视频教程:B站、网易云课堂、腾讯课堂
代码地址:Gitee、Github
存储地址:
百度云-提取码:
Google云
- 1.Tensorflow和Keras简介
- 2.Tensorflow
- 3.实现线性回归
- 4.保存和恢复模型
- 5.TensorBoard监控
- 6. 实现第一个神经网络
- 7.Keras
- 8.Keras的重要API
- 9. 纯Keras的神经网络
- 10.Keras中的现成模型
- 11.补充:OpenCV极简操作
1.Tensorflow和Keras简介
Tensorflow是由Google在2015年开源的一个深度学习框架,Tensorflow分前后端,前端是python接口,后端是c++/c实现代码。
Keras是纯python的高阶API,是tensorflow、mxnet、theano的再封装,接口标准化
一般用右边的

2. Tensorflow
Tensorflow是一个符号式编程的框架。由谷歌大脑开发,2015年开源,是目前业界用的最广泛的深度学习框架之一。该框架可广泛的用于各个终端,服务器端,移动端和嵌入式端等。
一个Tensorflow程序通常包含两个部分:
- 构建计算图(构建-init)
- 执行计算图(传播-forward)
Tensorflow版本采用的是1.2.0-cpu
import warnings
warnings.filterwarnings('ignore')
# 导入tensorflow包
import tensorflow as tf
# 构建计算图
g1 = tf.get_default_graph()
w = tf.constant(2.)
y = w+2
# 加载会话,执行计算图
with tf.Session(graph = g1) as sess:print(sess.run([y]))
# 清空图
tf.reset_default_graph()
基本概念:
Tensorflow中有一些基本概念必须掌握清楚:
-
图(graph)
-
会话(session)
-
操作(op)
-
张量(tensor)
-
变量(variable)
-
占位符(placeholder)
-
计算路径
-
tf.assgin
- 图(graph)
图由节点和边组成,需要注意的是这个图的概念和和理论上的计算图不一样。在Tensorflow中边表示流动的方向,节点表示张量和操作。张量和操作的概念在后面会进一步讲解。(课上讲的计算图,边表示操作,节点表示变量)
注意:计算图只包含操作,不包含结果(没有实际的运算过程)
 当你打开Tensorflow的时候,tf会自动为你分配一个默认的图。你所有构件图的操作都会在这个默认的图上进行操作。
当你打开Tensorflow的时候,tf会自动为你分配一个默认的图。你所有构件图的操作都会在这个默认的图上进行操作。
# 默认的图上进行操作
g0 = tf.get_default_graph()
# 这是图的一个构件
x0 = tf.Variable(1)
# 查看这个图中的构件属不属于这个图
x0.graph is g0
# 在不同的图上进行不同的操作
g1 = tf.Graph()
g2 = tf.Graph()
# 在g1这个图上进行操作
with g1.as_default():x1 = tf.Variable(1)
# 在g2这个图上进行操作
with g2.as_default():x2 = tf.Variable(1)
print(x1.graph is g2)
print(x2.graph is g2)
有时候需要查看一个图上有哪些操作节点:
# 查看某一个图上的操作节点
g1.get_operations()

在构建图的时候,由于重复构建操作导致图出错,所以在构建图的时候一定记得对默认的图进行清空。
g_now = tf.get_default_graph()
g_now.get_operations()

tf.reset_default_graph()
g_now = tf.get_default_graph()
g_now.get_operations()
补充:
Tensorflow是一种静态图的深度学习框架,Pytorch是一种动态图的深度学习框架。Tensorflow2.0引入了动态图机制,未来的框架是即可静态图也可动态图,两者可相互切换。
2.2 什么是会话(session)
会话的作用是处理内容和优化,使我们能够实际执行计算图指定的计算。
计算图是要执行的计算模版,会话通过分配计算资源来执行计算图的计算。
图的构建是几乎不占资源的,但是会话会占用很多资源
# 构建图(在默认的图上构建)
w = tf.constant(3)
x = w+2
y = x+5
z = x*3
# 执行会话
with tf.Session(graph=tf.get_default_graph()) as sess:print(sess.run([x]))print(sess.run([z])) print(x.eval())
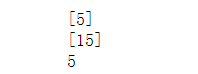

#### 注意:1. eval( )等价于sess.run( )。
2. tensorflow会自动检测依赖关系。
3. 除了variable变量其余计算结果每次计算完后会释放。variable在session执行完后释放。
4. 重复计算的问题。
# 解决重复计算的问题
# 构建图
w = tf.constant(3)
x = w+2
y = x+5
z = x*3
# 执行会话
with tf.Session(graph=tf.get_default_graph()) as sess:print(sess.run([x,z]))#print(sess.run[x])#print(sess.run(z))
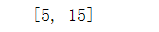
每次使用上下文管理器太麻烦,于是我们有互动的会话,互动的会话就像ipython一样,实时反馈。实时反馈的目的是为了简单进行调动
# 注意需要手动关闭
sess = tf.InteractiveSession()
print(x.eval())
print(sess.run(x)
sess.close()
# print(sess.run([x]))
- 张量(tensor)
操作的输入和输出就是张量,Tensorflow直观翻译,就是张量流动的意思。
- 标量(scalar)
- 向量(vector)
- 矩阵(matrix)
- 张量(tensor)
在tensorflow中张量主要有三个来源:
- constant
- variable
- placeholder
这里我们只讨论contant,后面两种在后面小节会详细讨论。
constant的生存周期在会话内。
tf.constant生成常量的意思(常量意味着不可变)。
import numpy as np
a = tf.constant(np.arange(12).reshape(3,4),dtype=tf.float32)
with tf.Session(graph=tf.get_default_graph()) as sess:print(sess.run([a]))
tf.reset_default_graph()

a = tf.constant(0.0,shape=(3,2,6),dtype=tf.float32)
with tf.Session() as sess:print(sess.run([a]))
tf.reset_default_graph()

- 变量(variable)
在神经网络中,我们需要一种能充当神经网络参数的角色。他可以被保存,也可被更新。这种角色称之为变量。变量也是一种张量。variable这种张量在session中会一直保持,不会被释放,可以被改变,直到session被关闭。
注意:变量一定需要初始化。(神经网络参数也需要初始化!)
变量的初始化主要使用下面的代码,这样就不需要一个一个的初始化了。
# 这个实际上是一个op包含了所有的变量。
......
init = tf.global_variables_initializer()
......
sess.run(init)
- 其中
init构建在图中。 - sess.run(init)在session中执行。
在Tensorflow中主要通过tf.Variable和tf.get_variable两个接口来实现变量。两者有很大的区别,建议大家尽量使用tf.get_variable
tf.Variable的使用
1. 每次调用得到的都是不同的变量,即使使用了相同的变量名,在底层实现的时候还是会为变量创建不同的别名。
var1 = tf.Variable(tf.random_uniform([1], -1.0, 1.0),name='var',dtype=tf.float32)
var2 = tf.Variable(initial_value=[2],name='var',dtype=tf.float32)
init = tf.global_variables_initializer()
with tf.Session() as sess:sess.run(init)print(var1.name, sess.run(var1))print(var2.name, sess.run(var2))

2. 会受tf.name_scope环境的影响,即会在前面加上name_scope的空间前缀。
tf.reset_default_graph()
with tf.name_scope('var_b_scope'):var1 = tf.Variable(name='var', initial_value=[2], dtype=tf.float32)var2 = tf.Variable(name='var', initial_value=[2], dtype=tf.float32)
with tf.name_scope('var_a_scope'):var3 = tf.Variable(name='var', initial_value=[2], dtype=tf.float32)
init = tf.global_variables_initializer()
with tf.Session() as sess:sess.run(init)print(var1.name, sess.run(var1))print(var2.name, sess.run(var2))print(var3.name, sess.run(var3))

3. Variable()创建时直接指定初始化的方式,还可以把其他变量的初始值作为初始值。
var2 = tf.Variable(var1.initialized_value())
tf.get_variable的使用
1. 只会创建一个同名变量,如果想共享变量,需指定reuse=True,否则多次创建会报错,使用reuse=True(第一次创建的时候不用,后面共享的时候声明),可以动态的修改某个scope的共享属性。
tf.reset_default_graph()def func(x):weight = tf.get_variable(name = "weight",initializer = tf.random_normal([1])) bias = tf.get_variable(name="bias",initializer = tf.zeros([1])) return tf.add(tf.multiply(weight, x), bias)result1 = func(1)
#result2 = func(2)
init = tf.global_variables_initializer()
with tf.Session() as sess:sess.run(init)print(sess.run([result1]))# print(sess.run(result2))
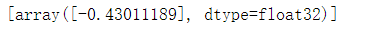
tf.reset_default_graph()
def func(x,reuse):with tf.variable_scope('neuron',reuse=reuse):weight = tf.get_variable(name = "weight",initializer = tf.random_normal([1])) bias = tf.get_variable(name="bias",initializer = tf.zeros([1])) return tf.add(tf.multiply(weight, x), bias)
result1 = func(1,reuse=False)
result2 = func(2,reuse=True)
init = tf.global_variables_initializer()
with tf.Session() as sess:sess.run(init)print(sess.run([result1]))print(sess.run([result2]))

2. 不受with tf.name_scope的影响(注:是name_scope,不是variable_scope,tf.Variable和tf.get_variable都会受variable_scope影响))
tf.reset_default_graph()
with tf.name_scope('var_a_scope'):var1 = tf.get_variable(name='var', shape=[1], dtype=tf.float32)var2 = tf.get_variable(name='var1', shape=[1], dtype=tf.float32)
with tf.Session() as sess:sess.run(tf.global_variables_initializer())print(var1.name, sess.run(var1))print(var2.name, sess.run(var2))

3. 初始化方法
conv1_weights = tf.get_variable(name="conv1_weights", shape=[5, 5, 3, 3], dtype=tf.float32, initializer=tf.truncated_normal_initializer())
conv1_biases = tf.get_variable(name='conv1_biases', shape=[3], dtype=tf.float32, initializer=tf.zeros_initializer())
4. with tf.variable_scope('scope_name")会进行“累加”,每调用一次就会给里面的所有变量添加一次前缀,叠加顺序是外层先调用的在前,后调用的在后
tf.reset_default_graph()
def my_image_filter(input_images):with tf.variable_scope('scope_a'):conv1_weights = tf.get_variable(name="conv1_weights", shape=[5, 5, 3, 3], dtype=tf.float32, \initializer=tf.truncated_normal_initializer())conv1_biases = tf.get_variable(name='conv1_biases', shape=[3], dtype=tf.float32, \initializer=tf.zeros_initializer())conv1 = tf.nn.conv2d(input_images, conv1_weights, strides=[1, 1, 1, 1], padding='SAME')print(conv1_weights.name)return tf.nn.relu(conv1 + conv1_biases)image1 = np.random.random(3*5*5).reshape(1, 5, 5, 3).astype(np.float32)
image2 = np.random.random(3*5*5).reshape(1, 5, 5, 3).astype(np.float32)
with tf.variable_scope("image_filters") as scope:result1 = my_image_filter(image1)print(result1.name)
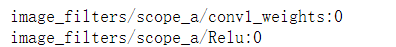
- 占位符(placeholder)
我们需要让计算图能接受外面来的数据,如何接受外面的数据就是通过占位符实现的。简单点理解就是神经网络需要输入的数据就是由占位符来输入的。为什么叫占位符,因为BatchSize是占了个位置,占好位置后,输入的数据在不断变化。
注意:占位符也是一种
tensor。输入的数据我们一般输入numpy的ndarray。
import numpy as np
ph = tf.placeholder(dtype=tf.float32,shape =(None,3))
add_op = tf.add(ph,1)with tf.Session() as sess:#print(sess.run(ph,feed_dict={ph:np.random.rand(4,3)}))print(sess.run(add_op,feed_dict={ph:np.random.rand(5,3)}))

- 计算路径
计算路径是指如果计算的节点具有依赖关系,那么我们就会计算这些节点,沿着父节点找。
TensorFlow仅通过必需的节点自动进行计算这一事实是该框架的一个巨大优势。如果计算图非常大并且有许多不必要的节点,那么它可以节省大量调用的运行时间。它允许我们构建大型的多用途计算图,这些计算图使用单个共享的核心节点集合,并根据所采取的不同计算路径去做不同的事情
# tensorflow会自动寻找依赖关系
# 如果去掉feed_dict会报错
tf.reset_default_graph()ph = tf.placeholder(tf.int32)three_node = tf.constant(3)sum_node = ph + three_nodewith tf.Session() as sess:#print(sess.run(three_node))print(sess.run(sum_node,feed_dict={ph:15}))

- 重要的操作tf.assign
tf.assign(target, value)表示把value值赋值给target。target必须是一个可变的tensor(variable)可以没被初始化。value必须要有和target相同的数据类型和形状。
思考一下如下的操作需要用到tf.assign吗?如果要用,对谁用?
θ = θ − β ∇ L ( θ ) \theta = \theta - \beta \nabla L(\theta) θ=θ−β∇L(θ)
3.实现线性回归
线性回归可以看作是最简单的神经网络。我们使用4种方法来实现一个线性回归。
- 解析法。
- 人工求梯度。
- 使用低阶API求梯度。
- 使用高阶API求梯度。
import tensorflow as tf
import numpy as np
from sklearn.datasets import fetch_california_housinghousing = fetch_california_housing()
m, n = housing.data.shape
housing_data_plus_bias = np.c_[np.ones((m, 1)), housing.data]X = tf.constant(housing_data_plus_bias, dtype=tf.float32, name="X")
y = tf.constant(housing.target.reshape(-1, 1), dtype=tf.float32, name="y")
XT = tf.transpose(X)
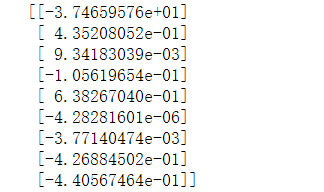
theta = tf.matmul(tf.matmul(tf.matrix_inverse(tf.matmul(XT, X)), XT), y)
with tf.Session() as sess: theta_value = theta.eval()print(theta_value)
import time
tf.reset_default_graph()n_epochs = 1000
learning_rate = 0.01data = housing.data
scaled_housing_data_plus_bias = (data-np.mean(data,axis=0))/np.std(data,axis=0)
scaled_housing_data_plus_bias = np.c_[np.ones((m, 1)), scaled_housing_data_plus_bias]X = tf.constant(scaled_housing_data_plus_bias, dtype=tf.float32, name="X")
y = tf.constant(housing.target.reshape(-1, 1), dtype=tf.float32, name="y")theta = tf.Variable(tf.random_uniform([n + 1, 1], -1.0, 1.0), name="theta")
y_pred = tf.matmul(X, theta, name="predictions")error = y_pred - y
mse = tf.reduce_mean(tf.square(error), name="mse")gradients = 2./m * tf.matmul(tf.transpose(X), error)training_op = tf.assign(theta, theta - learning_rate * gradients)init = tf.global_variables_initializer() with tf.Session() as sess:sess.run(init)for epoch in range(n_epochs):if epoch%100==0:print("Epoch", epoch, "MSE =", mse.eval())time.sleep(1)sess.run(training_op)best_theta = theta.eval()print(best_theta)

tf.reset_default_graph()
n_epochs = 1000
learning_rate = 0.01data = housing.data
scaled_housing_data_plus_bias = (data-np.mean(data,axis=0))/np.std(data,axis=0)
scaled_housing_data_plus_bias = np.c_[np.ones((m, 1)), scaled_housing_data_plus_bias]
X = tf.constant(scaled_housing_data_plus_bias, dtype=tf.float32, name="X")
y = tf.constant(housing.target.reshape(-1, 1), dtype=tf.float32, name="y")theta = tf.Variable(tf.random_uniform([n + 1, 1], -1.0, 1.0), name="theta")
y_pred = tf.matmul(X, theta, name="predictions")error = y_pred - y
mse = tf.reduce_mean(tf.square(error), name="mse")gradients = tf.gradients(mse,theta)training_op = tf.assign(theta, theta - learning_rate * gradients[0])
init = tf.global_variables_initializer()
with tf.Session() as sess:sess.run(init)for epoch in range(n_epochs):if epoch%100==0:print("Epoch", epoch, "MSE =", mse.eval())time.sleep(1)sess.run(training_op)best_theta = theta.eval()print(best_theta)

tf.reset_default_graph()
n_epochs = 1000
learning_rate = 0.01data = housing.data
scaled_housing_data_plus_bias = (data-np.mean(data,axis=0))/np.std(data,axis=0)
scaled_housing_data_plus_bias = np.c_[np.ones((m, 1)), scaled_housing_data_plus_bias]
X = tf.constant(scaled_housing_data_plus_bias, dtype=tf.float32, name="X")
y = tf.constant(housing.target.reshape(-1, 1), dtype=tf.float32, name="y")
theta = tf.Variable(tf.random_uniform([n + 1, 1], -1.0, 1.0), name="theta")
y_pred = tf.matmul(X, theta, name="predictions")
error = y_pred - y
mse = tf.reduce_mean(tf.square(error), name="mse")#optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
optimizer = tf.train.MomentumOptimizer(learning_rate=learning_rate,momentum=0.9)
training_op = optimizer.minimize(mse)init = tf.global_variables_initializer()
with tf.Session() as sess:sess.run(init)for epoch in range(n_epochs):if epoch%100==0:print("Epoch", epoch, "MSE =", mse.eval())time.sleep(1)sess.run(training_op)best_theta = theta.eval()print(best_theta)

4.保存和恢复模型
在模型的参数学习过程中,我们需要根据情况保存模型。根据前面的讲解知道神经网络的参数存储在variable中,variable的参数在session关闭后就会释放。所以我们需要在session打开的时候保存模型的参数。
保存模型参数类似于checkpoint(切片快照)。在迭代的过程中,选择某一次快照一下然后保存到硬盘中。
注意:模型保存在硬盘中有四个文件
tf.reset_default_graph()
theta = tf.Variable(tf.random_uniform([3, 1], -1.0, 1.0), name="theta")
init = tf.global_variables_initializer()
saver = tf.train.Saver()
n_epochs = 1000
with tf.Session() as sess: sess.run(init)for epoch in range(n_epochs):# checkpoint every 100 epochsif epoch % 100 == 0: saver.save(sess, save_path="./model/my_model.ckpt")print(theta.eval())
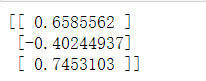
我们来查看一下保存的文件:

文件中主要保存了两类东西:
- 计算图(保存在meta文件中)
- variable的参数(保存在data文件中)
所以我们从硬盘中加载回模型有两种方法:
- 复制之前的代码,生成一摸一样的计算图,然后加载参数。
- 加载meta文件,将计算图加载回来,然后加载参数。
# 方法一
tf.reset_default_graph()
theta = tf.Variable(tf.random_uniform([3, 1], -1.0, 1.0), name="theta")
init = tf.global_variables_initializer()
saver = tf.train.Saver()
with tf.Session() as sess: saver.restore(sess,save_path="./model/my_model.ckpt")print(theta.eval())

# 方法二
tf.reset_default_graph()
saver = tf.train.import_meta_graph('./model/my_model.ckpt.meta')
with tf.Session() as sess:saver.restore(sess,'./model/my_model.ckpt')

4.1 tf.get_collection和tf.add_to_collection
为了方便我们取出不同的operation,我们需要使用tf.add_to_collection和tf.get_collection。
tf.reset_default_graph()
theta = tf.Variable(tf.random_uniform([3, 1], -1.0, 1.0), name="theta")
tf.add_to_collection('my_op',theta)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
n_epochs = 1000
with tf.Session() as sess: sess.run(init)for epoch in range(n_epochs):# checkpoint every 100 epochsif epoch % 100 == 0: saver.save(sess, save_path="./model/my_model.ckpt")print(theta.eval())
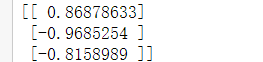
tf.reset_default_graph()
saver = tf.train.import_meta_graph('./model/my_model.ckpt.meta')
my_op = tf.get_collection('my_op')
with tf.Session() as sess:saver.restore(sess,'./model/my_model.ckpt')print(sess.run(my_op[0]))
my_op
在这里插入图片描述
5.TensorBoard监控
TensorBoard是和TensorFlow配套的一个神经网络可视化的工具。
大致流程如下:
- 在你创建的图里面,选择你要汇总(summary)的节点。
- 因为你要对每一个汇总操作,进行sess.run操作,为了方便所以我们需要将所有操作进行汇总。(tf.summary.merge_all())。
- 在sess中运行上面汇总的操作。
- 使用tf.summary.FileWriter,将结果写入文件。
- 使用tensorboard --logdir='path’运行文件。
5.1 summary操作
#统计标量,比如loss,accuracy,得到时序图
tf.summary.scalar(name,tensor)
#统计张量,直方图统计,看weights,bias的分布
tf.summary.histogram(name,tensor)
# 将summary的操作进行汇总
# inputs是个list
# 一个表示部分汇总一个表示全部汇总
merge_some=tf.summary.merge(inputs,collections=None,name=None)
merge_summary=tf.summary.merge_all(key=tf.GraphKeys.SUMMARIES)
注意:上面的操作都是在图的定义中
5.2 文件写入操作
#写入到硬盘的文件
#这个操作把图写入文件中
file_writer=tf.summary.FileWriter(logdir,graph,flush_secs)
merge=sess.run(merge_some)
file_writer.add_summary(merge,step)
注意,该操作是在sess会话中运行
[...]
for batch_index in range(n_batches):X_batch, y_batch = fetch_batch(epoch, batch_index, batch_size) if batch_index % 10 == 0:summary_str = mse_summary.eval(feed_dict={X: X_batch, y: y_batch})step = epoch * n_batches + batch_indexfile_writer.add_summary(summary_str, step)sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
[...]
5.3 运行tensorboard
#path为目录地址
tensorboard --logdir='path'
#关于端口被占用的解决方法
#默认使用的是6006端口
lsof -i:6006
kill -9 4969
#在浏览器中输入http://0.0.0.0:6006/ (or http://localhost:6006/)
6006倒过来就是goog的意思
# tensorboard举例
import tensorflow as tf
import numpy as np
from datetime import datetime
from sklearn.datasets import fetch_california_housinghousing = fetch_california_housing()
m, n = housing.data.shapetf.reset_default_graph()n_epochs = 1000
learning_rate = 0.01data = housing.data
scaled_housing_data_plus_bias = (data-np.mean(data,axis=0))/np.std(data,axis=0)
scaled_housing_data_plus_bias = np.c_[np.ones((m, 1)), scaled_housing_data_plus_bias]
X = tf.constant(scaled_housing_data_plus_bias, dtype=tf.float32, name="X")
y = tf.constant(housing.target.reshape(-1, 1), dtype=tf.float32, name="y")theta = tf.Variable(tf.random_uniform([n + 1, 1], -1.0, 1.0), name="theta")
y_pred = tf.matmul(X, theta, name="predictions")
error = y_pred - y
mse = tf.reduce_mean(tf.square(error), name="mse")# 定义写入的东西
tf.summary.scalar('mse',mse)
tf.summary.histogram('theta',theta)# 进行汇总
merge_summary=tf.summary.merge_all(key=tf.GraphKeys.SUMMARIES)# 定义写入地址
now = datetime.utcnow().strftime("%Y%m%d%H%M%S")
root_logdir = "tf_logs"
logdir = "{}/run-{}/".format(root_logdir, now)
# 打印写入的地址方便tensorboard使用
print(logdir)optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
training_op = optimizer.minimize(mse)init = tf.global_variables_initializer()
with tf.Session() as sess:sess.run(init)# 定义写的文件(打开)file_writer=tf.summary.FileWriter(logdir,sess.graph)for epoch in range(n_epochs):if epoch%100==0:print("Epoch", epoch, "MSE =", mse.eval())sess.run(training_op)# 计算写入的值summary_str = merge_summary.eval()file_writer.add_summary(summary_str, epoch)best_theta = theta.eval()print(best_theta)
file_writer.close()

6.实现第一个神经网络
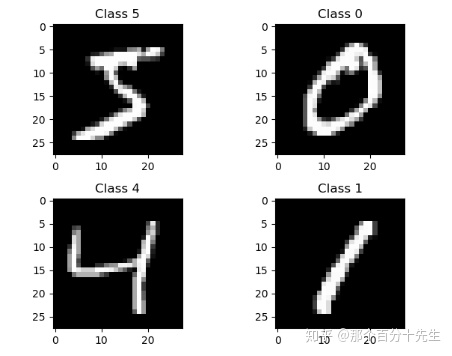
任务:使用mnist数据集来实现图像的分类:

输入是以下的一张图片:

等价于一个矩阵:

import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import systf.reset_default_graph()
epochs = 15
batch_size = 100
total_sum = 0
epoch = 0mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
train_num = mnist.train.num_examplesinput_data = tf.placeholder(tf.float32,shape=(None,784))
input_label = tf.placeholder(tf.float32,shape=(None,10))w1 = tf.get_variable(shape=(784,64),name='hidden_1_w')
b1 = tf.get_variable(shape=(64),initializer=tf.zeros_initializer(),name='hidden_1_b')w2 = tf.get_variable(shape=(64,32),name='hidden_2_w')
b2 = tf.get_variable(shape=(32),initializer=tf.zeros_initializer(),name='hidden_2_b')w3 = tf.get_variable(shape=(32,10),name='layer_output')#logit层
output = tf.matmul(tf.nn.relu(tf.matmul(tf.nn.relu(tf.matmul(input_data,w1)+b1),w2)+b2),w3)loss = tf.losses.softmax_cross_entropy(input_label,output)#opt = tf.train.GradientDescentOptimizer(learning_rate=0.1)
opt = tf.train.AdamOptimizer()train_op = opt.minimize(loss)# 测试评估
correct_pred = tf.equal(tf.argmax(input_label,axis=1),tf.argmax(output,axis=1))
acc = tf.reduce_mean(tf.cast(correct_pred,tf.float32))tf.add_to_collection('my_op',input_data)
tf.add_to_collection('my_op',output)
tf.add_to_collection('my_op',loss)init = tf.global_variables_initializer()
saver = tf.train.Saver()
with tf.Session() as sess:sess.run([init])test_data = mnist.test.imagestest_label = mnist.test.labelswhile epoch<epochs:data,label=mnist.train.next_batch(batch_size)data = data.reshape(-1,784)total_sum+=batch_sizesess.run([train_op],feed_dict={input_data:data,input_label:label})if total_sum//train_num>epoch:epoch = total_sum//train_numloss_val = sess.run([loss],feed_dict={input_data:data,input_label:label})acc_test = sess.run([acc],feed_dict={input_data:test_data,input_label:test_label})saver.save(sess, save_path="./model/my_model.ckpt")print('epoch:{},train_loss:{:.4f},test_acc:{:.4f}'.format(epoch,loss_val[0],acc_test[0]))

from matplotlib import pyplot as plt
%matplotlib inline
index = 666
plt.imshow(test_data[index].reshape(28,28),cmap='gray')

tf.reset_default_graph()
sess = tf.InteractiveSession()
saver = tf.train.import_meta_graph('./model/my_model.ckpt.meta')
saver.restore(sess,"./model/my_model.ckpt")
input_tensor = tf.get_collection('my_op')[0]
output_tensor = tf.get_collection('my_op')[1]
np.argmax(sess.run(output_tensor,feed_dict={input_tensor:np.expand_dims(test_data[index],axis=0)}))

7.Keras
Keras是一个高层神经网络API,Keras由纯Python编写而成并基Tensorflow、Theano以及CNTK后端。Keras 为支持快速实验而生,能够把你的idea迅速转换为结果,keras的基本特点:
- 简易和快速的原型设计(keras具有高度模块化,极简,和可扩充特性)
- 支持CNN和RNN,或二者的结合
- 无缝CPU和GPU切换
注意:Keras适用的Python版本是:Python 2.7-3.6
在这里我们使用tensorflow作为keras的后端,实际上tensorflow已经将keras集成进了tensorflow中,所以keras可以看作是tensorflow的一个高阶API。
from tensorflow.python import keras
import tensorflow as tf
8.Keras的重要API
Keras的API主要可以分为以下几类:
layers:主要涉及神经网络的一些构件,如全连接,卷积,最大池化等。
activations:主要涉及神经网络的常用激活函数。
losses:主要涉及一些常用的损失函数。
metrics:主要涉及常用的模型评估方法。
optimizers:主要涉及常用的优化方法。
models:主要涉及模型的组装,模型的保存,模型的加载。
backend: 主要涉及更底层的一些操作,如张量的操作。
callbacks:主要涉及一些回调函数的操作。如模型的保存,模型的可视化。
使用Keras建立神经网络主要包含三个步骤:
- 准备数据。
- 搭建神经网络结构。
- 编译模型(确定损失函数、优化方法和回调函数)。
- 训练模型。
## layers相关API
input_tensor = keras.layers.Input(shape=(784,))keras.layers.Dense(units=10,activation=keras.activations.relu,use_bias=True)keras.layers.Softmax(axis=-1)(input_tensor)keras.layers.Flatten()a = keras.layers.Input(shape=(28,))
print(a)
b = keras.layers.Input(shape=(56,))
print(b)
c= keras.layers.concatenate([a,b],axis=-1)
print(c)

## activations相关API
keras.activations.relu
keras.activations.sigmoid
keras.activations.tanh

## losses相关API
keras.losses.categorical_crossentropy
keras.losses.sparse_categorical_crossentropy
keras.losses.mean_squared_error
keras.losses.mean_absolute_error
keras.losses.logcosh()
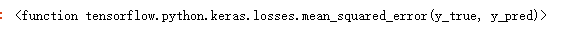
## metric相关API
keras.metrics.accuracy
keras.metrics.sparse_top_k_categorical_accuracy
keras.metrics.Precision()
keras.metrics.Recall()

## optimizers相关API
keras.optimizers.SGD()
keras.optimizers.RMSprop()
keras.optimizers.Adam()

## models相关API
# Sequential API
model = keras.models.Sequential([keras.layers.Dense(30, activation="relu",input_shape=[10]),keras.layers.Dense(1)])
print(model.input_shape)
model.compile(loss="mean_squared_error", optimizer="sgd")


#Function API
#单输入单输出
input_tensor = keras.layers.Input(shape=(12,))
hidden1 = keras.layers.Dense(30, activation="relu")(input_tensor)
hidden2 = keras.layers.Dense(30, activation="relu")(hidden1)
concat = keras.layers.Concatenate(axis=-1)([input_tensor, hidden2])
output_tensor = keras.layers.Dense(1)(concat)
keras.models.Model(inputs=[input_tensor],outputs=[output_tensor])
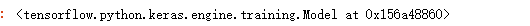

#多输入单输出
input_A = keras.layers.Input(shape=[5])
input_B = keras.layers.Input(shape=[6])
hidden1 = keras.layers.Dense(30, activation="relu")(input_B)
hidden2 = keras.layers.Dense(30, activation="relu")(hidden1)
concat = keras.layers.Concatenate(axis=-1)([input_A, hidden2])
output = keras.layers.Dense(1)(concat)
model = keras.models.Model(inputs=[input_A, input_B], outputs=[output])

#多输入多输出
input_A = keras.layers.Input(shape=[5])
input_B = keras.layers.Input(shape=[6])
hidden1 = keras.layers.Dense(30, activation="relu")(input_B)
hidden2 = keras.layers.Dense(30, activation="relu")(hidden1)
concat = keras.layers.concatenate([input_A, hidden2])
output = keras.layers.Dense(1)(concat)
aux_output = keras.layers.Dense(1)(hidden2)
model = keras.models.Model(inputs=[input_A, input_B],outputs=[output, aux_output])
model.compile(loss=["mse", "mae"], loss_weights=[0.9, 0.1], optimizer="sgd")

model的训练
model.fit([X_train_A, X_train_B], [y_train, y_train], epochs=20,batch_size=64,validation_data=([X_valid_A,X_valid_B],[y_valid, y_valid]))
## model系列API
keras.models.save_model
keras.models.load_model

## backend系列API
keras.backend.argmax
keras.backend.sum
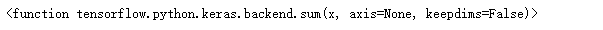
## callback系列API
keras.callbacks.ModelCheckpoint()
keras.callbacks.TensorBoard()
9. 纯Keras的神经网络
下面将使用一个简单的纯keras来实现一个神经网络,纯keras实现神经网络方便且简单。
要解决的问题fashion-mnist数据集问题:

这是一个十分类问题。
解决步骤:
- 数据准备
- 网络结构设计
- 损失函数设计
- 优化方法设计
import warnings
warnings.filterwarnings('ignore')
import numpy as np
from tensorflow.python import keras
fashion_mnist = keras.datasets.fashion_mnist
# 数据准备
(X_train_full, y_train_full), (X_test, y_test) = fashion_mnist.load_data()
X_train_scaler = X_train_full/255.
X_test_scaler = X_test/255.
X_train_scaler = X_train_scaler.reshape(-1,28*28)
X_test_scaler = X_test_scaler.reshape(-1,28*28)
class_names = ["T-shirt/top", "Trouser", "Pullover", "Dress", "Coat","Sandal", "Shirt", "Sneaker", "Bag", "Ankle boot"]
y_train = keras.utils.to_categorical(y_train_full,num_classes=10)
y_test = keras.utils.to_categorical(y_test,num_classes=10)
from matplotlib import pyplot as plt
%matplotlib inline
index = 666
plt.imshow(X_train_scaler[666].reshape(28,28),cmap='gray')

from tensorflow.python.keras.layers import Dense,Softmax,Activation,Input
from tensorflow.python.keras.models import Model
from tensorflow.python.keras.callbacks import ModelCheckpoint,TensorBoard
from tensorflow.python.keras import backend as K
import os
import tensorflow as tf# 网络架构设计
input_tensor = Input(shape=(784,))
hidden1 = Activation(activation='relu')(Dense(units=32,use_bias=True)(input_tensor))
hidden2 = Activation(activation='relu')(Dense(units=16,use_bias=True)(hidden1))
logits = Dense(units=10,use_bias=True)(hidden2)
pred = Softmax()(logits)# 损失函数设计: 注意loss和metric的区别
loss_op = keras.losses.categorical_crossentropy# 模型评估
def accuracy(y_true,y_pred):y_t = tf.argmax(y_true,axis=1)y_p = tf.argmax(y_pred,axis=1)return tf.reduce_mean(tf.cast(tf.equal(y_t,y_p),tf.float32))# 优化方法设计
train_op = keras.optimizers.sgd()# 保存模型
savemodel = ModelCheckpoint(filepath='keras_model/model_dnn.h5')# 模型组装和编译
model = Model(inputs=[input_tensor],outputs=[pred])
model.compile(loss=[loss_op],optimizer=train_op,metrics=[accuracy])# 可视化
root_logdir = os.path.join(os.curdir, "keras_logs")
def get_run_logdir(): import timerun_id = time.strftime("run_%Y_%m_%d-%H_%M_%S") return os.path.join(root_logdir, run_id)
run_logdir = get_run_logdir()
print(run_logdir)
tensorboard_cb = TensorBoard(run_logdir)# 模型的训练
model.fit(X_train_scaler,y_train,epochs=5,validation_data=(X_test_scaler,y_test),callbacks=[savemodel,tensorboard_cb])

# 查看参数数量和结构
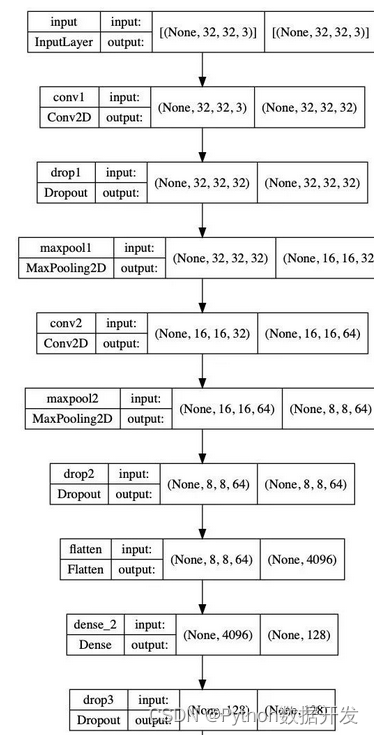
model.summary()

# 获取layer的名字
model.layers

# 查看参数
model.layers[1].get_weights()

from tensorflow.python.keras.models import load_model
model = load_model('keras_model/model_dnn.h5')
index = 666
img = X_test_scaler[index].reshape(1,-1)
pred = model.predict(img)
print(class_names[np.argmax(pred)])

from matplotlib import pyplot as plt
import numpy as np
%matplotlib inline
index = 666
img = X_test_scaler[index]
plt.imshow(img.reshape(28,28),cmap='gray')

10.Keras中的现成模型
/site-packages/keras_applications/
tf.keras.applications.inception_v3.InceptionV3
input_shape=(224,224,1)
base_model = tf.keras.applications.inception_v3.InceptionV3(include_top=True, weights=None, input_shape=input_shape, classes=100)
x=base_model.output
x.shape
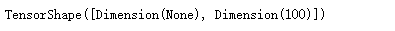
11.补充:OpenCV极简操作
# 导入opencv
import cv2
# 读取图片
img = cv2.imread("xxxx.jpg")
# 转化为灰度图
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
# 图片进行resize
img = cv2.resize(img,(256,256))
# 画矩形框
cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2)
# 显示图片
cv2.imshow('img',img)
# 写入图片
cv2.imwrite('img.png',img)



/cotent.assets/1587168767734.png)