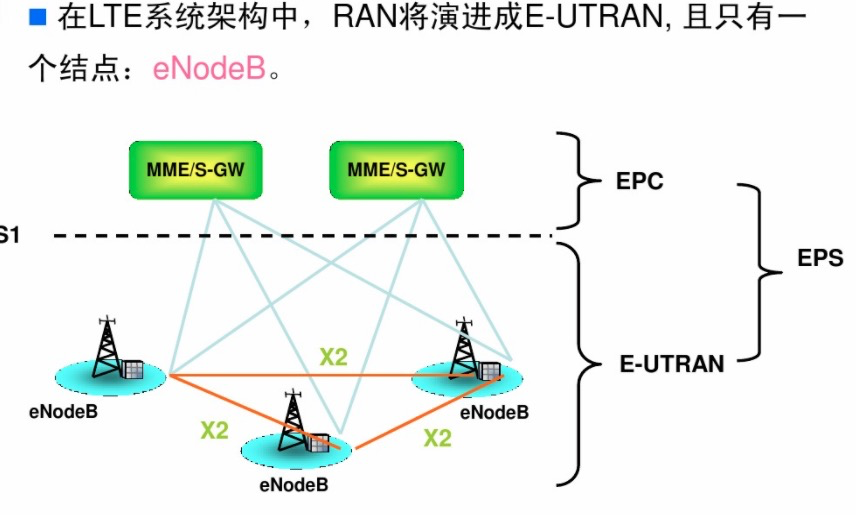
图1为本发明一实施例中在线语音识别引擎的结构框图,如图1所示,在线语音识别引擎100包括:至少一DNN网络10、RNN信息融合网络20、云端服务器30以及语音识别评价模块40。
每一DNN网络10针对其对应的局部特征一致的经标注的语音数据进行学习训练,自身一致性高,不需要海量的需要标注的语音数据,每一DNN网络10网络层级较简单。每一DNN网络10接收需要识别的新语音数据并基于其训练结果给出语音识别输出。
每一DNN网络10对应的局部特征一致的经标注的语音数据可以就要语音数据的属性来划分,例如方言、语种、应用领域等。
RNN信息融合网络20具有对学习样本数据的时序性进行分析的能力,能够平衡不同训练批次样本间特征不一致性,从而在整体上改善学习的效果和对数据扩展的适应性,在本实施例中,其用于接收需要识别的新语音数据和各个DNN语音识别子系统基于需要识别的新语音数据的输出,不断更新网络参数,不断提高RNN信息融合网络自身融合能力。
云端服务器30,用于存储与每一DNN网络对应的局部特征一致的经标注的语音数据及采集到的需要识别的新语音数据,其可以将与每一DNN网络10对应的局部特征一致的经标注的语音数据及采集到的需要识别的新语音数据传输至相应的每一DNN网络10,以及如果需要,将需要识别的新语音数据传输至RNN信息融合网络20。
语音识别评价模块40,其基于所述DNN网络,或DNN网络和RNN信息融合网络的语音识别输出给出评测结果。
语音识别评价模块40基于所述至少一DNN网络语音识别输出给出评测结果不好,即与需要识别的语音数据偏差较大时,此时DNN网络中的至少一个效能下降时,RNN信息融合网络开启工作,不断更新网络参数,不断提高RNN信息融合网络自身融合能力。
如此在线语音识别引擎100不断增强自身对新语音数据的适应性,从而提高自身扩展性和稳定性。
在线语音识别引擎100可以工作在两种工作模式下,在一种工作模式下,RNN信息融合网络20不开启,仅利用所述至少一DNN网络10来实现语音识别,在另一种工作模式,RNN信息融合网络20开启,DNN网络和RNN信息融合网络共同实现语音识别。
云端服务器30基于语音识别评价模块40的测评结果能够灵活进行不同工作模式的切换,降低不必要开销,增强系统效能。在DNN子系统能够提供有效服务时,利用子系统提供服务,在子系统效能下降时,启动RNN信息融合网络,提高语音识别率和服务能力。
本发明另一实施例提供一种在线语音识别方法,图2为本发明另一实施例在线语音识别方法的流程图,如图2所示,该在线语音识别方法包括以下步骤:
S100采用与其对应的局部特征一致的经标注的语音数据来对至少一个DNN网络进行学习训练;
每一DNN网络10针对其对应的局部特征一致的经标注的语音数据进行学习训练,自身一致性高,不需要海量的需要标注的语音数据,每一DNN网络10网络层级较简单。
每一DNN网络10对应的局部特征一致的经标注的语音数据可以就要语音数据的属性来划分,例如方言、语种、应用领域等。
S200至少一个DNN网络接收需要识别的新语音数据进行语音数据识别;
S300判断至少一个DNN网络的效能是否下降,若是则至步骤400,若否则返回S200。
语音识别评价模块40基于所述至少一DNN网络语音识别输出给出评测结果不好,即与需要识别的语音数据偏差较大时,此时DNN网络中的至少一个效能下降。
S400启动RNN信息融合网络。
RNN信息融合网络接收需要识别的新语音数据和各个DNN语音识别子系统基于需要识别的新语音数据的输出,并不断提高RNN信息融合网络自身融合能力。
应注意,实施例中提到的方向用语,例如“上”、“下”、“前”、“后”、“左”、“右”等,仅是参考附图的方向,并非用来限制本发明的保护范围。并且上述实施例可基于设计及可靠度的考虑,彼此混合搭配使用或与其他实施例混合搭配使用,即不同实施例中的技术特征可以自由组合形成更多的实施例。
需要说明的是,在附图或说明书正文中,未绘示或描述的实现方式,均为所属技术领域中普通技术人员所知的形式,并未进行详细说明。此外,上述对各元件和方法的定义并不仅限于实施例中提到的各种具体结构、形状或方式,本领域普通技术人员可对其进行简单地更改或替换。
以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。