配对交易方法
Abstract
抽象
This is one of the articles of A.I. Capital Management’s Research Article Series, with the intro article here. This one is about applying RL on market neutral strategies, specifically, optimizing a simple pair trading strategy with RL agent being the capital allocator on per trade basis, while leaving the entrance/exit signal untouched. The goal is to optimize an existing signal’s sequential trade size allocation while letting the agent adapt its actions to market regimes/conditions.
这是AI Capital Management研究文章系列的文章之一, 此处有介绍性文章。 这是关于将RL应用于市场中立策略,具体而言,以RL代理为每笔交易的资本分配者来优化简单的成对交易策略,同时保持进/出信号不变。 目的是优化现有信号的顺序交易规模分配,同时让代理人使其行动适应市场制度/条件。
Author: Marshall Chang is the founder and CIO of A.I. Capital Management, a quantitative trading firm that is built on Deep Reinforcement Learning’s end-to-end application to momentum and market neutral trading strategies. The company primarily trades the Foreign Exchange markets in mid-to-high frequencies.
作者: Marshall Chang是AI Capital Management的创始人兼CIO,这是一家定量交易公司,其建立在Deep Reinforcement Learning在动量和市场中性交易策略的端到端应用程序的基础上。 该公司主要以中高频交易外汇市场。
Overview
总览
Pairs trading is the foundation of market neutral strategy, which is one of the most sought-after quantitative trading strategies because it does not profit from market directions, but from the relative returns between a pair of assets, avoiding systematic risk and the Random Walk complexity. The profitability of market neutral strategies lie within the assumed underlying relationship between pairs of assets, however, when such relationship no longer withhold, often during volatile regime-shifting times such as this year with COVID-19, returns generally diminishes for such strategies. In fact, according to HFR (Hedge Fund Research, Inc.), the HFRX Equity Hedge Index, by the end of July, 2020, reported a YTD return of -9.74%[1]; its close relative, the HFRX Relative Value Arbitrage Index, reported a YTD return of -0.85%. There is no secret that for market neutral quants, or perhaps any quants, the challenge is not just to find profitable signals, but more in how to quickly detect and adapt complex trading signals during regime-shifting times.
交易对是市场中立策略的基础,这是最抢手的定量交易策略之一,因为它不从市场方向获利,而是从一对资产之间的相对收益中获利,避免了系统性风险和随机游走的复杂性。 市场中立策略的获利能力处于资产对之间假定的基本关系之内,但是,当这种关系不再保留时,通常在动荡的政权转换时期(例如今年的COVID-19),这种策略的收益通常会减少。 实际上,根据HFR(Hedge Fund Research,Inc.)的数据,截至2020年7月,HFRX股票对冲指数的年初至今回报率为-9.74% [1] ; 其近亲HFRX相对价值套利指数的年初至今回报率为-0.85%。 毫无疑问,对于市场中立的量化指标,或者也许对任何量化指标而言,面临的挑战不仅是寻找有利可图的信号,而且还在于如何在政权转换期间快速检测和适应复杂的交易信号。
Within the field of market neutral trading, most research have been focusing on uncovering correlations and refining signals, often using proprietary alternative data purchased at high costs to find an edge. However, optimization of capital allocation at trade size and portfolio level is often neglected. We found that lots of pair trading signals, though complex, still utilizes fixed entry thresholds and linear allocations. With the recent advancement of complex models and learning algorithms such as Deep Reinforcement Learning (RL), these class of algorithm is yearning for innovation with non-linear optimization.
在市场中立交易领域,大多数研究都集中在发现相关性和提炼信号上,通常使用高成本购买的专有替代数据来寻找优势。 但是, 经常忽略在贸易规模和投资组合水平上进行资本配置的优化 。 我们发现,许多配对交易信号尽管很复杂,但仍利用固定的进入门槛和线性分配。 随着复杂模型和学习算法(例如深度强化学习(RL))的最新发展,这类算法正渴望通过非线性优化进行创新。
Methodology — AlphaSpread RL Solution
方法论— AlphaSpread RL解决方案
To address the detection and adaptation of pair trading strategies through regime shifting times, our unique approach is to solve trade allocation optimization with sequential agent-based solution directly trained on top of existing signal generalization process, with clear tracked improvement and limited overhead of deployment.
为了解决通过制度转移时间来发现和调整配对交易策略的问题,我们独特的方法是通过在现有信号泛化过程之上直接训练的,基于顺序代理的解决方案来解决贸易分配优化问题,该解决方案具有明确的跟踪改进和有限的部署开销。
Internally named as AlphaSpread, this project demonstrates RL sequential trade size allocation’s ROI (Return on Investment) improvement over standard linear trade size allocation on 1 pair spread trading of U.S. S&P 500 equities. We take the existing pair trading strategy with standard allocation per trade as baseline, train RL allocator represented by a deep neural network model in our customized Spread Trading Gym environment, then test on out-of-sample data and aim to outperform baseline ending ROI.
该项目内部称为AlphaSpread ,展示了美国标准普尔500股票一对对价差交易中RL顺序交易规模分配的ROI(投资回报)相对于标准线性交易规模分配的提高。 我们将现有的配对交易策略(以每笔交易的标准分配作为基准)作为基准,在定制的Spread Trading Gym环境中训练由深度神经网络模型表示的RL分配器,然后对样本外数据进行测试,并力求超越基准期末ROI。
Specifically, we select cointegrated pairs based on their stationary spreads our statistical models. Cointegrated pairs are usually within the same industry, but we also include cross sectional pairs that show strong cointegration. The trading signal are generated by reaching pre-defined threshold of z-score on residues predicted by the statistical model using daily close prices. The baseline for this example allocates fixed 50% of overall portfolio to each trading signal, whereas the RL allocator output 0–100% allocation for each trading signal sequentially based on current market condition represented by a lookback of z-score.
具体来说,我们根据统计模型的固定价差选择协整对。 协整对通常位于同一行业,但我们还包括横截面对,它们显示出很强的协整性。 交易信号是通过使用每日收盘价通过统计模型预测的残差达到z分数的预定阈值而生成的。 此示例的基准将固定总资产组合的50%分配给每个交易信号,而RL分配器根据Z分数回溯表示的当前市场状况依次为每个交易信号输出0-100%的分配。
Results Summary
结果汇总
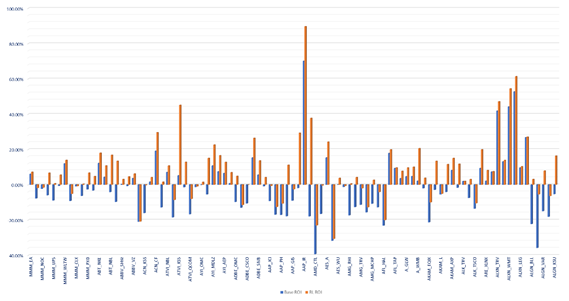
We summarize our RL approach’s pairs trading ROI against baseline linear allocation for 107 U.S. Equity pairs traded. The ROI is calculated with ending NAV of testing period against each pair’s $100,000 starting capital. The result is from back-testing on out-of-sample data between 2018 to April 2020 (COVID-19 months included). The RL allocators are trained with data between 2006 and 2017. In both cases fees are not consider in the testing. We have achieved on average 9.82% per pair ROI improvement over baseline approach, with maximum of 55.62% and minimum of 0.08%.
我们针对107个美国股票对总结了RL方法的对投资回报率与基准线性分配的对。 相对于每对100,000美元的启动资金,以测试期末的资产净值来计算ROI。 结果是对2018年至2020年4月(包括COVID-19个月)之间的样本外数据进行了回测。 RL分配器接受了2006年至2017年之间的数据培训。在两种情况下,测试均不考虑费用。 与基线方法相比,我们平均每对ROI提升了9.82%,最大为55.62%,最小为0.08%。
In other words, with limited model tuning, this approach is able to result in generalized improvement of ROI through early detecting of regime-shifting and the accordingly capital allocation adaptation by the RL allocator agent.
换句话说,通过有限的模型调整,该方法能够通过早期检测到体制转移以及相应地由RL分配器代理进行资本分配适应,来全面提高ROI。
Discussions of Generalization
泛化讨论
The goal of this project is to demonstrate out-of-sample generalization of the underlying improvements on a very simple one-pair trading signals, hence providing guidance on adapting such methodology on large scale complex market neutral strategies to be deployed. Below is a discussion of the 3 goals we set out to achieve in this experiment.
该项目的目的是展示对非常简单的一对交易信号的潜在改进的样本外概括,从而为在将要部署的大规模复杂市场中立策略上采用这种方法提供指导 。 以下是我们在本实验中要实现的3个目标的讨论。
Repeatability — This RL framework consists of customized pairs trading RL environment used to accurately train and test RL agents, RL training algorithms including DQN, DDPG and Async Actor Critics, RL automatic training roll out mechanism that integrates memory prioritized replay, dynamic model tuning, exploration/exploitation and etc., enabling repeatability for large datasets with minimum customization and hand tuning. The advantage of running RL compared with other machine learning algorithm is that it is an end-to-end system from training data generalization, reward function design, model and learning algorithm selection to output a sequential policy. A well-tuned system requires minimum maintenance and the retraining / readapting of models to new data is done in the same environment.
重复性 -此RL框架包括用于准确训练和测试RL代理的定制交易RL环境配对交易,包括DQN,DDPG和Async Actor Critics在内的RL训练算法,集成了内存优先重放,动态模型调整,探索的RL自动训练推出机制/ exploitation等,从而以最小的自定义和手动调整实现大型数据集的可重复性。 与其他机器学习算法相比,运行RL的优势在于它是一个从训练数据概括,奖励函数设计,模型和学习算法选择到输出顺序策略的端到端系统。 调整良好的系统需要最少的维护,并且在同一环境中对新数据进行模型的重新训练/重新适应。
Sustainability — Under the one-pair trading example, the pairs cointegration test and RL training were done using data from 2006 and 2017, and then trained agents run testing from 2018 to early 2020. The training and testing data split are roughly 80:20. With RL automatic training roll out, we can generalize sustainable improvements over baseline return for more than 2 years across hundreds of pairs. The RL agent learns to allocate according to the lookback of z-scores representing the pathway of the pair’s cointegration as well as volatility and is trained with exploration / exploitation to find policy that maximize ending ROI. Compared with traditional supervised and unsupervised learning with static input — output, RL algorithms has built-in robustness for generalization in that it directly learns state-policy values with a reward function that reflects realized P/L. The RL training targets are always non-static in that the training experience improves as the agent interacts with the environment and improves its policy, hence the reinforcement of good behavior and vice versa.
可持续性 —在一对交易示例中,使用2006年和2017年的数据进行货币对协整测试和RL训练,然后由受过训练的代理商从2018年到2020年初进行测试。训练和测试数据的划分大致为80:20。 借助RL自动培训的推出,我们可以在数百年中对超过2年的基线回报进行可持续改进。 RL代理学习根据代表该货币对的协整和波动性的z分数的回溯进行分配,并经过探索/开发训练,以找到可最大程度提高最终投资回报率的策略。 与具有静态输入输出的传统有监督和无监督学习相比,RL算法具有内置的泛化鲁棒性,因为它可以直接使用反映已实现P / L的奖励函数来学习状态策略值。 RL培训目标始终是非静态的,因为随着代理人与环境的互动并改善其政策,培训经验将得到改善,从而加强良好行为,反之亦然。
Scalability — Train and deploy large scale end-to-end Deep RL trading algorithms is still its infancy in quant trading, but we believe it is the future of alpha in our field, as RL has demonstrated dramatic improvement over traditional ML in the game space (AlphaGo, Dota etc.). This RL framework is well versed to apply to different pair trading strategies that is deployed by market neutral funds. With experience running RL system in multiple avenues of quant trading, we can customize environment, training algorithms and reward function to effectively solve unique tasks in portfolio optimization, powered by RL’s agent based sequential learning that traditional supervised and unsupervised learning models cannot achieve.
可扩展性 —训练和部署大规模的端到端深度RL交易算法仍是定量交易的起步阶段,但我们相信这是我们领域alpha的未来,因为RL在游戏领域已证明优于传统ML。 (AlphaGo,Dota等)。 此RL框架非常适合应用于市场中立基金部署的不同对交易策略。 凭借在多种数量交易渠道上运行RL系统的经验,我们可以自定义环境,训练算法和奖励功能,以有效地解决投资组合优化中的独特任务,这是基于RL基于代理的顺序学习提供的,而传统的监督和无监督学习模型则无法实现。
Key Take Away
钥匙拿走
If the signal makes money, it makes money with linear allocation (always trade x unit). But when it doesn’t, obviously we want to redo the signal, let it adapt to new market conditions. However, sometimes that’s not easy to do, and a quick fix might be a RL agent/layer on top of existing signal process. In our case, we let the agent observe a dataset that represents volatility of the spreads, and decide on the pertinent allocation based on past trades and P/L.
如果信号赚钱,它就会线性分配(总是以x单位交易)赚钱。 但是,如果不这样做,显然我们要重做信号,使其适应新的市场条件。 但是,有时这并不容易做到,快速解决方案可能是在现有信号处理之上的RL代理/层。 在我们的案例中,我们让代理商观察代表价差波动性的数据集,并根据过去的交易和损益决定相关的分配。
Background and More Details
背景和更多详细信息
Signal Generalization Process — We first run a linear regression on both assets’ past look back price history (2006–2017 daily price), then we do OLS test to obtain the residual, with which we run unit root test (Augmented Dickey–Fuller test) to check the existence of cointegration. In this example, we set the p-value threshold at 0.5% to reject unit root hypothesis, which results in a universe of 2794 S&P 500 pairs that pass the test. Next phrase is how we set the trigger conditions. First, we normalize the residual to get a vector that follows assumed standard normal distribution. Most tests use two sigma level reaches 95% which is relatively difficult to trigger. To generate enough trading for each pair, we set our threshold at one sigma. After normalization, we obtain a white noise follows N(0,1), and set +/- 1 as the threshold. Overall, the signal generation process is very straight forward. If the normalized residual gets above or below threshold, we long the bearish one and short the bullish one, and vice versa. We only need to generate trading signal of one asset, and the other one should be the opposite direction
信号概括过程 —我们首先对两种资产的过去回溯价格历史记录(2006-2017年每日价格)进行线性回归,然后进行OLS测试以获取残差,然后进行单位根检验(Augmented Dickey-Fuller检验) )检查协整的存在。 在此示例中,我们将p值阈值设置为0.5%,以拒绝单位根假设,这导致2794个标准普尔500对货币对通过了测试。 接下来的短语是我们如何设置触发条件。 首先,我们对残差进行归一化以获得遵循假定标准正态分布的向量。 大多数测试使用两个西格玛水平达到95%,这相对难以触发。 为了为每个货币对产生足够的交易,我们将阈值设置为一个西格玛。 归一化后,我们获得跟随N(0,1)的白噪声,并将+/- 1设置为阈值。 总体而言,信号生成过程非常简单。 如果归一化残差高于或低于阈值,则我们做多看跌期权,而做空看涨期权,反之亦然。 我们只需要生成一种资产的交易信号,而另一种应该是相反的方向
Deep Reinforcement Learning — The RL training regimes starts with running an exploration to exploitation linear annealed policy to generate training data by running the training environment, which in this case runs the same 2006–2017 historical data as with the cointegration. The memory is stored in groups of
深度强化学习 — RL培训制度从运行探索线性退火策略开始,通过运行培训环境来生成培训数据,在这种情况下,该环境运行与协整相同的2006–2017历史数据。 内存按以下组存储
State, Action, Reward, next State, next Action (SARSA)
状态,动作,奖励,下一状态,下一动作(SARSA)
Here we use a mixture of DQN and Policy Gradient learning target, in that our action outputs are continuous (0–100%) yet sample inefficient (within hundreds of trades per pair due to daily frequency). Our training model updates iteratively with
在这里,我们混合使用DQN和Policy Gradient学习目标,因为我们的行动输出是连续的(0–100%),但样本效率低下(由于每日交易频率,每对交易有数百笔交易)。 我们的训练模型会迭代更新
Q(State) = reward + Q-max (next States, next Actions)
Q(状态)=奖励+ Q-最大值(下一个状态,下一个动作)
Essentially, RL agent is learning the q value of continuous-DQN but trained with policy gradient on the improvements of each policy, hence avoiding the sample inefficiency (Q learning is guaranteed to converge to training global optimal) and tendency to stuck in local minimum too quickly (avoiding all 0 or 1 outputs for PG). Once the warm-up memories are stored, we train the model (in this case is a 3-layer dense net outputting single action) with the memory data as agent continues to interact with the environment and roll out older memories.
本质上,RL代理正在学习连续DQN的q值,但是在每种策略的改进上通过策略梯度进行了训练,因此避免了样本效率低下(保证Q学习收敛到训练全局最优值)和陷入局部最小值的趋势。快速(避免PG的所有0或1输出)。 一旦存储了预热的内存,随着代理继续与环境交互并推出较旧的内存,我们将使用内存数据训练模型(在这种情况下为3层密集网络输出单个动作)。
Sutton RS, Barto AG. Reinforcement learning: An introduction. MIT press; 2018.
Sutton RS,Barto AG。 强化学习:简介。 麻省理工学院出版社; 2018。
HFRX® Indices Performance Tables. (n.d.). Retrieved August 03, 2020, from https://www.hedgefundresearch.com/family-indices/hfrx
HFRX®指数性能表。 (nd)。 于2020年8月3日从 https://www.hedgefundresearch.com/family-indices/hfrx 检索
翻译自: https://towardsdatascience.com/adaptive-pair-trading-under-covid-19-a-reinforcement-learning-approach-ff17e6a8f0d6
配对交易方法
相关文章

一种拉风的交易策略——配对交易
基于协整理论的配对交易

matlab配对交易回测,精品案例 | 经典投资策略之配对交易策略
金融量化 — 配对交易策略 (Pair Trading)
【量化笔记】配对交易

配对交易——初识统计套利


股票中的情侣——配对交易(附:源码)

在html中透明度的用法,关于CSS透明度的两种使用方法以及优缺点

设置CSS透明度的方法

css透明度兼容问题opacity

html中透明度100是,CSS 透明度设置方法及常见问题解析

html页面透明度属性,css透明度属性是什么?

html中的透明度怎么设置,css透明度怎么设置?css中各种透明度的设置方法总结...

html页面透明度属性,css透明度是什么属性?

html css表格透明度,【总结】CSS透明度大汇总_html/css_WEB-ITnose
![CSS透明度[简述]](https://img-blog.csdnimg.cn/29730e6d4a244a93a08113d15ffa7665.png)
CSS透明度[简述]