🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
import torch,math
from pathlib import Path
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import torchvision.datasets as dsets
from torch.utils.data import Dataset, DataLoaderimport torch.nn.functional as F
import torch.nn as NN
torch.__version__Fashion MNIST 介绍
Fashion MNIST数据集 是kaggle上提供的一个图像分类入门级的数据集,其中包含10个类别的70000个灰度图像。如图所示,这些图片显示的是每件衣服的低分辨率(28×28像素)
数据集的下载和介绍:地址
Fashion MNIST的目标是作为经典MNIST数据的替换——通常被用作计算机视觉机器学习程序的“Hello, World”。
MNIST数据集包含手写数字(0-9等)的图像,格式与我们将在这里使用的衣服相同,MNIST只有手写的0-1数据的复杂度不高,所以他只能用来做“Hello, World”
而Fashion MNIST 的由于使用的是衣服的数据,比数字要复杂的多,并且图片的内容也会更加多样性,所以它是一个比常规MNIST稍微更具挑战性的问题。
Fashion MNIST这个数据集相对较小,用于验证算法是否按预期工作。它们是测试和调试代码的好起点。
数据集介绍
分类
0 T-shirt/top
1 Trouser
2 Pullover
3 Dress
4 Coat
5 Sandal
6 Shirt
7 Sneaker
8 Bag
9 Ankle boot格式
fashion-mnist_test.csv
fashion-mnist_train.csv
存储的训练的数据和测试的数据,格式如下:
label是分类的标签 pixel1-pixel784是每一个像素代表的值 因为是灰度图像,所以是一个0-255之间的数值。
为什么是784个像素? 28 * 28 = 784
数据提交
Fashion MNIST不需要我们进行数据的提交,数据集中已经帮助我们将 训练集和测试集分好了,我们只需要载入、训练、查看即可,所以Fashion MNIST 是一个非常好的入门级别的数据集
#指定数据目录
DATA_PATH=Path('./data/')
train = pd.read_csv(DATA_PATH / "fashion-mnist_train.csv");
train.head(10)| label | pixel1 | pixel2 | pixel3 | pixel4 | pixel5 | pixel6 | pixel7 | pixel8 | pixel9 | ... | pixel775 | pixel776 | pixel777 | pixel778 | pixel779 | pixel780 | pixel781 | pixel782 | pixel783 | pixel784 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 5 | 0 | ... | 0 | 0 | 0 | 30 | 43 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 1 | 2 | 0 | 0 | 0 | 0 | ... | 3 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 4 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | 4 | 0 | 0 | 0 | 5 | 4 | 5 | 5 | 3 | 5 | ... | 7 | 8 | 7 | 4 | 3 | 7 | 5 | 0 | 0 | 0 |
| 6 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 14 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 7 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 8 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 2 | 0 | ... | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 9 | 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 203 | 214 | 166 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
10 rows × 785 columns
test = pd.read_csv(DATA_PATH / "fashion-mnist_test.csv");
test.head(10)Out[4]:
| label | pixel1 | pixel2 | pixel3 | pixel4 | pixel5 | pixel6 | pixel7 | pixel8 | pixel9 | ... | pixel775 | pixel776 | pixel777 | pixel778 | pixel779 | pixel780 | pixel781 | pixel782 | pixel783 | pixel784 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 9 | 8 | ... | 103 | 87 | 56 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 34 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 14 | 53 | 99 | ... | 0 | 0 | 0 | 0 | 63 | 53 | 31 | 0 | 0 | 0 |
| 3 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 137 | 126 | 140 | 0 | 133 | 224 | 222 | 56 | 0 | 0 |
| 4 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | 2 | 0 | 0 | 0 | 0 | 0 | 44 | 105 | 44 | 10 | ... | 105 | 64 | 30 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 6 | 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 7 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | ... | 174 | 136 | 155 | 31 | 0 | 1 | 0 | 0 | 0 | 0 |
| 8 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 57 | 70 | 28 | 0 | 2 | 0 | 0 | 0 | 0 | 0 |
10 rows × 785 columns
train.max()Out[5]:
label 9 pixel1 16 pixel2 36 pixel3 226 pixel4 164... pixel780 255 pixel781 255 pixel782 255 pixel783 255 pixel784 170 Length: 785, dtype: int64
ubyte文件标识了数据的格式
其中idx3的数字表示数据维度。也就是图像为3维, idx1 标签维1维。
具体格式详解:MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges
import struct
from PIL import Image with open(DATA_PATH / "train-images-idx3-ubyte", 'rb') as file_object:header_data=struct.unpack(">4I",file_object.read(16))print(header_data)(2051, 60000, 28, 28)
with open(DATA_PATH / "train-labels-idx1-ubyte", 'rb') as file_object:header_data=struct.unpack(">2I",file_object.read(8))print(header_data)(2049, 60000)
如下是训练的图片的二进制格式
[offset] [type] [value] [description]
0000 32 bit integer 0x00000803(2051) magic number
0004 32 bit integer 60000 number of images
0008 32 bit integer 28 number of rows
0012 32 bit integer 28 number of columns
0016 unsigned byte ?? pixel
0017 unsigned byte ?? pixel
........
xxxx unsigned byte ?? pixel有四字节的header_data,故使用unpack_from进行二进制转换时,偏置offset=16
with open(DATA_PATH / "train-images-idx3-ubyte", 'rb') as file_object:raw_img=file_object.read()
img = struct.unpack_from(">784B",raw_img,16)
image = np.asarray(img)
image = image.reshape((28,28))
print(image.shape)
plt.imshow(image,cmap = plt.cm.gray)
plt.show()(28, 28)

with open(DATA_PATH / "train-labels-idx1-ubyte", 'rb') as file_object:raw_img = file_object.read(1)label = struct.unpack(">B",raw_img)print(label)(0,)
这里好像有点错误,显示的错位了,但是我的确是按照格式进行处理的。这种格式处理起来比较复杂,并且数据集中的csv直接给出了每个像素的值,所以这里我们可以直接使用csv格式的数据。
数据加载
为了使用pytorch的dataloader进行数据的加载,需要先创建一个自定义的dataset
class FashionMNISTDataset(Dataset):def __init__(self, csv_file, transform=None):data = pd.read_csv(csv_file)self.X = np.array(data.iloc[:, 1:]).reshape(-1, 1, 28, 28).astype(float)self.Y = np.array(data.iloc[:, 0]);del data; #结束data对数据的引用,节省空间self.len=len(self.X)def __len__(self):#return len(self.X)return self.lendef __getitem__(self, idx):item = self.X[idx]label = self.Y[idx]return (item, label)对于自定义的数据集,只需要实现三个函数:
__init__: 初始化函数主要用于数据的加载,这里直接使用pandas将数据读取为dataframe,然后将其转成numpy数组来进行索引
__len__: 返回数据集的总数,pytorch里面的datalorder需要知道数据集的总数的
__getitem__:会返回单张图片,它包含一个index,返回值为样本及其标签。
创建训练和测试集
train_dataset = FashionMNISTDataset(csv_file=DATA_PATH / "fashion-mnist_train.csv")
test_dataset = FashionMNISTDataset(csv_file=DATA_PATH / "fashion-mnist_test.csv")在使用Pytorch的DataLoader读取数据之前,需要指定一个batch size 这也是一个超参数,涉及到内存的使用量,如果出现OOM的错误则要减小这个数值,一般这个数值都为2的幂或者2的倍数。
#因为是常量,所以大写,需要说明的是,这些常量建议都使用完整的英文单词,减少歧义
BATCH_SIZE=256 # 这个batch 可以在M250的笔记本显卡中进行训练,不会oom我们接着使用dataloader模块来使用这些数据
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,batch_size=BATCH_SIZE,shuffle=True) # shuffle 标识要打乱顺序test_loader = torch.utils.data.DataLoader(dataset=test_dataset,batch_size=BATCH_SIZE,shuffle=False) # shuffle 标识要打乱顺序,测试集不需要打乱查看一下数据
a=iter(train_loader)
data=next(a)
img=data[0][0].reshape(28,28)
data[0][0].shape,img.shape(torch.Size([1, 28, 28]), torch.Size([28, 28]))
plt.imshow(img,cmap = plt.cm.gray)
plt.show()
这回看着就没问题了,是一个完整的图了,所以我们还是用csv吧
创建网络
三层的简单的CNN网络
class CNN(NN.Module):def __init__(self):super(CNN, self).__init__()self.layer1 = NN.Sequential( NN.Conv2d(1, 16, kernel_size=5, padding=2),NN.BatchNorm2d(16), NN.ReLU()) #16, 28, 28self.pool1=NN.MaxPool2d(2) #16, 14, 14self.layer2 = NN.Sequential(NN.Conv2d(16, 32, kernel_size=3),NN.BatchNorm2d(32),NN.ReLU())#32, 12, 12self.layer3 = NN.Sequential(NN.Conv2d(32, 64, kernel_size=3),NN.BatchNorm2d(64),NN.ReLU()) #64, 10, 10self.pool2=NN.MaxPool2d(2) #64, 5, 5self.fc = NN.Linear(5*5*64, 10)def forward(self, x):out = self.layer1(x)#print(out.shape)out=self.pool1(out)#print(out.shape)out = self.layer2(out)#print(out.shape)out=self.layer3(out)#print(out.shape)out=self.pool2(out)#print(out.shape)out = out.view(out.size(0), -1)#print(out.shape)out = self.fc(out)return out以上代码看起来很简单。这里面都是包含的数学的含义。我们只讲pytorch相关的:在函数里使用torch.nn提供的模块来定义各个层,在每个卷积层后使用了批次的归一化和RELU激活并且在每一个操作分组后面进行了pooling的操作(减少信息量,避免过拟合),后我们使用了全连接层来输出10个类别。
view函数用来改变输出值矩阵的形状来匹配最后一层的维度。
cnn = CNN();
#可以通过以下方式验证,没报错说明没问题,
cnn(torch.rand(1,1,28,28))tensor([[-0.9031, 0.1854, -1.2564, 0.0946, -0.9428, 0.9311, -0.4686, -0.5068,-0.3318, -0.6995]], grad_fn=<AddmmBackward>)
#打印下网络,做最后的确认
print(cnn)CNN((layer1): Sequential((0): Conv2d(1, 16, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU())(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(layer2): Sequential((0): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1))(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU())(layer3): Sequential((0): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU())(pool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(fc): Linear(in_features=1600, out_features=10, bias=True) )
从定义模型开始就要指定模型计算的位置,CPU还是GPU,所以需要加另外一个参数
DEVICE=torch.device("cpu")
if torch.cuda.is_available():DEVICE=torch.device("cuda")
print(DEVICE)cuda
#先把网络放到gpu上
cnn=cnn.to(DEVICE)损失函数
多分类因为使用Softmax回归将神经网络前向传播得到的结果变成概率分布 所以使用交叉熵损失。 在pytorch中 NN.CrossEntropyLoss 是将 nn.LogSoftmax() 和 nn.NLLLoss()进行了整合,CrossEntropyLoss ,我们也可以分开来写使用两步计算,这里为了方便直接一步到位
#损失函数也需要放到GPU中
criterion = NN.CrossEntropyLoss().to(DEVICE)优化器
Adam 优化器:简单,暴力,最主要还是懒
#另外一个超参数,学习率
LEARNING_RATE=0.01#优化器不需要放GPU
optimizer = torch.optim.Adam(cnn.parameters(), lr=LEARNING_RATE)开始训练
#另外一个超参数,指定训练批次
TOTAL_EPOCHS=50%%time
#记录损失函数
losses = [];
for epoch in range(TOTAL_EPOCHS):for i, (images, labels) in enumerate(train_loader):images = images.float().to(DEVICE)labels = labels.to(DEVICE)#清零optimizer.zero_grad()outputs = cnn(images)#计算损失函数loss = criterion(outputs, labels)loss.backward()optimizer.step()losses.append(loss.cpu().data.item());if (i+1) % 100 == 0:print ('Epoch : %d/%d, Iter : %d/%d, Loss: %.4f'%(epoch+1, TOTAL_EPOCHS, i+1, len(train_dataset)//BATCH_SIZE, loss.data.item()))Epoch : 1/50, Iter : 100/234, Loss: 0.4569 Epoch : 1/50, Iter : 200/234, Loss: 0.3623 Epoch : 2/50, Iter : 100/234, Loss: 0.2648 Epoch : 2/50, Iter : 200/234, Loss: 0.3044 Epoch : 3/50, Iter : 100/234, Loss: 0.2107 Epoch : 3/50, Iter : 200/234, Loss: 0.3022 Epoch : 4/50, Iter : 100/234, Loss: 0.2583 Epoch : 4/50, Iter : 200/234, Loss: 0.2837 Epoch : 5/50, Iter : 100/234, Loss: 0.2377 Epoch : 5/50, Iter : 200/234, Loss: 0.2422 Epoch : 6/50, Iter : 100/234, Loss: 0.1537 Epoch : 6/50, Iter : 200/234, Loss: 0.2270 Epoch : 7/50, Iter : 100/234, Loss: 0.1485 Epoch : 7/50, Iter : 200/234, Loss: 0.1740 Epoch : 8/50, Iter : 100/234, Loss: 0.3264 Epoch : 8/50, Iter : 200/234, Loss: 0.2096 Epoch : 9/50, Iter : 100/234, Loss: 0.1844 Epoch : 9/50, Iter : 200/234, Loss: 0.1927 Epoch : 10/50, Iter : 100/234, Loss: 0.1343 Epoch : 10/50, Iter : 200/234, Loss: 0.2225 Epoch : 11/50, Iter : 100/234, Loss: 0.1251 Epoch : 11/50, Iter : 200/234, Loss: 0.1789 Epoch : 12/50, Iter : 100/234, Loss: 0.1439 Epoch : 12/50, Iter : 200/234, Loss: 0.1290 Epoch : 13/50, Iter : 100/234, Loss: 0.2017 Epoch : 13/50, Iter : 200/234, Loss: 0.1130 Epoch : 14/50, Iter : 100/234, Loss: 0.0992 Epoch : 14/50, Iter : 200/234, Loss: 0.1736 Epoch : 15/50, Iter : 100/234, Loss: 0.0920 Epoch : 15/50, Iter : 200/234, Loss: 0.1557 Epoch : 16/50, Iter : 100/234, Loss: 0.0914 Epoch : 16/50, Iter : 200/234, Loss: 0.1508 Epoch : 17/50, Iter : 100/234, Loss: 0.1273 Epoch : 17/50, Iter : 200/234, Loss: 0.1982 Epoch : 18/50, Iter : 100/234, Loss: 0.1752 Epoch : 18/50, Iter : 200/234, Loss: 0.1517 Epoch : 19/50, Iter : 100/234, Loss: 0.0586 Epoch : 19/50, Iter : 200/234, Loss: 0.0984 Epoch : 20/50, Iter : 100/234, Loss: 0.1409 Epoch : 20/50, Iter : 200/234, Loss: 0.1286 Epoch : 21/50, Iter : 100/234, Loss: 0.0900 Epoch : 21/50, Iter : 200/234, Loss: 0.1168 Epoch : 22/50, Iter : 100/234, Loss: 0.0755 Epoch : 22/50, Iter : 200/234, Loss: 0.1217 Epoch : 23/50, Iter : 100/234, Loss: 0.0703 Epoch : 23/50, Iter : 200/234, Loss: 0.1383 Epoch : 24/50, Iter : 100/234, Loss: 0.0916 Epoch : 24/50, Iter : 200/234, Loss: 0.0685 Epoch : 25/50, Iter : 100/234, Loss: 0.0947 Epoch : 25/50, Iter : 200/234, Loss: 0.1244 Epoch : 26/50, Iter : 100/234, Loss: 0.0615 Epoch : 26/50, Iter : 200/234, Loss: 0.0478 Epoch : 27/50, Iter : 100/234, Loss: 0.0280 Epoch : 27/50, Iter : 200/234, Loss: 0.0459 Epoch : 28/50, Iter : 100/234, Loss: 0.0213 Epoch : 28/50, Iter : 200/234, Loss: 0.0764 Epoch : 29/50, Iter : 100/234, Loss: 0.0391 Epoch : 29/50, Iter : 200/234, Loss: 0.0899 Epoch : 30/50, Iter : 100/234, Loss: 0.0541 Epoch : 30/50, Iter : 200/234, Loss: 0.0750 Epoch : 31/50, Iter : 100/234, Loss: 0.0605 Epoch : 31/50, Iter : 200/234, Loss: 0.0766 Epoch : 32/50, Iter : 100/234, Loss: 0.1368 Epoch : 32/50, Iter : 200/234, Loss: 0.0588 Epoch : 33/50, Iter : 100/234, Loss: 0.0253 Epoch : 33/50, Iter : 200/234, Loss: 0.0705 Epoch : 34/50, Iter : 100/234, Loss: 0.0248 Epoch : 34/50, Iter : 200/234, Loss: 0.0751 Epoch : 35/50, Iter : 100/234, Loss: 0.0449 Epoch : 35/50, Iter : 200/234, Loss: 0.1006 Epoch : 36/50, Iter : 100/234, Loss: 0.0281 Epoch : 36/50, Iter : 200/234, Loss: 0.0418 Epoch : 37/50, Iter : 100/234, Loss: 0.0547 Epoch : 37/50, Iter : 200/234, Loss: 0.1003 Epoch : 38/50, Iter : 100/234, Loss: 0.0694 Epoch : 38/50, Iter : 200/234, Loss: 0.0340 Epoch : 39/50, Iter : 100/234, Loss: 0.0620 Epoch : 39/50, Iter : 200/234, Loss: 0.1004 Epoch : 40/50, Iter : 100/234, Loss: 0.0588 Epoch : 40/50, Iter : 200/234, Loss: 0.0309 Epoch : 41/50, Iter : 100/234, Loss: 0.0387 Epoch : 41/50, Iter : 200/234, Loss: 0.0136 Epoch : 42/50, Iter : 100/234, Loss: 0.0149 Epoch : 42/50, Iter : 200/234, Loss: 0.0448 Epoch : 43/50, Iter : 100/234, Loss: 0.0076 Epoch : 43/50, Iter : 200/234, Loss: 0.0593 Epoch : 44/50, Iter : 100/234, Loss: 0.0267 Epoch : 44/50, Iter : 200/234, Loss: 0.0308 Epoch : 45/50, Iter : 100/234, Loss: 0.0150 Epoch : 45/50, Iter : 200/234, Loss: 0.0764 Epoch : 46/50, Iter : 100/234, Loss: 0.0221 Epoch : 46/50, Iter : 200/234, Loss: 0.0325 Epoch : 47/50, Iter : 100/234, Loss: 0.0190 Epoch : 47/50, Iter : 200/234, Loss: 0.0359 Epoch : 48/50, Iter : 100/234, Loss: 0.0256 Epoch : 48/50, Iter : 200/234, Loss: 0.0374 Epoch : 49/50, Iter : 100/234, Loss: 0.0198 Epoch : 49/50, Iter : 200/234, Loss: 0.0300 Epoch : 50/50, Iter : 100/234, Loss: 0.0465 Epoch : 50/50, Iter : 200/234, Loss: 0.0558 Wall time: 7min 18s
训练后操作
可视化损失函数
plt.xkcd();
plt.xlabel('Epoch #');
plt.ylabel('Loss');
plt.plot(losses);
plt.show();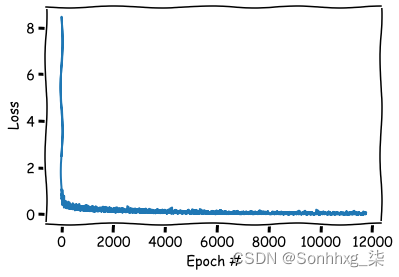
保存模型
torch.save(cnn.state_dict(), "fm-cnn3.pth")
# 加载用这个
#cnn.load_state_dict(torch.load("fm-cnn3.pth"))模型评估
模型评估就是使用测试集对模型进行的评估,应该是添加到训练中进行了,这里为了方便说明直接在训练完成后评估了
cnn.eval()
correct = 0
total = 0
for images, labels in test_loader:images = images.float().to(DEVICE)outputs = cnn(images).cpu()_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum()
print('准确率: %.4f %%' % (100 * correct / total))准确率: 90.0000 %
模型评估的步骤如下:
- 将网络的模式改为eval。
- 将图片输入到网络中得到输出。
- 通过取出one-hot输出的最大值来得到输出的 标签。
- 统计正确的预测值。
进一步优化
%%time
#修改学习率和批次
cnn.train()
LEARNING_RATE=LEARNING_RATE / 10
TOTAL_EPOCHS=20
optimizer = torch.optim.Adam(cnn.parameters(), lr=0.001)
losses = [];
for epoch in range(TOTAL_EPOCHS):for i, (images, labels) in enumerate(train_loader):images = images.float().to(DEVICE)labels = labels.to(DEVICE)#清零optimizer.zero_grad()outputs = cnn(images)#计算损失函数#损失函数直接放到CPU中,因为还有其他的计算loss = criterion(outputs, labels).cpu()loss.backward()optimizer.step()losses.append(loss.data.item());if (i+1) % 100 == 0:print ('Epoch : %d/%d, Iter : %d/%d, Loss: %.4f'%(epoch+1, TOTAL_EPOCHS, i+1, len(train_dataset)//BATCH_SIZE, loss.data.item()))Epoch : 1/20, Iter : 100/234, Loss: 0.0096 Epoch : 1/20, Iter : 200/234, Loss: 0.0124 Epoch : 2/20, Iter : 100/234, Loss: 0.0031 Epoch : 2/20, Iter : 200/234, Loss: 0.0020 Epoch : 3/20, Iter : 100/234, Loss: 0.0013 Epoch : 3/20, Iter : 200/234, Loss: 0.0041 Epoch : 4/20, Iter : 100/234, Loss: 0.0016 Epoch : 4/20, Iter : 200/234, Loss: 0.0023 Epoch : 5/20, Iter : 100/234, Loss: 0.0010 Epoch : 5/20, Iter : 200/234, Loss: 0.0008 Epoch : 6/20, Iter : 100/234, Loss: 0.0017 Epoch : 6/20, Iter : 200/234, Loss: 0.0010 Epoch : 7/20, Iter : 100/234, Loss: 0.0009 Epoch : 7/20, Iter : 200/234, Loss: 0.0009 Epoch : 8/20, Iter : 100/234, Loss: 0.0005 Epoch : 8/20, Iter : 200/234, Loss: 0.0008 Epoch : 9/20, Iter : 100/234, Loss: 0.0005 Epoch : 9/20, Iter : 200/234, Loss: 0.0006 Epoch : 10/20, Iter : 100/234, Loss: 0.0016 Epoch : 10/20, Iter : 200/234, Loss: 0.0011 Epoch : 11/20, Iter : 100/234, Loss: 0.0003 Epoch : 11/20, Iter : 200/234, Loss: 0.0009 Epoch : 12/20, Iter : 100/234, Loss: 0.0010 Epoch : 12/20, Iter : 200/234, Loss: 0.0002 Epoch : 13/20, Iter : 100/234, Loss: 0.0004 Epoch : 13/20, Iter : 200/234, Loss: 0.0005 Epoch : 14/20, Iter : 100/234, Loss: 0.0003 Epoch : 14/20, Iter : 200/234, Loss: 0.0004 Epoch : 15/20, Iter : 100/234, Loss: 0.0002 Epoch : 15/20, Iter : 200/234, Loss: 0.0005 Epoch : 16/20, Iter : 100/234, Loss: 0.0002 Epoch : 16/20, Iter : 200/234, Loss: 0.0007 Epoch : 17/20, Iter : 100/234, Loss: 0.0003 Epoch : 17/20, Iter : 200/234, Loss: 0.0002 Epoch : 18/20, Iter : 100/234, Loss: 0.0004 Epoch : 18/20, Iter : 200/234, Loss: 0.0001 Epoch : 19/20, Iter : 100/234, Loss: 0.0003 Epoch : 19/20, Iter : 200/234, Loss: 0.0005 Epoch : 20/20, Iter : 100/234, Loss: 0.0002 Epoch : 20/20, Iter : 200/234, Loss: 0.0002 Wall time: 2min 21s
可视化一下损失
plt.xkcd();
plt.xlabel('Epoch #');
plt.ylabel('Loss');
plt.plot(losses);
plt.show();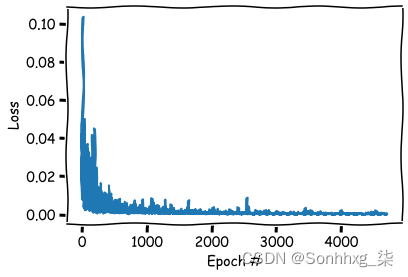
再次进行评估
cnn.eval()
correct = 0
total = 0
for images, labels in test_loader:images = images.float().to(DEVICE)outputs = cnn(images).cpu()_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum()
print('准确率: %.4f %%' % (100 * correct / total))准确率: 91.0000 %
%%time
#修改学习率和批次
cnn.train()
LEARNING_RATE=LEARNING_RATE / 10
TOTAL_EPOCHS=10
optimizer = torch.optim.Adam(cnn.parameters(), lr=0.001)
losses = [];
for epoch in range(TOTAL_EPOCHS):for i, (images, labels) in enumerate(train_loader):images = images.float().to(DEVICE)labels = labels.to(DEVICE)#清零optimizer.zero_grad()outputs = cnn(images)#计算损失函数#损失函数直接放到CPU中,因为还有其他的计算loss = criterion(outputs, labels)loss.backward()optimizer.step()losses.append(loss.cpu().data.item());if (i+1) % 100 == 0:print ('Epoch : %d/%d, Iter : %d/%d, Loss: %.4f'%(epoch+1, TOTAL_EPOCHS, i+1, len(train_dataset)//BATCH_SIZE, loss.data.item()))Epoch : 1/10, Iter : 100/234, Loss: 0.0002 Epoch : 1/10, Iter : 200/234, Loss: 0.0001 Epoch : 2/10, Iter : 100/234, Loss: 0.0001 Epoch : 2/10, Iter : 200/234, Loss: 0.0005 Epoch : 3/10, Iter : 100/234, Loss: 0.0002 Epoch : 3/10, Iter : 200/234, Loss: 0.0001 Epoch : 4/10, Iter : 100/234, Loss: 0.0003 Epoch : 4/10, Iter : 200/234, Loss: 0.0001 Epoch : 5/10, Iter : 100/234, Loss: 0.0002 Epoch : 5/10, Iter : 200/234, Loss: 0.0003 Epoch : 6/10, Iter : 100/234, Loss: 0.0002 Epoch : 6/10, Iter : 200/234, Loss: 0.0002 Epoch : 7/10, Iter : 100/234, Loss: 0.0001 Epoch : 7/10, Iter : 200/234, Loss: 0.0002 Epoch : 8/10, Iter : 100/234, Loss: 0.0008 Epoch : 8/10, Iter : 200/234, Loss: 0.0008 Epoch : 9/10, Iter : 100/234, Loss: 0.0005 Epoch : 9/10, Iter : 200/234, Loss: 0.0002 Epoch : 10/10, Iter : 100/234, Loss: 0.0006 Epoch : 10/10, Iter : 200/234, Loss: 0.0002 Wall time: 1min 9s
plt.xkcd();
plt.xlabel('Epoch #');
plt.ylabel('Loss');
plt.plot(losses);
plt.show();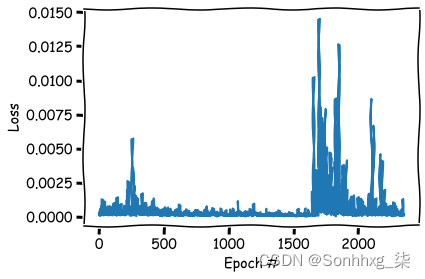
cnn.eval()
correct = 0
total = 0
for images, labels in test_loader:images = images.float().to(DEVICE)outputs = cnn(images).cpu()_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum()
print('准确率: %.4f %%' % (100 * correct / total))准确率: 91.0000 %
损失小了,但是准确率没有提高,这就说明已经接近模型的瓶颈了,如果再要进行优化,就需要修改模型了。另外还有一个判断模型是否到瓶颈的标准,就是看损失函数,最后一次的训练的损失函数明显的没有下降的趋势,只是在震荡,这说明已经没有什么优化的空间了。
通过简单的操作,我们也能够看到Adam优化器的暴力性,我们只要简单的修改学习率就能够达到优化的效果,Adam优化器的使用一般情况下是首先使用0.1进行预热,然后再用0.01进行大批次的训练,最后使用0.001这个学习率进行收尾,再小的学习率一般情况就不需要了。
总结
最后我们再总结一下几个超参数:
BATCH_SIZE: 批次数量,定义每次训练时多少数据作为一批,这个批次需要在dataloader初始化时进行设置,并且需要这对模型和显存进行配置,如果出现OOM有线减小,一般设为2的倍数
DEVICE:进行计算的设备,主要是CPU还是GPU
LEARNING_RATE:学习率,反向传播时使用
TOTAL_EPOCHS:训练的批次,一般情况下会根据损失和准确率等阈值
其实优化器和损失函数也算超参数,这里就不说了

![[转]MNIST机器学习入门](http://wiki.jikexueyuan.com/project/tensorflow-zh/images/mnist9.png)