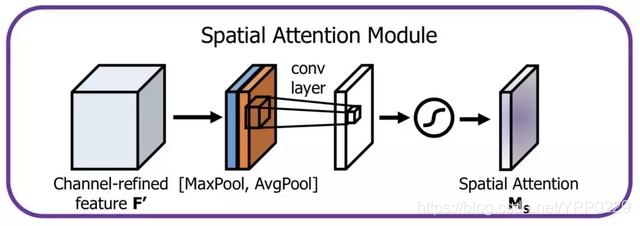
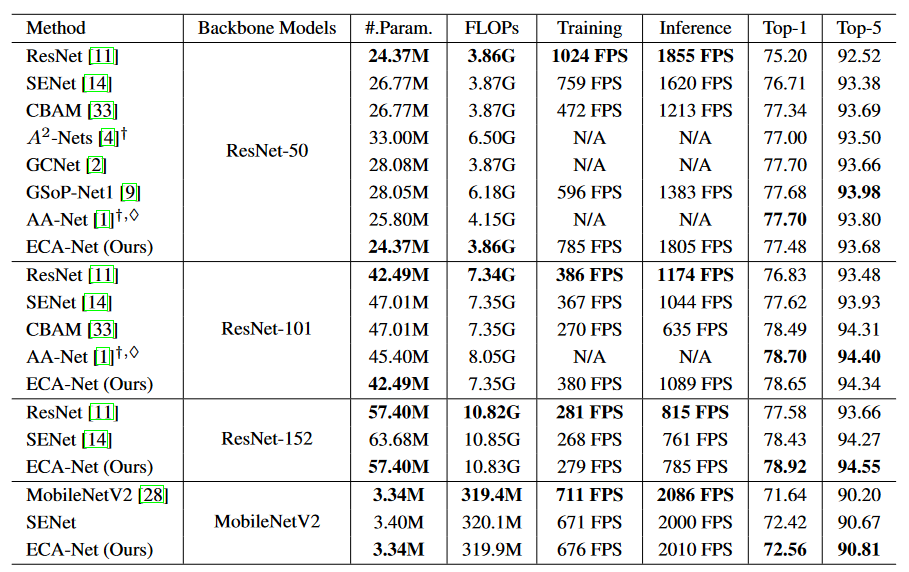
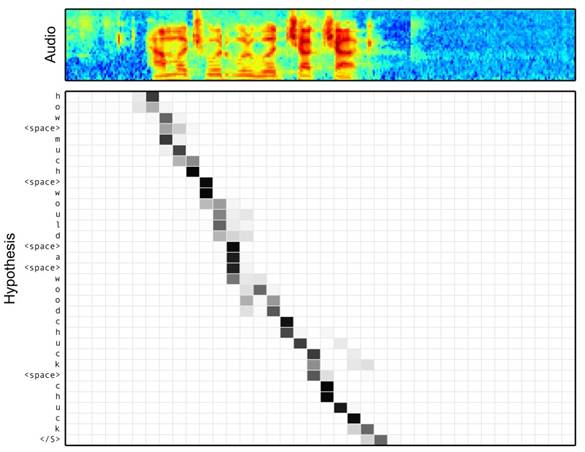
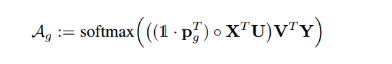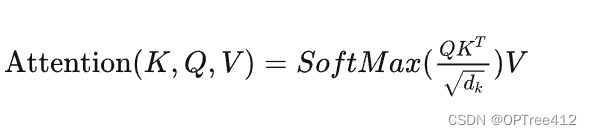- 前言
- attention的内部结构是什么?
前言
这里学习的注意力模型是我在研究image caption过程中的出来的经验总结,其实这个注意力模型理解起来并不难,但是国内的博文写的都很不详细或说很不明确,我在看了 attention-mechanism后才完全明白。得以进行后续工作。
这里的注意力模型是论文 Show,Attend and Tell:Neural Image Caption Generation with Visual Attention里设计的,但是注意力模型在大体上来讲都是相通的。
先给大家介绍一下我需要注意力模型的背景。

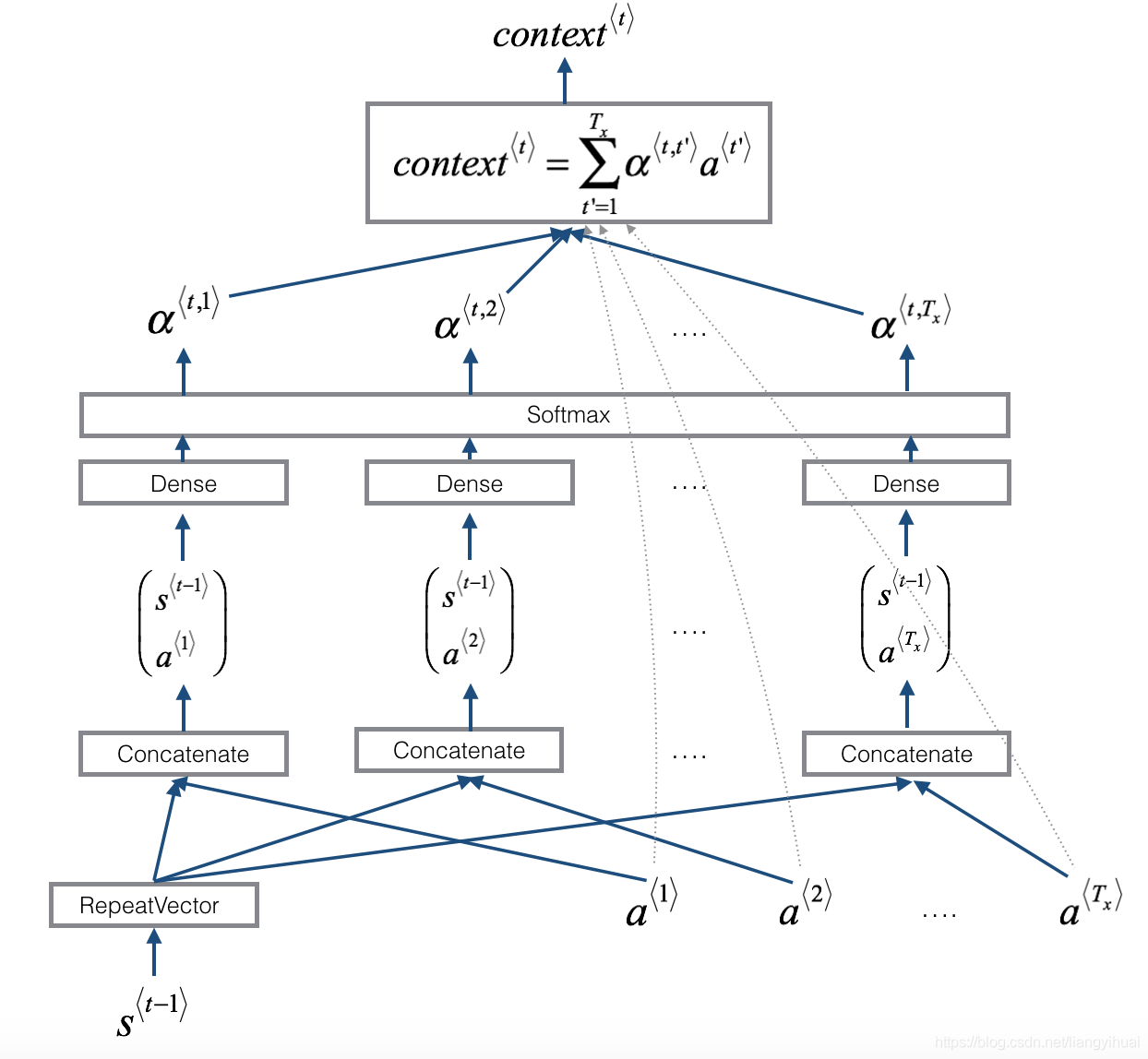
I是图片信息矩阵也就是[224,224,3],通过前面的cnn也就是所谓的sequence-sequence模型中的encoder,我用的是vgg19,得到a,这里的a其实是[14*14,512]=[196,512],很形象吧,代表的是图片被分成了这么多个区域,后面就看我们单词注意在哪个区域了,大家可以先这么泛泛理解。通过了本文要讲的Attention之后得到z。这个z是一个区域概率,也就是当前的单词在哪个图像区域的概率最大。然后z组合单词的embedding去训练。
好了,先这么大概理解一下这张图就好。下面我们来详细解剖attention,附有代码~
attention的内部结构是什么?

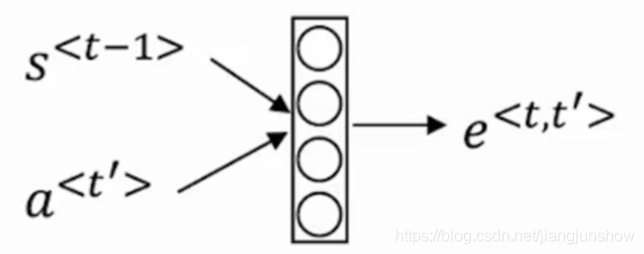
这里的c其实一个隐含输入,计算方式如下
首先我们这么个函数:
def _get_initial_lstm(self, features):with tf.variable_scope('initial_lstm'):features_mean = tf.reduce_mean(features, 1)w_h = tf.get_variable('w_h', [self.D, self.H], initializer=self.weight_initializer)b_h = tf.get_variable('b_h', [self.H], initializer=self.const_initializer)h = tf.nn.tanh(tf.matmul(features_mean, w_h) + b_h)w_c = tf.get_variable('w_c', [self.D, self.H], initializer=self.weight_initializer)b_c = tf.get_variable('b_c', [self.H], initializer=self.const_initializer)c = tf.nn.tanh(tf.matmul(features_mean, w_c) + b_c)return c, h上面的c你可以暂时不用管,是lstm中的memory state,输入feature就是通过cnn跑出来的a,我们暂时考虑batch=1,就认为这个a是一张图片生成的。所以a的维度是[1,196,512],y向量代表的就是feature。
下面我们打开这个黑盒子来看看里面到底是在做什么处理。

上图中可以看到
这里的tanh不能替换成ReLU函数,一旦替换成ReLU函数,因为有很多负值就会消失,会很影响后面的结果,会造成最后Inference句子时,不管你输入什么图片矩阵的到的句子都是一样的。不能随便用激活函数!!!ReLU是能解决梯度消散问题,但是在这里我们需要负值信息,所以只能用tanh
c和y在输入到tanh之前要做个全连接,代码如下。
w = tf.get_variable('w', [self.H, self.D], initializer=self.weight_initializer)b = tf.get_variable('b', [self.D], initializer=self.const_initializer)w_att = tf.get_variable('w_att', [self.D, 1], initializer=self.weight_initializer)h_att = tf.nn.relu(features_proj + tf.expand_dims(tf.matmul(h, w), 1) + b) # (N, L, D)
这里的features_proj是feature已经做了全连接后的矩阵。并且在上面计算h_att中你可以看到一个矩阵的传播机制,也就是relu函数里的加法。features_proj和后面的那个维度是不一样的。
def _project_features(self, features):with tf.variable_scope('project_features'):w = tf.get_variable('w', [self.D, self.D], initializer=self.weight_initializer)features_flat = tf.reshape(features, [-1, self.D])features_proj = tf.matmul(features_flat, w) features_proj = tf.reshape(features_proj, [-1, self.L, self.D])return features_proj然后要做softmax了,这里有个点,因为上面得到的m的维度是[1,196,512],1是代表batch数量。经过softmax后想要得到的是维度为[1,196]的矩阵也就是每个区域的注意力权值。所以
out_att = tf.reshape(tf.matmul(tf.reshape(h_att, [-1, self.D]), w_att), [-1, self.L]) # (N, L)
alpha = tf.nn.softmax(out_att) 最后计算s就是一个相乘。
context = tf.reduce_sum(features * tf.expand_dims(alpha, 2), 1, name='context') #(N, D)这里也是有个传播的机制,features维度[1,196,512],后面那个维度[1,196,1]。
最后给个完整的注意力模型代码。
def _attention_layer(self, features, features_proj, h, reuse=False):with tf.variable_scope('attention_layer', reuse=reuse):w = tf.get_variable('w', [self.H, self.D], initializer=self.weight_initializer)b = tf.get_variable('b', [self.D], initializer=self.const_initializer)w_att = tf.get_variable('w_att', [self.D, 1], initializer=self.weight_initializer)h_att = tf.nn.relu(features_proj + tf.expand_dims(tf.matmul(h, w), 1) + b) # (N, L, D)out_att = tf.reshape(tf.matmul(tf.reshape(h_att, [-1, self.D]), w_att), [-1, self.L]) # (N, L)alpha = tf.nn.softmax(out_att) context = tf.reduce_sum(features * tf.expand_dims(alpha, 2), 1, name='context') #(N, D)return context, alpha 如果大家想研究整个完整的show-attend-tell模型,可以去看看github链接