前言
本文用于记录使用pytorch读取minist数据集的过程,以及一些思考和疑惑吧…
正文
在阅读教程书籍《深度学习入门之Pytorch》时,文中是如此加载MNIST手写数字训练集的:
train_dataset = datasets.MNIST(root='./MNIST',train=True,transform=data_tf,download=True)
解释一下参数
datasets.MNIST是Pytorch的内置函数torchvision.datasets.MNIST,通过这个可以导入数据集。
train=True 代表我们读入的数据作为训练集(如果为true则从training.pt创建数据集,否则从test.pt创建数据集)
transform则是读入我们自己定义的数据预处理操作
download=True则是当我们的根目录(root)下没有数据集时,便自动下载。
如果这时候我们通过联网自动下载方式download我们的数据后,它的文件路径是以下形式:

其中我们所需要的文件主要在raw文件夹下
train-images-idx3-ubyte.gz: training set images (9912422 bytes)
train-labels-idx1-ubyte.gz: training set labels (28881 bytes) t10k-images-idx3-ubyte.gz: test set images (1648877 bytes)
t10k-labels-idx1-ubyte.gz: test set labels (4542 bytes)
接下来,书中是如此加载数据集的
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,batch_size=5,shuffle=True)
由于DataLoader为Pytorch内部封装好的函数,所以对于它的调用方法需要自行去查阅。
我在最开始疑惑的点:传入的根目录在下载好数据集后,为MNIST下两个文件夹,而processed和raw文件夹下还有诸多文件,所以到底是如何读入数据的呢?所以我决定将数据集下载后,通过读取本地的MINIST数据集并进行装载。
首先,自定义数据类来继承和重写Dataset抽象类
class DealDataset(Dataset):"""读取数据、初始化数据"""def __init__(self, folder, data_name, label_name,transform=None):(train_set, train_labels) = self.load_data(folder, data_name, label_name) # 其实也可以直接使用torch.load(),读取之后的结果为torch.Tensor形式self.train_set = train_setself.train_labels = train_labelsself.transform = transformdef __getitem__(self, index):img, target = self.train_set[index], int(self.train_labels[index])if self.transform is not None:img = self.transform(img)return img, targetdef __len__(self):return len(self.train_set)'''load_data也是我们自定义的函数,用途:读取数据集中的数据 ( 图片数据+标签label'''def load_data(self,data_folder, data_name, label_name):with gzip.open(os.path.join(data_folder,label_name), 'rb') as lbpath: # rb表示的是读取二进制数据y_train = np.frombuffer(lbpath.read(), np.uint8, offset=8)with gzip.open(os.path.join(data_folder,data_name), 'rb') as imgpath:x_train = np.frombuffer(imgpath.read(), np.uint8, offset=16).reshape(len(y_train), 28, 28)return (x_train, y_train)
接下来,调用我们自定义的数据类来加载数据集
trainDataset = DealDataset('./MNIST/MNIST/raw', "train-images-idx3-ubyte.gz","train-labels-idx1-ubyte.gz",transform=transforms.ToTensor())# 训练数据和测试数据的装载
train_loader = torch.utils.data.DataLoader(dataset=trainDataset,batch_size=10, # 一个批次可以认为是一个包,每个包中含有10张图片shuffle=False,
)
通过这种方式便可以大概了解了读取数据集的过程。
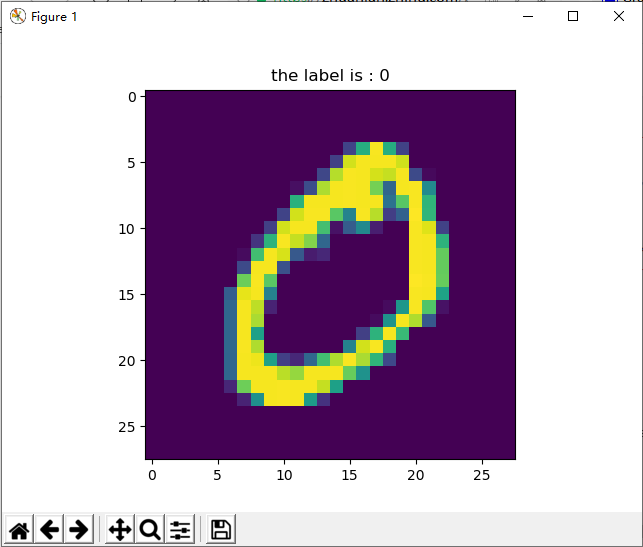
接下来,我们来验证以下我们数据是否正确加载
# 实现单张图片可视化
images, labels = next(iter(train_loader))
img = torchvision.utils.make_grid(images)img = img.numpy().transpose(1, 2, 0)
std = [0.5, 0.5, 0.5]
mean = [0.5, 0.5, 0.5]
img = img * std + mean
print(labels)
plt.imshow(img)
plt.show()
p.s.:其实这里是用cv2.imshow来展示图片,但是我的代码是在jupyter notebook上写的,所以只能通过plt来代替加载。

数据加载成功~
深入探索
可以看到,在load_data函数中
y_train = np.frombuffer(lbpath.read(), np.uint8, offset=8)
这个offset=8又是为啥呢?
我们进入MNIST数据集的官方页面进行查看

通过文档介绍,可以看到
offset的0000-0003是 magic number,所以跳过不读,
offset的0004-0007是items数目
接下来这些代表的就是标签
同理对于
x_train = np.frombuffer(imgpath.read(), np.uint8, offset=16).reshape(len(y_train)

根据刚才的分析方法,也可以明白为什么offset=16了
完整代码
1.直接使用pytorch自带的mnist数据集加载
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import torchvision
from torch.autograd import Variable
from torch.utils.data import DataLoader
import cv2
import matplotlib.pyplot as pltdata_tf = transforms.Compose([transforms.ToTensor(),transforms.Normalize([0.5],[0.5])]
)train_dataset = datasets.MNIST(root='./coding/learning/lrdata/MNIST',train=True,transform=data_tf,download=True)train_loader = torch.utils.data.DataLoader(dataset=train_dataset,batch_size=5,shuffle=True)
# 实现单张图片可视化
images, labels = next(iter(train_loader))
img = torchvision.utils.make_grid(images)img = img.numpy().transpose(1, 2, 0)
std = [0.5, 0.5, 0.5]
mean = [0.5, 0.5, 0.5]
img = img * std + mean
print(labels)
plt.imshow(img)
plt.show()
p.s.:记得自己修改root根目录。
2.使用自定义的数据类加载本地MNIST数据集
import numpy as np
import torch
from torch.utils.data import DataLoader,Dataset
from torchvision import transforms
import gzip
import os
import torchvision
import cv2
import matplotlib.pyplot as pltclass DealDataset(Dataset):"""读取数据、初始化数据"""def __init__(self, folder, data_name, label_name,transform=None):(train_set, train_labels) = load_data(folder, data_name, label_name) # 其实也可以直接使用torch.load(),读取之后的结果为torch.Tensor形式self.train_set = train_setself.train_labels = train_labelsself.transform = transformdef __getitem__(self, index):img, target = self.train_set[index], int(self.train_labels[index])if self.transform is not None:img = self.transform(img)return img, targetdef __len__(self):return len(self.train_set)def load_data(data_folder, data_name, label_name):with gzip.open(os.path.join(data_folder,label_name), 'rb') as lbpath: # rb表示的是读取二进制数据y_train = np.frombuffer(lbpath.read(), np.uint8, offset=8)with gzip.open(os.path.join(data_folder,data_name), 'rb') as imgpath:x_train = np.frombuffer(imgpath.read(), np.uint8, offset=16).reshape(len(y_train), 28, 28)return (x_train, y_train)trainDataset = DealDataset('./coding/learning/lrdata/MNIST/MNIST/raw', "train-images-idx3-ubyte.gz","train-labels-idx1-ubyte.gz",transform=transforms.ToTensor())# 训练数据和测试数据的装载
train_loader = torch.utils.data.DataLoader(dataset=trainDataset,batch_size=10, # 一个批次可以认为是一个包,每个包中含有10张图片shuffle=False,
)# 实现单张图片可视化
images, labels = next(iter(train_loader))
img = torchvision.utils.make_grid(images)img = img.numpy().transpose(1, 2, 0)
std = [0.5, 0.5, 0.5]
mean = [0.5, 0.5, 0.5]
img = img * std + mean
print(labels)
plt.imshow(img)
plt.show()
参考
1.《深度学习入门之Pytorch》- 廖星宇
2.使用Pytorch进行读取本地的MINIST数据集并进行装载
3.顺藤摸瓜-mnist数据集的补充








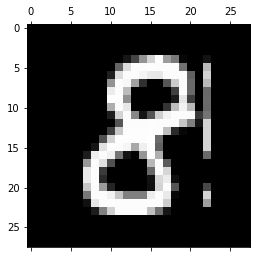

![[转]MNIST机器学习入门](http://wiki.jikexueyuan.com/project/tensorflow-zh/images/mnist9.png)