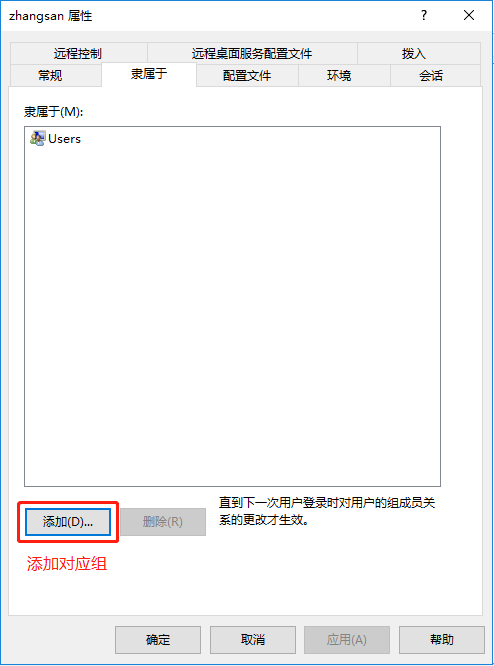
一、基本概念
(一)基本介绍
Linux作为一种多用户的操作系统(服务器系统),允许多个用户同时登陆到系统上,并响应每个用户的请求。任何需要使用操作系统的用户,都需要一个系统账号,账号分为:管理员账号与普通用户账号。在Linux中,操作系统根据UID来判断用!根据UID来判断用户! 而不是用户名!只要id为0就是管理员,哪怕有多个id为0 的账号;系统在新建账号时,会根据账号类型,自动分配递增账号的UID与GID (用户身份编号,组编号),也可自行分配。通常情况下,应当保证UID与GID唯一且不重复。
(二)Linux的单用户任务和多用户任务
在Linux下,当你登录后,你也可以同时开启很多的服务任务和进程,而各自服务都会跑的很好却对其他任务没有任何影响,这种登录一个用户登录系统执行多个服务任务和进程的情况,就称为单用户多任务。
多用户任务——有时可能是很多用户同时用同一个系统,如公司几十个运维人员,每台机器都可以和被若干个运维人员登录部署或解决相关故障问题,但并不是所有的运维人员都要做同一件事,所以就有了多任务、多用户的情况。
注:多用户、多任务并不是大家同时挤到一起,在一台机器的键盘和显示器前来操作机器,多用户可能是通过SSH客户端工具等远程工具等远程登录服务器来进行,比如对服务器的运程控制,只要具有相关用户的权限,任何人都是可以上去操作访问服务器。
(三)Linux系统用户角色划分
用户在系统中是分角色的,在Linux系统中,由于角色的不同,权限和所完成的任务也不同;值得注意的是用户的角色是通过UID和GID识别的;特别是UID,在运维工作中,一个UID是唯一标识一个系统用户的账号。
用户账户:
超级用户root(0)
程序用户(1~499)
普通用户(500~65535)
超级用户:
默认是root用户,其UID和GID均为0。在每台unix/linux操作系统中都是唯一且真实存在的,通过它可以登录系统,可以操作系统中任何文件和命令,
拥有最高的管理权限。在生产环境,一般禁止root账号远程登录SSH连接服务器,以加强系统安全。
普通用户:
这类用户一般是由具备系统管理员root的权限的运维人员添加的
程序序用户:
与真实用户区分开来,这类用户的最大特点是安装系统后默认就会存在的,且默认情况不能登录系统,它们是系统正常运行必不可少的,
他们的存在主要是方便系统管理,满足相应的系统进程都文件属主的要求。例如系统默认的bin、adm、nodoby、mail用户等。由于服务器角色的不同,有部分用不到的系统服务被禁止开机执行,因此,在做系统安全优化时,被禁止开机启动了的服务对应的虚拟用户也是可以处理掉的(删除或注释)。
举例说明:
(四)用户和用户组介绍
用户—每一个用户都有一个唯一的用户名和用户口令,在登录系统后,只有正确输入了用户名和密码,才能登录系统和相应的目录。
用户组—简单的说,linux系统中的用户组(group)就是具有相同特性的用户(user)集合;有时我们需要让多个用户具有相同的权限,比如查看、修改某一个文件或目录,如果不用用户组,这种需求在授权时就很难实现。如果使用用户组就方便多了,只需要把授权的用户都加入到同一个用户组里,然后通过修改该文件或目录的对应的用户组的权限,让用户组具有符合需求的操作权限,这样用户组下的所有用户对该文件或目录就会具有相同的权限,这就是用户组的用途。将用户分组是linux系统中对用户进行管理及控制访问权限的一种手段,通过定义用户组,在很大程度上简化了运维管理工作。
用户和用户组的对应关系有:一对一、一对多、多对一和多对多.
一对一:即一个用户可以存在一个组中,也可以是组中的唯一成员。比如,root
一对多:即一个用户可以存在多个组中,这个用户就具有这些组。
多对一:即多个用户可以存在一个组中,这些用户这些组的共同权限。
多对多:即多用户可以存在于多个组中。并且几个用户可以归属相同的组;其实多对多的关系是前面三条的扩展。
二、用户及用户组配置文件介绍
在Linux中,万物皆文件,所以用户与组也以配置文件的形式保存在系统中,以下为用户和组的主要配置文件详解:
- /etc/passwd:用户及其属性信息(名称、 UID、主组ID等)
- /etc/group:组及其属性信息
- /etc/shadow:用户密码及其相关属性
- /etc/gshadow:组密码及其相关属性
1.用户的配置文件/etc/passwd
/etc/passwd文件中每行定义一个用户账号,有多少行就表示多少个账号,在一行中可以清晰的看出,各内容之间又通过”:”号划分了7个字段,这7个字段分别定义了账号的不同属性,passwd文件实际内容如下:

字段1:帐号名,这是用户登陆时使用的账户名称,在系统中是唯一的,不能重名
字段2:密码占位符x;早期的unix系统中,该字段是存放账户和密码的,由于安全原因,后来把这个密码字段内容移到/etc/shadow中了。这里可以看到一个字母x,表示该用户的密码是/etc/shadow文件中保护的。
字段3:UID;范围是0-65535
字段4:GID;范围是0-65535;当添加用户时,默认情况下会同时建立一个与用户同名且UID和GID相同的组。
字段5:用户说明;这个字段是对这个账户的说明
字段6:宿主目录;用户登陆后首先进入的目录,一般与"/home/用户名"这样的目录
字段7:登录Shell 当前用户登陆后所使用的shell,在centos/rhel系统中,默认的shell是bash;如果不希望用户登陆系统,可以通过usermod或者手动修改passwd设置,将该字段设置为/sbin/nologin 即可。大多数内置系统账户都是/sbin/nologin,这表示禁止登陆系统。这是出于安全考虑的。——awd攻防必须的操作!
passwd中有关UID的限制说明:
0:当用户的UID为0时,表示这个账户为超级用户;如果要增加一个系统管理员账户的话,只需将该账户的UID改为0即可。不建议
1~499:这个范围是保留给系统用户使用的UID
500~65535:普通账户UID
最后,来看一下/etc/passwd的权限:

因为每个用户登录时都需要取得UID和GID来判断权限问题,所以/etc/passwd的权限为644,这样一来就会带来安全问题,即所有的用户都可以都/etc/passwd文件,即使文件内的密码是加密的,但还是存在一定的被攻击破解的安全隐患。因此,就有了/etc/shadow文件。
2.用户的影子口令文件/etc/shadow

字段1:帐号名称
字段2:加密的密码(通常使用shad512加密)
字段3:最近更改密码的时间;从1970/1/1到上次修改密码的天数
字段4:禁止修改密码的天数;从1970/1/1开始,多少天之内不能修改密码,默认值为0
字段5:用户必须更改口令的天数;密码的最长有效天数,默认值为99999
字段6:警告更改密码的期限;密码过期之前警告天数,默认值为7;在用户密码过期前多少天提醒用户更改密码
字段7:不活动时间;密码过期之后账户宽限时间 3+5;在用户密码过期之后到禁用账户的天数
字段8:帐号失效时间,默认值为空;从1970/1/1日起,到用户被禁用的天数
字段9:保留字段(未使用),标志
3. 用户组配置文件/etc/group
/etc/group 文件是用户组的配置文件,内容包括用户与用户组,并且能显示用户归属哪个用户组,因为一个用户可以归属一个或多个不同的用户组;同一用户组的用户之间具有相似的特性。如果某个用户下有对系统管理有最重要的内容,最好让用户拥有独立的用户组,或者是把用户下的文件的权限设置为完全私有;另外root用户组一般不要轻易把普通用户加入并且。同/etc/passwd类似,其文件权限也是644:

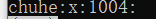
字段1:组账户名称
字段2:密码占位符x;通常不需要设置该密码,由于安全原因,该密码被记在/etc/gshadow中,因此显示为'x'。这类似/etc/shadow。
字段3:组账户GID号,用户组ID
字段4:本组的成员用户列表;加入这个组的所有用户账号
4.用户组的影子文件/etc/gshadow
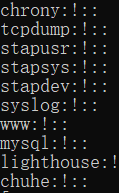
字段1:组账号的名称 字段2:加密后的密码字符串,这个字段可以空的或者!;如果是空的或有!,表示没有密码 字段3:本组的管理员列表;这个字段也可为空;如果有多个用户组管理员,用,号分隔 字段4:本组的成员列表;加入这个组的所有用户账户;列表中多个用户通过","分隔