注明:本文为原创文章,转载请注明出处。参考文章见本文末尾。
wireshark是一个非常好用的抓包工具,本文根据平时抓包经验,对之前wireshark抓包的一些常见知识点进行了整理。
有不当之处,欢迎指正
1.SYN,FIN会消耗一个序号,单独的ACK不消耗序号
2.WIN表示可以接收数据的滑动窗口(接收缓冲区)是多少,如果A发到B的包的win为0,就是A告诉B说我现在滑动窗口为0了,饱了,你不要再发给我了,就说明A端环境有压力
3.ACK可以理解为应答。A发给B的ack是告诉B,我已收到你发的数据包,收到ack号这里了,你下次要发seq为ack号的给我
4.连续传输的时候,且无乱序,无丢包的情况下:上一个包的seq + len = 下一个包的 seq,如:
包55976:
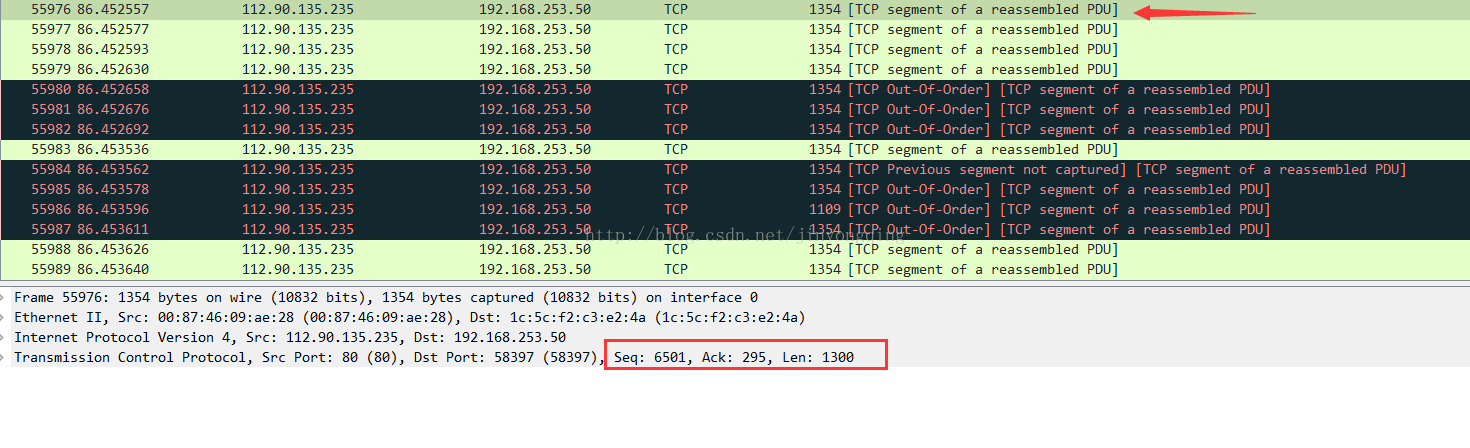
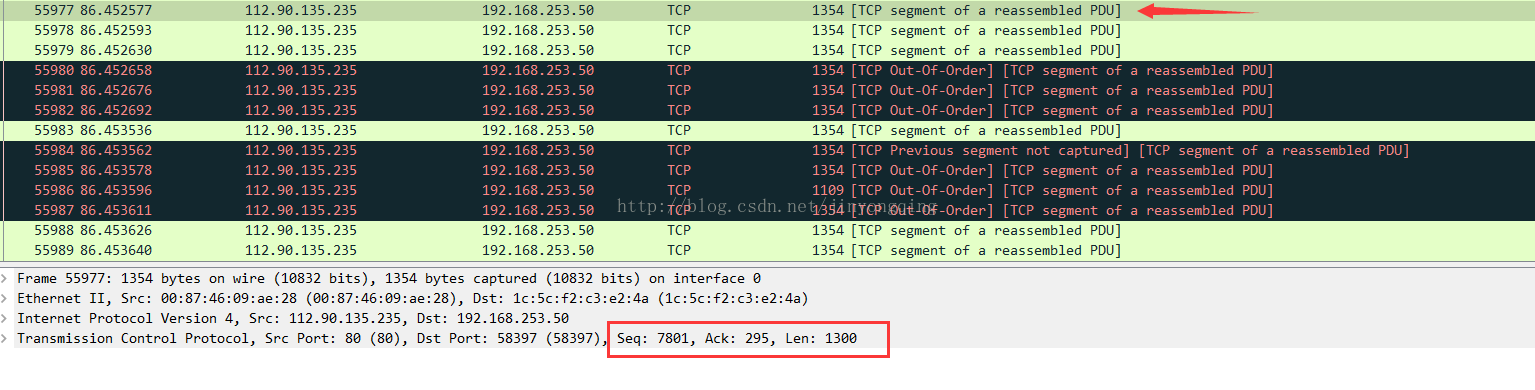
7801(55977的seq ) = 6501(55976的seq) + 1300(55976的len)
5.[TCP Previous segment not captured]
在TCP传输过程中,同一台主机发出的数据段应该是连续的,即后一个包的Seq号等于前一个包的Seq Len(三次握手和四次挥手是例外)。
如果Wireshark发现后一个包的Seq号大于前一个包的Seq Len,就知道中间缺失了一段数据。中间缺失的数据有的时候是由于乱序导致的,在后面的包中还可以找到
如:包55974
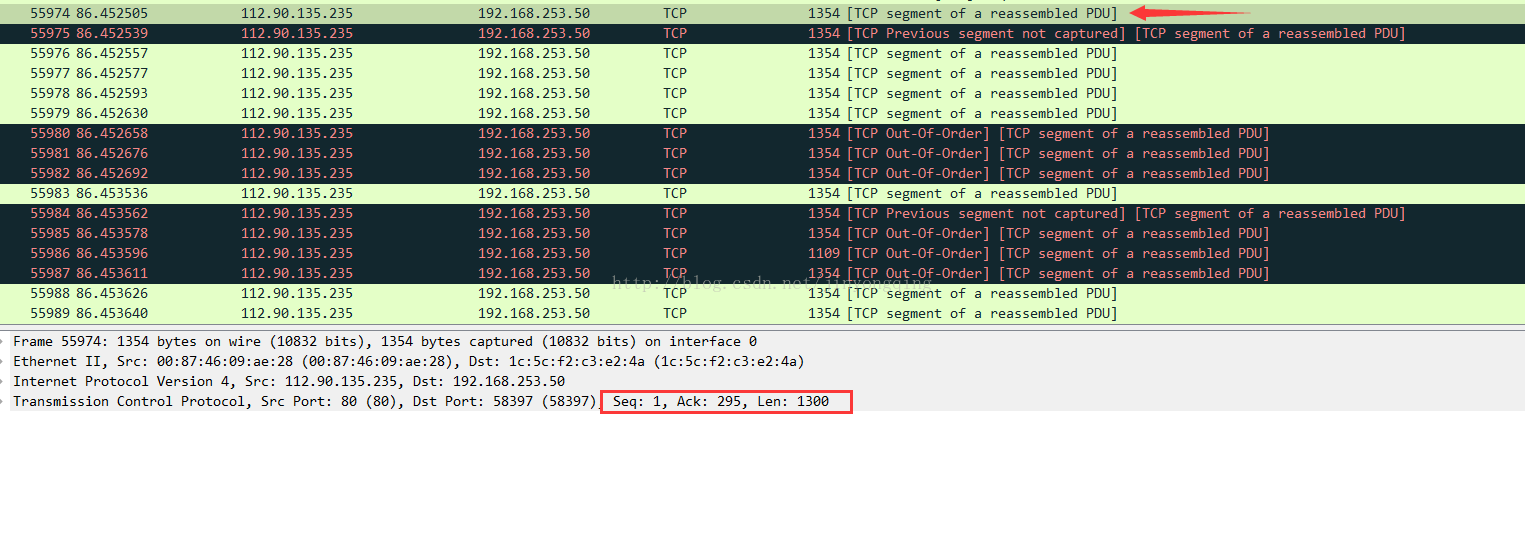
包55975:
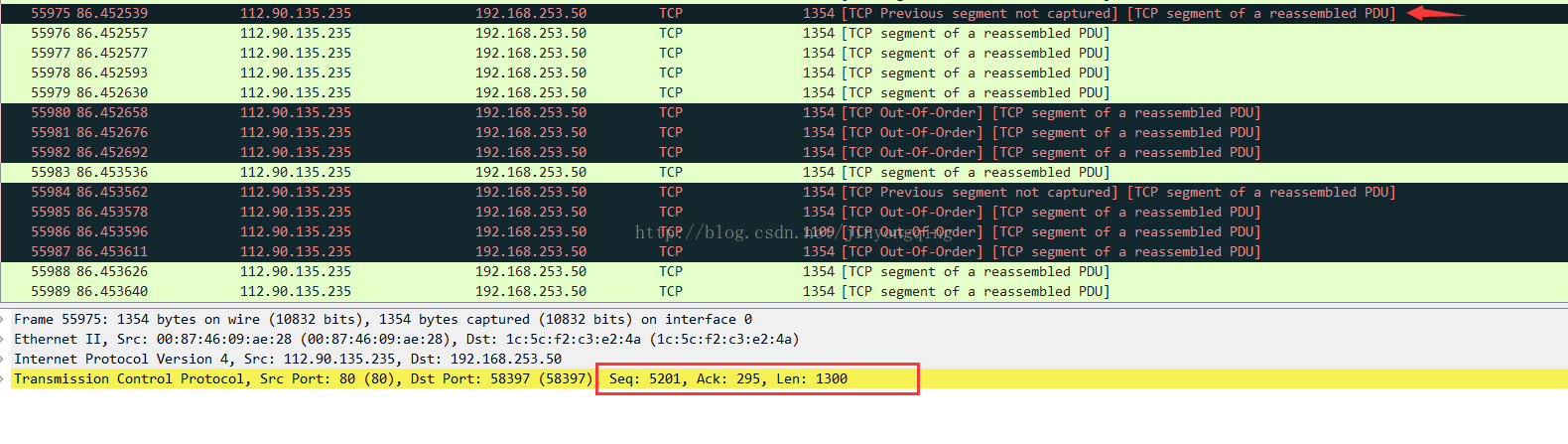
5201(55975的seq ) != 1(55974的seq ) + 1300(55974的len )
6.在TCP传输过程中(不包括三次握手和四次挥手),同一台主机发出的数据包应该是连续的,即后一个包的Seq号等于前一个包的Seq Len。
也可以说,后一个包的Seq会大于或等于前一个包的Seq。当Wireshark发现后一个包的Seq号小于前一个包的Seq Len时,就会认为是乱序了。跨度大的乱序却可能触发快速重传
也可以说,后一个包的Seq会大于或等于前一个包的Seq。当Wireshark发现后一个包的Seq号小于前一个包的Seq Len时,就会认为是乱序了。跨度大的乱序却可能触发快速重传
包55979:
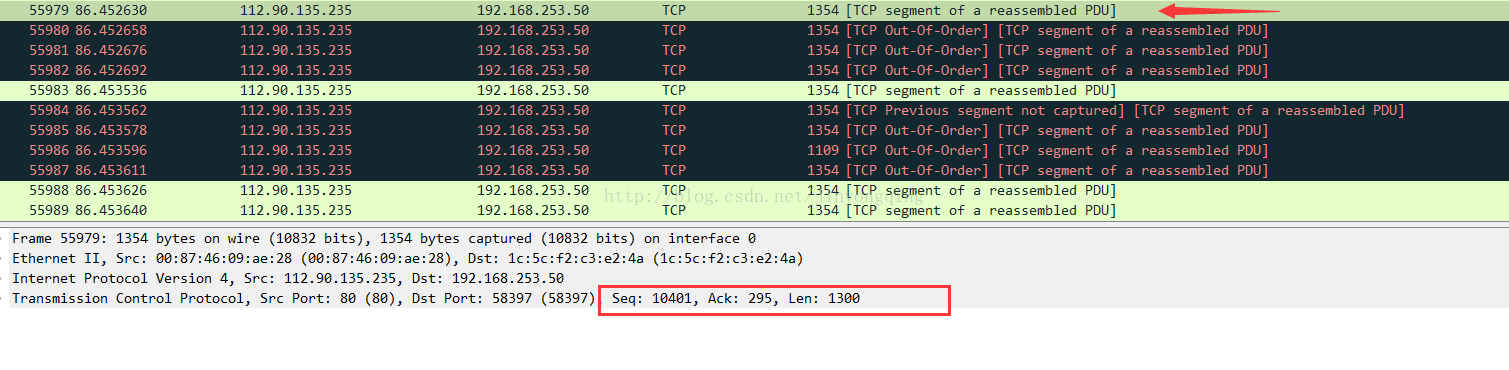
包55980
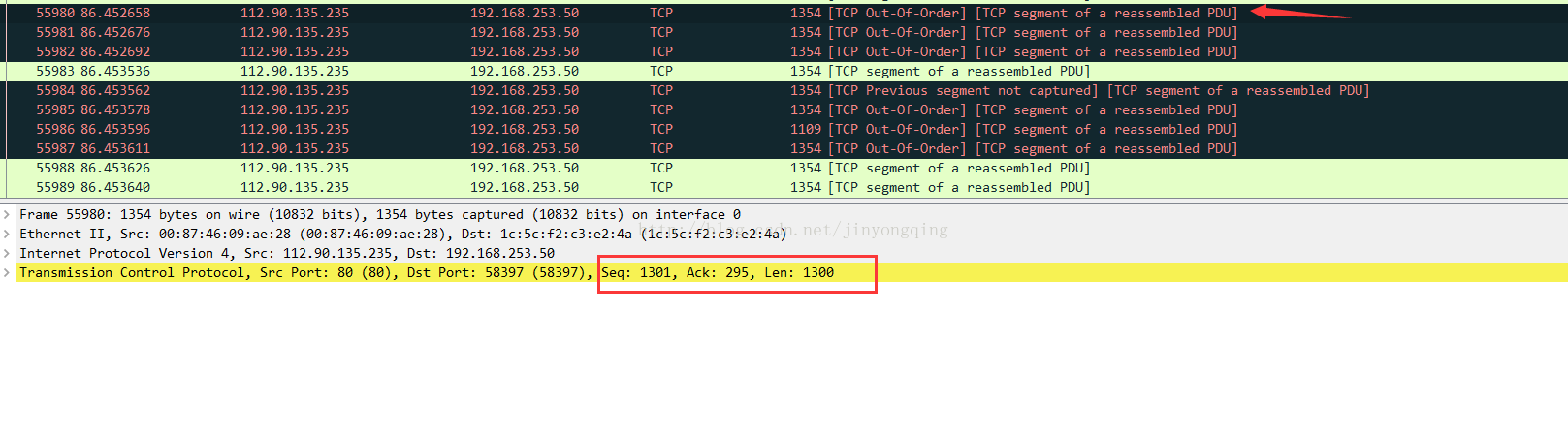
seq(55979) > seq(55980),55980应该是紧跟着55974的(1301 =1300 + 1),从到达的时间来看,是乱序了
7.关于SLE和SRE:
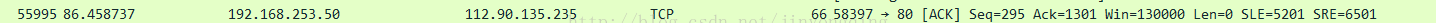
比如,服务器已发送的数据为1~34454个包,但是,客户端只收到了“1~1301,5201~6501”这些序列的包,也就是说“1302~5200”这些包已经丢了。
这个时候,客户端会向服务器请求发送ACK,说我收到了seq为1301的包,同时也乱序收到了"SLE为5201,SRE为6501"的包。
那么,服务器就知道,接着从seq=1302的包开始发送,发送到seq=5200的包的时候,就不用在发送seq=5201的包了,因为客户端已经收到了。
如果ACK中不带SLE和SRE会怎样呢?那服务器就会重发从"1302"开始之后的所有的包,包括其实客户端已经收到的"5201~6501"序号的包,那就浪费网络带宽了
如果ACK中不带SLE和SRE会怎样呢?那服务器就会重发从"1302"开始之后的所有的包,包括其实客户端已经收到的"5201~6501"序号的包,那就浪费网络带宽了
8.[TCP Dup ACK]
当乱序或者丢包发生时,接收方会收到一些Seq号比期望值大的包。它每收到一个这种包就会Ack一次期望的Seq值,以此方式来提醒发送方,于是就产生了一些重复的Ack。
同时,这些重复的ACK中,也会更新SLE和SRE的值,因为尽管ACK的值不变,即期望的seq没有收到,但可能又会新收到后面的乱序的包

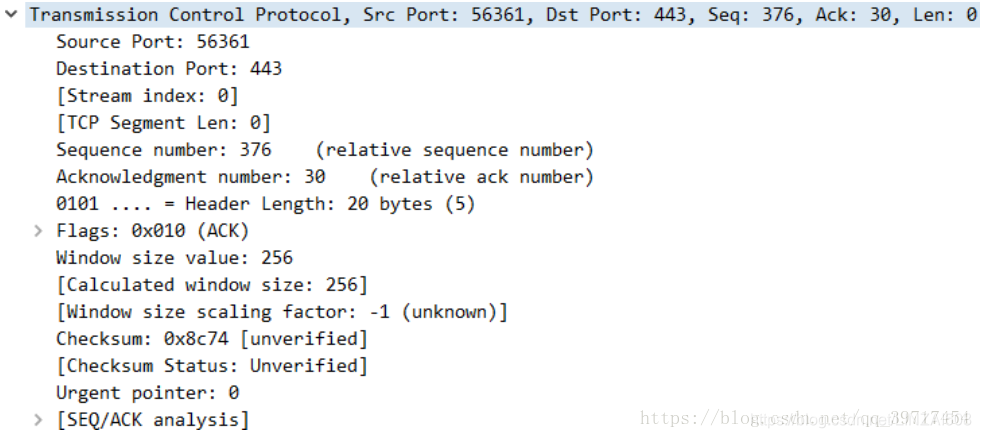
9.关于Seq,Ack,Win,Len的理解:
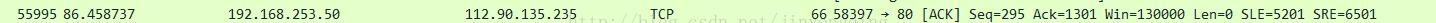
1.指明本次数据发送的信息:本次发送的数据起始序号是Seq,发送的长度是Len
2.发送端告诉接收端:我期望的Ack是多少,即希望接收端下次发从seq为ack号的给我,同时我还可以接收Win大小的数据,即接收端可以发送(Ack,Ack + Win)区间内的数据给发送端
10.[TCP Window Update]
这种情况下,Seq,Ack,Len都没有变,唯一变的是Win大小。说明这个ACK只是表明发送端接收数据的滑动窗口更新了
一般出现这种情况,就是由于发送端的应用程序将数据从接收数据缓冲区中取出来了,导致接收缓冲区大小更新

11.关于TCP重传:
决定报文是否有必要重传的主要机制是重传计时器(retransmission timer),它的主要功能是维护重传超时(RTO)值。当报文使用TCP传输时,重传计时器启动,收到ACK时计时器停止。报文发送至接收到ACK的时间称为往返时间(RTT)。对若干次时间取平均值,该值用于确定最终RTO值。在最终RTO值确定之前,确定每一次报文传输是否有丢包发生使用重传计时器,下图说明了TCP重传过程。

当报文发送之后,但接收方尚未发送TCP ACK报文,发送方假设源报文丢失并将其重传。重传之后,RTO值加倍;如果在2倍RTO值到达之前还是没有收到ACK报文,就再次重传。如果仍然没有收到ACK,那么RTO值再次加倍。如此持续下去,每次重传RTO都翻倍,直到收到ACK报文或发送方达到配置的最大重传次数。
所以TCP RTO的值会越来越大

如图所示:
1.37527的包,在75.55s发出,期望的ack=120656
2.知道42504的包,即103.85s的时候,才收到seq=120656的包,很显然,这个ack是超时重传的,因为中间过了28s的时间
3.在75.55-103.85期间,112.90.135.235应该进行过多次重传,但是都丢失了。知道103.85这个时间点的重传,才到达了客户端
4.每次重传后,RTO的时间会变大,所以如果重传一直不成功,两次重传之间的间隔时间也会越来越大,从而导致等待数据到达时间也会越来越长
参考文章:
参考文章:
1.Wireshark抓包常见问题解析: http://www.xianren.org/net/wireshark-q.html
2.wireshark抓包常见提示含义解析 : http://blog.csdn.net/u012398362/article/details/52276067
3.Wireshark抓包工具--TCP数据包seq ack等解读 : http://blog.csdn.net/wang7dao/article/details/16805337
4.一站式学习Wireshark(四):网络性能排查之TCP重传与重复ACK:http://blog.jobbole.com/71427/
5.wireshark中带有SLE和SRE的SACK包详解 :http://blog.csdn.net/season_hangzhou/article/details/48318599