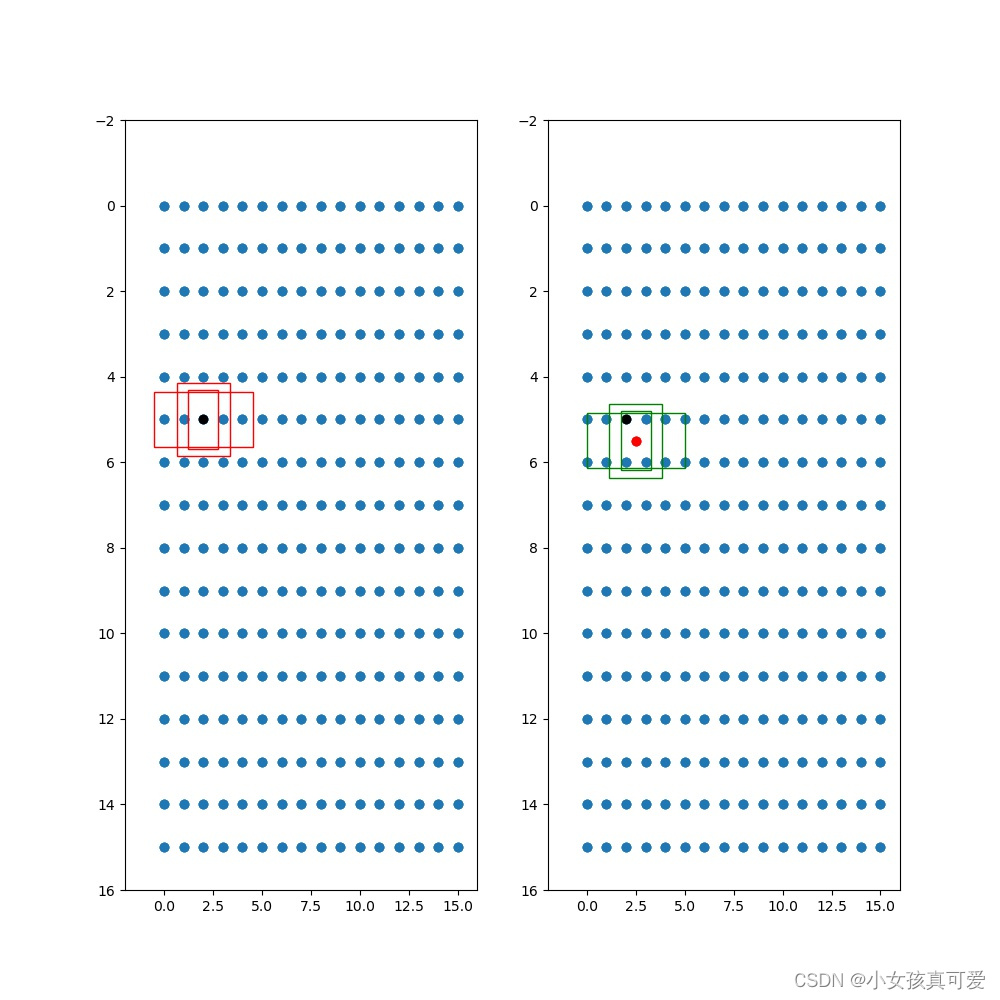
keras-yolov3在训练自定义图片集之前,设置合理的yolo_anchors.txt值,有利于模型训练的收敛,一般都带有默认的参数如下:
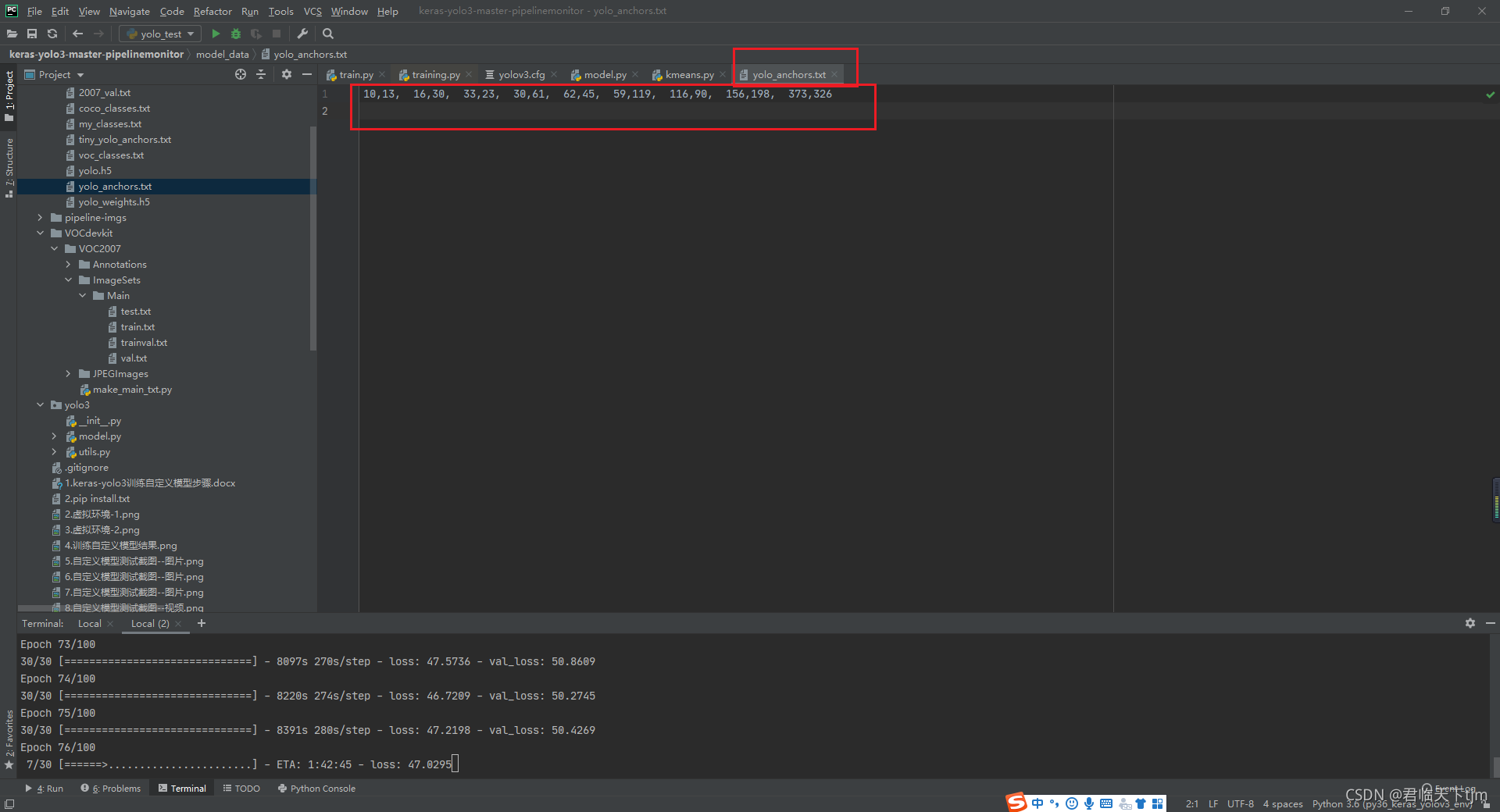
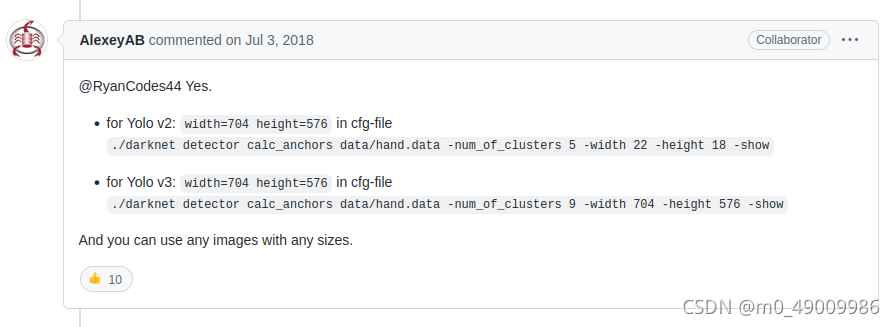
在实际项目中,yolo_anchors的值可以根据kmeans.py计算获取,通过聚类得到最佳anchors数据;
kmeans.py执行后即可得到合适的yolo_anchors参数值,代码如下:
import numpy as npclass YOLO_Kmeans:def __init__(self, cluster_number, filename):self.cluster_number = cluster_numberself.filename = "2007_train.txt"def iou(self, boxes, clusters): # 1 box -> k clustersn = boxes.shape[0]k = self.cluster_numberbox_area = boxes[:, 0] * boxes[:, 1]box_area = box_area.repeat(k)box_area = np.reshape(box_area, (n, k))cluster_area = clusters[:, 0] * clusters[:, 1]cluster_area = np.tile(cluster_area, [1, n])cluster_area = np.reshape(cluster_area, (n, k))box_w_matrix = np.reshape(boxes[:, 0].repeat(k), (n, k))cluster_w_matrix = np.reshape(np.tile(clusters[:, 0], (1, n)), (n, k))min_w_matrix = np.minimum(cluster_w_matrix, box_w_matrix)box_h_matrix = np.reshape(boxes[:, 1].repeat(k), (n, k))cluster_h_matrix = np.reshape(np.tile(clusters[:, 1], (1, n)), (n, k))min_h_matrix = np.minimum(cluster_h_matrix, box_h_matrix)inter_area = np.multiply(min_w_matrix, min_h_matrix)result = inter_area / (box_area + cluster_area - inter_area)return resultdef avg_iou(self, boxes, clusters):accuracy = np.mean([np.max(self.iou(boxes, clusters), axis=1)])return accuracydef kmeans(self, boxes, k, dist=np.median):box_number = boxes.shape[0]distances = np.empty((box_number, k))last_nearest = np.zeros((box_number,))np.random.seed()clusters = boxes[np.random.choice(box_number, k, replace=False)] # init k clusterswhile True:distances = 1 - self.iou(boxes, clusters)current_nearest = np.argmin(distances, axis=1)if (last_nearest == current_nearest).all():break # clusters won't changefor cluster in range(k):clusters[cluster] = dist( # update clustersboxes[current_nearest == cluster], axis=0)last_nearest = current_nearestreturn clustersdef result2txt(self, data):f = open("yolo_anchors.txt", 'w')row = np.shape(data)[0]for i in range(row):if i == 0:x_y = "%d,%d" % (data[i][0], data[i][1])else:x_y = ", %d,%d" % (data[i][0], data[i][1])f.write(x_y)f.close()def txt2boxes(self):f = open(self.filename, 'r')dataSet = []for line in f:infos = line.split(" ")length = len(infos)for i in range(1, length):width = int(infos[i].split(",")[2]) - \int(infos[i].split(",")[0])height = int(infos[i].split(",")[3]) - \int(infos[i].split(",")[1])dataSet.append([width, height])result = np.array(dataSet)f.close()return resultdef txt2clusters(self):all_boxes = self.txt2boxes()result = self.kmeans(all_boxes, k=self.cluster_number)result = result[np.lexsort(result.T[0, None])]self.result2txt(result)print("K anchors:\n {}".format(result))print("Accuracy: {:.2f}%".format(self.avg_iou(all_boxes, result) * 100))if __name__ == "__main__":cluster_number = 16 # 类别数量filename = "2007_train.txt"kmeans = YOLO_Kmeans(cluster_number, filename)kmeans.txt2clusters()
替换原有默认的yolo_anchors.txt文件,再进行模型训练。
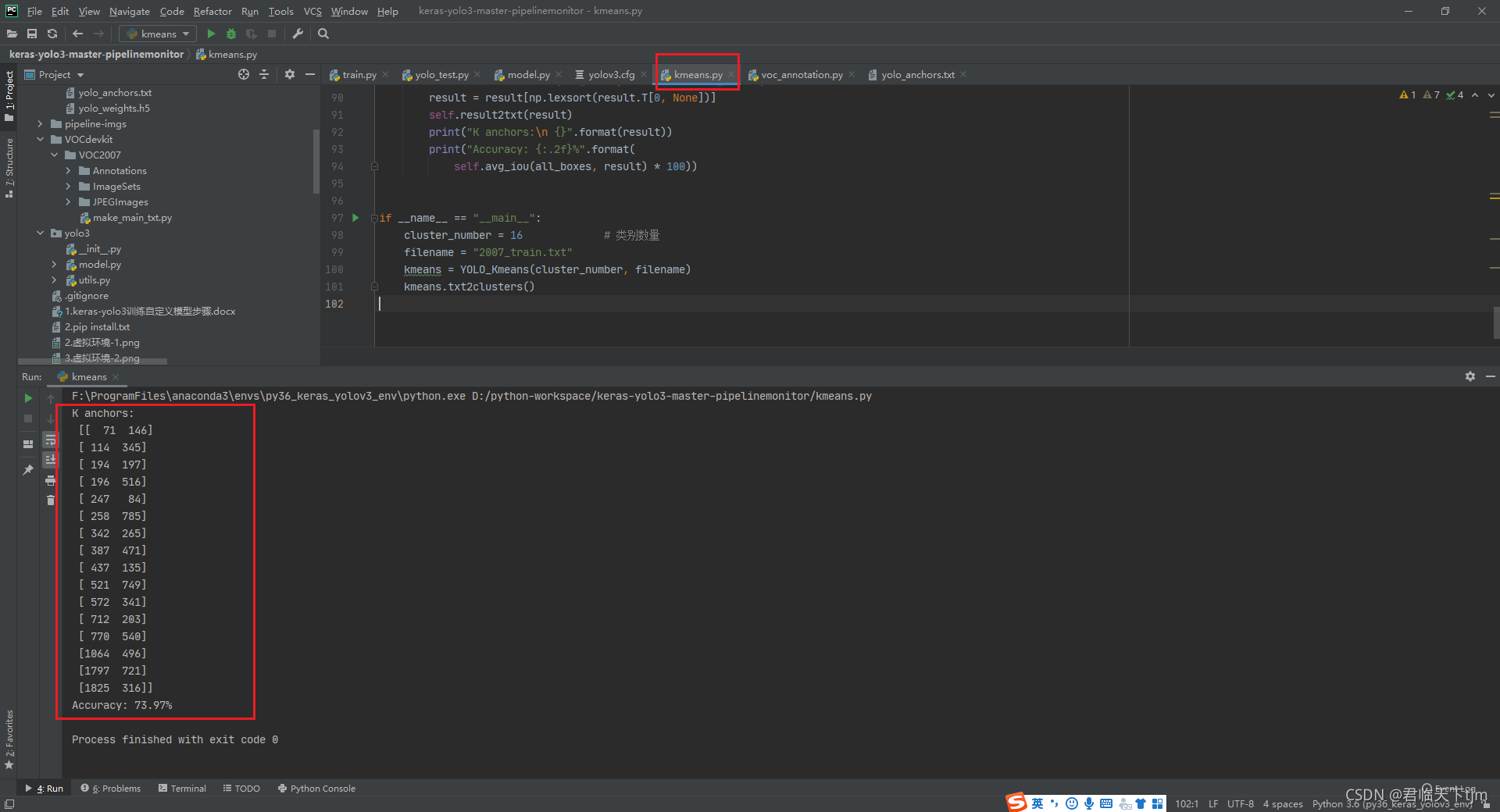
注意:执行kmeans.py的时机,需要在模型训练之前,模型训练之前需要先写入新的anchors的值,后续博客再做yolov3全流程开发补充。