案例:客户的相关操作(增删改查)
1.分析:
1.搭建环境:
-
创建maven工程,导入相关坐标;
-
配置使用jpa的核心配置文件;
位置;需要配置到类路径下叫做 META-INF的文件夹下
命名:persistence.xml -
编写客户实体类;
-
配置实体类和表,类中属性和表中字段形成映射关系。
2.完成基本CRUD
2.入门代码:
1.导入坐标
<properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><project.hibernate.version>5.0.7.Final</project.hibernate.version></properties><dependencies><!-- junit --><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version><scope>test</scope></dependency><!-- hibernate对jpa的支持包 --><dependency><groupId>org.hibernate</groupId><artifactId>hibernate-entitymanager</artifactId><version>${project.hibernate.version}</version></dependency><!-- c3p0 --><dependency><groupId>org.hibernate</groupId><artifactId>hibernate-c3p0</artifactId><version>${project.hibernate.version}</version></dependency><!-- log日志 --><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version></dependency><!-- Mysql and MariaDB --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.6</version></dependency></dependencies>
2.配置persistence.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<persistence xmlns="http://java.sun.com/xml/ns/persistence" version="2.0"><!--配置persistence-unit节点--><!--名称;事务管理方式(两种:分布式和本地)--><persistence-unit name="myJPA" transaction-type="RESOURCE_LOCAL"><!--配置JPA实现方式(服务提供商)--><provider>org.hibernate.jpa.HibernatePersistenceProvider</provider><!--配置数据库--><properties><property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/><property name="javax.persistence.jdbc.url" value="jdbc:mysql:///ssm"/><property name="javax.persistence.jdbc.user" value="root"/><property name="javax.persistence.jdbc.password" value="root"/><!--配置实现方配置信息--><!--显示sql--><property name="hibernate.show_sql" value="true"/><property name="hibernate.format_sql" value="true"/><!--自动生成表--><!--create:程序运行时创建书籍库表,如果存在会先删除在创建update:运行时创建表,如果存在,不会删除none:不会创建表--><property name="hibernate.hbm2ddl.auto" value="update"/></properties></persistence-unit>
</persistence>
3.使用注解配置对应关系
package com;import javax.persistence.*;/*
配置用户实体类:配置映射关系:1.实体类和表的映射关系(Entity和Table)2.实体类属性和表中字段的映射关系/*注意:主键生成使用哪种策略,底层诗句库必须支持Generation.IDENTITY :mysqlGeneration.SEQUENCE:oracle// 了解Generation.Table:JPA提供,通过生成一张表的形式完成主键自增Generation.AUTO:程序自己看着生成(也是多了一张表)*/@Entity //声明实体类
@Table(name = "account") //配置实体类和表的映射关系 //name即是表的名称public class Account {@Id //声明主键配置
@GeneratedValue(strategy = GenerationType.IDENTITY) //配置主键生成策略(自增)
@Column(name="id") //配置属性和字段的映射关系private int id; //id独一无二,其他普通的只需要直接配置映射关系即可@Column(name="name")private String name;@Column(name="money")private double money;public int getId() {return id;}public void setId(int id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}public double getMoney() {return money;}public void setMoney(double money) {this.money = money;}@Overridepublic String toString() {return "Account{" +"id=" + id +", name='" + name + '\'' +", money=" + money +'}';}
}4.测试
/*jpa操作步骤:1.加载配置文件,根据名称创建工厂;2.通过实体类工厂,获取实体管理器3.获取事务对象,开启事务4.完成增删改5.提交事务或者回滚6.释放资源*/
@Testpublic void save(){// 1.加载配置文件,根据名称创建工厂;// EntityManagerFactory factory = Persistence.createEntityManagerFactory("myJPA");// 2.通过实体类工厂,获取实体管理器// EntityManager manager = factory.createEntityManager();EntityManager manger = JpaUtils.getEntityManger();EntityTransaction tx = manger.getTransaction();// 3.获取事务对象,开启事务tx.begin();//4.增删改 保存Account account = manger.find(Account.class, 1);account.setName("honey");manger.merge(account); //更新// System.out.println(account);//提交事务tx.commit();//关闭资源manger.close();// factory.close();}
代码问题分析:
生成实体类工厂时,内部会卫华很多东西,所以会造成资源浪费。

那么,我们改如何解决??
解决:抽取工具类,以静态代码块的形式创建工厂,产生EntityManager公共对象。
注意,此时,因为总共只有一个工厂,所以不能再关闭工厂资源。
public class JpaUtils {private static EntityManagerFactory factory;static{factory = Persistence.createEntityManagerFactory("myJPA");}public static EntityManager getEntityManger(){return factory.createEntityManager();}}
3.增删改查语句:
1.保存:

2.根据id查询:
find:立即加载(得到的是对象本身)
getReferance:延迟加载(特点:得到的是一个**代理**对象;**什么时候使用什么时候加载(可以通过生成sql语句的时间来验证)**)延迟加载使用较多(不会造成资源浪费)
这里需要传入它的字节码文件

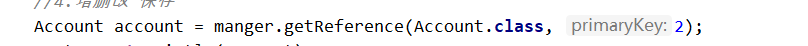
3.删除:
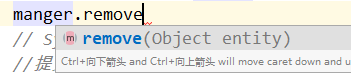
这里使用remove方法。我们可以看到这里面需要传递一个Object对象。所以删除我们需要两步(先根据id查询,返回一个对象,再remove)来完成。
4.更新:
需要三条语句:(先查询,再修改,再使用merge执行更新操作)

总结:

4.jpql查询:
即jpa提供的一种查询方法。
特点:它是面向对象的,即可进行更高级的查询。比如可以用来查询实体类和类中的属性。查询语句和sql相似。
1.查询所有:
注意:jpql不支持 *
//查询全部String jpql="from com.Account"; //需要创建query对象,query才是执行jpql的对象Query query=manger.createQuery(jpql);//发送查询,并封装结果List list=query.getResultList();//遍历获取结果for(Object obj:list){System.out.println(obj);}
简写也是支持的
String jpql="from Account";
2.倒序
//倒序 降序String jpql="from Account order by id desc ";
3.统计查询
//聚合函数 统计结果String jpql="select count(id) from Account ";//需要创建query对象,query才是执行jpql的对象Query query=manger.createQuery(jpql);Object result = query.getSingleResult();System.out.println(result);
4.分页查询:
//分页查询String jpql=" from Account ";//需要创建query对象,query才是执行jpql的对象Query query=manger.createQuery(jpql);query.setFirstResult(0); //代表从0开始查询,不包含0,query.setMaxResults(2); //每次显示两条5.条件查询:
//分页查询String jpql=" from Account where name like ? ";//需要创建query对象,query才是执行jpql的对象Query query=manger.createQuery(jpql);query.setParameter(1,"honey");



![window10c语言下载,[下载备用]Windows 10多国语言包和独立语言包下载](https://img-blog.csdnimg.cn/img_convert/e20d15c2634b43144f206d61c9f8f9d0.png)