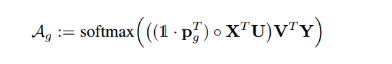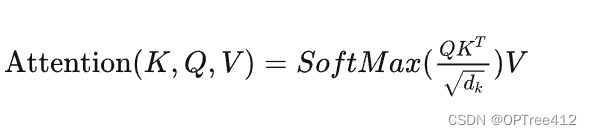1、人类的视觉注意力
从注意力模型的命名方式看,很明显其借鉴了人类的注意力机制,因此,我们首先简单介绍人类视觉的选择性注意力机制。
视觉注意力机制是人类视觉所特有的大脑信号处理机制。人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,也就是一般所说的注意力焦点,而后对这一区域投入更多注意力资源,以获取更多所需要关注目标的细节信息,而抑制其他无用信息。
简单来说,就和我在上一段官方文章中进行的加粗有着异曲同工之妙。人们会把更多的注意力放在ta认为重要需要注意的地方。这样我们更专注于更加重要的细节,减少信息干扰。
这是人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段,是人类在长期进化中形成的一种生存机制,人类视觉注意力机制极大地提高了视觉信息处理的效率与准确性。
那么人类的这种“注意力机制”是否可用在AI中呢?
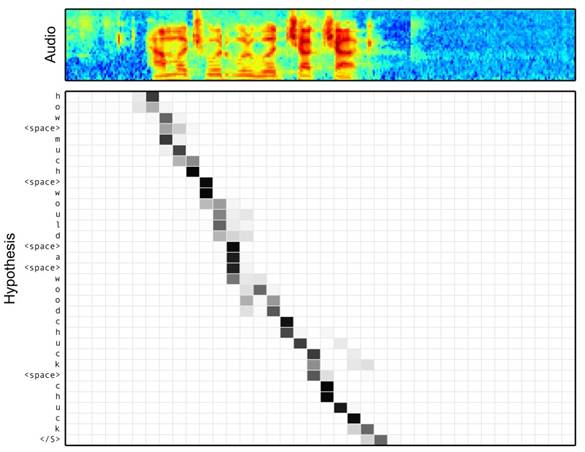
我们来看一下,图片描述(Image Caption)中引入了“注意力机制”后的效果。“图片描述”是深度学习的一个典型应用,即输入一张图片,AI系统根据图片上的内容输出一句描述文字出来。下面看一下“图片描述”的效果,左边是输入原图,下边的句子是AI系统自动生成的描述文字,右边是当AI系统生成划横线单词的时候,对应图片中聚焦的位置区域,如下图:



可以看到,当输出frisbee(飞碟)、dog(狗)等单词时,AI系统会将注意力更多地分配给图片中飞碟、狗的对应位置,以获得更加准确地输出
什么是“注意力机制”?
深度学习中的注意力机制(Attention Mechanism)和人类视觉的注意力机制类似,就是在众多信息中把注意力集中放在重要的点上,选出关键信息,而忽略其他不重要的信息。
回顾Encoder-Decoder框架(编码-解码框架)
目前大多数的注意力模型附着在Encoder-Decoder框架下,所以我们先来了解下这个框架。Encoder-Decoder框架可以看作是一种文本处理领域的研究模式,该框架的抽象表示如下图:
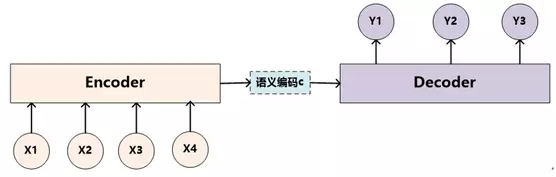
给定输入X,通过Encoder-Decoder框架生成目标Y。其中,Encoder(编码器)就是对输入X进行编码,通过非线性变换转化为中间语义表示C;Decoder(解码器),根据输入X的语义表示C和之前已生成的历史信息生成目标信息。
注意力机制
本文开头讲到的人类视觉注意力机制,它在处理信息时注意力的分布是不一样的。而Encoder-Decoder框架将输入X都编码转化为语义表示C,这样就会导致所有输入的处理权重都一样,没有体现出注意力集中,因此,也可看成是“分心模型”。
为了能体现注意力机制,将语义表示C进行扩展,用不同的C来表示不同注意力的集中程度,每个C的权重不一样。那么扩展后的Encoder-Decoder框架变为:
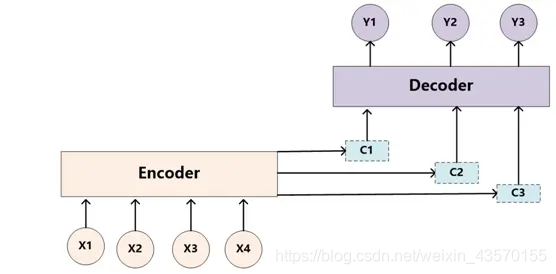
下面通过一个英文翻译中文的例子来说明“注意力模型”。
例如输入的英文句子是:Tom chase Jerry,目标的翻译结果是“汤姆追逐杰瑞”。那么在语言翻译中,Tom, chase,Jerry这三个词对翻译结果的影响程度是不同的,其中,Tom,Jerry是主语、宾语,是两个人名,chase是谓语,是动作。
那么这三个词的影响程度大小顺序分别是Jerry>Tom>chase,例如(Tom,0.3),(Chase,0.2), (Jerry,0.5),不同的影响程度代表AI模型在翻译时分配给不同单词的注意力大小,即分配的概率大小。
使用上图扩展了Ci的Encoder-Decoder框架,则翻译Tom chase Jerry的过程如下。
生成目标句子单词的过程如下面的形式:
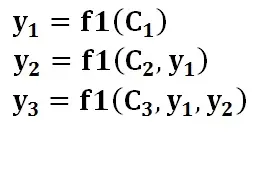
其中,f1是Decoder(解码)的非线性变换函数
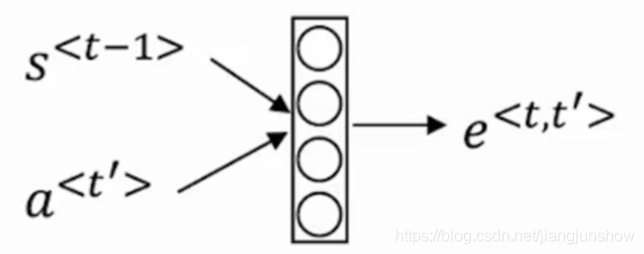
每个Ci对应着不同的源单词的注意力分配概率分布,计算如下面的形式:

其中,f2函数表示Encoder(编码)节点中对输入英文单词的转换函数,g函数代表Encoder(编码)表示合成整个句子中间语义表示的变换函数,一般采用加权求和的方式,如下式:
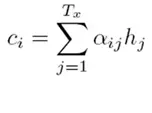
其中aij表示权重,hj表示Encoder的转换函数,即h1=f2(“Tom”),h2=f2(“Chase”),h3=f2(“Jerry”),Tx表示输入句子的长度
当i是“汤姆”时,则注意力模型权重aij分别是0.6, 0.2, 0.2。那么这个权重是如何得到的呢?
aij可以看做是一个概率,反映了hj对ci的重要性,可使用softmax来表示:
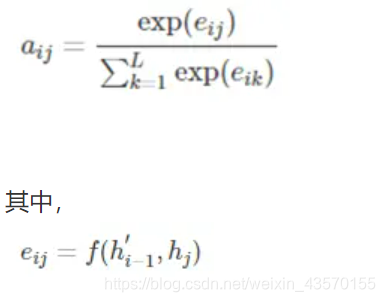
这里的f表示一个匹配度的打分函数,可以是一个简单的相似度计算,也可以是一个复杂的神经网络计算结果。在这里,由于在计算ci时还没有h’i,因此使用最接近的h’i-1代替。当匹配度越高,则aij的概率越大。
因此,得出aij的过程如下图:
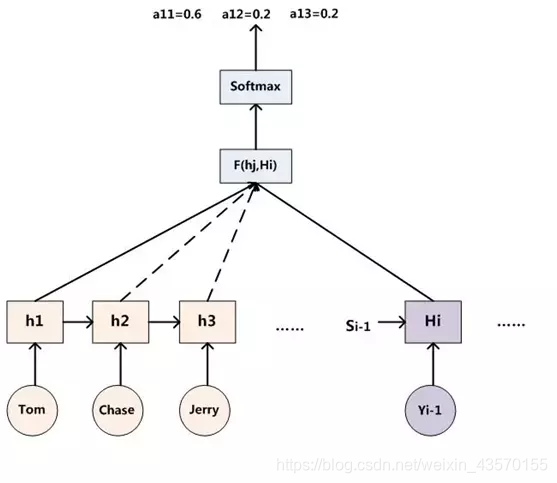
其中,hi表示Encoder转换函数,F(hj,Hi)表示预测与目标的匹配打分函数
将以上过程串起来,则注意力模型的结构如下图所示:
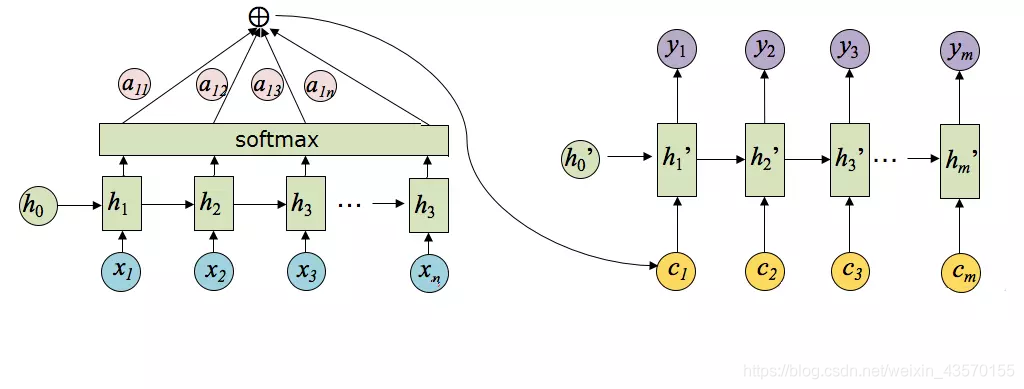
其中,hi表示Encoder阶段的转换函数,ci表示语义编码,h’i表示Decoder阶段的转换函数。
以上介绍的就是经典的Soft-Attention模型,而注意力模型按不同维度还有其它很多分类。
Attention模型分类
按注意力的可微性,可分为:
- Hard-Attention,就是0/1问题,某个区域要么被关注,要么不关注,这是一个不可微的注意力;
- Soft-Attention,[0,1]间连续分布问题,用0到1的不同分值表示每个区域被关注的程度高低,这是一个可微的注意力。
按照认知神经学中的注意力,可以为:
- 聚焦式(focus)注意力:自上而下的有意识的注意力,主动注意——是指有预定目的、依赖任务的、主动有意识地聚焦于某一对象的注意力;
- 显著性(saliency-based)注意力:自下而上的有意识的注意力,被动注意——基于显著性的注意力是由外界刺激驱动的注意,不需要主动干预,也和任务无关;可以将max-pooling和门控(gating)机制来近似地看作是自下而上的基于显著性的注意力机制。
在人工神经网络中,注意力机制一般就特指聚焦式注意力。
以上 内容参考转载于:https://my.oschina.net/u/876354/blog/3061863
以下内容参考于莫烦python。
切换注意力
为了理解一个事物,做一项购买决定之前,我们其实都是经历了一段思考, 这段思考时期,有短有长,有时候短到可能我们都没有意识到。而在这短暂的思考期间, 借助我们眼球的运动能力,我们可以不断切换要注意的地方, 即使在观察一段静止图片时或浏览静态网页时,都是如此。每次注意到的不同地点, 让我们能产生新的认知,或者对先有认知有更深程度的理解。人类通过在时间轴上, 眼球的移动,收集随时间变化的注意力,如果换一个说法,我想我会说: 这是对注意力的注意力。第一份注意力,产生了第一份认知理解,基于第一份理解, 我们决定第二次注意的位置,以此类推,直到我们达到完整的掌控和理解,做出对应的决策。
在语言上,也是一样,我们举个例子。

如果哪天有一位异性好友对你表白的回复是:“你人很好,很感谢有你的陪伴”。情场新手刚上车,第一眼看起来,好像是这个女生再夸我,激动得我眼泪要掉下来。带着这句话,让我一天都有好心情。可是当我吃完饭,再回想起她说我“人很好”,“感谢”我,这句话怎么听起来怪怪的。睡前我好像想明白了,她虽然说我好,但是这只是发好人卡的前奏,重点在后面,她在用“感谢陪伴”,委婉拒绝我!所以我使用了三次注意力,每次注意的时候都是基于上次注意后的理解。通过反复地回忆、琢磨才能研究透一句话背后的意思。
所以,如果深刻理解是通过注意力产生的,那么肯定也不只使用了一次注意力。这种思路正是目前AI技术发展的方向之一,利用注意力产生理解,而且使用的也是多次注意力的转换。
我们之前提到的模型,在通读语言后产生一个对句子全局的理解(句向量),然后再分别将 全局理解 和部分被注意的 局部理解 效应叠加,作为我后续任务的基础,比如基于全局和局部生成回复信息。但是这并不是我们刚刚提到的在注意力上再注意。所以聪明的科研人员创造了另一种方法,他们说,根本没有什么全局理解,我们用一次一次的注意力产生的局部理解就能解决这个问题。我们再来重复一遍上述发好人卡的过程,不过这一次,我们站在机器的角度,看它是怎么注意的。
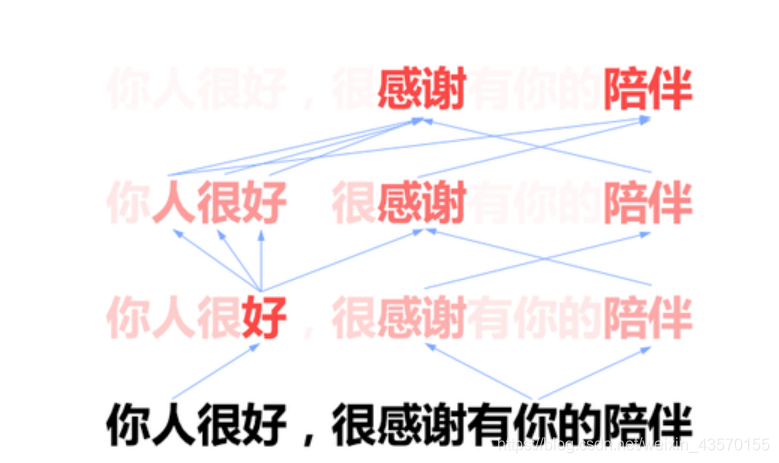
模型第一次会通常会注意到一些局部的信息,在分散的地域分析有哪些有趣的词汇可以做出贡献,它觉得有趣的词可能是“好”, “感谢”, “陪伴”,如果单看这些注意到的东西,我可能以为女生在表扬我,我十分有戏。不过模型基于注意到的信息,再次注意。这次,模型开始觉得不对劲了,她说我好,还感谢我的陪伴,她到底想说啥? 经过第三次注意,模型意识到她可能只是想先扬后抑,这句话实际是一种转折,重点在后半句。所以模型也可以经过几次注意,不同层级的注意力带来的是不同层级上的理解。越是后面的注意,就是越深度的思考。如果熟悉自然语言模型的同学此刻应该也想到了,这就是 Transformer 模型。
Transformer 模型
首先我们要知道,在理解我们句子的时候,可以不仅仅只过目一遍,我还可以像多层RNN一样,在理解的基础上再次理解。 只是这次,不会像RNN那样,每次都对通句加深理解,而是一遍又一遍地注意到句子的不同部分,提炼对句子更深层的理解。这就是Transformer 模型的思想精髓。如下图
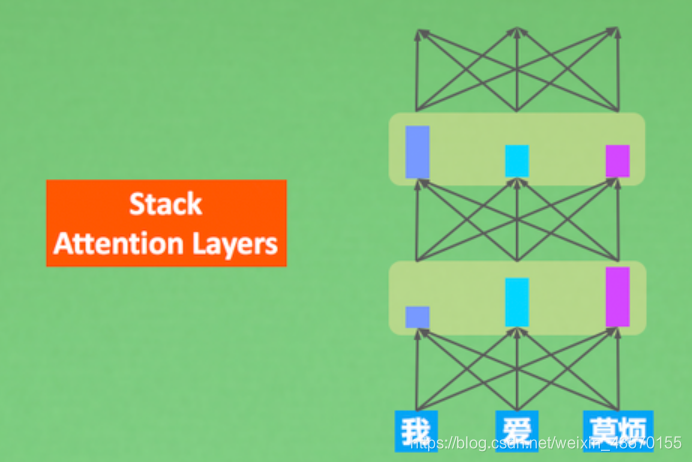
Transformer 这种模型是一种 seq2seq 模型,是为了解决生成语言的问题。它也有一个 Encoder-Decoder 结构,只是它不像RNN中的 Encoder-Decoder。
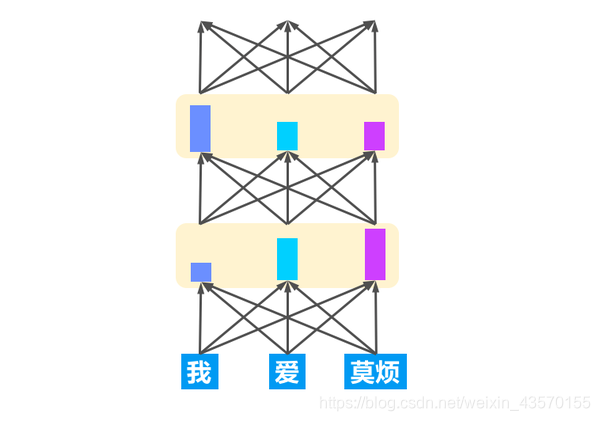
Transformer 模型可视化大概如图,它使用的是一个个注意力矩阵来表示在不同位置的注意力强度。通过控制强度来控制信息通道的阀门大小。即使这样,研究者还觉得不够。假如这种情况是一个人看多次,我们何不尝试让多个人一起看多次呢?这样会不会更有效率,变成三个臭皮匠赛过诸葛亮?
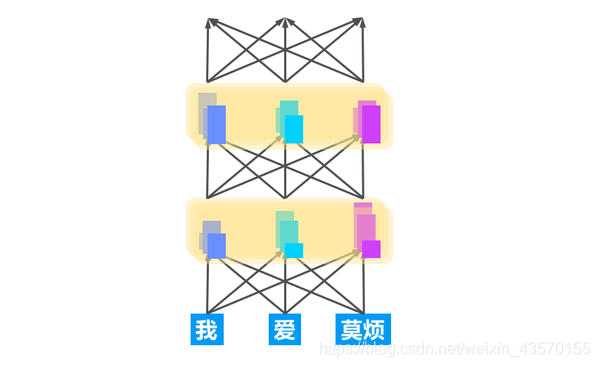
结果就有了这样的形态,多个人同时观察一句话,分别按自己的意见提出该注意哪里, 然后再汇总自己通过自己的注意力得到的结论,再进入下一轮注意力。 研究表明,这种注意力方案的确可以带给我们更深层的句意理解。
Transformer 的核心点,它的 attention 是怎么做的呢?
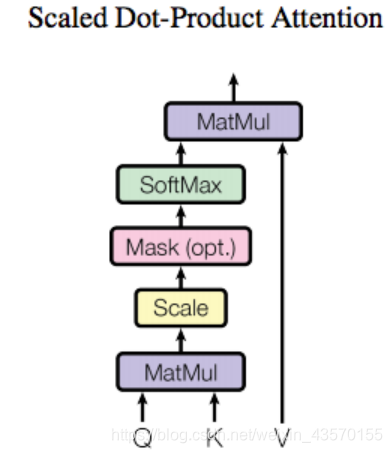
上面是论文中的原图,看懵逼了?没问题,我们来抽象化。它关注的有三种东西,Query, Key, Value。 其实做这件事的核心目的是快速准确地找到核心内容,换句话说:用我的搜索(Query)找到关键内容(Key),在关键内容上花时间花功夫(Value)。
例子:
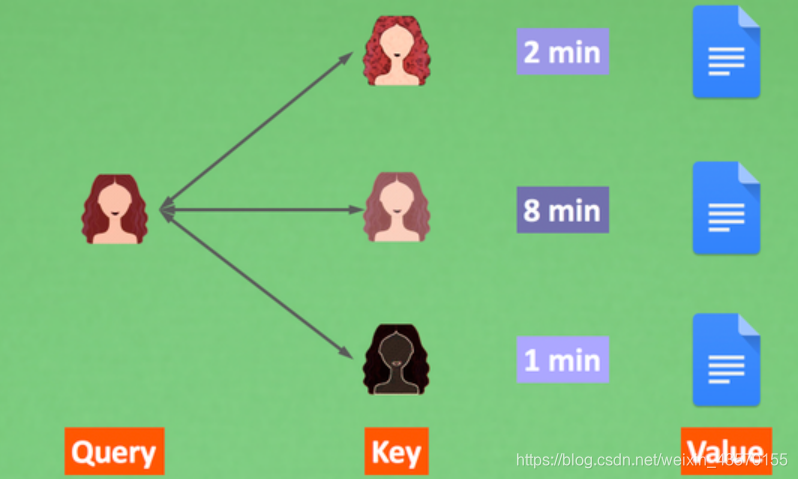
想象这是一个相亲画面,我有我心中有个喜欢女孩的样子,我会按照这个心目中的形象浏览各女孩的照片,如果一个女生样貌很像我心中的样子,我就注意这个人, 并安排一段稍微长一点的时间阅读她的详细材料,反之我就安排少一点时间看她的材料。这样我就能将注意力放在我认为满足条件的候选人身上了。 我心中女神的样子就是Query,我拿着它(Query)去和所有的候选人(Key)做对比,得到一个要注意的程度(attention), 根据这个程度判断我要花多久时间仔细阅读候选人的材料(Value)。 这就是Transformer的注意力方式。
为了增强“注意力”的能力,Transformer还做了一件事:从注意力修改成了注意力注意力注意力注意力。这叫做多头注意力(Multi-Head Attention)。 论文中的原图长这样。
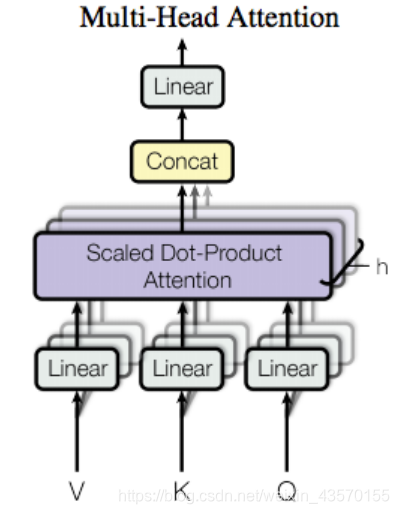
解释:
其实“多头注意力”指的就是在同一层做注意力计算的时候,我多搞几次注意力。有点像我同时找了多个人帮我注意一下,这几个人帮我一轮一轮注意+理解之后, 我在汇总所有人的理解,统一判断。有点“三个臭皮匠赛过诸葛亮”的意思。
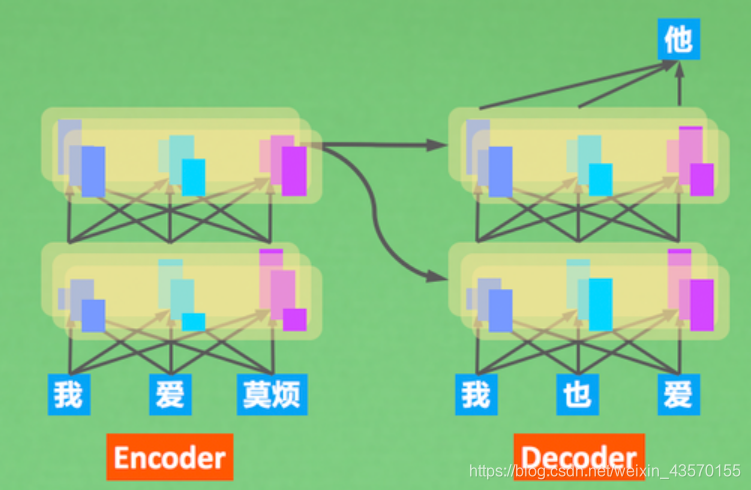
最后一个我想提到的重点是Decoder怎么样拿到Encoder对句子的理解的?或者Encoder是怎么样引起Decoder的注意的? 在理解这个问题之前,我们需要知道Encoder和Decoder都存在注意力,Encoder里的的注意力叫做自注意力(self-attention), 因为Encoder在这个时候只是自己和自己玩,自己捣鼓一句话的意思。而Decoder说:你把你捣鼓到的意思借我参考一下吧。 这时Self-attention在transformer中的意义才被凸显出来。

在Decoding时,decoder会向encoder借一下Key和Value,Decoder自己可以提供Query(已经预测出来的token)。使用我们刚刚提到的K,Q,V结合方式计算。 不过这张图里面还有些细节没有提到,比如 Decoder 先要经过Masked attention再和encoder的K,V结合,然后还有有一个feed forward计算,还要计算残差。