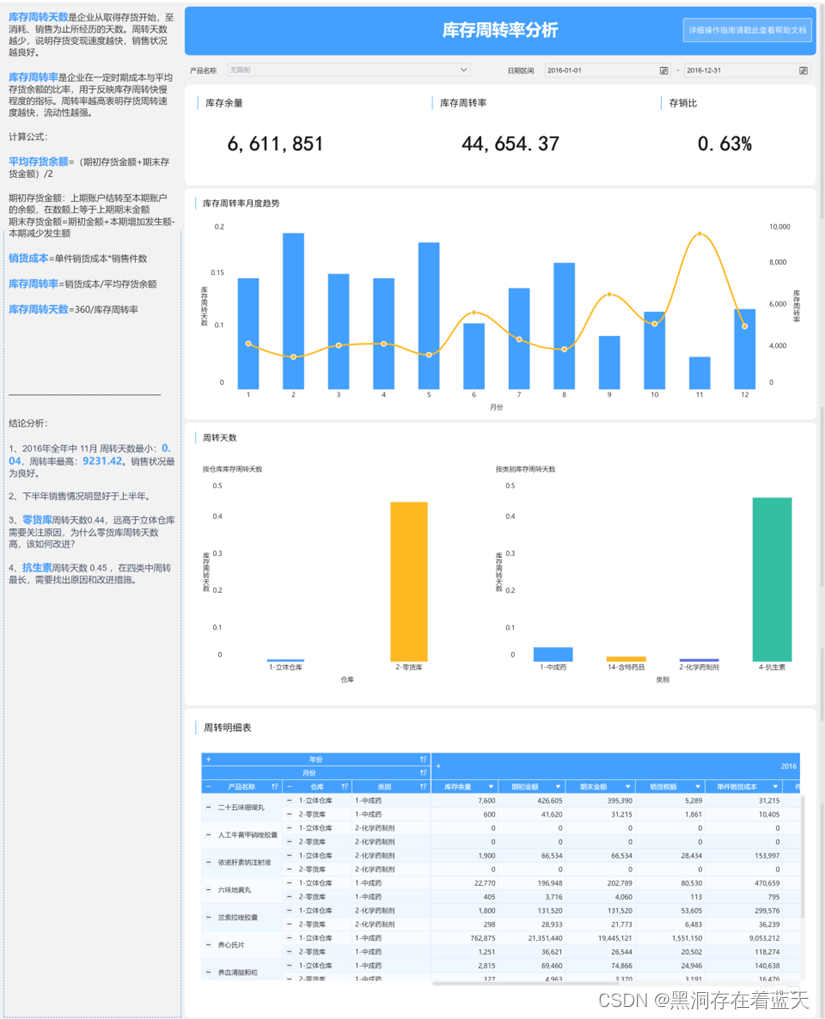
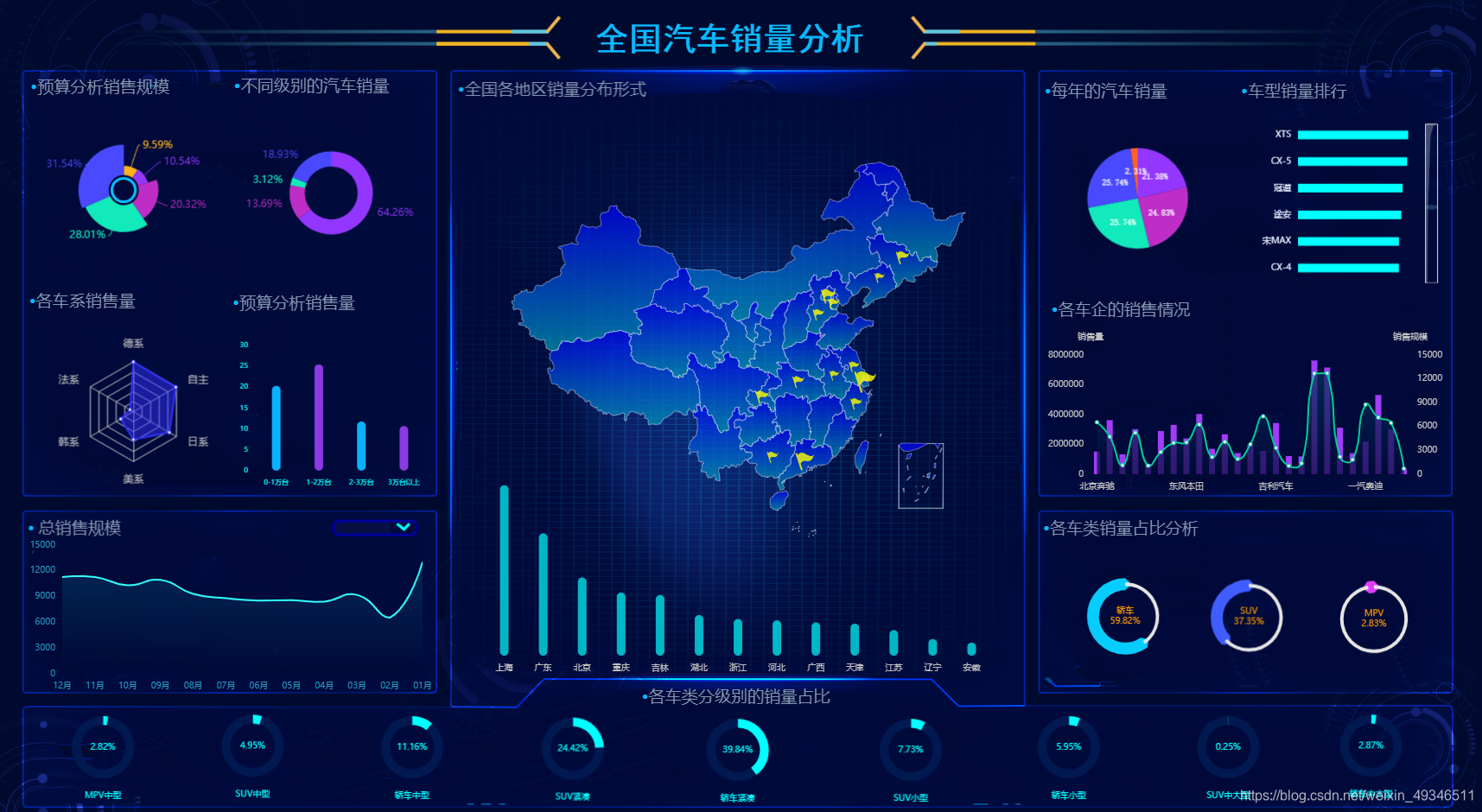
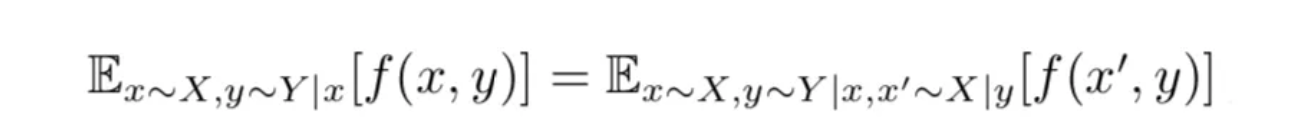深度学习-李宏毅GAN学习之InfoGAN,VAE-GAN,BiGAN
- 提出问题
- InfoGAN
- VAE-GAN
- BiGAN
- 总结
提出问题
我们知道最基本的GAN就是输入一个随机的向量,输出一个图片。以手写数字为例,我们希望修改随机向量的某一维,能改变数字的特想,比如角度,粗细,数字等,但是实际上貌似没什么大的影响,下图就是个例子,貌似看不到某一维度的具体含义,如下图:

我们可能直观的会认为每个维度应该就是一个特征,分布可能是这样的:
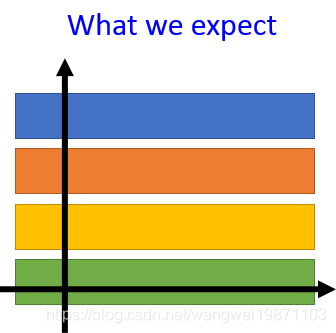
不同颜色代表不同特征的分布,如果真这样话就方便了,但是实际上或许是这样的分布:
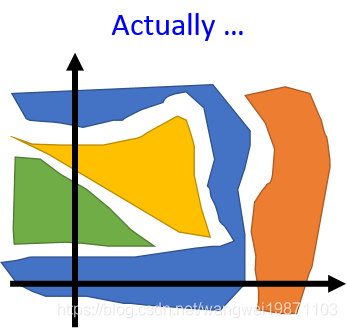
很蛋疼的分布,很难区分不同维度表示的特征。那怎么用他变成我们想象中的分布呢,可以使用InfoGAN。
InfoGAN
传统的GAN架构是这样。

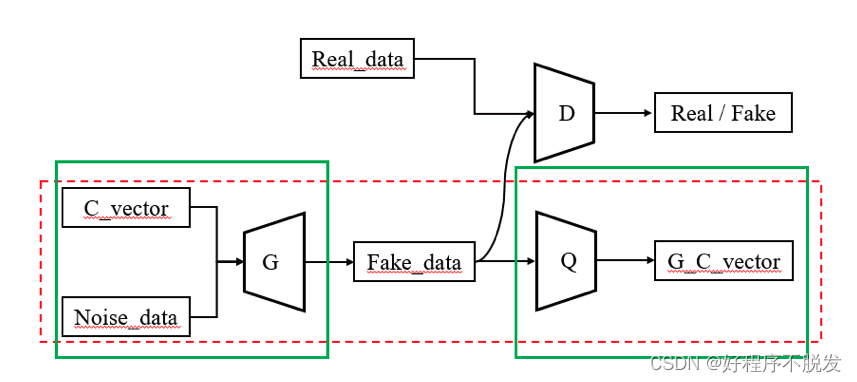
InfoGAN里把输入的向量随机看成2部分,然后加上一个分类器,通过x分类出c是什么:
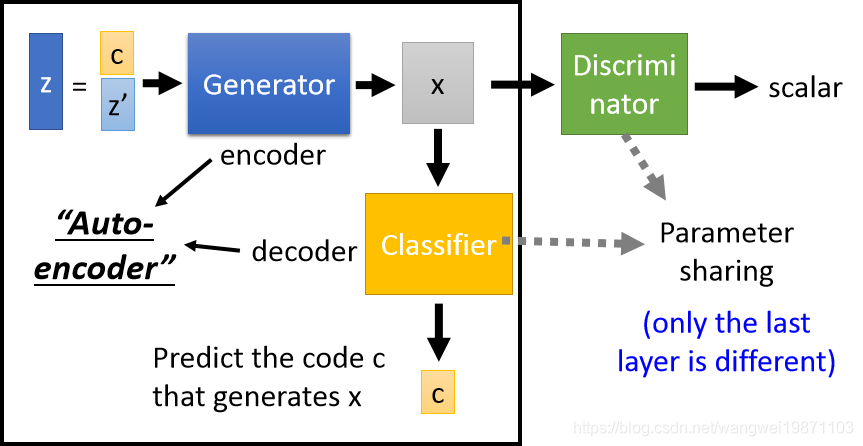
生成器和分类器就组成了自编码器,只不过输入向量,中间是图片,输出是向量,自编码器就希望能将z里的c部分预测出来,那样x必定包含c的特征,但是这样可能会有个问题,生成器可能很偷懒的直接把c贴在x图像上来帮助分类器学习出来,这就不符合我们的要求啦,中间的图出问题,所以这个时候,我们可以加入一个判别器,用来判别x是真是假,防止出现上述情况。分类器和判别器的输入都是x,网络可以共用参数,只是最后一层不一样,分类器可以是softmax,给出一堆概率的值表示c,生成器可以是sigmoid,输出0,1.
可以看下效果,左上角是某一维改变数字,右上是传统GAN的,左下是改了角度,右下是该了粗细:

VAE-GAN
顾名思义是VAE和GAN的结合体,可以说用GAN来强化VAE,也可以说用VAE来强化GAN,毕竟双方都有缺点,互补好呀。
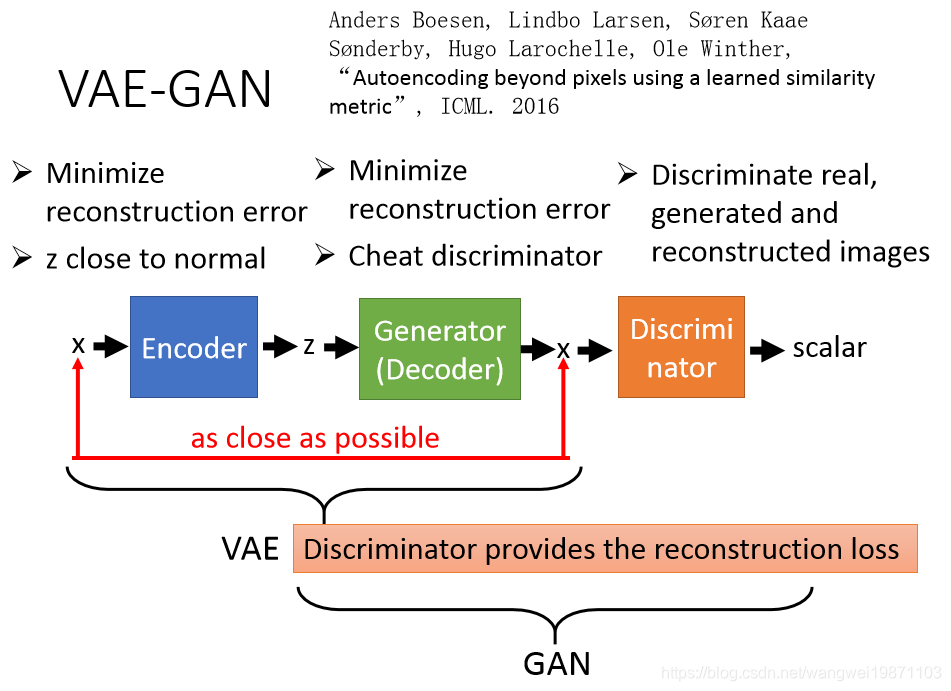
VAE生成的图片比较模糊,因为他的其中的一个目的是输入和输出最小差异嘛,所以可能会有很多像素为了差异最小,取了平均值,所以看起来就会模糊。那GAN刚好是可以判别图片质量啦,给模糊的低分,给真实高分,逼着生成器去生成清晰的图片,又要复原原图像。
算法基本思想就是:
编码器要做的就是让P(z|x)逼近分布P(z),比如标准正太分布,同时最小化生成器(解码器)和输入x的差距。
生成器(解码器)要做的就是最小化输出和输入x的差距,同时又要骗过判别器。
判别器要做的就是给真实的高分,跟P(z)采样生成的和重建的低分。
来看看他的算法,很清楚,就不多说了:

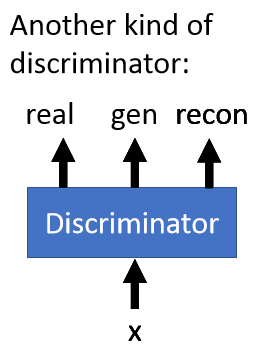
当然还有一种是判别器分为三类的,但是也是判别出真实的和其他的:
BiGAN
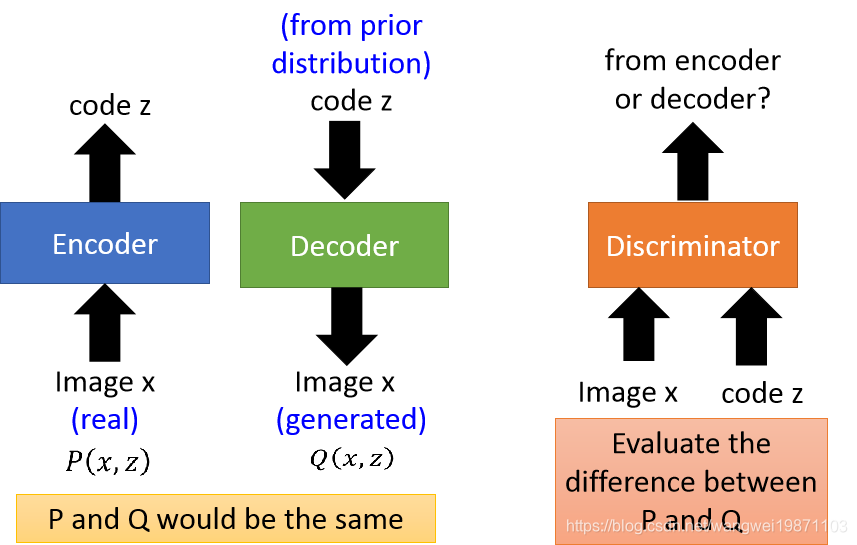
算法思想:将编码器和解码器分开,但是加一个判别器,将他们的输入和输出同时作为判别器的输入,然后区分是来自编码器还是解码器,如果无法分别来自哪个,就说明编码器的输入图片和解码器生成的图片很接近,编码器输出的z和解码器输入的z很接近,目的就达到了。
简单的原理就是将编码器看成一个P(x,z)分布,将解码器看成Q(x,z)分布,通过判别器,让他们的差异越来越小。理想情况下就会:
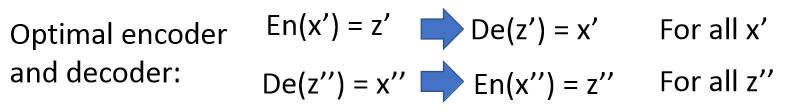
算法也很清楚:

上面的结构好像也可以改成训练两个自编码器:
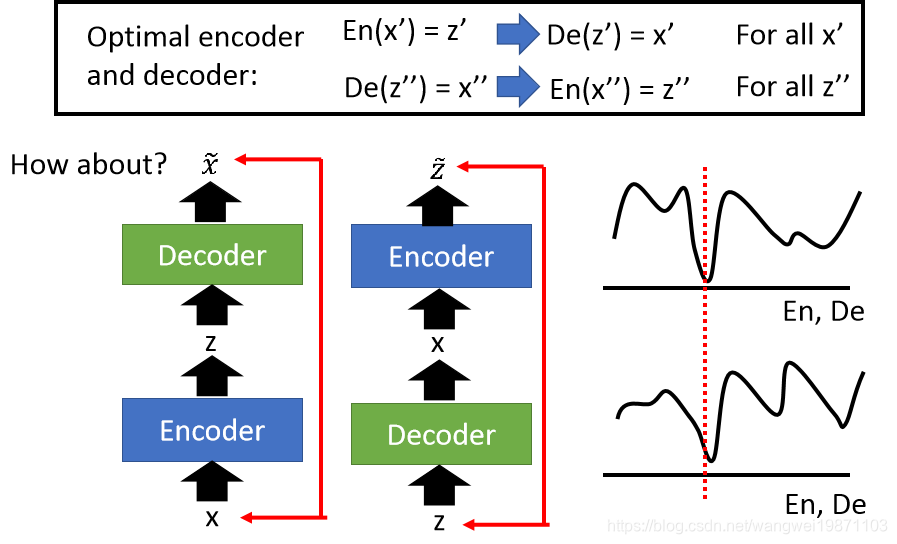
这种做法在最优的情况可能会跟BiGAN的架构一样,但是实际情况不可能最优,只能近似最优,而且这两个出来的图的特性不一样,自编码器出来还是跟输入的图一样,但是BiGAN出来的可能不是同一张图,但是还是原来图的内容,比如输入是一只鸟,输出可能是另一只鸟,鸟还是鸟,不会变别的,这个可能就是GAN的特性吧,有创造特性。
总结
AE可以让我们提取特征,VAE可以让我们找出特征分布,而GAN可以让特征的质量更加高,可以有效的结合三者,做更有趣的东西。
好了,今天就到这里了,希望对学习理解有帮助,大神看见勿喷,仅为自己的学习理解,能力有限,请多包涵,图片来自李宏毅课件,侵删。